
Retrieval-Augmented Era, or RAG, marks an necessary step ahead for pure language processing. It helps massive language fashions (LLMs) carry out higher by letting them test info exterior their coaching information earlier than making a response. This implies LLMs can work properly with particular firm information or new info with out pricey retraining. Rerankers for RAG play a vital function in refining retrieved info, guaranteeing probably the most related context is offered. RAG blends info retrieval with textual content era, leading to correct, related solutions that sound pure.
Why Preliminary Retrieval Isn’t Sufficient
Step one in RAG includes discovering paperwork associated to a consumer’s question. Techniques typically use strategies like key phrase search or vector similarity. These strategies are good beginning factors, however they’ll return many paperwork that aren’t all equally helpful. The embedding fashions used may not grasp the high-quality particulars wanted to choose probably the most related info.
Vector search, which seems to be for comparable meanings, can battle with brief queries or specialised phrases. Additionally, LLMs have limits on how a lot context they’ll deal with properly. Feeding them too many paperwork, even barely related ones, can confuse the mannequin and decrease the standard of the ultimate reply. This preliminary “noisy” retrieval can dilute the LLM’s focus. We want a option to refine this primary batch of data.

This picture depicts the retrieval and era steps of RAG, a query is requested by the consumer after which our system extracts the outcomes based mostly on the query by looking out the Vector retailer. Then the retrieved content material is handed to the LLM together with the query and LLM supplies a structured output.
Enter Rerankers: Refining the Search
That is the place rerankers change into important. Reranking improves the precision of search outcomes. Rerankers use good algorithms to have a look at the initially retrieved paperwork and reorder them based mostly on how properly they match the consumer’s particular query and intent.
In RAG, rerankers act as a high quality filter. They study the primary set of outcomes and prioritize the paperwork that supply the most effective info for the question. The objective is to raise probably the most related items to the highest. Consider a reranker as a specialist that double-checks the preliminary search, utilizing a deeper understanding of language to seek out the most effective match between the paperwork and the query.

This picture illustrates a two-stage search course of. Reranking is the second stage, the place an preliminary set of search outcomes, based mostly on semantic or key phrase matching, is refined to considerably enhance the relevance and ordering of the ultimate outcomes, delivering a extra correct and helpful consequence for the consumer’s question.
How Reranking Improves RAG
Rerankers enhance the accuracy of the context given to the LLM. They analyze the that means and relationship between the consumer’s query and every retrieved doc, going past easy key phrase matching. This deeper understanding helps determine probably the most helpful info.
By focusing the LLM on a smaller, higher set of paperwork, rerankers result in extra exact solutions. The LLM will get high-quality context, permitting it to kind extra knowledgeable and direct responses. Rerankers calculate a rating displaying how semantically shut a doc is to a question, permitting for a greater ultimate ordering. They will discover related info even with out actual key phrase matches.
This concentrate on high quality context helps scale back LLM “hallucinations”—cases the place the mannequin generates incorrect however believable info. Grounding the LLM in paperwork verified by a reranker makes the ultimate output extra reliable.
The usual RAG course of includes retrieval then era. An enhanced RAG pipeline provides a reranking step within the center.
- Retrieve: Fetch an preliminary set of candidate paperwork.
- Rerank: Use a reranking mannequin to reorder these paperwork based mostly on relevance to the question.
- Generate: Present solely the top-ranked, most related paperwork to the LLM to create the reply.
This two-stage technique lets the preliminary retrieval forged a large internet (recall), whereas the reranker focuses on choosing the most effective gadgets from that internet (precision). This division improves the general course of and provides the LLM the very best enter.

A question is used to look a vector database, retrieving the highest 25 most related paperwork. These paperwork are then handed to a “Reranker” module. The reranker refines the outcomes, choosing the highest 3 most related paperwork for the ultimate output.
High Reranking Fashions in 2025
Allow us to look into the highest reranking fashions in 2025.
