

Introduction
Giant Language Fashions (LLMs) have set new benchmarks in pure language processing, however their tendency for hallucination—producing inaccurate outputs—stays a important subject for knowledge-intensive purposes. Retrieval-Augmented Technology (RAG) frameworks try to resolve this by incorporating exterior data into language technology. Nevertheless, conventional RAG approaches depend on chunk-based retrieval, which limits their skill to symbolize advanced semantic relationships. Entity-relation graph-based RAG strategies (GraphRAG) tackle some structural limitations, however nonetheless face excessive building value, one-shot retrieval inflexibility, and dependence on long-context reasoning and punctiliously crafted prompts.
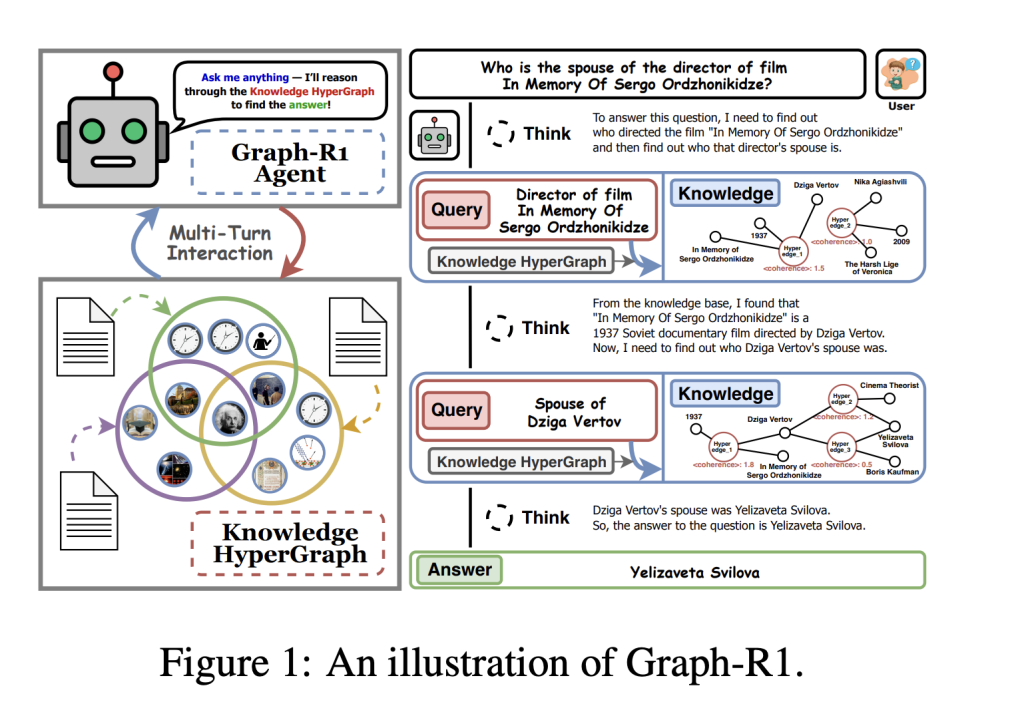
Researchers from Nanyang Technological College, Nationwide College of Singapore, Beijing Institute of Laptop Expertise and Utility, and Beijing Anzhen Hospital have launched Graph-R1, an agentic GraphRAG framework powered by end-to-end reinforcement studying.

Core Improvements of Graph-R1
1. Light-weight Data Hypergraph Development
Graph-R1 constructs data as a hypergraph, the place every data phase is extracted utilizing LLM-driven n-ary relation extraction. This strategy encodes richer and extra semantically grounded relationships, boosting agentic reasoning capabilities whereas sustaining manageable value and computational necessities.


