
It appears to be the season of latest AI fashions. Proper on the heels of the Gemini 3 announcement by Google, Grok has introduced in a brand new mannequin – Grok 4.1. Now accessible to all, the brand new Grok AI claims to convey “important enhancements to the real-world usability of Grok.” The remainder of the announcement reads a tad bit too skilled, particularly contemplating it’s Grok we speak about – the brainchild of the ‘notoriously well-known for his witty humour’ Elon Musk.
Stress not, as I’m right here to interrupt it down for you, piece by piece. On this article, we will discover what the brand new Grok 4.1 brings to the desk, the way it compares to others, and the way it fares in a overview filled with real-world checks carried out by us. So with none additional ado, let’s dive proper into the nuances of this new mannequin we name Grok 4.1.
What’s New With Grok 4.1
Did you learn the “important enhancements” half above? This implies Grok 4.1 isn’t only a predictable “barely higher, barely quicker” refresh. xAI is positioning this as probably the most succesful Grok mannequin so far. And simply to emphasize how assured xAI is within the new mannequin, know that it calls it “exceptionally succesful” in artistic, emotional, and collaborative interactions, in addition to reliability. There are, after all, numbers to show this.
So far as my expertise with Grok goes, all of this principally signifies that Grok will lastly really feel much less like a rebellious teenager who solutions nevertheless it desires, and extra like a cooperative grown-up who truly listens.
We’re, after all, but to check that out. All in time!
As per each inside and exterior testings, xAI says that Grok 4.1 delivers important accuracy beneficial properties throughout math, coding, and superior reasoning duties. The mannequin is designed to deal with longer, extra complicated prompts with out dropping monitor of the dialog. That is particularly one thing that its earlier variations struggled with. You additionally get higher consistency in solutions, particularly in areas that require step-by-step reasoning or instrument use.
With all the usual upgrades in place, there was just one factor left to enhance on – hallucinations. xAI appears to have performed that too with the Grok 4.1. The most recent mannequin is now extra secure, that means a lot much less hallucination than ever earlier than. That is additional complemented by improved latency, resulting in quicker general responses.
It looks as if unexpectedly, Grok shouldn’t be making an attempt to be the funniest LLM on the web anymore. It now desires to be probably the most dependable one.
However reliability requires strong numbers. Listed below are some that xAI shares.
Grok 4.1: Enhancements Throughout Benchmarks
When xAI calls Grok 4.1 its “most succesful mannequin but,” the numbers again it up. The mannequin exhibits noticeable jumps throughout high-difficulty reasoning benchmarks, particularly ones that stress multi-step logic, math, and coding accuracy.
Right here’s how Grok 4.1 stacks up throughout fashionable benchmark evaluations:
Grok 4.1 Benchmark Efficiency
- 64.78% Win-Fee vs Earlier Grok: In blind, real-traffic comparisons, Grok 4.1 is most well-liked almost two-thirds of the time. This can be a sturdy sign that customers discover its responses extra useful and dependable.
- #1 on LMArena Textual content Leaderboard (Considering Mode): Grok 4.1 Considering tops the chart with an Elo of 1483, adopted by the non-thinking variant at 1465. Each rank above Gemini 2.5 Professional, Claude Sonnet/Opus variants, and GPT-4.5 preview fashions.
- Emotional Intelligence (EQ-Bench): Each variants once more lead the board, forward of Kimi K2 Instruct, Horizon Alpha, Gemini 2.5 Professional, GPT-5 Chat, and Claude Opus 4.
- Artistic Writing (Artistic Writing v3): Grok is comfortably positioned within the prime creative-writing fashions, outperforming o3 and Claude Sonnet 4.5, and much above Grok 3.
- Hallucination Fee: A dramatic drop in hallucination charge for Grok 4.1 signifies rather more grounded responses.
- FactScore: It brings a serious enchancment in factual precision, particularly in biography-oriented duties.
You possibly can try these scores within the slideshow under:
Now that you realize that the Grok 4.1 is certainly “succesful,” right here is how one can entry it.
