
It is a visitor submit by Thomas Cardenas, Employees Software program Engineer at Ancestry, in partnership with AWS.
Ancestry, the worldwide chief in household historical past and shopper genomics, makes use of household bushes, historic data, and DNA to assist individuals on their journeys of non-public discovery. Ancestry has the most important assortment of household historical past data, consisting of 40 billion data. They serve greater than 3 million subscribers and have over 23 million individuals of their rising DNA community. Their clients can use this knowledge to find their household story.
Ancestry is proud to attach customers with their households previous and current. They assist individuals study extra about their very own identification by studying about their ancestors. Customers construct a household tree by which we floor related data, historic paperwork, photographs, and tales which may include particulars about their ancestors. These artifacts are surfaced by Hints. The Hints dataset is likely one of the most attention-grabbing datasets at Ancestry. It’s used to alert customers that potential new data is on the market. The dataset has a number of shards, and there are at present 100 billion rows being utilized by machine studying fashions and analysts. Not solely is the dataset massive, it additionally adjustments quickly.
On this submit, we share the very best practices that Ancestry used to implement an Apache Iceberg-based hints desk able to dealing with 100 billion rows with 7 million hourly adjustments. The optimizations coated right here resulted in price reductions of 75%.
Overview of answer
Ancestry’s Enterprise Information Administration (EDM) workforce confronted a vital problem—tips on how to present a unified, performant knowledge ecosystem that might serve numerous analytical workloads throughout monetary, advertising and marketing, and product analytics groups. The ecosystem wanted to assist every little thing from knowledge scientists coaching advice fashions to geneticists growing inhabitants research—all requiring entry to the identical Hints knowledge.
The ecosystem round Hints knowledge had been developed organically, with out a well-defined structure. Groups independently accessed Hints knowledge by direct service calls, Kafka subject subscriptions, or warehouse queries, creating vital knowledge duplication and pointless system load. To cut back price and enhance efficiency, EDM carried out a centralized Apache Iceberg knowledge lake on Amazon Easy Storage Service (Amazon S3), with Amazon EMR offering the processing energy. This structure, proven within the following picture, creates a single supply of reality for the Hints dataset whereas utilizing Iceberg’s ACID transactions, schema evolution, and partition evolution capabilities to deal with scale and replace frequency.
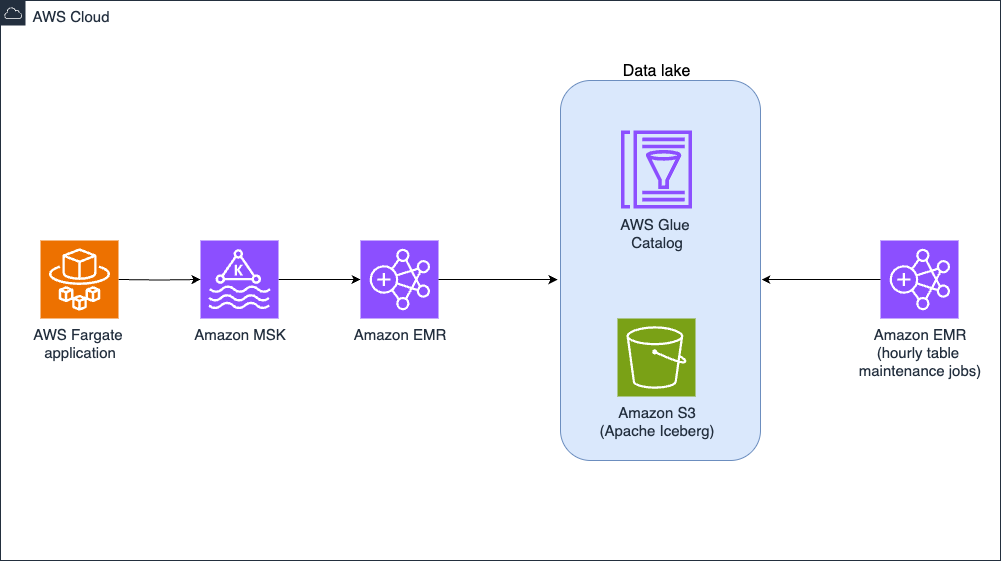
Hints desk administration structure
Managing datasets exceeding one billion rows presents distinctive challenges, and Ancestry confronted this problem with the bushes assortment of 20–100 billion rows throughout a number of tables. At this scale, dataset updates require cautious execution to manage prices and stop reminiscence points. To resolve these challenges, EDM selected Amazon EMR on Amazon EC2 working Spark to put in writing Iceberg tables on Amazon S3 for storage. With massive and regular Amazon EMR workloads, working the clusters on Amazon EC2, versus Serverless, proved price efficient. EDM has scheduled an Apache Spark job to run each hour on their Amazon EMR on EC2. This job makes use of the merge operation to replace the Iceberg desk with lately modified rows. Performing updates like this on such a big dataset can simply result in runaway prices and out-of-memory errors.
