
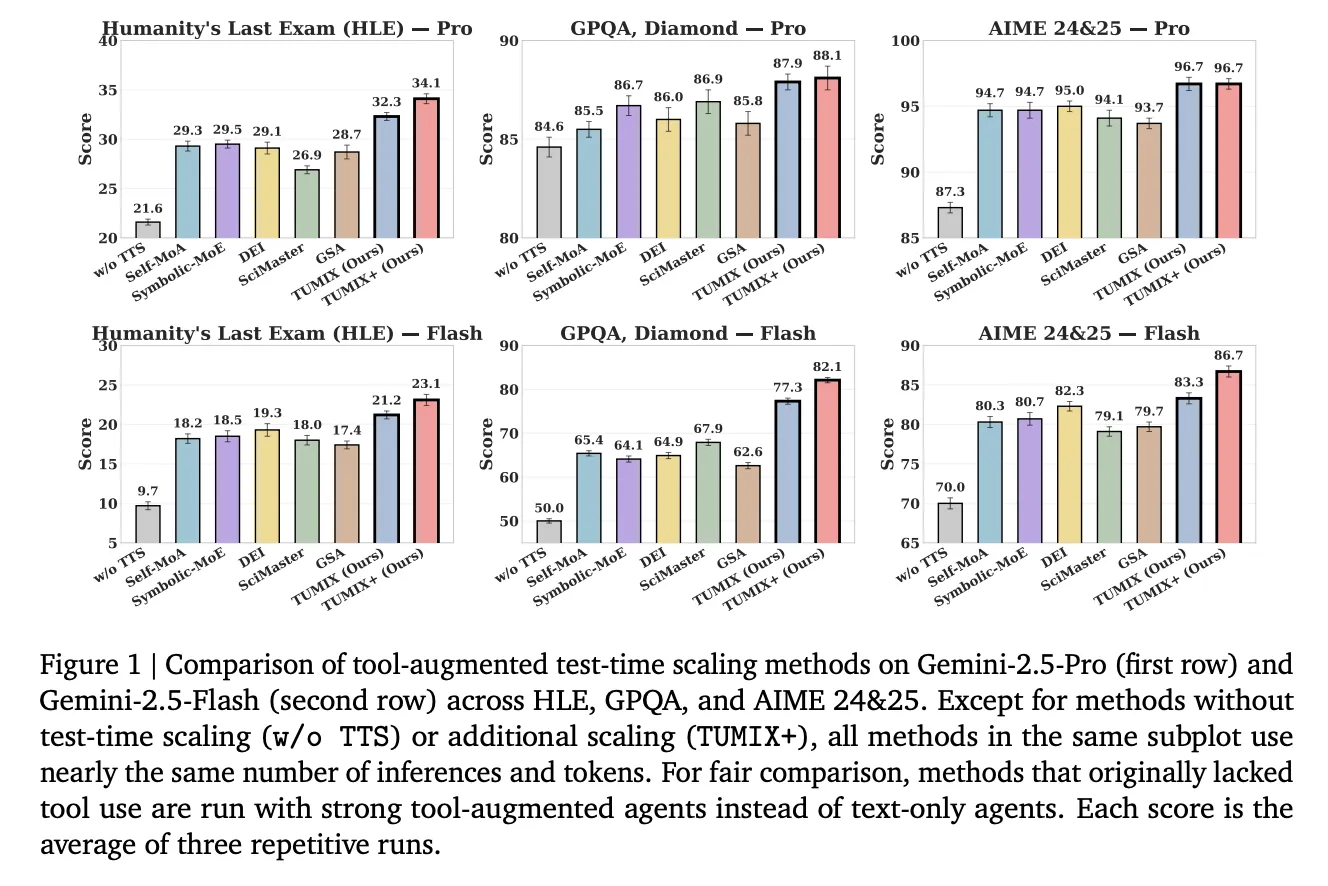
What if, as an alternative of re-sampling one agent, you may push Gemini-2.5 Professional to 34.1% on HLE by mixing 12–15 tool-using brokers that share notes and cease early? Google Cloud AI Analysis, with collaborators from MIT, Harvard, and Google DeepMind, launched TUMIX (Software-Use Combination)—a test-time framework that ensembles heterogeneous agent types (text-only, code, search, guided variants) and lets them share intermediate solutions over a number of refinement rounds, then cease early through an LLM-based decide. The consequence: greater accuracy at decrease price on onerous reasoning benchmarks akin to HLE, GPQA-Diamond, and AIME (2024/2025).