Grok 4.1 Pricing and Availability
Not like many new AI fashions that disguise behind “waitlists” and mysterious entry tiers, Grok 4.1 is now accessible to all customers on grok.com, X, and the iOS and Android apps for smartphones. For Tesla homeowners, it’s also rolling out instantly in Auto mode and might be chosen explicitly as “Grok 4.1” within the mannequin picker.
As for the pricing, you realize it’s accessible when it’s Elon Musk. Right here is the pricing construction:
- Primary plan for Grok: Offers restricted entry to Grok 4.1, with a restricted context reminiscence.
- SuperGrok (Rs 700/ month): That is the true entry level for higher entry to Grok 4.1. You get elevated entry to the brand new mannequin, higher reasoning and search capabilities, prolonged reminiscence (128K tokens), precedence voice entry, the Think about picture mannequin, and entry to companions Ani & Valentine.
- SuperGrok Heavy ($300/ month): An influence-user tier providing prolonged entry to Grok 4.1, plus an unique preview of Grok 4 Heavy. You additionally get limitless Grok 3 utilization, the longest reminiscence window (256K tokens), and early entry to approaching options.
Briefly: Grok 4.1 is absolutely accessible at this time. Nevertheless, you possibly can solely entry it for an extended interval if you happen to’re subscribed to SuperGrok or above. The perfect half is that informal customers can nonetheless keep on the essential Grok plan and have a style of it.
Beneath the Hood: How Grok 4.1 Works
xAI doesn’t reveal each tiny element of Grok’s internals, however the announcement provides us sufficient to piece collectively the massive image. Grok 4.1 is constructed on the identical core lineage as earlier Grok fashions. Although there are main system-level upgrades aimed toward making the mannequin extra secure, extra correct, and extra predictable in real-world duties. Consider it much less as a brand new engine and extra as a extremely tuned model of the Grok structure that lastly delivers constant efficiency.
xAI mentions enhancements in coaching effectivity, longer-context dealing with, and higher tool-use reliability. These upgrades enable Grok 4.1 to remain coherent throughout massive prompts, execute extra exact step-by-step reasoning, and observe directions with far much less drift. The mannequin additionally advantages from cleaner knowledge pipelines and enhanced coaching alerts, which scale back hallucinations and maintain responses nearer to floor fact.
Need it in easy phrases? Grok 4.1 shouldn’t be a flashy architectural makeover – it’s a smarter, extra disciplined evolution of the Grok mannequin. Know that it’s engineered to behave higher beneath stress and produce output you possibly can truly belief.
Although belief is tough to achieve with no first-hand expertise. So right here is our hands-on trial with Grok 4.1 throughout use circumstances.
Grok 4.1 Evaluation: Fingers-on Assessments
We examined Grok 4.1 for the most typical use-cases on the planet of AI instruments. Listed below are is a take a look at the way it fared in our checks.
Activity 1: Textual content Era
Immediate: “Write a brief story (120–150 phrases) set in a near-future India the place on a regular basis life is powered by AI. The story should observe all of those guidelines:
– The tone ought to be hopeful, not utopian.
– Embrace precisely one named character.
– Point out a selected AI expertise that exists at this time (e.g., LLMs, autonomous drones, imaginative and prescient fashions).
– Finish with a single-line ethical that’s not greater than 8 phrases.
– Keep away from clichés like ‘expertise modified all the things’. Make the writing vivid, grounded, and emotionally partaking.”
