
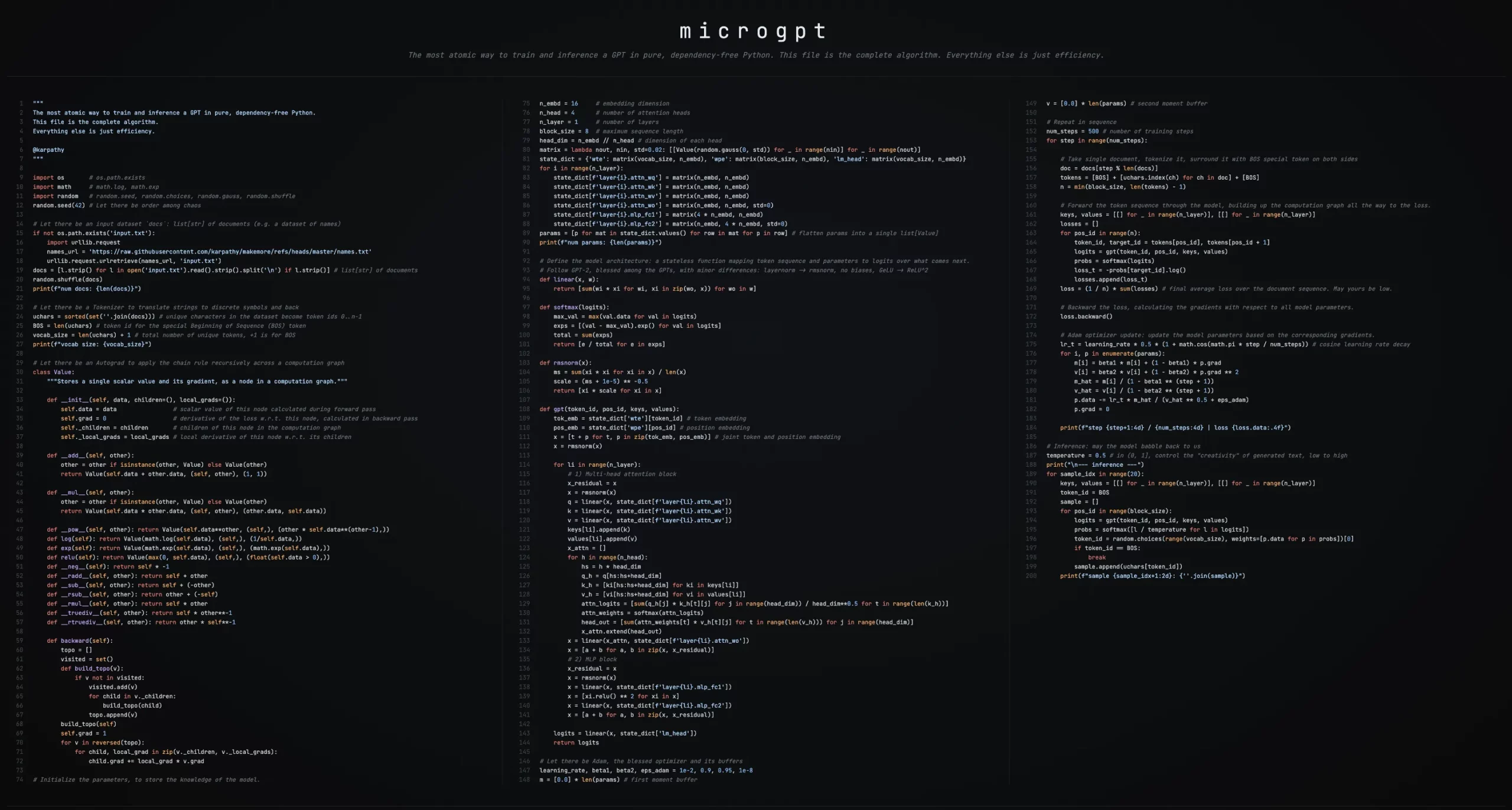
The AI researcher Andrej Karpathy has developed an academic software microGPT which gives the best entry to GPT expertise in line with his analysis findings. The challenge makes use of 243 strains of Python code which doesn’t want any exterior dependency to indicate customers the elemental mathematical ideas that govern Massive Language Mannequin operations as a result of it removes all sophisticated options of contemporary deep studying programs.