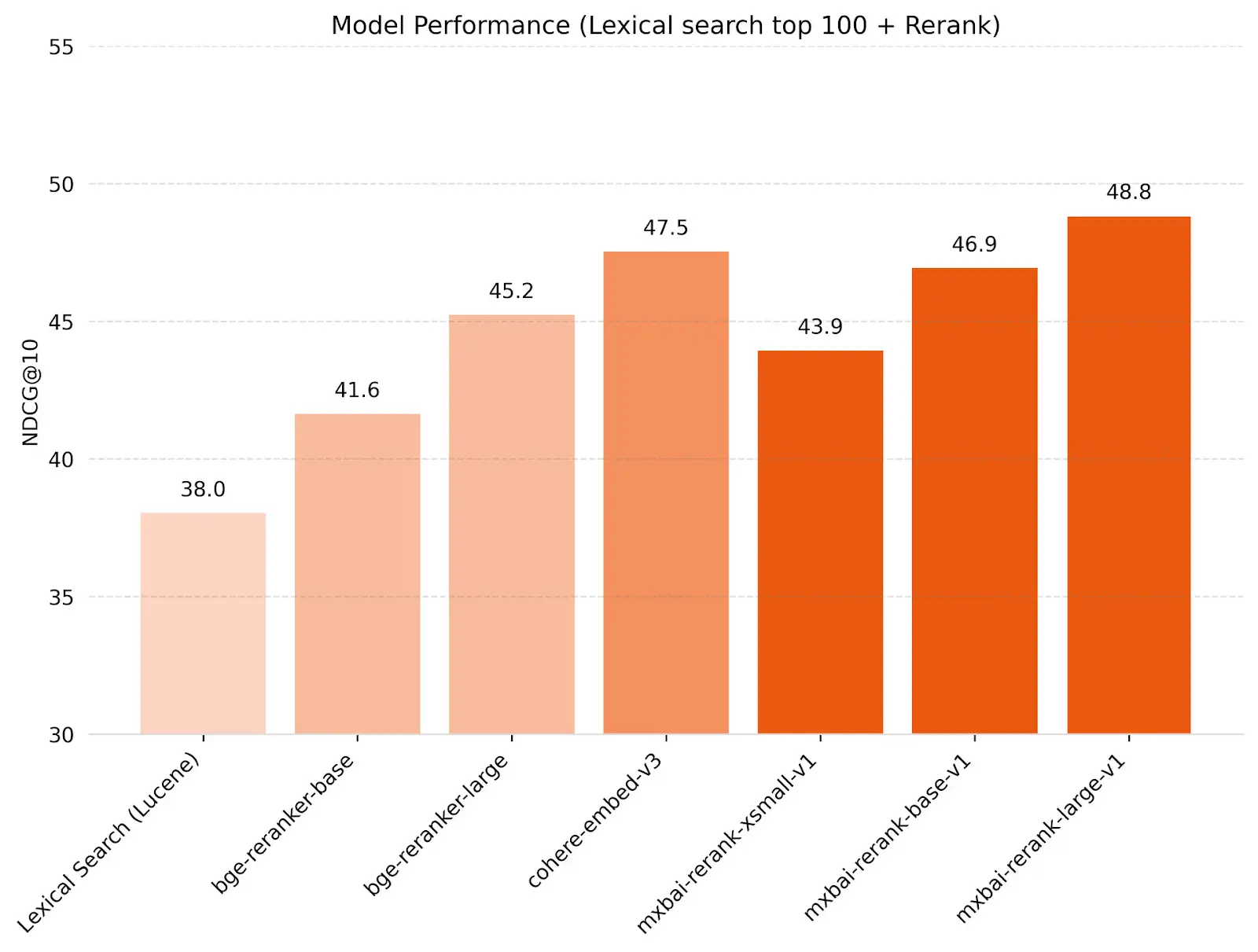
Supply: Click on Right here
A number of reranking fashions are common selections for RAG pipelines:
| Reranker | Mannequin Kind | Supply | Energy | Weak spot | Finest For |
| Cohere | Cross-encoder( API) | Non-public | Excessive Accuracy, Multilingual, Ease of Use, Velocity (Nimble) | Price (API charges), Closed-source | Normal RAG, Enterprise, Multilingual, Ease of Use |
| bge-reranker | Cross-encoder | Open-Supply | Excessive Accuracy, Open-source, Runs on average {hardware} | Requires self-hosting | Normal RAG, Open-source choice, Funds-conscious |
| Voyage | Cross-encoder( API) | Non-public | High-tier Relevance/Accuracy | Price (API charges), Probably larger latency (high mannequin) | Max Accuracy Wants (Finance, Authorized), Relevance-critical apps |
| Jina | Cross-encoder / ColBERT variant | Combined | Balanced Efficiency, Price-effective, Lengthy Docs (Jina-ColBERT) | Might not attain peak accuracy | Normal RAG, Lengthy paperwork, Balanced value/efficiency |
| FlashRank | Light-weight Cross-encoder | Open-Supply | Very Quick, Low Useful resource Use, Simple Integration | Accuracy decrease than massive fashions | Velocity-critical apps, Useful resource-constrained environments |
| ColBERT | Multi-vector (Late Interplay) | Open-Supply | Environment friendly at Scale (Massive Collections), Quick Retrieval | Indexing compute/storage intensive | Very massive doc units, Effectivity at scale |
| MixedBread (mxbai-rerank-v2) | Cross-encoder | Open-Supply | SOTA Perf (claimed), Quick Inference, Multilingual, Lengthy Context, Versatile | Requires self-hosting, Comparatively new | Excessive-Efficiency RAG, Multilingual, Lengthy Docs/Code/JSON, Open-Supply Pref |
Cohere Rerank
Cohere Rerank makes use of a classy neural community, doubtless based mostly on the transformer structure, appearing as a cross-encoder. It processes the question and doc collectively to exactly choose relevance. It’s a proprietary mannequin accessed by way of an API.
- Key Options: A significant characteristic is its help for over 100 languages, making it versatile for international purposes. It integrates simply as a hosted service. Cohere additionally gives “Rerank 3 Nimble,” a model designed for considerably sooner efficiency in manufacturing environments whereas retaining excessive accuracy.
- Efficiency: Cohere Rerank constantly delivers excessive accuracy throughout varied embedding fashions used within the preliminary retrieval step. The Nimble variant reduces response time significantly. Prices rely upon API utilization.
