
Particle-based simulations and point-cloud functions are driving a large enlargement within the dimension and complexity of scientific and industrial datasets, usually leaping into the realm of billions or trillions of discrete factors. Effectively lowering, storing, and analyzing this knowledge with out bottlenecking fashionable GPUs is among the rising grand challenges in fields like cosmology, geology, molecular dynamics, and 3D imaging. Lately, a group of researchers from Florida State College, the College of Iowa, Argonne Nationwide Laboratory, the College of Chicago, and several other different establishments launched GPZ, a GPU-optimized, error-bounded lossy compressor that radically improves throughput, compression ratio, and knowledge constancy for particle knowledge—outperforming 5 state-of-the-art options by large margins.
Why Compress Particle Knowledge? And Why is It So Arduous?
Particle (or point-cloud) knowledge—in contrast to structured meshes—represents methods as irregular collections of discrete parts in multidimensional house. This format is important for capturing complicated bodily phenomena, however has low spatial and temporal coherence and virtually no redundancy, making it a nightmare for classical lossless or generic lossy compressors.
Think about:
- The Summit supercomputer generated a single cosmological simulation snapshot of 70 TB utilizing Nvidia V100 GPUs.
- The USGS 3D Elevation Program’s level clouds of U.S. terrain exceed 200 TB of storage.
Conventional approaches—like downsampling or on-the-fly processing—throw away as much as 90% of uncooked knowledge or foreclose reproducibility by lack of storage. Furthermore, generic mesh-focused compressors exploit correlations that merely don’t exist in particle knowledge, yielding poor ratios and abysmal GPU throughput.
GPZ: Structure and Improvements
GPZ comes geared up with a four-stage, parallel GPU pipeline—specifically engineered for the quirks of particle knowledge and the stringent calls for of recent massively-parallel {hardware}.
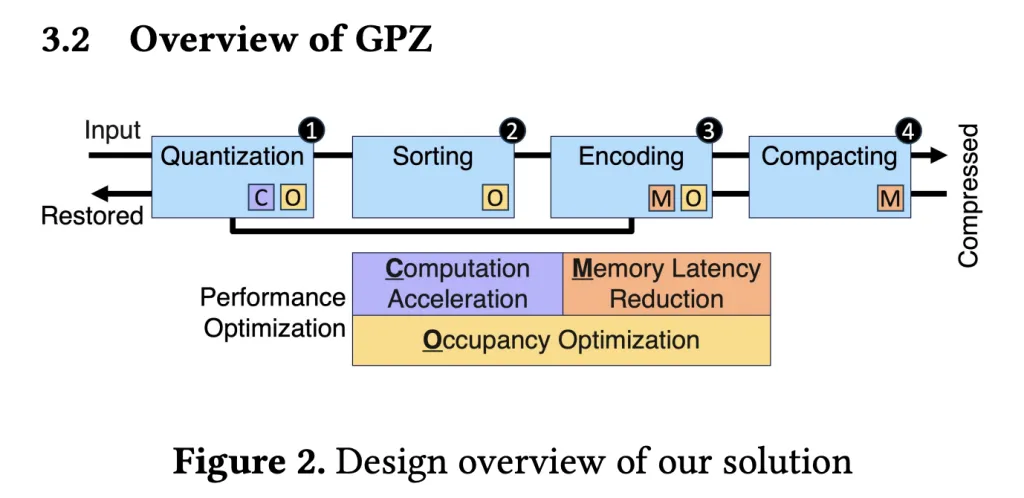
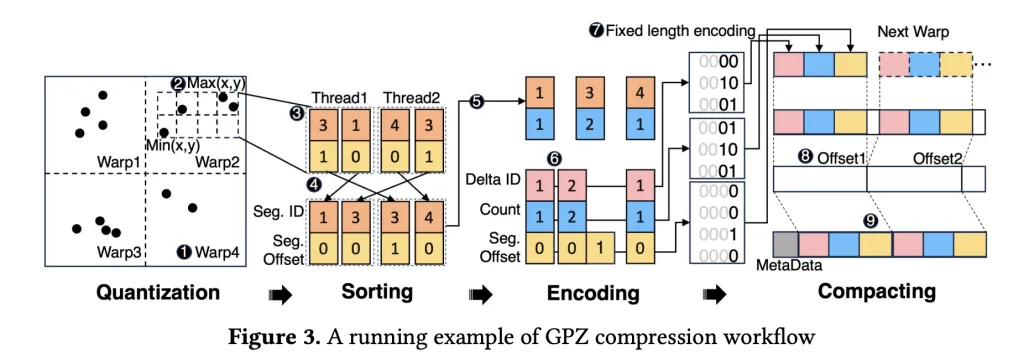
Pipeline Levels:
- Spatial Quantization
- Particles’ floating-point positions are mapped to integer section IDs and offsets, respecting user-specified error bounds whereas leveraging quick FP32 operations for optimum GPU arithmetic throughput.