Let’s dive into the code and work out how he was capable of obtain such a marvellous feat in such a economical method.
What Makes MicroGPT Revolutionary?
Most GPT tutorials as we speak depend on PyTorch, TensorFlow, or JAX which function highly effective frameworks, however they conceal mathematical foundations by means of their user-friendly interface. Karpathy’s microGPT takes the other strategy as a result of it builds all of its capabilities by means of Python’s built-in modules that embrace primary programming instruments.
The code doesn’t comprise the next:
- The code contains neither PyTorch nor TensorFlow.
- The code incorporates no NumPy or every other numerical libraries.
- The system doesn’t use GPU acceleration or any optimization methods.
- The code incorporates no hid frameworks or unexposed programs.
The code incorporates the next:
- The system makes use of pure Python to create autograd which performs computerized differentiation.
- The system contains the entire GPT-2 structure which options multi-head consideration.
- The Adam optimizer has been developed by means of first ideas.
- The system gives a whole coaching and inference system.
- The system produces operational textual content era that generates precise textual content output.
This method operates as a whole language mannequin which makes use of precise coaching knowledge to create logical written content material. The system has been designed to prioritize comprehension as a substitute of quick processing pace.
Understanding the Core Parts
The Autograd Engine: Constructing Backpropagation
Computerized differentiation capabilities because the core element for all neural community frameworks as a result of it permits computer systems to routinely calculate gradients. Karpathy developed a primary model of PyTorch autograd which he named micrograd that features just one Worth class. The computation makes use of Worth objects to trace each quantity which consists of two parts.
- The precise numeric worth (knowledge)
- The gradient with respect to the loss (grad)
- Which operation created it (addition, multiplication, and so on.)
- Learn how to backpropagate by means of that operation
Worth objects create a computation graph while you use a + b operation or an a * b operation. The system calculates all gradients by means of chain rule software while you execute loss.backward() command. This PyTorch implementation performs its core capabilities with none of its optimization and GPU capabilities.
# Let there be an Autograd to use the chain rule recursively throughout a computation graph
class Worth:
"""Shops a single scalar worth and its gradient, as a node in a computation graph."""
def __init__(self, knowledge, youngsters=(), local_grads=()):
self.knowledge = knowledge # scalar worth of this node calculated throughout ahead go
self.grad = 0 # spinoff of the loss w.r.t. this node, calculated in backward go
self._children = youngsters # youngsters of this node within the computation graph
self._local_grads = local_grads # native spinoff of this node w.r.t. its youngsters
def __add__(self, different):
different = different if isinstance(different, Worth) else Worth(different)
return Worth(self.knowledge + different.knowledge, (self, different), (1, 1))
def __mul__(self, different):
different = different if isinstance(different, Worth) else Worth(different)
return Worth(self.knowledge * different.knowledge, (self, different), (different.knowledge, self.knowledge))
def __pow__(self, different):
return Worth(self.knowledge**different, (self,), (different * self.knowledge**(different - 1),))
def log(self):
return Worth(math.log(self.knowledge), (self,), (1 / self.knowledge,))
def exp(self):
return Worth(math.exp(self.knowledge), (self,), (math.exp(self.knowledge),))
def relu(self):
return Worth(max(0, self.knowledge), (self,), (float(self.knowledge > 0),))
def __neg__(self):
return self * -1
def __radd__(self, different):
return self + different
def __sub__(self, different):
return self + (-other)
def __rsub__(self, different):
return different + (-self)
def __rmul__(self, different):
return self * different
def __truediv__(self, different):
return self * different**-1
def __rtruediv__(self, different):
return different * self**-1The GPT Structure: Transformers Demystified
The mannequin implements a simplified GPT-2 structure with all of the important transformer parts:
- The system makes use of token embeddings to create vector representations which map every character to its corresponding realized vector.
- The system makes use of positional embeddings to indicate the mannequin the precise place of every token in a sequence.