- Strengths: Simple integration by way of API, sturdy and dependable efficiency, wonderful multilingual capabilities, and a speed-optimized choice (Nimble).
- Weaknesses: It’s a closed-source, business service, so that you pay per use and can’t modify the mannequin.
- Supreme Use Circumstances: Good for basic RAG purposes, enterprise search platforms, buyer help chatbots, and conditions needing broad language help with out managing mannequin infrastructure.
Instance Code
First set up the Cohere library.
%pip set up --upgrade --quiet cohereArrange the Cohere and ContextualCompressionRetriever.
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
from langchain.chains import RetrievalQA
llm = Cohere(temperature=0)
compressor = CohereRerank(mannequin="rerank-english-v3.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
chain = RetrievalQA.from_chain_type(
llm=Cohere(temperature=0), retriever=compression_retriever
)Output:
{'question': 'What did the president say about Ketanji Brown Jackson',
'outcome': " The president speaks extremely of Ketanji Brown Jackson, stating that she
is likely one of the nation's high authorized minds, and can proceed the legacy of excellence
of Justice Breyer. The president additionally mentions that he labored together with her household and
that she comes from a household of public college educators and law enforcement officials. Since
her nomination, she has acquired help from varied teams, together with the
Fraternal Order of Police and judges from each main political events. nnWould
you want me to extract one other sentence from the offered textual content? "}
bge-reranker (Base/Massive)
These fashions come from the Beijing Academy of Synthetic Intelligence (BAAI) and are open-source (Apache 2.0 license). They’re transformer-based, doubtless cross-encoders, designed particularly for reranking duties. They’re out there in numerous sizes, like Base and Massive.
- Key Options: Being open-source provides customers freedom to deploy and modify them. The bge-reranker-v2-m3 mannequin, for instance, has underneath 600 million parameters, permitting it to run effectively on widespread {hardware}, together with client GPUs.
- Efficiency: These fashions carry out very properly, particularly the big variations, typically attaining outcomes near high business fashions. They display sturdy Imply Reciprocal Rank (MRR) scores. The fee is primarily the compute assets wanted for self-hosting.
- Strengths: No licensing charges (open-source), sturdy accuracy, flexibility for self-hosting, and good efficiency even on average {hardware}.
- Weaknesses: Requires customers to handle deployment, infrastructure, and updates. Efficiency will depend on the internet hosting {hardware}.
