
We now have been listening to the time period AGI for some time now. Nonetheless, the vast majority of the best-performing LLMs are nonetheless not very adept at resolving difficult issues, not to mention reaching AGI. These are some points that take a variety of effort and time to resolve, even for us people. To unravel such advanced puzzles, we should be capable to determine patterns, generate summary information, and enhance our reasoning with every iteration. We are going to now examine a mannequin referred to as the “Hierarchical Reasoning Mannequin,” which has gained consideration within the subject of AI analysis and outperformed a number of well-known LLMs, together with GPT-5, Deepseek R1, Claude’s Opus 4, and OpenAI’s o3 mannequin. This text will go over what HRMs are and why they’re pushing the envelope with regards to AGI.
The Present Drawback
For duties requiring reasoning, virtually the entire transformer fashions in use in the present day depend on CoT (Chain of Thought). Right here, we’ll be giving the mannequin enter, and it’ll produce related tokens that show the pure language reasoning course of (much like the one we see in DeepSeek). This course of continues till it involves a ultimate level. The price for producing such a prolonged thought hint can be larger as a result of iterating repeatedly and making a number of ahead passes will increase the context window, which slows down the method whereas consuming a variety of knowledge.
By breaking down the issue into smaller intermediate steps, these pure language reasoning steps enable the mannequin to carry out multi-step advanced reasoning. However there may be additionally a major drawback to this sort of Tree of Thought reasoning course of. If an error is made at the start or in the course of the method, it could propagate to the next levels and consequence within the incorrect reply being outputted.
Learn extra: Chain-of-Although Prompting
What’s occurring
Nearly all of processes have this sort of structure, by which the mannequin can embrace a number of transformer blocks. As is broadly recognised, every block is actually a typical causal attention-based transformer which mixes multi-head consideration with RoPE embeddings. a feed-forward community, normalisation layers, and residual connections.
The plot above compares the efficiency of transformers as their sizes are elevated, first by scaling the width after which by scaling the depth with further layers. This demonstrates the numerous benefits of larger depth. Nonetheless, after a sure variety of parameters, transformer efficiency doesn’t improve or saturate from this elevated depth.
So, there was a specific answer to this difficulty. Right here, we’ll be making use of the recurrent community. Through the use of recurrent blocks, we are able to effectively obtain arbitrary depth on this recurrent community structure, the place every block reuses the identical set of parameters. since quite a few steps are concerned in the identical computation. Nonetheless, the mannequin might progressively lose consciousness of our downside assertion because the hidden representations are modified over a number of iterations (much like catastrophic forgetting).
Our mannequin should perceive the preliminary enter to fight this difficulty. This may be completed, for instance, by injecting the embedded enter knowledge into every iteration’s recurrent block. That is additionally known as recall or enter injection in loop transformers. This makes it simpler to remain totally conscious of the unique context of the issue whereas utilizing reasoning.
We will see right here how recurrent-based transformers work higher than conventional transformers. We additionally get to see that by rising the variety of iterations within the recurrent community, efficiency ultimately drops because the fashions get deeper.
Now we have now understood the earlier points we encountered with regards to reasoning-based duties. Now, let’s soar into how HRMs work and counter these shortcomings.
What’s HRM?
HRM was impressed by biology, because the human mind has a cross-frequency that {couples} between theta and gamma neural frequencies. Its twin recurrent loop system is HRM’s major innovation. Primarily based on the likelihood of the following phrase from earlier tokens, regular transformers are made to foretell the following token. In distinction, two completely different recurrent neural networks are utilized by HRM to generate tokens.
Right here, the HRM goes to have interaction in a cognitive course of by pondering shortly at decrease ranges whereas additionally receiving steerage from larger ranges which might be slower and extra summary than the decrease ranges. That is basically the inspiration that’s primarily biology-oriented. Within the following part, we are going to perceive the technical understanding of HRMs.
The HRM structure divides the thought course of into two branches, as within the inspiration above, which employs two distinct time frequencies that may have an effect on one’s thought bursts, guaranteeing larger reasoning.