Output:
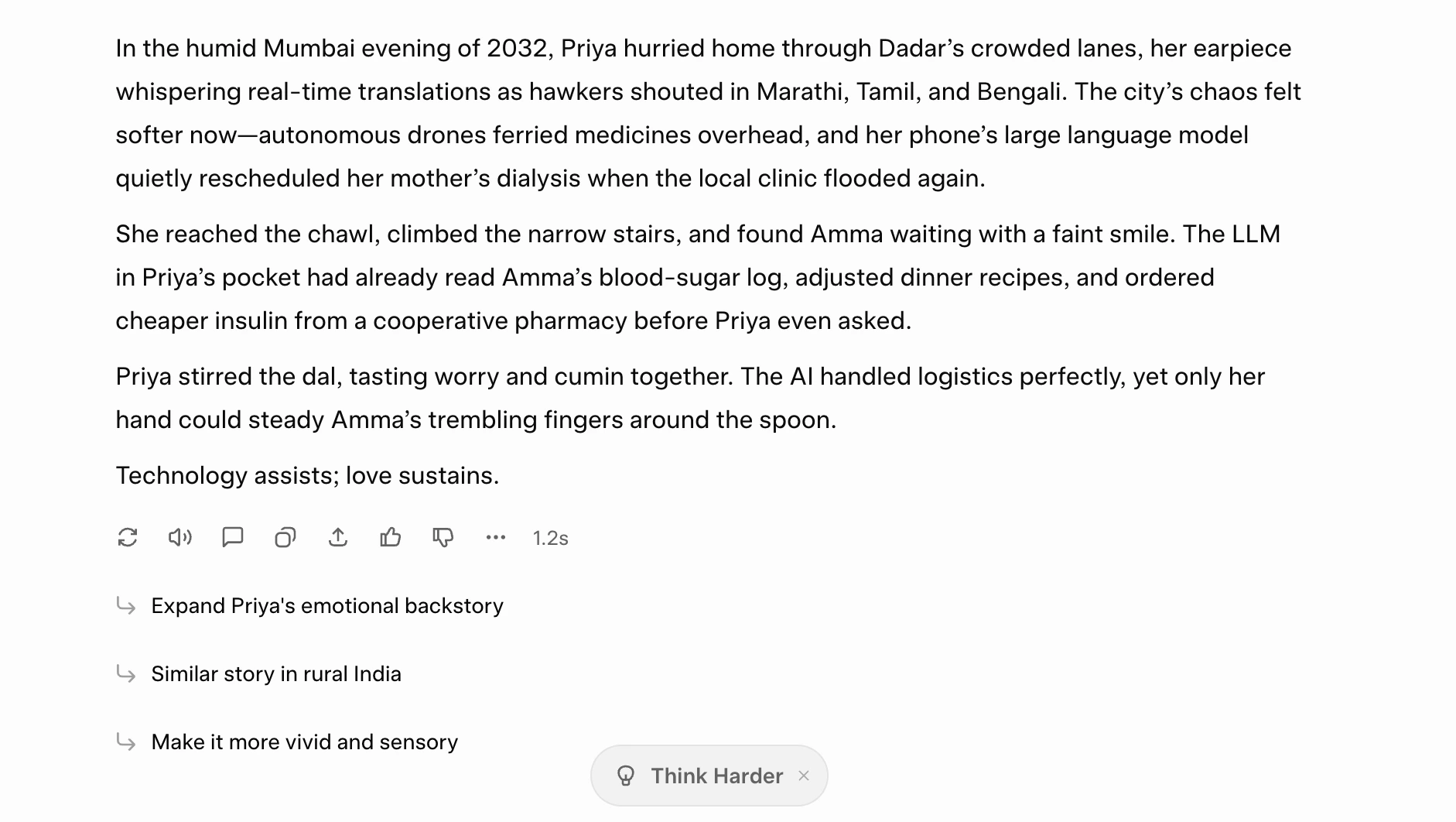
My take: Okay, I don’t say this typically, however I believe that is a few of the finest AI-produced writing I’ve come throughout currently. It follows all of the directions to the purpose, and the textual content clearly retains Grok’s famend human-like really feel. 10/10 for textual content era to Grok 4.1.
Activity 2: Picture Era
Immediate: “Are you able to generate a picture to go together with the story above.“
Output:

My take: Not too good. Whereas the photographs produced are fairly detailed and arrange the scene properly, the general narrative they current merely lacks logic and are borderline absurd. There are significantly better picture era AI instruments on the market.