- Supreme Use Circumstances: Appropriate for basic RAG duties, analysis tasks, groups preferring open-source instruments, budget-aware purposes, and customers comfy with self-hosting.
Instance Code
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
mannequin = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
compressor = CrossEncoderReranker(mannequin=mannequin, top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke("What's the plan for the financial system?")
pretty_print_docs(compressed_docs)Output:
Doc 1:
Extra infrastructure and innovation in America.
Extra items shifting sooner and cheaper in America.
Extra jobs the place you possibly can earn a very good residing in America.
And as an alternative of counting on overseas provide chains, let’s make it in America.
Economists name it “rising the productive capability of our financial system.”
I name it constructing a greater America.
My plan to combat inflation will decrease your prices and decrease the deficit.----------------------------------------------------------------------------------------------------
Doc 2:
Second – reduce power prices for households a median of $500 a yr by combatting
local weather change.Let’s present investments and tax credit to weatherize your properties and companies to
be power environment friendly and also you get a tax credit score; double America’s clear power
manufacturing in photo voltaic, wind, and a lot extra; decrease the value of electrical autos,
saving you one other $80 a month since you’ll by no means need to pay on the gasoline pump
once more.----------------------------------------------------------------------------------------------------
Doc 3:
Have a look at vehicles.
Final yr, there weren’t sufficient semiconductors to make all of the vehicles that folks
wished to purchase.
And guess what, costs of cars went up.
So—now we have a alternative.
One option to combat inflation is to drive down wages and make People poorer.
I've a greater plan to combat inflation.
Decrease your prices, not your wages.
Make extra vehicles and semiconductors in America.
Extra infrastructure and innovation in America.
Extra items shifting sooner and cheaper in America.
Voyage Rerank
Voyage AI supplies proprietary neural community fashions (voyage-rerank-2, voyage-rerank-2-lite) accessed by way of API. These are doubtless superior cross-encoders finely tuned for max relevance scoring.
- Key Options: Their important distinction is attaining top-tier relevance scores in benchmark exams. Voyage supplies a easy Python consumer library for straightforward integration. The lite model gives a stability between efficiency and pace/value.
- Efficiency: voyage-rerank-2 typically leads benchmarks by way of pure relevance accuracy. The lite mannequin performs comparably to different sturdy contenders. The high-accuracy rerank-2 mannequin may need barely larger latency than some rivals. Prices are tied to API utilization.
- Strengths: State-of-the-art relevance, doubtlessly probably the most correct choice out there. Simple to make use of by way of their Python consumer.
- Weaknesses: Proprietary API-based service with related prices. The best accuracy mannequin is perhaps marginally slower than others.
- Supreme Use Circumstances: Finest suited to purposes the place maximizing relevance is vital, comparable to monetary evaluation, authorized doc evaluation, or high-stakes query answering the place accuracy outweighs slight pace variations.
Instance Code
First set up the voyage library
%pip set up --upgrade --quiet voyageai
%pip set up --upgrade --quiet langchain-voyageaiArrange the Cohere and ContextualCompressionRetriever
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.retrievers import ContextualCompressionRetriever
from langchain_openai import OpenAI
from langchain_voyageai import VoyageAIRerank
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_voyageai import VoyageAIEmbeddings
paperwork = TextLoader("../../how_to/state_of_the_union.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(paperwork)
retriever = FAISS.from_documents(
texts, VoyageAIEmbeddings(mannequin="voyage-law-2")
).as_retriever(search_kwargs={"okay": 20})
llm = OpenAI(temperature=0)
compressor = VoyageAIRerank(
mannequin="rerank-lite-1", voyageai_api_key=os.environ["VOYAGE_API_KEY"], top_k=3
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)Output:
Doc 1:One of the vital severe constitutional obligations a President has is
nominating somebody to serve on the USA Supreme Court docket.
And I did that 4 days in the past, once I nominated Circuit Court docket of Appeals Decide Ketanji
Brown Jackson. One in all our nation’s high authorized minds, who will proceed Justice
Breyer’s legacy of excellence.----------------------------------------------------------------------------------------------------
Doc 2:
So let’s not abandon our streets. Or select between security and equal justice.