So, What precisely is totally different new?
- Combination over modality, not simply extra samples: TUMIX runs ~15 agent types spanning Chain-of-Thought (CoT), code execution, internet search, dual-tool brokers, and guided variants. Every spherical, each agent sees (a) the unique query and (b) different brokers’ earlier solutions, then proposes a refined reply. This message-passing raises common accuracy early whereas range regularly collapses—so stopping issues.
- Adaptive early-termination: An LLM-as-Decide halts refinement as soon as solutions exhibit robust consensus (with a minimal spherical threshold). This preserves accuracy at ~49% of the inference price vs. fixed-round refinement; token price drops to ~46% as a result of late rounds are token-heavier.
- Auto-designed brokers: Past human-crafted brokers, TUMIX prompts the bottom LLM to generate new agent sorts; mixing these with the handbook set yields an further ~+1.2% common carry with out additional price. The empirical “candy spot” is ~12–15 agent types.
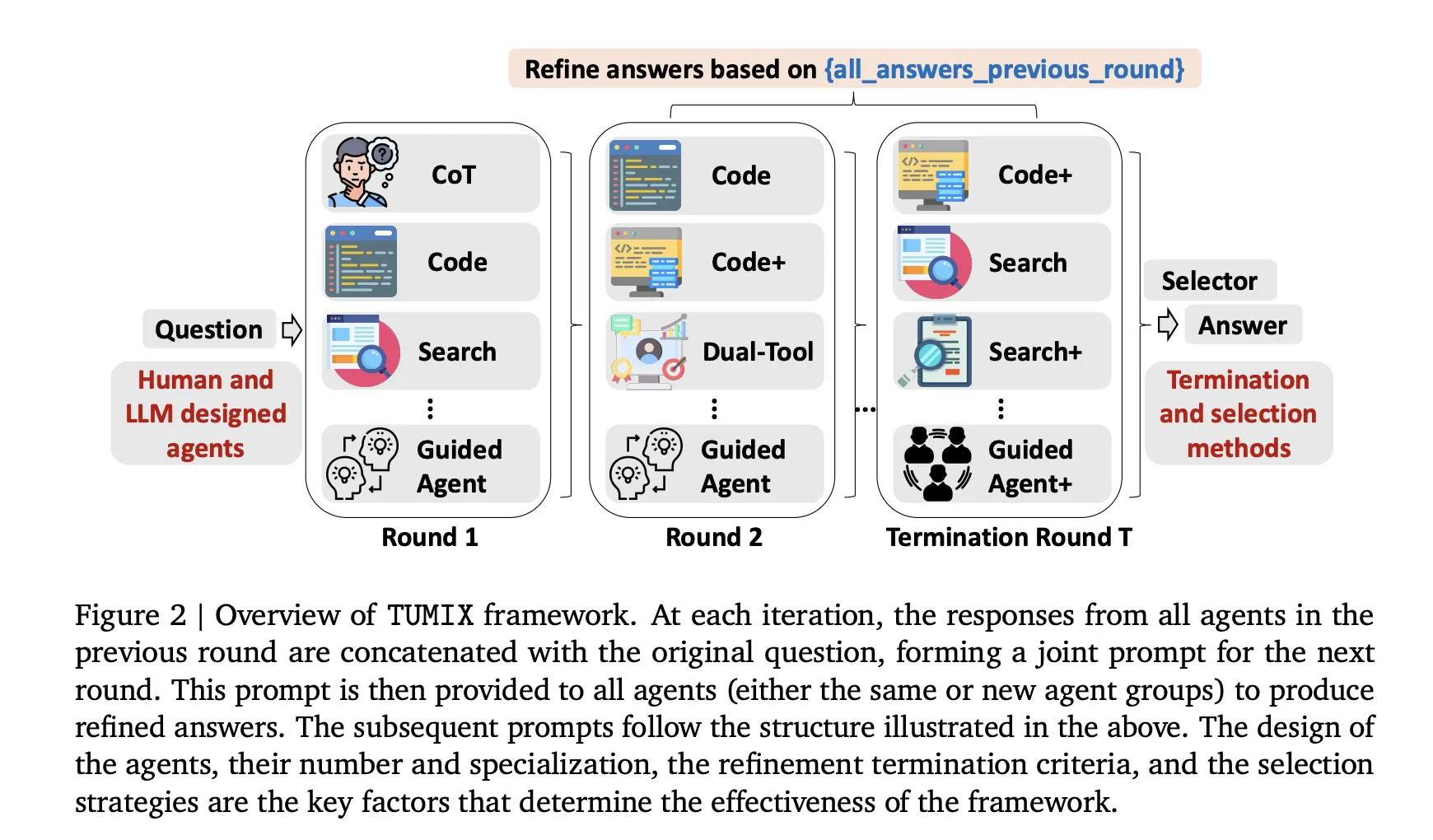
How does it work?
