 Framework Permits LLMs to Predict Industrial System Efficiency Immediately from Uncooked Textual content Knowledge")
Google’s new Regression Language Mannequin (RLM) strategy allows Giant Language Fashions (LLMs) to foretell industrial system efficiency instantly from uncooked textual content knowledge, with out counting on advanced function engineering or inflexible tabular codecs.
The Problem of Industrial System Prediction
Predicting efficiency for large-scale industrial programs—like Google’s Borg compute clusters—has historically required intensive domain-specific function engineering and tabular knowledge representations, making scalability and adaptation troublesome. Logs, configuration recordsdata, variable {hardware} mixes, and nested job knowledge can’t be simply flattened or normalized for traditional regression fashions. Because of this, optimization and simulation workflows usually grow to be brittle, pricey, and gradual, particularly when new sorts of workloads or {hardware} are launched.
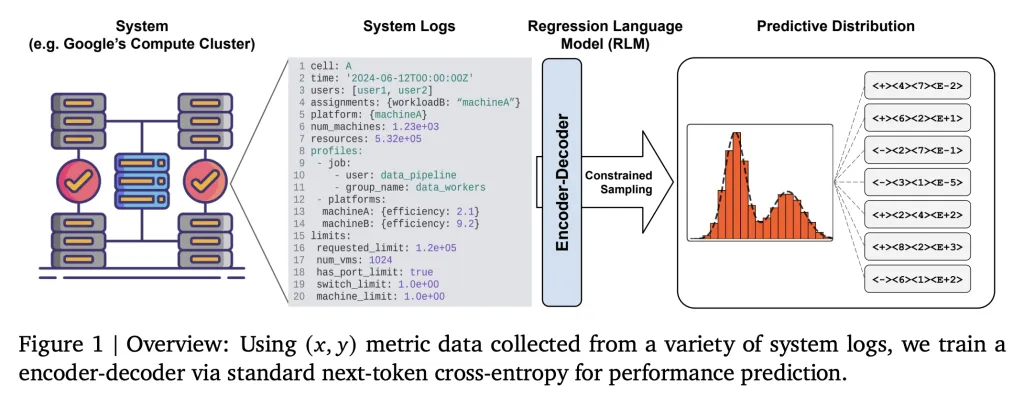
The Primary Thought: Textual content-to-Textual content Regression
Google’s Regression Language Mannequin (RLM) reformulates regression as a textual content technology activity: all system state knowledge (configuration, logs, workload profiles, {hardware} descriptions) are serialized into structured textual content codecs like YAML or JSON and used because the enter immediate xxx. The regression mannequin then outputs the numerical goal yyy—comparable to effectivity metrics (Hundreds of thousands of Directions Per Second per Google Compute Unit, MIPS per GCU)—as a textual content string response.
- No Tabular Options Required: This eliminates the necessity for predefined function units, normalization, and inflexible encoding schemes.
- Common Applicability: Any system state will be represented as a string; heterogeneous, nested, or dynamically evolving options are natively supported.
Technical Particulars: Structure and Coaching
The strategy makes use of a comparatively small encoder-decoder LLM (60M parameters) that trains by way of next-token cross-entropy loss on string representations of xxx and yyy. The mannequin isn’t pretrained on common language modeling—coaching can begin from random initialization, focusing instantly on correlating system states with numeric outcomes.
- Customized Numeric Tokenization: Outcomes are tokenized effectively (e.g., P10 mantissa-sign-exponent encoding) to symbolize floating-point values inside the mannequin’s vocabulary.
- Few-shot Adaptation: Pretrained RLMs are quickly fine-tunable on new duties with as few as 500 examples, adapting to new cluster configurations or months inside hours, not weeks.
- Sequence Size Scaling: Fashions can course of very lengthy enter texts (hundreds of tokens), guaranteeing advanced states are totally noticed.
Efficiency: Outcomes on Google’s Borg Cluster
Testing on the Borg cluster, RLMs achieved as much as a 0.99 Spearman rank correlation (0.9 common) between predicted and true MIPS per GCU, with 100x decrease imply squared error than tabular baselines. The fashions natively quantify uncertainty by sampling a number of outputs for every enter, supporting probabilistic system simulation and Bayesian optimization workflows.
- Uncertainty Quantification: RLMs seize each aleatoric (inherent) and epistemic (unknowns attributable to restricted observability) uncertainties, not like most black-box regressors.
- Common Simulators: The density modeling capabilities of RLMs recommend their use in constructing common digital twins for large-scale programs, accelerating infrastructure optimization, and real-time suggestions.
Comparability: RLMs vs Conventional Regression
| Method | Knowledge Format | Function Engineering | Adaptability | Efficiency | Uncertainty |
|---|---|---|---|---|---|
| Tabular Regression | Flat tensors, numbers | Guide required | Low | Restricted by options | Minimal |
| RLM (Textual content-to-Textual content) | Structured, nested textual content | None required | Excessive | Close to-perfect ranks | Full-spectrum |
Purposes and Abstract
- Cloud and Compute Clusters: Direct efficiency prediction and optimization for big, dynamic infrastructure.
- Manufacturing and IoT: Common simulators for consequence prediction throughout various industrial pipelines.
- Scientific Experiments: Finish-to-end modeling the place enter states are advanced, textually described, and numerically various.
This new strategy—treating regression as language modeling—removes longstanding obstacles in system simulation, allows fast adaptation to new environments, and helps strong uncertainty-aware prediction, all essential for next-generation industrial AI.
Take a look at the Paper, Codes and Technical particulars. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking advanced datasets into actionable insights.

{kind=link}