 Strategy that Maps a Spoken Question On to an Embedding and Retrieves Info with out First Changing Speech to Textual content")
Google AI Analysis workforce has introduced a manufacturing shift in Voice Search by introducing Speech-to-Retrieval (S2R). S2R maps a spoken question on to an embedding and retrieves info with out first changing speech to textual content. The Google workforce positions S2R as an architectural and philosophical change that targets error propagation within the traditional cascade modeling method and focuses the system on retrieval intent moderately than transcript constancy. Google analysis workforce states Voice Search is now powered by S2R.
From cascade modeling to intent-aligned retrieval
Within the conventional cascade modeling method, computerized speech recognition (ASR) first produces a single textual content string, which is then handed to retrieval. Small transcription errors can change question which means and yield incorrect outcomes. S2R reframes the issue across the query “What info is being sought?” and bypasses the delicate intermediate transcript.
Evaluating the potential of S2R
Google’s analysis workforce analyzed the disconnect between phrase error fee (WER) (ASR high quality) and imply reciprocal rank (MRR) (retrieval high quality). Utilizing human-verified transcripts to simulate a cascade groundtruth “excellent ASR” situation, the workforce in contrast (i) Cascade ASR (real-world baseline) vs (ii) Cascade groundtruth (higher sure) and noticed that decrease WER doesn’t reliably predict increased MRR throughout languages. The persistent MRR hole between the baseline and groundtruth signifies room for fashions that optimize retrieval intent straight from audio.
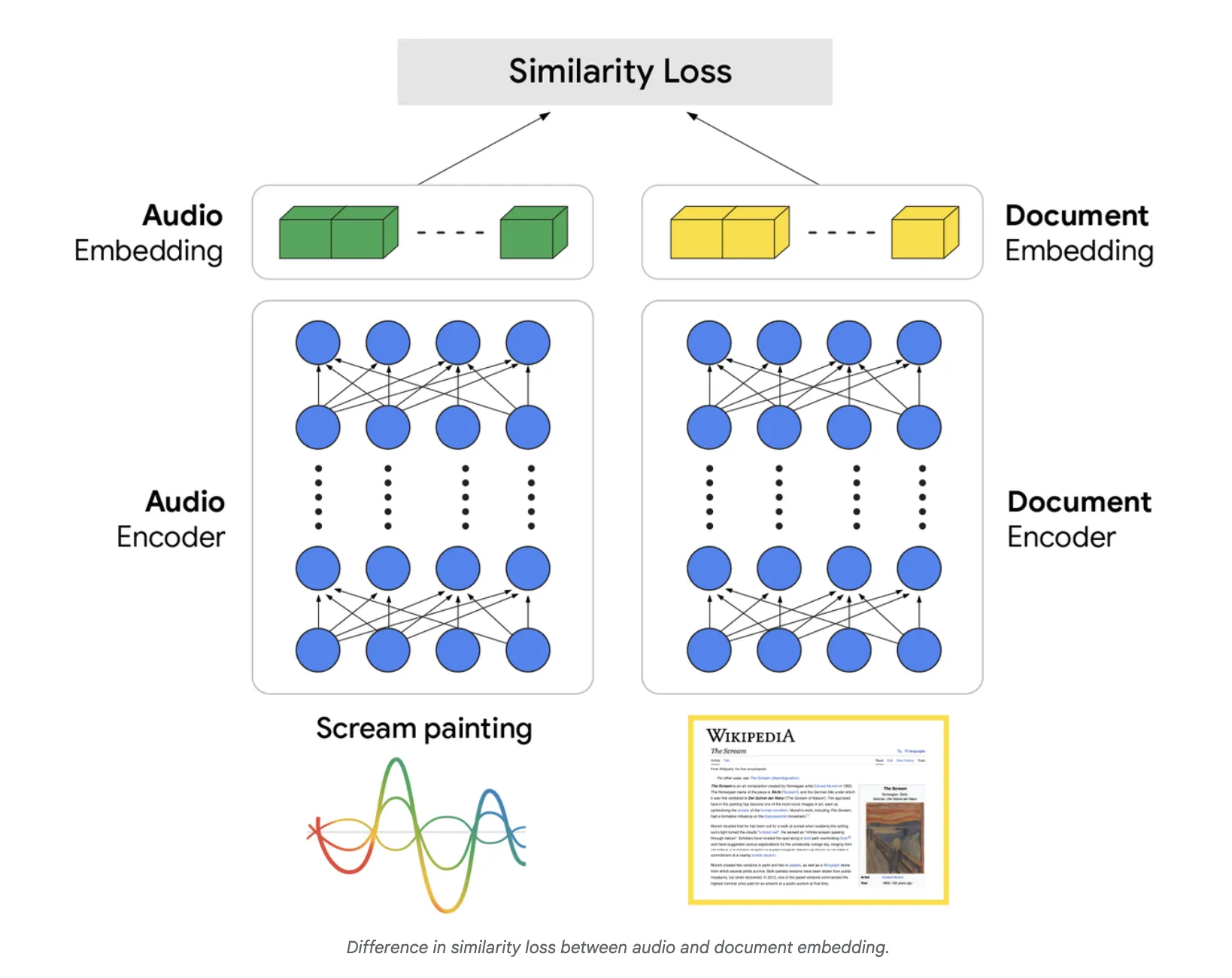
Structure: dual-encoder with joint coaching