Key optimization strategies
The engineers wanted to allow quick, row-level updates with out impacting question efficiency or incurring substantial price. To realize this, Ancestry used a mix of partitioning methods, desk configurations, Iceberg procedures, and incremental updates. The next is roofed intimately:
- Partitioning
- Sorting
- Merge-on-read
- Compaction
- Snapshot administration
- Storage-partitioned joins
Partitioning technique
Creating an efficient partitioning technique was essential for the 100-billion-row Hints desk. Iceberg helps varied partition transforms together with column worth, temporal features (yr, month, day, hour), and numerical transforms (bucket, truncate). Following AWS greatest practices, Ancestry fastidiously analyzed question patterns to establish a partitioning strategy that might assist these queries whereas balancing these two competing concerns:
- Too few partitions would drive queries to scan extreme knowledge, degrading efficiency and rising prices.
- Too many partitions would create small recordsdata and extreme metadata, inflicting administration overhead and slower question planning. It’s typically greatest to keep away from parquet recordsdata smaller than 100 MB.
By means of question sample evaluation, Ancestry found that the majority analytical queries filtered on trace standing (notably pending standing) and trace kind. This perception led us to implement a two-level partitioning strategy-first on standing after which on kind, which dramatically lowered the quantity of knowledge scanned throughout typical queries.
Sorting
To additional optimize question efficiency, Ancestry carried out strategic knowledge group inside partitions utilizing Iceberg’s type orders. Whereas Iceberg doesn’t keep good ordering, even approximate sorting considerably improves knowledge locality and compression ratios.
For the Hints desk with 100 billion rows, Ancestry confronted a singular problem: the first identifiers (PersonId and HintId) are high-cardinality numeric columns that might be prohibitively costly to type fully. The answer makes use of Iceberg’s truncate rework perform to assist sorting on only a portion of the quantity, successfully creating one other partition by grouping a group of IDs collectively. For instance, we will specify truncate(100_000_000, hintId) to create teams of 100 million trace IDs, drastically enhancing the efficiency of queries that specify that column.
Merge on learn
With 7 million adjustments to the Hints desk occurring hourly, optimizing write efficiency grew to become vital to the structure. Along with ensuring queries carried out nicely, Ancestry additionally wanted to ensure our frequent updates would carry out nicely in each time and value. It was rapidly found that the default copy-on-write (CoW) technique, which copies a whole file when any a part of it adjustments, was too gradual and costly for his or her use case. Ancestry was capable of get the efficiency we wanted by as an alternative specifying the merge-on-read (MoR) replace technique, which maintains new data in diff recordsdata which can be reconciled on learn. The big updates that occur each hour led us to decide on sooner updates at the price of slower reads.
File compaction
The frequent updates imply recordsdata are continually needing to be re-written to take care of efficiency. Iceberg gives the rewrite_data_files process for compaction, however default configurations proved inadequate for our scale. Leaving the default configuration in place, the rewrite operation wrote to 5 partitions at a time and didn’t meet our efficiency goal. We discovered that rising the concurrent writes improved efficiency. We used the next set of parameters, setting a comparatively excessive max-concurrent-file-group-rewrites worth of 100 to extra effectively take care of our 1000’s of partitions. The default of rewriting just one file at a time couldn’t sustain with the frequency of our updates.
Key optimizations in Ancestry’s strategy embrace:
- Excessive concurrency: We elevated
max-concurrent-file-group-rewritesfrom the default 5 to 100, enabling parallel processing of our 1000’s of partitions. This elevated compute prices however was vital to assist be certain that the roles completed. - Resilience at scale: We enabled
partial-progressto create compaction checkpoints, important when working at our scale the place failures are notably expensive. - Complete delta elimination: Setting
rewrite-alltotruehelps be certain that each knowledge recordsdata and delete recordsdata are compacted, stopping the buildup of delete recordsdata. By default, the delete recordsdata created as a part of this technique aren’t re-written and would proceed to build up, slowing queries.
We arrived at these optimizations by successive trials and evaluations. For instance, with our very massive dataset, we found that we might use a WHERE clause to restrict re-writes to a single partition. Primarily based on the partitions, we see assorted execution instances and useful resource utilization. For some partitions, we wanted to cut back concurrency to keep away from working into out of reminiscence errors.
Snapshot administration
Iceberg tables keep snapshots to protect the historical past of the desk, permitting you to time journey by the adjustments. As these snapshots accrue, they add to storage prices and degrade efficiency. Because of this sustaining an Iceberg desk requires you to periodically name the expire_snapshots process. We discovered we wanted to allow concurrency for snapshot administration in order that it might full in a well timed method:
Think about tips on how to stability efficiency, price, and the necessity to maintain historic data relying in your use case. Once you achieve this, word that there’s a table-level setting for optimum snapshot age which may override the retain_last parameter and retain solely the lively snapshot.