HRM Internals
HRM didn’t do any pre-training within the present case. When creating an LLM, pretraining is usually a necessary step by which the mannequin is fed billions to trillions of knowledge factors to be taught from. These fashions that we beforehand used are known as foundational fashions. Right here, HRMs are usually not basis fashions.
Since HRMs are unable to generalise on duties, they’re unable to generalise from huge quantities of knowledge as foundational fashions do. As a substitute, ARC-AGI measures its capability for instinct and the power to resolve logical puzzles. Reinforcement studying (Q-learning) is used to coach this HRM mechanism. If the mannequin stops on the applicable second and generates the right response, it’s rewarded.
Right here, HRM adopts a very completely different technique that makes use of each the enter injection part and the most effective options of the recurrent community structure. On this case, the mannequin solely prints the ultimate response with out the reasoning traces, finishing up all the reasoning course of internally in a single ahead cross.
HRM right here makes use of two recurrent modules:-
- H module: Used for high-level summary reasoning and planning.
- L module: Used for quick, detailed computations
Each of those 2 modules are coupled with one another and work collectively within the reasoning course of.
Notice:- Each the H and L modules are recurrent networks, every with a singular set of parameters or weights.
HRM Workflow
Now, let’s perceive the workflow of HRM.
The enter is first remodeled into machine-readable type by the trainable embedding layer. The 2 coupled recurrent modules, which function at numerous time frequencies, are then utilized by the HRM. The planner is a high-level module that manages summary reasoning and defines the final course. The low-level module is the doer; it follows the high-level plan by performing fast, advanced calculations.
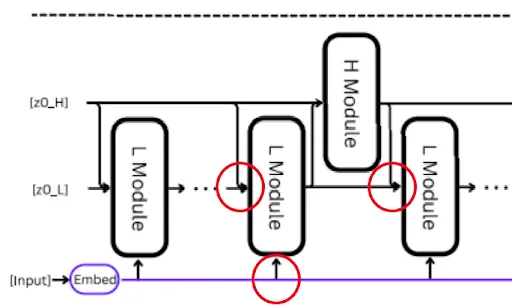
The low-level module begins working first. Because it takes the enter embedding s and the preliminary hidden states of each the low-level and high-level modules (z0_H and z0_L), after which updates its hidden state. It then runs a number of recurrent steps on every; it consumes its hidden state from the earlier step together with the enter embeddings, together with the hidden state from the high-level module, which is the primary one because it hasn’t run but.
The low-level modules run for T steps. As soon as completed, its hidden state is distributed as much as the high-level module. The high-level module processes it together with its personal earlier hidden state and updates its plan accordingly, and sends a brand new high-level hidden state again all the way down to the low-level module.
The low-level module once more runs for an additional T steps, now with a brand new hidden state enter from the high-level module, and sends the consequence again up. That is principally a nested loop for N cycles of low-level modules till the mannequin converges. Right here, convergence means we arrive on the ultimate reply from each the high-level and low-level modules. Lastly, the final high-level hidden state is fed to a trainable output layer that produces the ultimate tokens. So principally, low-level modules run for N*T occasions, the place N is the variety of occasions the high-level module.
Easy Understanding
The low-level module takes a number of fast steps to succeed in a partial answer. That result’s despatched as much as the high-level module, which then updates the plan. The low-level module resets and runs once more for T steps, and the cycle repeats for N occasions till the mannequin converges on the ultimate reply.
def hrm(z, x, N=2, T=2):
x = input_embedding(x)
zH, zL = z
with torch.no_grad():
for _i in vary(N * T - 1):
zL = L_net(zL, zH, x)
if (_i + 1) % T == 0:
zH = H_net(zH, zL)
# 1-step grad
zL = L_net(zL, zH, x)
zH = H_net(zH, zL)
return (zH, zL), output_head(zH)
# Deep Supervision
for x, y_true in train_dataloader:
z = z_init
for step in vary(N_supervision):
z, y_hat = hrm(z, x)
loss = softmax_cross_entropy(y_hat, y_true)
z = z.detach()
loss.backward()
choose.step()
choose.zero_grad()As is well-known, recurrent networks regularly encounter early convergence, which means they conclude after a sure variety of steps. This difficulty is resolved, and computational depth is attained via the interplay of two HRM modules. The high-level module’s replace capabilities as a planner when the low-level module begins to converge, resetting the convergence. In distinction to standard recurrent networks, this permits HRM to attain the next computational depth.