Let’s come collectively to guard our communities, restore belief, and maintain regulation
enforcement accountable.
That’s why the Justice Division required physique cameras, banned chokeholds, and
restricted no-knock warrants for its officers.----------------------------------------------------------------------------------------------------
Doc 3:
I spoke with their households and advised them that we're endlessly in debt for his or her
sacrifice, and we'll keep on their mission to revive the belief and security each
neighborhood deserves.I’ve labored on these points a very long time.
I do know what works: Investing in crime prevention and neighborhood law enforcement officials
who’ll stroll the beat, who’ll know the neighborhood, and who can restore belief and
security.So let’s not abandon our streets. Or select between security and equal justice.
Jina Reranker
This gives reranking options together with neural fashions like Jina Reranker v2 and Jina-ColBERT. Jina Reranker v2 is probably going a cross-encoder fashion mannequin. Jina-ColBERT implements the ColBERT structure (defined subsequent) utilizing Jina’s base fashions.
- Key Options: Jina supplies cost-effective choices with good efficiency. A standout characteristic is Jina-ColBERT’s means to deal with very lengthy paperwork, supporting context lengths as much as 8,000 tokens. This reduces the necessity to aggressively chunk lengthy texts. Open-source parts are additionally a part of Jina’s ecosystem.
- Efficiency: Jina Reranker v2 gives a very good mixture of pace, value, and relevance. Jina-ColBERT excels when coping with lengthy supply paperwork. Prices are usually aggressive.
- Strengths: Balanced efficiency, cost-effective, wonderful dealing with of lengthy paperwork by way of Jina-ColBERT, flexibility with out there open-source elements.
- Weaknesses: Normal Jina rerankers may not hit absolutely the peak accuracy of specialised fashions like Voyage’s high tier.
- Supreme Use Circumstances: Normal RAG methods, purposes processing lengthy paperwork (technical manuals, analysis papers, books), tasks needing a very good stability between value and efficiency.
Instance Code
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import JinaEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
paperwork = TextLoader(
"../../how_to/state_of_the_union.txt",
).load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(paperwork)
embedding = JinaEmbeddings(model_name="jina-embeddings-v2-base-en")
retriever = FAISS.from_documents(texts, embedding).as_retriever(search_kwargs={"okay": 20})
question = "What did the president say about Ketanji Brown Jackson"
docs = retriever.get_relevant_documents(question)Doing Reranking with JIna
from langchain.retrievers import ContextualCompressionRetriever
from langchain_community.document_compressors import JinaRerank
compressor = JinaRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)Output:
Doc 1:So let’s not abandon our streets. Or select between security and equal justice.
Let’s come collectively to guard our communities, restore belief, and maintain regulation
enforcement accountable.
That’s why the Justice Division required physique cameras, banned chokeholds, and
restricted no-knock warrants for its officers.----------------------------------------------------------------------------------------------------
Doc 2:
I spoke with their households and advised them that we're endlessly in debt for his or her
sacrifice, and we'll keep on their mission to revive the belief and security each
neighborhood deserves.
I’ve labored on these points a very long time.
I do know what works: Investing in crime prevention and neighborhood law enforcement officials
who’ll stroll the beat, who’ll know the neighborhood, and who can restore belief and
security.
So let’s not abandon our streets. Or select between security and equal justice.
ColBERT
ColBERT (Contextualized Late Interplay over BERT) is a multi-vector mannequin. As an alternative of representing a doc with one vector, it creates a number of contextualized vectors (typically one per token). It makes use of a “late interplay” mechanism the place question vectors are in contrast in opposition to the numerous doc vectors after encoding. This enables doc vectors to be pre-calculated and listed.
- Key Options: Its structure permits for very environment friendly retrieval from massive collections as soon as paperwork are listed. The multi-vector method permits fine-grained comparisons between question phrases and doc content material. It’s an open-source method.
- Efficiency: ColBERT gives a robust stability between retrieval effectiveness and effectivity, particularly at scale. Retrieval latency is low after the preliminary indexing step. The primary value is compute for indexing and self-hosting.
- Strengths: Extremely environment friendly for big doc units, scalable retrieval, open-source flexibility.
- Weaknesses: The preliminary indexing course of will be computationally intensive and require vital storage.
