
Google eliminated outdated structured knowledge documentation, however as a substitute of returning a 404 response, they’ve chosen to redirect the outdated URLs to a changelog that hyperlinks to the outdated URL, thereby inflicting an infinite loop between the 2 pages. Though that’s technically not a mushy 404, it’s an fascinating use of a 301 redirect for a lacking internet web page and never how SEOs usually deal with lacking internet pages and 404 server responses. Did Google make a mistake?
When you’re it simply from the Changelog, then it does appear like a mistake. There’s one other web page from June 2025 that says the discontinuation of help for these pages that additionally hyperlinks to documentation about these structured knowledge that aren’t out of date. However the therapy of the pages is just not constant. A few of the hyperlinks go to the changelog, whereupon a round loop is triggered and one in all them is a 404, which is the anticipated habits.
Google Eliminated Structured Information Documentation
Google quitely printed a changelog notice saying they’d eliminated out of date structured knowledge documentation. An announcement was made three months in the past in June and at this time they lastly eliminated the out of date documentation.
The lacking pages are for the next structured knowledge that’s not supported:
- Course data
- Estimated wage
- Studying video
- Particular announcement – 404 Error Response
- Car itemizing.
These pages are fully lacking. Gone, and sure by no means coming again. The same old process in that type of state of affairs is to return a 404 Web page Not Discovered server response. However that’s not what is occurring.
As an alternative of a 404 response Google is returning a 301 redirect again to the changelog for among the modified pages. What makes this setup considerably bizarre is that Google is linking again to the lacking internet web page from the changelog, which then redirects again to the changelog, creating an infinite loop between the 2 pages. There’s one other web page, the June 2025 announcement, however as soon as the press goes from there to the changelog that’s the place the infinite redirect loop begins.
Screenshot Of Changelog
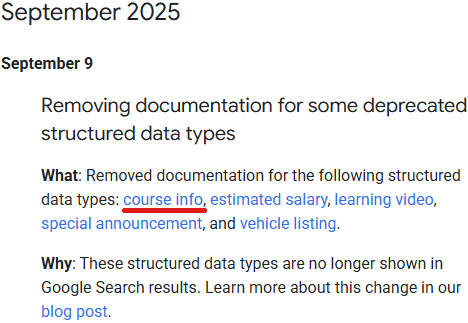
Within the above screenshot I’ve underlined in crimson the hyperlink to the Course Data structured knowledge.
The phrases “course data” are a hyperlink to this URL:
https://builders.google.com/search/docs/look/structured-data/course-info
Which redirects proper again to the changelog right here:
https://builders.google.com/search/updates#september-2025
Which in fact incorporates the hyperlinks to the 5 URLs that not exist, primarily inflicting an infinite loop.
It’s not an excellent person expertise and it’s not good for crawlers. So the query is, why did Google do this?
301 redirects are an choice for pages which are lacking, so Google is technically right to make use of a 301 redirect. Nonetheless, 301 redirects are typically used to level “to a extra correct URL” which typically means a redirect to a alternative web page, one which serves the identical or comparable function.
Technically they didn’t create a mushy 404. However the way in which they dealt with the lacking pages creates a loop that sends crawlers forwards and backwards between a lacking internet web page and the changelog. It appears that evidently it will have been a greater person and crawler expertise to as a substitute hyperlink to the June 2025 weblog submit that explains why these structured knowledge varieties are not supported reasonably than create an infinite loop.
I don’t assume it’s something most SEOs or publishers would do, so why does Google assume it’s a good suggestion?
Featured Picture by Shutterstock/Kues

{kind=link}