How are HRMs educated?
Backpropagation via time (BPTT) is usually used to coach fashions of recurrent neural networks. The loss is then back-propagated via every step, requiring a major quantity of reminiscence and regularly changing into unstable because the chain of reasoning grows longer. HRM makes use of a one-step gradient approximation to get round this difficulty.
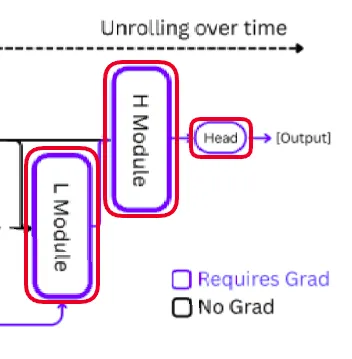
There are some advantages we get by doing this:-
- Regardless of what number of reasoning steps are completed, the reminiscence will stay the identical.
- There’s coaching stability because it avoids exploding and vanishing gradients points from backpropagation chains
There are a variety of explicit challenges when coaching this sort of mannequin once we repeatedly iterate the recurrent blocks. As a result of it eliminates the necessity for unrolled computation over time, this logic considerably lowers reminiscence utilization. Each cross is known as a phase. The applying of Deep Supervision is usually recommended within the paper. In different phrases, every phase’s gradients are saved from reverting to their earlier states. On this approach, the mannequin makes use of a one-step gradient approximation within the setting of recursive deep supervision.
Statement
One other level to notice is that, in distinction to what the earlier photos present, the high-level module’s ultimate hidden state isn’t despatched straight into the output layer. Nonetheless, it goes via a halting headfirst, which determines whether or not the mannequin ought to cease or proceed for an additional N cycle, very similar to people do once we look again and decide whether or not we made the suitable alternative. Relying on the duty, the mannequin can dynamically modify its pondering time. Generally, extra cycles of reasoning shall be required for tougher issues.
Conclusion
The current improvement of Hierarchical Reasoning Fashions (HRMs) represents an vital improvement in our understanding of AI reasoning. HRMs show that efficient reasoning will be completed via structured recurrence impressed by the human mind. These fashions show that RNN-style pondering nonetheless has a spot in modern AI by combining high-level planning with fast low-level computation. Additionally they outperform a few of the most subtle LLMs accessible in the present day and produce again the long-overlooked potential of recurrent architectures.