- Supreme Use Circumstances: Massive-scale RAG purposes, methods needing quick retrieval over tens of millions or billions of paperwork, situations the place pre-computation time is appropriate.
Instance Code
Set up the Ragtouille library for utilizing ColBERT reranker.
pip set up -U ragatouilleNow setting the up the ColBERT reranker
from ragatouille import RAGPretrainedModel
from langchain.retrievers import ContextualCompressionRetriever
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=RAG.as_langchain_document_compressor(), base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What animation studio did Miyazaki discovered"
)
print(compressed_docs[0])Output:
Doc(page_content="In June 1985, Miyazaki, Takahata, Tokuma and Suzuki based
the animation manufacturing firm Studio Ghibli, with funding from Tokuma Shoten.
Studio Ghibli"s first movie, Laputa: Fort within the Sky (1986), employed the identical
manufacturing crew of Nausicaä. Miyazaki's designs for the movie's setting have been
impressed by Greek structure and "European urbanistic templates". A number of the
structure within the movie was additionally impressed by a Welsh mining city; Miyazaki
witnessed the mining strike upon his first', metadata={'relevance_score':
26.5194149017334})
FlashRank
FlashRank is designed as a really light-weight and quick reranking library, sometimes leveraging smaller, optimized transformer fashions (typically distilled or pruned variations of bigger fashions). It goals to supply vital relevance enhancements over easy similarity search with minimal computational overhead. It features like a cross-encoder however makes use of methods to speed up the method. It’s normally out there as an open-source Python library.
- Key Options: Its major characteristic is pace and effectivity. It’s designed for straightforward integration and low useful resource consumption (CPU or average GPU utilization). It typically requires minimal code to implement.
- Efficiency: Whereas not reaching the height accuracy of the biggest cross-encoders like Cohere or Voyage, FlashRank goals to ship substantial features over no reranking or fundamental bi-encoder reranking. Its pace makes it appropriate for real-time or high-throughput situations. Price is minimal (compute for self-hosting).
- Strengths: Very quick inference pace, low computational necessities, straightforward to combine, open-source.
- Weaknesses: Accuracy is perhaps decrease than bigger, extra complicated reranking fashions. Mannequin selections is perhaps extra restricted in comparison with broader frameworks.
- Supreme Use Circumstances: Purposes needing fast reranking on resource-constrained {hardware} (like CPUs or edge gadgets), high-volume search methods the place latency is vital, tasks searching for a easy “better-than-nothing” reranking step with minimal complexity.
Instance Code
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import FlashrankRerank
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
compressor = FlashrankRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
print([doc.metadata["id"] for doc in compressed_docs])
pretty_print_docs(compressed_docs)This code snippet makes use of FlashrankRerank inside a ContextualCompressionRetriever to enhance the relevance of retrieved paperwork. It particularly reranks paperwork obtained by a base retriever (represented by a retriever) based mostly on their relevance to the question “What did the president say about Ketanji Jackson Brown”. Lastly, it prints the doc IDs and the compressed, reranked paperwork.
Output:
[0, 5, 3]Doc 1:
One of the vital severe constitutional obligations a President has is
nominating somebody to serve on the USA Supreme Court docket.
And I did that 4 days in the past, once I nominated Circuit Court docket of Appeals Decide Ketanji
Brown Jackson. One in all our nation’s high authorized minds, who will proceed Justice
Breyer’s legacy of excellence.
----------------------------------------------------------------------------------------------------Doc 2:
He met the Ukrainian folks.
From President Zelenskyy to each Ukrainian, their fearlessness, their braveness,
their willpower, conjures up the world.
Teams of residents blocking tanks with their our bodies. Everybody from college students to
retirees academics turned troopers defending their homeland.
On this battle as President Zelenskyy mentioned in his speech to the European
Parliament “Gentle will win over darkness.” The Ukrainian Ambassador to the United
States is right here tonight.
----------------------------------------------------------------------------------------------------Doc 3:
And tonight, I’m asserting that the Justice Division will identify a chief prosecutor
for pandemic fraud.
By the top of this yr, the deficit can be all the way down to lower than half what it was
earlier than I took workplace.
The one president ever to chop the deficit by multiple trillion {dollars} in a
single yr.