On the core of S2R is a dual-encoder structure. An audio encoder converts the spoken question right into a wealthy audio embedding that captures semantic which means, whereas a doc encoder generates a corresponding vector illustration for paperwork. The system is educated with paired (audio question, related doc) information in order that the vector for an audio question is geometrically shut to vectors of its corresponding paperwork within the illustration area. This coaching goal straight aligns speech with retrieval targets and removes the brittle dependency on actual phrase sequences.
Serving path: streaming audio, similarity search, and rating
At inference time, the audio is streamed to the pre-trained audio encoder to provide a question vector. This vector is used to effectively establish a extremely related set of candidate outcomes from Google’s index; the search rating system—which integrates lots of of indicators—then computes the ultimate order. The implementation preserves the mature rating stack whereas changing the question illustration with a speech-semantic embedding.
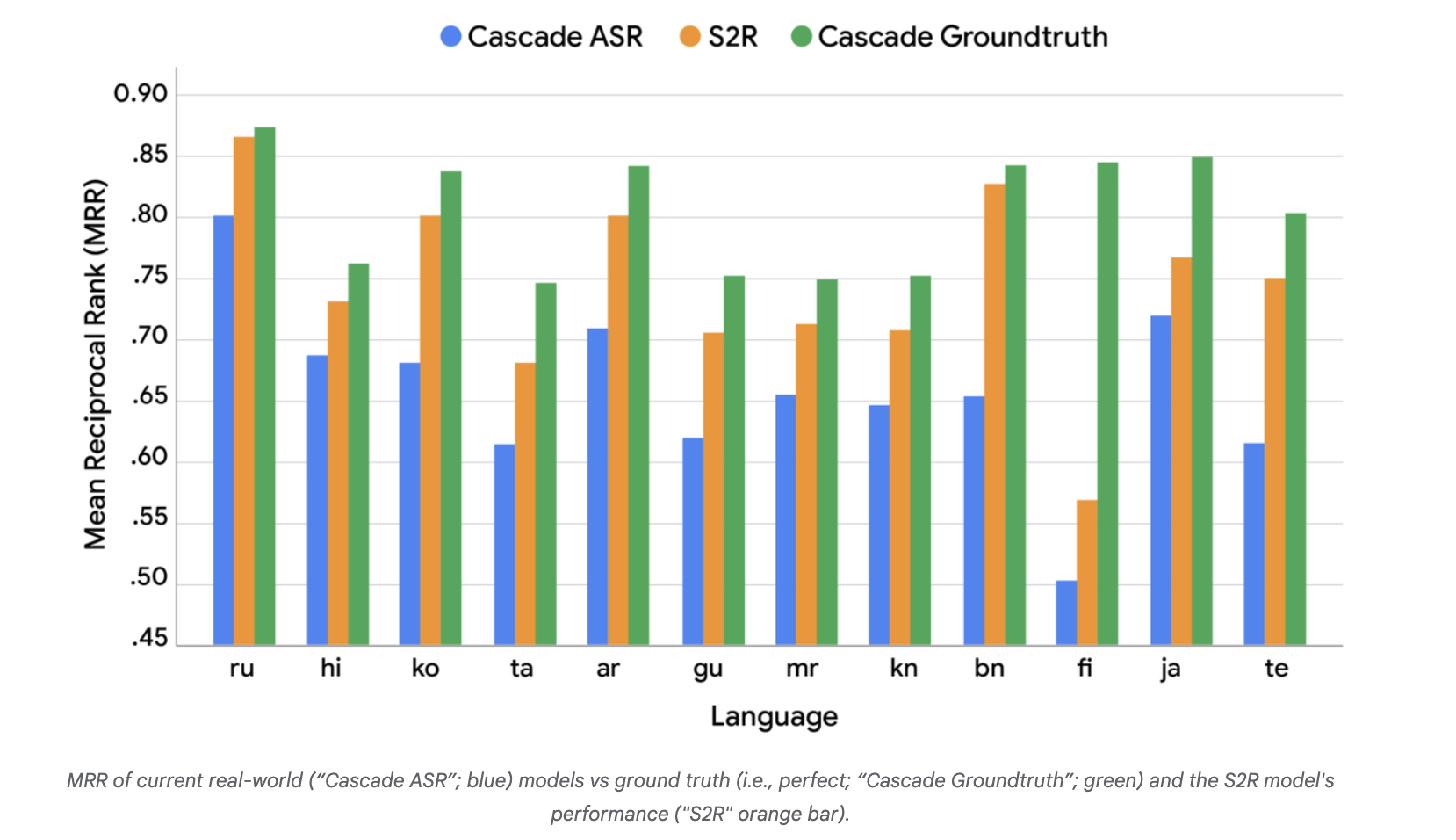
Evaluating S2R on SVQ
On the Easy Voice Questions (SVQ) analysis, the publish presents a comparability of three techniques: Cascade ASR (blue), Cascade groundtruth (inexperienced), and S2R (orange). The S2R bar considerably outperforms the baseline Cascade ASR and approaches the higher sure set by Cascade groundtruth on MRR, with a remaining hole that the authors observe as future analysis headroom.
Open sources: SVQ and the Huge Sound Embedding Benchmark (MSEB)
To assist group progress, Google open-sourced Easy Voice Questions (SVQ) on Hugging Face: quick audio questions recorded in 26 locales throughout 17 languages and beneath a number of audio circumstances (clear, background speech noise, visitors noise, media noise). The dataset is launched as an undivided analysis set and is licensed CC-BY-4.0. SVQ is a part of the Huge Sound Embedding Benchmark (MSEB), an open framework for assessing sound embedding strategies throughout duties.