TUMIX runs a gaggle of heterogeneous brokers—text-only Chain-of-Thought, code-executing, web-searching, and guided variants—in parallel, then iterates a small variety of refinement rounds the place every agent circumstances on the unique query plus the opposite brokers’ prior rationales and solutions (structured note-sharing). After every spherical, an LLM-based decide evaluates consensus/consistency to resolve early termination; if confidence is inadequate, one other spherical is triggered, in any other case the system finalizes through easy aggregation (e.g., majority vote or selector). This mixture-of-tool-use design trades brute-force re-sampling for numerous reasoning paths, enhancing protection of right candidates whereas controlling token/instrument budgets; empirically, advantages saturate round 12–15 agent types, and stopping early preserves range and lowers price with out sacrificing accuracy
Lets talk about the Outcomes
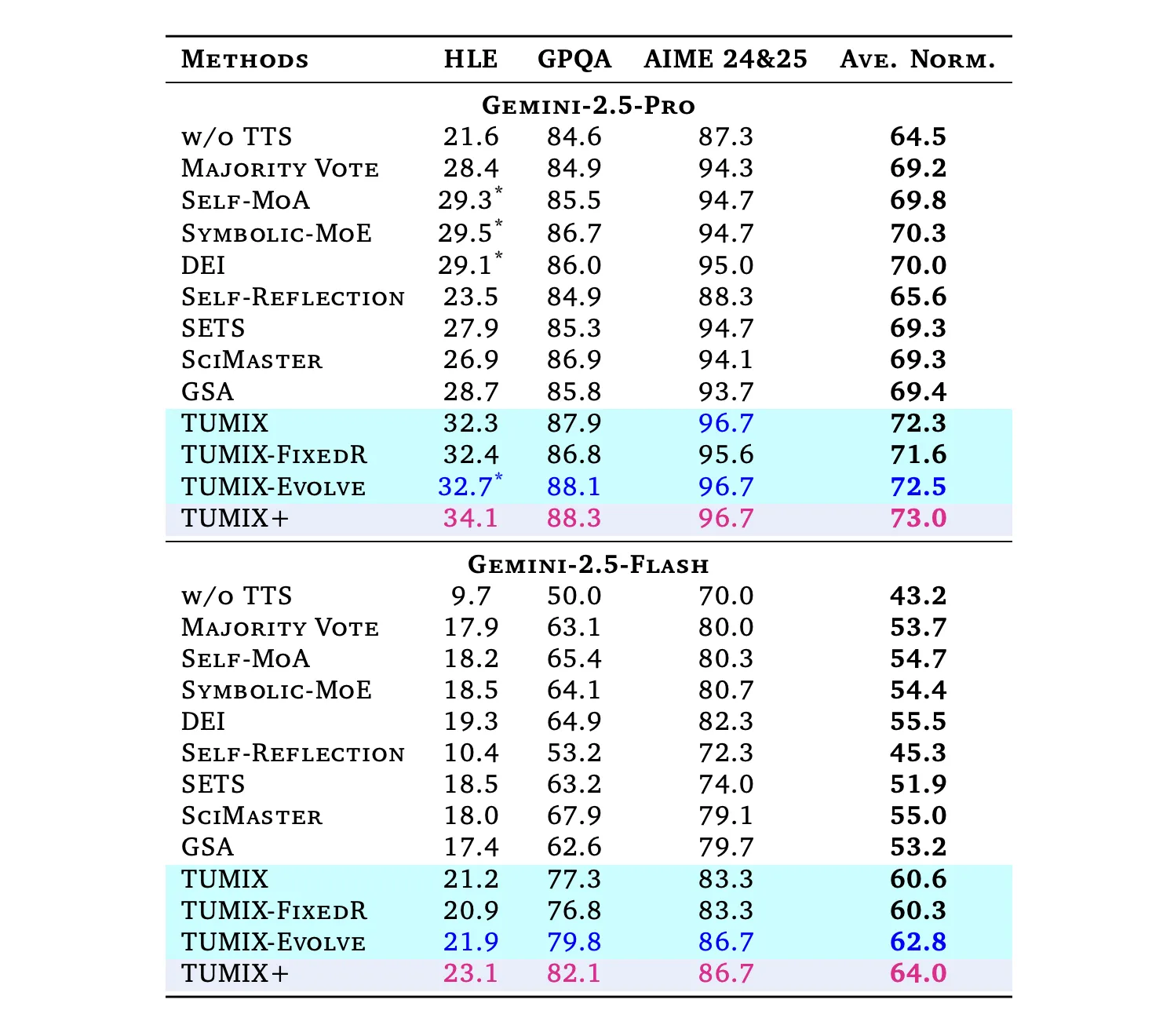
Below comparable inference budgets to robust tool-augmented baselines (Self-MoA, Symbolic-MoE, DEI, SciMaster, GSA), TUMIX yields the finest common accuracy; a scaled variant (TUMIX+) pushes additional with extra compute:
- HLE (Humanity’s Final Examination): Professional: 21.6% → 34.1% (TUMIX+); Flash: 9.7% → 23.1%.
(HLE is a 2,500-question, tough, multi-domain benchmark finalized in 2025.) - GPQA-Diamond: Professional: as much as 88.3%; Flash: as much as 82.1%. (GPQA-Diamond is the toughest 198-question subset authored by area consultants.)
- AIME 2024/25: Professional: 96.7%; Flash: 86.7% with TUMIX(+) at check time.
Throughout duties, TUMIX averages +3.55% over the very best prior tool-augmented test-time scaling baseline at related price, and +7.8% / +17.4% over no-scaling for Professional/Flash, respectively.
TUMIX is a superb strategy from Google as a result of it frames test-time scaling as a search drawback over heterogeneous instrument insurance policies somewhat than brute-force sampling. The parallel committee (textual content, code, search) improves candidate protection, whereas the LLM-judge allows early-stop that preserves range and reduces token/instrument spend—helpful beneath latency budgets. The HLE positive factors (34.1% with Gemini-2.5 Professional) align with the benchmark’s finalized 2,500-question design, and the ~12–15 agent types “candy spot” signifies choice—not era—is the limiting issue.
Try the Paper. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}