Reducing your prices additionally means demanding extra competitors.
I’m a capitalist, however capitalism with out competitors isn’t capitalism
It’s exploitation—and it drives up costs.
The output footwear it reranks the retrieved chunks based mostly on the relevancy.
MixedBread
Offered by Mixedbread AI, this household contains mxbai-rerank-base-v2 (0.5B parameters) and mxbai-rerank-large-v2 (1.5B parameters). They’re open-source (Apache 2.0 license) cross-encoders based mostly on the Qwen-2.5 structure. A key differentiator is their coaching course of, which includes a three-stage reinforcement studying (RL) method (GRPO, Contrastive Studying, Choice Studying) on high of preliminary coaching.
- Key Options: Claims state-of-the-art efficiency throughout benchmarks (like BEIR). Helps over 100 languages. Handles lengthy contexts as much as 8k tokens (and is suitable with 32k). Designed to work properly with numerous information varieties together with textual content, code, JSON, and for LLM device choice. Out there by way of Hugging Face and a Python library.
- Efficiency: Benchmarks revealed by Mixedbread present these fashions outperforming different high open-source and closed-source rivals like Cohere and Voyage on BEIR (Massive attaining 57.49, Base 55.57). In addition they display vital pace benefits, with the 1.5B parameter mannequin being notably sooner than different massive open-source rerankers in latency exams. Price is compute assets for self-hosting.
- Strengths: Excessive benchmark efficiency (claimed SOTA), open-source license, quick inference pace relative to accuracy, broad language help, very lengthy context window, versatile throughout information varieties (code, JSON).
- Weaknesses: Requires self-hosting and infrastructure administration. As comparatively new fashions, long-term efficiency and neighborhood vetting are ongoing.
- Supreme Use Circumstances: Normal RAG needing top-tier efficiency, multilingual purposes, methods coping with code, JSON, or lengthy paperwork, LLM device/perform calling choice, groups preferring high-performing open-source fashions.
Instance Code
!pip set up mxbai_rerank
from mxbai_rerank import MxbaiRerankV2
# Load the mannequin, right here we use our base sized mannequin
mannequin = MxbaiRerankV2("mixedbread-ai/mxbai-rerank-base-v2")
# Instance question and paperwork
question = "Who wrote To Kill a Mockingbird?"
paperwork = ["To Kill a Mockingbird is a novel by Harper Lee published in 1960. It was immediately successful, winning the Pulitzer Prize, and has become a classic of modern American literature.",
"The novel Moby-Dick was written by Herman Melville and first published in 1851. It is considered a masterpiece of American literature and deals with complex themes of obsession, revenge, and the conflict between good and evil.",
"Harper Lee, an American novelist widely known for her novel To Kill a Mockingbird, was born in 1926 in Monroeville, Alabama. She received the Pulitzer Prize for Fiction in 1961.",
"Jane Austen was an English novelist known primarily for her six major novels, which interpret, critique and comment upon the British landed gentry at the end of the 18th century.",
"The Harry Potter series, which consists of seven fantasy novels written by British author J.K. Rowling, is among the most popular and critically acclaimed books of the modern era.",
"The Great Gatsby, a novel written by American author F. Scott Fitzgerald, was published in 1925. The story is set in the Jazz Age and follows the life of millionaire Jay Gatsby and his pursuit of Daisy Buchanan."
]
# Calculate the scores
outcomes = mannequin.rank(question, paperwork)
print(outcomes)Output:
[RankResult(index=0, score=9.847987174987793, document="To Kill a Mockingbird is a
novel by Harper Lee published in 1960. It was immediately successful, winning the
Pulitzer Prize, and has become a classic of modern American literature."),RankResult(index=2, score=8.258672714233398, document="Harper Lee, an American
novelist widely known for her novel To Kill a Mockingbird, was born in 1926 in
Monroeville, Alabama. She received the Pulitzer Prize for Fiction in 1961."),RankResult(index=3, score=3.579845428466797, document="Jane Austen was an English
novelist known primarily for her six major novels, which interpret, critique and
comment upon the British landed gentry at the end of the 18th century."),RankResult(index=4, score=2.716982841491699, document="The Harry Potter series,
which consists of seven fantasy novels written by British author J.K. Rowling, is
among the most popular and critically acclaimed books of the modern era."),RankResult(index=1, score=2.233165740966797, document="The novel Moby-Dick was
written by Herman Melville and first published in 1851. It is considered a
masterpiece of American literature and deals with complex themes of obsession,
revenge, and the conflict between good and evil."),RankResult(index=5, score=1.8150043487548828, document="The Great Gatsby, a novel
written by American author F. Scott Fitzgerald, was published in 1925. The story is
set in the Jazz Age and follows the life of millionaire Jay Gatsby and his pursuit
of Daisy Buchanan.")]