- Effectivity: Solely 5.69s and $2.81 per 1,000 tokens for building (vs. $3.35 for GraphRAG and $4.14 for HyperGraphRAG), whereas producing semantically wealthy graphs with 120,499 nodes and 98,073 edges.
2. Multi-Flip Agentic Retrieval Course of
Graph-R1 fashions retrieval as a multi-turn interplay loop (“think-retrieve-rethink-generate”), permitting the agent to adaptively question and refine its data path, not like earlier strategies that use one-shot retrieval.
- Dynamic Reasoning: The agent decides at every step whether or not to proceed exploring or terminate with a solution. Entity-based and direct hyperedge retrieval are fused by means of reciprocal rank aggregation, bettering the possibilities of retrieving probably the most related data.
3. Finish-to-Finish Reinforcement Studying Optimization
Graph-R1 makes use of Group Relative Coverage Optimization (GRPO) for end-to-end RL, integrating rewards for format adherence, relevance, and reply correctness. This unified reward guides brokers to develop generalizable reasoning methods tightly aligned with each the data construction and output high quality.
- End result-directed reward mechanism: Combines format rewards (structural coherence) and reply rewards (semantic accuracy) for efficient optimization, solely rewarding solutions embedded in structurally legitimate reasoning trajectories.
Key Findings
Benchmarking on RAG QA Duties
Graph-R1 was evaluated throughout six customary QA datasets (2WikiMultiHopQA, HotpotQA, Musique, Pure Questions, PopQA, TriviaQA).
| Technique | Avg. F1 (Qwen2.5-7B) |
|---|---|
| NaiveGeneration | 13.87 |
| StandardRAG | 15.89 |
| GraphRAG | 24.87 |
| HyperGraphRAG | 29.40 |
| Search-R1 | 46.19 |
| R1-Searcher | 42.29 |
| Graph-R1 | 57.82 |
- Graph-R1 achieves as much as 57.82 common F1 with Qwen2.5-7B, surpassing all earlier baselines by a large margin. Bigger base fashions amplify its efficiency beneficial properties.
Ablation Evaluation
Element ablation demonstrates that eradicating hypergraph building, multi-turn reasoning, or RL optimization dramatically reduces efficiency, validating the need of every module inside Graph-R1.
Retrieval and Effectivity
- Graph-R1 retrieval is extra concise and efficient. It achieves excessive F1 scores with reasonable common content material lengths (~1200-1500 tokens per alternate), and helps extra interplay turns (common 2.3-2.5), facilitating steady and correct data extraction.2507.21892v1.pdf
- Technology value is minimal: Regardless of richer illustration, Graph-R1’s response time per question (7.0s) and per-query value ($0) outperforms graph-based opponents like HyperGraphRAG (9.6s, $8.76).2507.21892v1.pdf
Technology High quality
Graph-R1’s technology high quality is evaluated throughout seven dimensions—comprehensiveness, knowledgeability, correctness, relevance, variety, logical coherence, factuality—and constantly outperforms all RL-based and graph-based baselines, reaching prime scores in correctness (86.9), relevance (95.2), and coherence (88.5).
Generalizability
Cross-validation on out-of-distribution (O.O.D.) settings reveals that Graph-R1 maintains sturdy efficiency throughout datasets, with O.O.D./I.I.D. ratios typically above 85%, demonstrating sturdy area generalization properties.
Theoretical Ensures
Graph-R1 is supported by information-theoretic analyses:
- Graph-structured data offers greater data density per retrieval and sooner convergence to right solutions in comparison with chunk-based retrieval.
- Multi-turn interplay allows the agent to realize greater retrieval effectivity by dynamically specializing in high-impact graph areas.
- Finish-to-end RL optimization bridges graph-structured proof and language technology, lowering output entropy and error charges.
Algorithmic Workflow (Excessive-Degree)
- Data Hypergraph Extraction: LLM extracts n-ary relations to construct entity and hyperedge units.
- Multi-turn Agentic Reasoning: The agent alternates between reflective considering, querying, hypergraph retrieval (entity and hyperedge twin paths), and synthesis.
- GRPO Optimization: RL coverage is up to date utilizing sampled trajectories and reward normalization, imposing construction and reply correctness.
Conclusion
Graph-R1 demonstrates that integrating hypergraph-based data illustration, agentic multi-turn reasoning, and end-to-end RL delivers unprecedented beneficial properties in factual QA efficiency, retrieval effectivity, and technology high quality, charting the trail for next-generation agentic and knowledge-driven LLM techniques.
FAQ 1: What’s the key innovation of Graph-R1 in comparison with earlier GraphRAG and RAG techniques?
Graph-R1 introduces an agentic framework the place retrieval is modeled as a multi-turn interplay fairly than a single one-shot course of. Its essential improvements are:
- Hypergraph Data Illustration: As an alternative of easy entity-relation graphs or textual content chunks, Graph-R1 constructs a semantic hypergraph that allows extra expressive, n-ary relationships between entities.
- Multi-Flip Reasoning Loop: The agent operates in repeated cycles of “assume–retrieve–rethink–generate” over the hypergraph, dynamically focusing queries fairly than retrieving every thing directly.
- Finish-to-Finish Reinforcement Studying (RL): The agent is educated with a reward perform that concurrently optimizes for step-wise logical reasoning and remaining reply correctness, enabling tighter alignment between structured data and pure language solutions.
FAQ 2: How does Graph-R1’s retrieval and technology effectivity evaluate to earlier strategies?
Graph-R1 is considerably extra environment friendly and efficient in each retrieval and reply technology:
- Decrease Development & Retrieval Price: For constructing the data hypergraph, Graph-R1 takes solely 5.69 seconds and prices $2.81 per 1,000 tokens (on the 2Wiki dataset), outperforming comparable graph-based strategies.
- Sooner and Cheaper Technology: Question response instances (common 7 seconds per question) and technology prices ($0 per question) are higher than prior graph-RAG techniques, corresponding to HyperGraphRAG.
- Conciseness & Robustness: Graph-R1 solutions are each extra concise (often 1,200–1,500 tokens) and extra correct as a result of multi-turn interplay, with state-of-the-art F1 scores throughout six QA datasets.
FAQ 3: Wherein situations or domains is the Graph-R1 framework most relevant?
Graph-R1 is good for advanced knowledge-intensive purposes demanding each factual accuracy and reasoning transparency, corresponding to:
- Healthcare and Medical AI: The place multi-hop reasoning, traceability, and reliability are important.
- Authorized and Regulatory Domains: That require exact grounded solutions and interpretable multi-step reasoning.
- Enterprise Data Automation: For duties needing scalable, dynamic querying and retrieval throughout massive doc or information corpora.
The mannequin’s structure additionally permits for simple adaptation to different fields that profit from agentic, multi-turn data search anchored in structured representations.
Try the Paper right here and GitHub Web page. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks.


Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.

{kind=link}