Decreasing shuffle with Storage-Partitioned Joins
We use Storage-Partitioned Joins (SPJ) in Iceberg tables to reduce costly shuffles throughout knowledge processing. SPJ is a complicated Iceberg characteristic (accessible in Spark 3.3 or later with Iceberg 1.2 or later) that makes use of the bodily storage structure of tables to get rid of shuffle operations fully. For our Hints replace pipeline, this optimization was transformational.
SPJ is very helpful throughout MERGE INTO operations, the place datasets have equivalent partitioning. Correct configuration helps guarantee efficient use of SPJ to optimize joins.
SPJ has a couple of necessities similar to each tables have to be Iceberg partitioned the identical approach and joined on the partition key. Then Iceberg will know that it doesn’t must shuffle the information when the tables are loaded. This even works when there are a unique variety of partitions on both facet.
Updates to the Hints database are first staged within the Trace Adjustments database the place knowledge is reworked from the unique Kafka knowledge format into the way it will look within the goal (Hints) desk. It is a non permanent Iceberg desk the place we’re capable of carry out audits utilizing Write-Audit-Publish (WAP) sample. Along with utilizing the WAP sample we’re ready to make use of the SPJ performance.
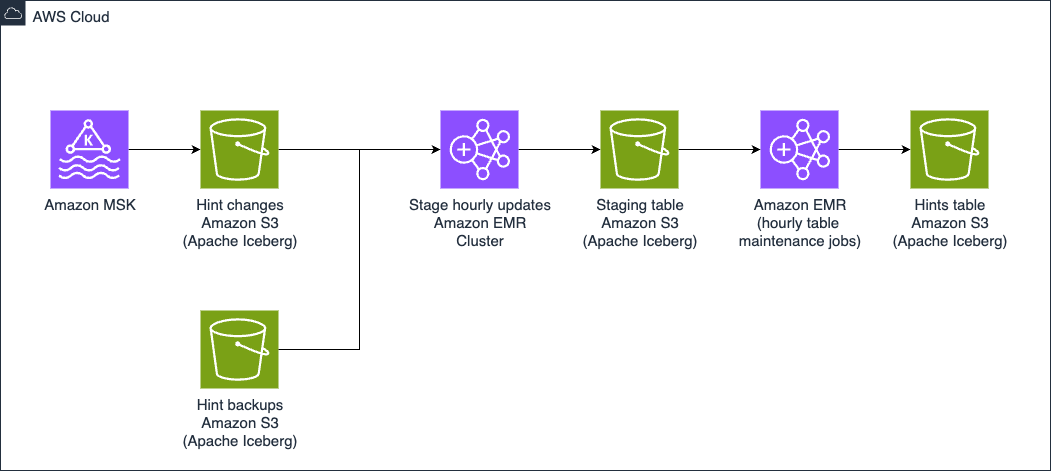
The Hints knowledge pipeline
Decreasing full-table scans
One other technique to cut back shuffle is minimizing the information concerned in joins by dynamically pushing down filters. In manufacturing, these filters fluctuate between batches, so a multi-step operation is commonly vital for establishing merges. The next instance code first limits its scope by setting minimal and most values for the ID, then performs an replace or delete to the goal desk relying on whether or not a goal worth exists.
This method reduces price in a number of methods: the bounded merge reduces the variety of affected rows, it permits for predicate pushdown optimization, which filters on the storage layer, and it reduces shuffle operations compared with a be a part of.
Extra insights
Other than the Hints desk, we’ve got carried out over 1,000 Iceberg tables in our knowledge ecosystem. The next are some key insights that we noticed:
- Updating a desk utilizing
MERGEis often the most costly motion, so that is the place we spent probably the most time optimizing. It was nonetheless our greatest choice. - Utilizing complicated knowledge varieties will help co-locate related knowledge within the desk.
- Monitor prices of every pipeline as a result of whereas following good follow you’ll be able to stumble throughout belongings you miss which can be inflicting prices to extend.
Conclusion
Organizations can use Apache Iceberg tables on Amazon S3 with Amazon EMR to handle huge datasets with frequent updates. Many purchasers will be capable to obtain glorious efficiency with a low upkeep burden by utilizing the AWS Glue desk optimizer for computerized, asynchronous compaction. Some clients, like Ancestry, would require customized optimizations of their upkeep procedures to fulfill their price and efficiency targets. These clients ought to begin with a cautious evaluation of question patterns to develop a partitioning technique to reduce the quantity of knowledge that must be learn and processed. Replace frequency and latency necessities will dictate different selections, like whether or not merge-on-read or copy-on-write is the higher technique.
In case your group faces related challenges with excessive volumes of knowledge requiring frequent updates, you should use a mix of Apache Iceberg’s superior options with AWS providers like Amazon EMR Serverless, Amazon S3, and AWS Glue to construct a really trendy knowledge lake that delivers the size, efficiency, and cost-efficiency you want.
Additional studying
In regards to the authors

{kind=link}