Learn how to Inform if Your Reranker is Working
Evaluating rerankers is necessary. Frequent metrics assist measure their effectiveness:
- Accuracy@okay: How typically a related doc seems within the high okay outcomes.
- Precision@okay: The proportion of related paperwork inside the high okay outcomes.
- Recall@okay: The fraction of all related paperwork discovered inside the high okay outcomes.
- Normalized Discounted Cumulative Acquire (NDCG): Measures rating high quality by contemplating each relevance and place. Larger-ranked related paperwork contribute extra to the rating. It’s normalized (0 to 1), permitting comparisons.
- Imply Reciprocal Rank (MRR): Focuses on the rank of the primary related doc discovered. It’s the typical of 1/rank throughout a number of queries. Helpful when discovering one good outcome shortly is necessary.
- F1-score: The harmonic imply of precision and recall, providing a balanced view.
Selecting the Proper Reranker for Your Wants
Selecting the right reranker includes balancing a number of components:
- Relevance Wants: How correct do the outcomes have to be on your software?
- Latency: How shortly should the reranker return outcomes? Velocity is essential for real-time purposes.
- Scalability: Can the mannequin deal with your present and future information quantity and consumer load?
- Integration: How simply does the reranker match into your current RAG pipeline (embedding fashions, vector database, LLM framework)?
- Area Specificity: Do you want a mannequin educated on information particular to your area?
- Price: Think about API charges for personal fashions or computing prices for self-hosted ones.
There are trade-offs:
- Cross-encoders supply excessive precision however are slower.
- Bi-encoders are sooner and scalable however is perhaps barely much less exact.
- LLM-based rerankers will be extremely correct however costly and sluggish.
- Multi-vector fashions purpose for a stability.
- Rating-based strategies are quickest however could lack semantic depth.
To decide on correctly:
- Outline your objectives for accuracy and pace.
- Analyze your information traits (dimension, area).
- Consider totally different fashions in your information utilizing metrics like NDCG and MRR.
- Think about integration ease and finances.
The very best reranker matches your particular efficiency, effectivity, and price necessities.
Conclusion
Rerankers for RAG are very important for getting probably the most out of RAG methods. They refine the data given to LLMs, main to raised, extra reliable solutions. With varied fashions out there, from extremely exact cross-encoders to environment friendly bi-encoders and specialised choices like ColBERT, builders have selections. Choosing the proper one requires understanding the trade-offs between accuracy, pace, scalability, and price. As RAG evolves, particularly in direction of dealing with numerous information varieties, rerankers for RAG will proceed to play a vital function in constructing smarter, extra dependable AI purposes. Cautious analysis and choice stay key to success.
Steadily Requested Questions
A. RAG is a way that improves massive language fashions (LLMs) by permitting them to retrieve exterior info earlier than producing responses. This makes them extra correct, adaptable, and capable of incorporate new information with out retraining.
A. Preliminary retrieval strategies like key phrase search or vector similarity can return many paperwork, however not all are extremely related. This will result in noisy inputs that scale back LLM efficiency. Refining these outcomes is critical to enhance reply high quality.
A. Rerankers reorder retrieved paperwork based mostly on their relevance to the question. They act as a high quality filter, guaranteeing probably the most related info is prioritized earlier than being handed to the LLM for reply era.
A. Cohere Rerank supplies excessive accuracy, multilingual help, and API-based integration. Its “Nimble” variant is optimized for sooner responses, making it very best for real-time purposes.
A. bge-reranker is open-source and will be self-hosted, decreasing prices whereas sustaining excessive accuracy. It’s appropriate for groups that desire full management over their fashions.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (in order that they don’t substitute him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.

{kind=link}