- Section sizes are tuned for optimum GPU occupancy.
- Spatial Sorting
- Inside every block (mapped to a CUDA warp), particles are sorted by their section ID to boost subsequent lossless coding—utilizing warp-level operations to keep away from expensive synchronization.
- Block-level kind balances compression ratio with shared reminiscence footprint for greatest parallelism.
- Lossless Encoding
- Revolutionary parallel run-length and delta encoding strip redundancy from sorted section IDs and quantized offsets.
- Bit-plane coding eliminates zero bits, with all steps closely optimized for GPU reminiscence entry patterns.
- Compacting
- Compressed blocks are effectively assembled right into a contiguous output utilizing a three-step device-level technique that slashes synchronization overheads and maximizes reminiscence throughput (809 GB/s on RTX 4090, close to theoretical peak).
Decompression is the reverse—extract, decode, and reconstruct positions inside error bounds, enabling high-fidelity post-hoc evaluation.
{Hardware}-Conscious Efficiency Optimizations
GPZ units itself aside with a set of hardware-centric optimizations:
- Reminiscence coalescing: Reads and writes are fastidiously aligned to 4-byte boundaries maximizing DRAM bandwidth (as much as 1.6x enchancment over strided entry).
- Register and shared reminiscence administration: Algorithms are designed to maintain occupancy excessive. Precision is dropped to FP32 the place attainable, and extreme register use is prevented to stop spills.
- Compute scheduling: One-warp-per-block mapping, express use of CUDA intrinsics like FMA operations, and loop unrolling the place helpful.
- Division/modulo elimination: Changing sluggish division/modulo operations with precomputed reciprocals and bitwise masks the place attainable.
Benchmarking: GPZ vs. State-of-the-Artwork
GPZ was evaluated on six real-world datasets (from cosmology, geology, plasma physics, and molecular dynamics), spanning three GPU architectures:
- Client: RTX 4090,
- Knowledge middle: H100 SXM,
- Edge: Nvidia L4.
Baselines included:
- cuSZp2
- PFPL
- FZ-GPU
- cuSZ
- cuSZ-i
Most of those instruments, optimized for generic scientific meshes, failed or confirmed extreme efficiency/high quality drop-offs on particle datasets over 2 GB; GPZ remained strong all through.
Outcomes:
- Pace: GPZ delivered compression throughputs as much as 8x increased than the next-best competitor. Common throughputs hit 169 GB/s (L4), 598 GB/s (RTX 4090), and 616 GB/s (H100). Decompression scales even increased.
- Compression Ratio: GPZ constantly outperformed all baselines, yielding ratios as a lot as 600% increased in difficult settings. Even when runners-up edged barely forward, GPZ sustained a 3x-6x pace benefit.
- Knowledge High quality: Price-distortion plots confirmed superior preservation of scientific options (increased PSNR at decrease bitrates), and visible inspection (particularly in 10x magnified views) revealed GPZ’s reconstructions had been almost indistinguishable from the originals, whereas different compressions produced seen artifacts.
Key Takeaways & Implications
GPZ units a brand new gold normal for real-time, large-scale particle knowledge discount on fashionable GPUs. Its design acknowledges the basic limits of generic compressors and delivers tailor-made options that exploit each ounce of GPU-parallelism and precision tuning.
For researchers and practitioners working with immense scientific datasets, GPZ presents:
- Strong error-bounded compression suited to in-situ and post-hoc evaluation
- Sensible throughput and ratios throughout client and HPC-class {hardware}
- Close to-perfect reconstruction for downstream analytics, visualization, and modeling duties
As knowledge sizes proceed to scale, options like GPZ will more and more outline the following period of GPU-oriented scientific computing and large-scale knowledge administration.
Take a look at the Paper right here. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

{kind=link}