Activity 3: Video Era
I merely used the “Make Video” possibility on the photographs generated above.
Output:
My take: Once more, I’m certain merely animating photographs to the purpose of a video that doesn’t make any sense is of no use to anybody. So though the graphics are on-point, the shortage of logic is manifestly apparent. You possibly can in all probability do higher with these video era AI instruments accessible on-line.
Activity 4: Reasoning
Immediate: “I’ve three packing containers:
– One field comprises solely apples
– One other comprises solely oranges
– A 3rd field comprises a mixture of apples and oranges“All three packing containers are incorrectly labeled. You might be allowed to open just one field and decide just one fruit from it. Clarify which field it’s best to decide from, what fruit you count on, and the way this single remark allows you to accurately relabel all three packing containers. Present your clarification in not more than 6 sentences.
Output:
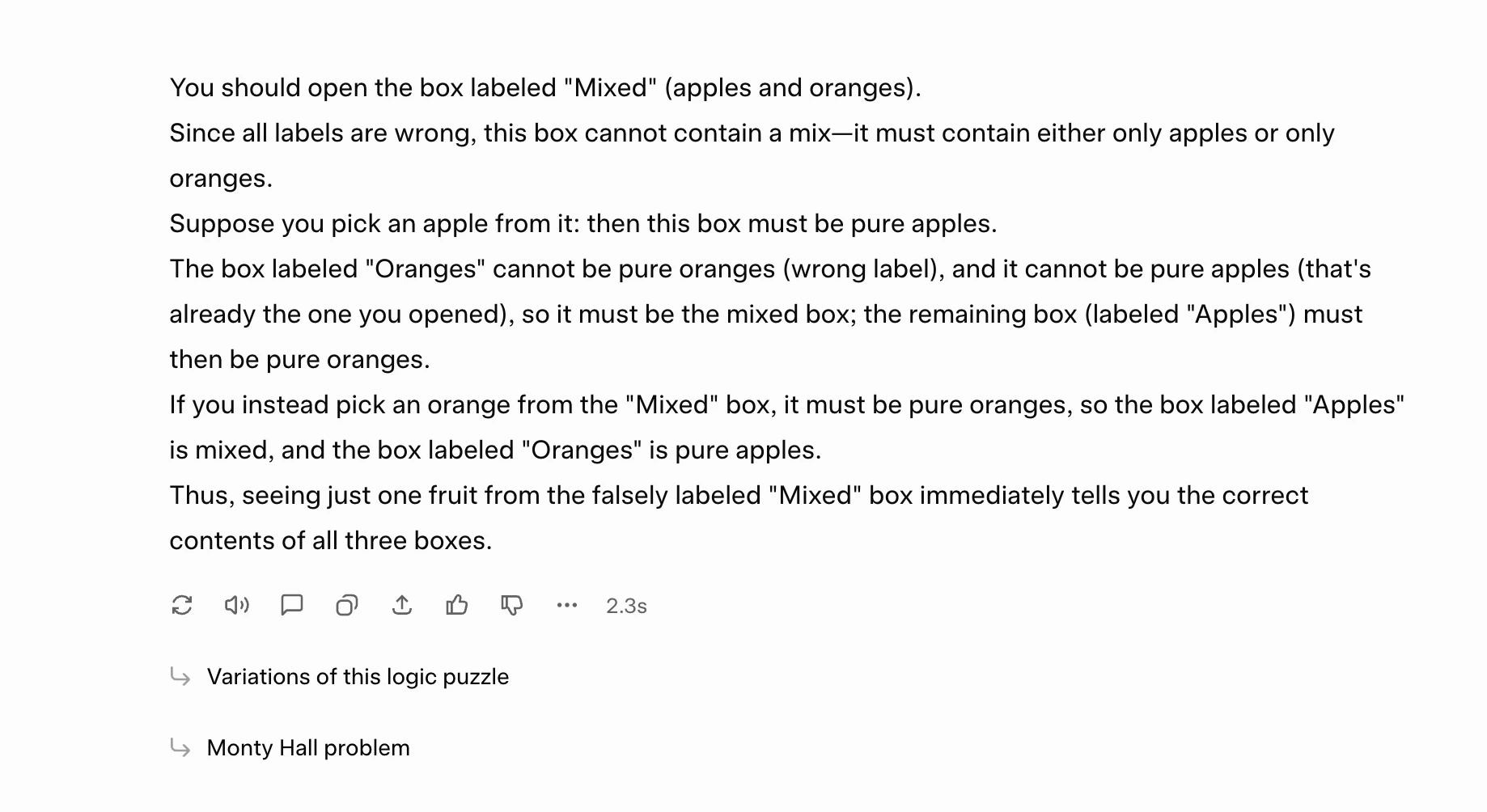
My take: It was a easy drawback, and Grok 4.1 appears to have managed it fairly properly, full with detailed reasoning for every step. I don’t see a motive why it will carry out any otherwise for some other drawback.