Key Takeaways
- Google has moved Voice Search to Speech-to-Retrieval (S2R), mapping spoken queries to embeddings and skipping transcription.
- Twin-encoder design (audio encoder + doc encoder) aligns audio/question vectors with doc embeddings for direct semantic retrieval.
- In evaluations, S2R outperforms the manufacturing ASR→retrieval cascade and approaches the ground-truth transcript higher sure on MRR.
- S2R is dwell in manufacturing and serving a number of languages, built-in with Google’s present rating stack.
- Google launched Easy Voice Questions (SVQ) (17 languages, 26 locales) beneath MSEB to standardize speech-retrieval benchmarking.
Speech-to-Retrieval (S2R) is a significant architectural correction moderately than a beauty improve: by changing the ASR→textual content hinge with a speech-native embedding interface, Google aligns the optimization goal with retrieval high quality and removes a serious supply of cascade error. The manufacturing rollout and multilingual protection matter, however the fascinating work now’s operational—calibrating audio-derived relevance scores, stress-testing code-switching and noisy circumstances, and quantifying privateness trade-offs as voice embeddings turn into question keys.
Take a look at the Technical particulars right here. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Max is an AI analyst at MarkTechPost, based mostly in Silicon Valley, who actively shapes the way forward for know-how. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI every day to translate complicated tech developments into clear, comprehensible insights

{kind=link}