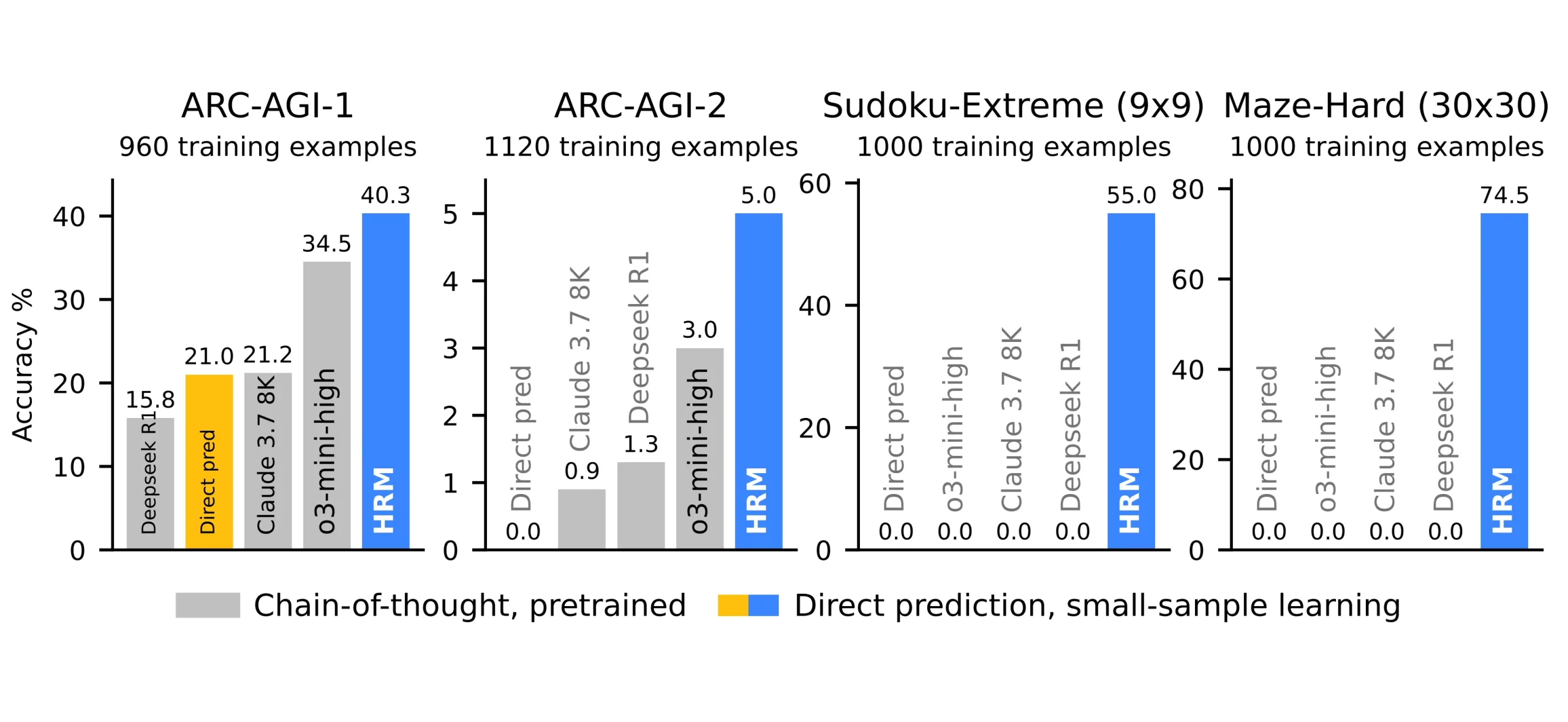
This “return of recurrence” signifies a time when reasoning techniques shall be extra compact, faster, and versatile, in a position to dynamically modify their degree of element to correspond with job complexity. HRMs exhibit distinctive problem-solving abilities in logical and navigation duties, however they don’t depend on intensive pretraining like basis fashions do. HRMs and their recurring spine may outline the following section of AGI analysis, bringing us one step nearer to AI that thinks extra like people, if transformers outlined the earlier one.
Learn extra: Way forward for LLMS
Ceaselessly Requested Questions
A. In contrast to transformers that depend on chain-of-thought traces, HRMs use two coupled recurrent modules—one for quick computations and one for high-level planning—permitting environment friendly reasoning with out large pretraining.
A. HRMs reset convergence via high-level planning updates, stopping early collapse and permitting deeper reasoning in comparison with normal recurrent networks.
A. They obtain sturdy reasoning efficiency with simply 27M parameters and 1,000 coaching examples, utilizing one-step gradient approximation to keep away from the excessive reminiscence prices of backpropagation via time.
GenAI Intern @ Analytics Vidhya | Remaining Yr @ VIT Chennai
Captivated with AI and machine studying, I am wanting to dive into roles as an AI/ML Engineer or Information Scientist the place I could make an actual influence. With a knack for fast studying and a love for teamwork, I am excited to carry progressive options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout numerous fields and take the initiative to delve into knowledge engineering, guaranteeing I keep forward and ship impactful tasks.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}