- Multi-head self-attention permits all positions to view prior positions whereas merging completely different streams of knowledge.
- The attended data will get processed by means of feed-forward networks which use realized transformations to investigate the info.
The implementation makes use of ReLU² (squared ReLU) activation as a substitute of GeLU, and it eliminates bias phrases from the complete system, which makes the code simpler to grasp whereas sustaining its elementary components.
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id] # token embedding
pos_emb = state_dict['wpe'][pos_id] # place embedding
x = [t + p for t, p in zip(tok_emb, pos_emb)] # joint token and place embedding
x = rmsnorm(x)
for li in vary(n_layer):
# 1) Multi-head consideration block
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict[f'layer{li}.attn_wq'])
ok = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
keys[li].append(ok)
values[li].append(v)
x_attn = []
for h in vary(n_head):
hs = h * head_dim
q_h = q[hs:hs + head_dim]
k_h = [ki[hs:hs + head_dim] for ki in keys[li]]
v_h = [vi[hs:hs + head_dim] for vi in values[li]]
attn_logits = [
sum(q_h[j] * k_h[t][j] for j in vary(head_dim)) / head_dim**0.5
for t in vary(len(k_h))
]
attn_weights = softmax(attn_logits)
head_out = [
sum(attn_weights[t] * v_h[t][j] for t in vary(len(v_h)))
for j in vary(head_dim)
]
x_attn.lengthen(head_out)
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)]
# 2) MLP block
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() ** 2 for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)]
logits = linear(x, state_dict['lm_head'])
return logitsThe Coaching Loop: Studying in Motion
The coaching course of is refreshingly simple:
- The code processes every dataset doc by first changing its textual content into character ID tokens.
- The code processes every doc by first changing its textual content into character ID tokens after which sending these tokens by means of the mannequin for processing.
- The system calculates loss by means of its skill to foretell the upcoming character. The system performs backpropagation to acquire gradient values.
- The system makes use of the Adam optimizer to execute parameter updates.
The Adam optimizer itself is applied from scratch with correct bias correction and momentum monitoring. The optimization algorithm gives full transparency as a result of all its steps are seen with none hidden processes.
# Repeat in sequence
num_steps = 500 # variety of coaching steps
for step in vary(num_steps):
# Take single doc, tokenize it, encompass it with BOS particular token on each side
doc = docs[step % len(docs)]
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
n = min(block_size, len(tokens) - 1)
# Ahead the token sequence by means of the mannequin, build up the computation graph all the way in which to the loss.
keys, values = [[] for _ in vary(n_layer)], [[] for _ in vary(n_layer)]
losses = []
for pos_id in vary(n):
token_id, target_id = tokens[pos_id], tokens[pos_id + 1]
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # closing common loss over the doc sequence. Might yours be low.
# Backward the loss, calculating the gradients with respect to all mannequin parameters.
loss.backward()What Makes This a Gamechanger for Studying?
This implementation is pedagogical gold for a number of causes:
Full Transparency
The execution of hundreds of strains optimized C++ and CUDA code occurs while you use the mannequin.ahead() operate in PyTorch. The entire set of mathematical calculations seems in Python code which you’ll learn. Wish to know precisely how softmax works? How are consideration scores calculated? How gradients circulation by means of matrix multiplications? Each element seems in a clear method within the code.
No Dependencies, No Set up Hassles
The system operates with out requiring any dependencies whereas delivering simple set up procedures.
No conda environments, no CUDA toolkit, no model conflicts. Simply Python 3 and curiosity. You possibly can create a purposeful GPT coaching system by copying the code right into a file and working it. This removes each barrier between you and understanding.
Debuggable and Modifiable
You possibly can check the system by adjusting its consideration head rely. It’s good to change ReLU² with one other activation operate. The system permits you to add further layers. The system lets you change the training fee schedule by means of its settings. Your entire textual content will be learn and understood by all readers. The system lets you place print statements at any location all through this system to watch the precise values which circulation by means of the computation graph.