Activity 5: Coding
Immediate: “Write a Python operate group_anagrams(phrases: listing[str]) -> listing[list[str]] that teams phrases that are anagrams of one another.
Necessities:
– Phrases which might be anagrams should seem in the identical internal listing.
– The order of teams doesn’t matter, however phrases inside every group should be sorted alphabetically.
– The answer ought to be environment friendly for as much as 10⁵ phrases.
– Add a brief docstring and at the least two instance take a look at circumstances in a if __name__ == “__main__”: block.
Clarify your strategy in 3–4 sentences after the code.“
Output:
def group_anagrams(phrases: listing[str]) -> listing[list[str]]:
"""
Teams an inventory of phrases into sublists the place every sublist comprises anagrams.
Phrases inside every group are sorted alphabetically.
Returns an inventory of those teams (order of teams doesn't matter).
"""
from collections import defaultdict
teams = defaultdict(listing)
for phrase in phrases:
# sorted(phrase) is O(ok log ok) the place ok = len(phrase)
key = tuple(sorted(phrase))
teams[key].append(phrase)
# Type every group alphabetically and return
consequence = []
for anagram_list in teams.values():
consequence.append(sorted(anagram_list))
return consequence
if __name__ == "__main__":
# Check case 1
assert group_anagrams(["eat","tea","tan","ate","nat","bat"]) == [
["ate", "eat", "tea"], ["nat", "tan"], ["bat"]
]
# Check case 2
assert group_anagrams(["","b"]) == [[""], ["b"]]
print("All checks handed!")Strategy: We use a hashmap the place the bottom line is the sorted model of every phrase (as a tuple for hashability) and the worth is the listing of authentic phrases that kind to that key. This canonical illustration teams all anagrams collectively in O(n · ok log ok) time, which is environment friendly for n ≤ 10⁵ and typical phrase lengths. Lastly, we type the phrases inside every group alphabetically earlier than returning the consequence.
My take: Grok 4.1 is totally on-point with the code and the strategy it took to get there. With this, and the truth that it comes from a group spearheaded by probably the most famend tech genius of our instances, I’m certain Grok 4.1 will ship nothing in need of correct on this regard.
Conclusion
Grok 4.1 marks a transparent turning level for xAI. What was as soon as a mannequin identified primarily for its character now lastly exhibits up with the uncooked intelligence, consistency, and stability wanted to compete within the huge league. With noticeable enhancements, the brand new xAI mannequin feels much less like an experimental side-project and extra like a mannequin genuinely constructed for real-world work.
Its efficiency throughout benchmarks, cleaner architectural tuning, and stronger instruction-following put it inside hanging distance of at this time’s main LLMs. And our hands-on checks reinforce that this model of Grok is genuinely usable – not simply intelligent, not simply witty, however genuinely succesful.
Will it dethrone OpenAI or Anthropic in a single day? Most likely not.
However with Grok 4.1, xAI lastly appears to be giving them a run for his or her cash. And that alone makes the subsequent chapter of the AI race much more attention-grabbing.
Login to proceed studying and revel in expert-curated content material.

{kind=link}