Actual Outcomes
The academic content material of this materials makes it appropriate for studying functions regardless of its management deficiencies. The mannequin demonstrates its skill to coach efficiently whereas producing comprehensible textual content output. The system learns to create life like names after it has been educated on a reputation database. The inference part makes use of temperature-based sampling to indicate how the mannequin generates inventive content material.
Getting Began: Operating Your Personal GPT
The great thing about this challenge is its simplicity. The challenge requires you to obtain the code from the GitHub repository or Karpathy’s web site and put it aside as microgpt.py. You should utilize the next command for execution.
python microgpt.py It reveals the method of downloading coaching knowledge whereas coaching the mannequin and creating textual content output. The system wants no digital environments and no pip installations and no configuration information. The system operates by means of untainted Python which performs unadulterated machine studying duties.
In case you’re within the full code, seek advice from Andrej Kaparthy’s Github repository.
Efficiency and Sensible Limitations
The present implementation reveals sluggish execution as a result of the applied system takes extreme time to finish its duties. The coaching course of on a CPU with pure Python requires:
- The system executes operations at a single cut-off date
- The system performs computations with out GPU assist
- The system makes use of pure Python math as a substitute of superior numerical libraries
The mannequin which trains in seconds with PyTorch requires three hours to finish the coaching course of. Your entire system capabilities as a check setting which lacks precise manufacturing code.
The academic code prioritizes readability for studying functions as a substitute of attaining quick execution. The method of studying to drive a handbook transmission system turns into like studying to drive an computerized transmission system. The method lets you really feel each gear shift whereas gaining full data concerning the transmission system.
Going deeper with Experimental Concepts
The code implementation course of requires you to first be taught the programming language. The experiments begin after you obtain code comprehension:
- Modify the structure: Add extra layers, change embedding dimensions, experiment with completely different consideration heads
- Attempt completely different datasets: Practice on code snippets, tune lyrics, or any textual content that pursuits you
- Implement new options: Add dropout, studying fee schedules, or completely different normalization schemes
- Debug gradient circulation: Add logging to see how gradients change throughout coaching
- Optimize efficiency: Take a look at the system with NumPy implementation and primary vectorization implementation whereas sustaining system efficiency
The code construction permits customers to conduct experiments with out issue. Your experiments will reveal the elemental ideas that govern transformer performance.
Conclusion
The 243-line GPT implementation within the identify of microGPT developed by Andrej Karpathy capabilities as greater than an algorithm as a result of it demonstrates Final coding excellence. The system reveals that understanding transformers requires just a few strains of important framework code. The system demonstrates that customers can perceive how consideration capabilities while not having high-cost GPU {hardware}. Customers want solely mainly constructing parts to develop their language modeling system.
The mixture of your curiosity with Python programming and your skill to grasp 243 strains of academic code creates your necessities for profitable studying. This implementation serves as an precise current for 3 completely different teams of individuals: college students, engineers, and researchers who need to find out about neural networks. The system gives you with essentially the most exact view of transformer structure out there throughout all places.
Obtain the file, learn the code, make modifications and even dismantle the complete course of and begin your individual model. The system will train you about GPT operation by means of its pure Python code base, which you’ll be taught one line at a time.
Continuously Requested Questions
A. It’s a pure Python GPT implementation that exposes core math and structure, serving to learners perceive transformers with out counting on heavy frameworks like PyTorch.
A. He implements autograd, the GPT structure, and the Adam optimizer completely in Python, exhibiting how coaching and backpropagation work step-by-step.
A. It runs on pure Python with out GPUs or optimized libraries, prioritizing readability and training over pace and manufacturing efficiency.
Knowledge Science Trainee at Analytics Vidhya
I’m at present working as a Knowledge Science Trainee at Analytics Vidhya, the place I give attention to constructing data-driven options and making use of AI/ML methods to resolve real-world enterprise issues. My work permits me to discover superior analytics, machine studying, and AI purposes that empower organizations to make smarter, evidence-based selections.
With a powerful basis in pc science, software program improvement, and knowledge analytics, I’m obsessed with leveraging AI to create impactful, scalable options that bridge the hole between expertise and enterprise.
📩 It’s also possible to attain out to me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}