
How do you make an LLM agent really study from its personal runs—successes and failures—with out retraining? Google Analysis proposes ReasoningBank, an AI agent reminiscence framework that converts an agent’s personal interplay traces—each successes and failures—into reusable, high-level reasoning methods. These methods are retrieved to information future choices, and the loop repeats so the agent self-evolves. Coupled with memory-aware test-time scaling (MaTTS), the method delivers as much as +34.2% relative effectiveness positive factors and –16% fewer interplay steps throughout net and software-engineering benchmarks in comparison with prior reminiscence designs that retailer uncooked trajectories or success-only workflows.
So, what’s the downside?
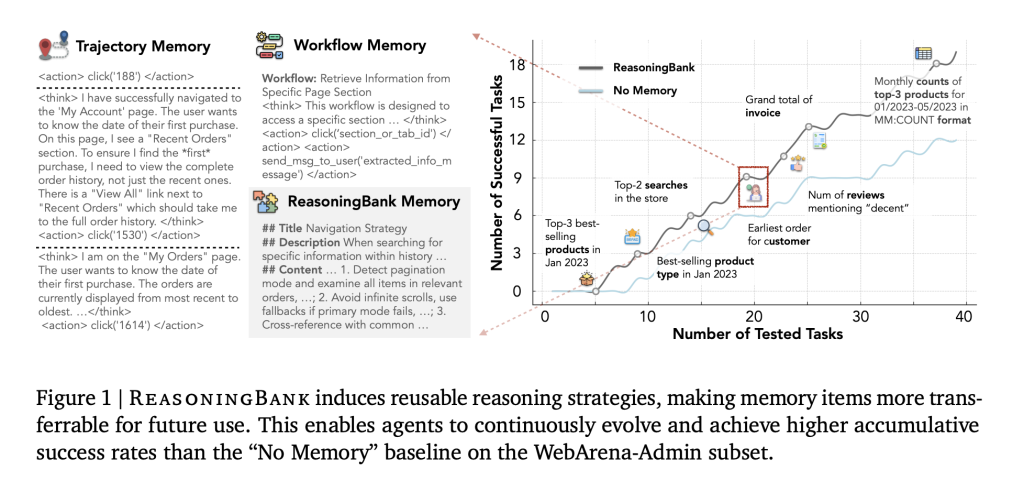
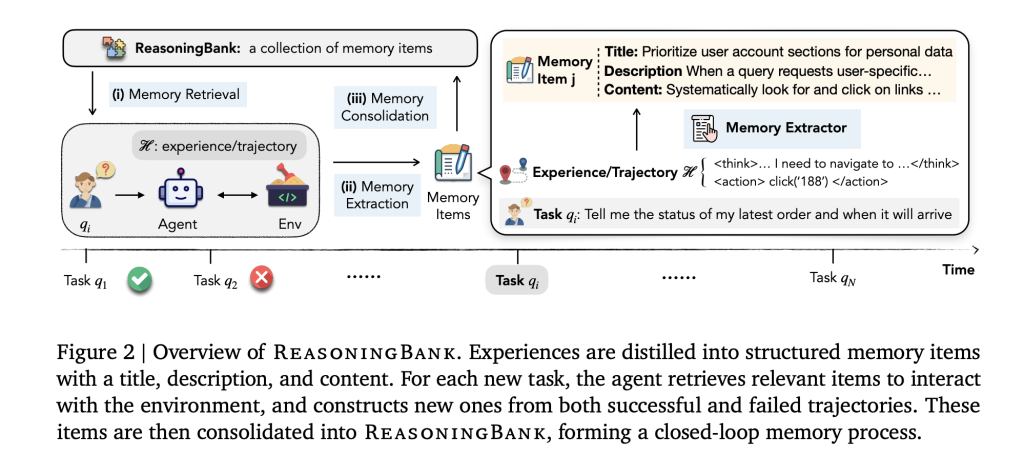
LLM brokers deal with multi-step duties (net looking, pc use, repo-level bug fixing) however usually fail to build up and reuse expertise. Typical “reminiscence” tends to hoard uncooked logs or inflexible workflows. These are brittle throughout environments and sometimes ignore helpful indicators from failures—the place lots of actionable data lives. ReasoningBank reframes reminiscence as compact, human-readable technique objects which might be simpler to switch between duties and domains.
Then how does it deal with?
Every expertise is distilled right into a reminiscence merchandise with a title, one-line description, and content material containing actionable rules (heuristics, checks, constraints). Retrieval is embedding-based: for a brand new job, top-k related objects are injected as system steering; after execution, new objects are extracted and consolidated again. The loop is deliberately easy—retrieve → inject → choose → distill → append—so enhancements could be attributed to the abstraction of methods, not heavy reminiscence administration.
Why it transfers: objects encode reasoning patterns (“favor account pages for user-specific information; confirm pagination mode; keep away from infinite scroll traps; cross-check state with job spec”), not website-specific DOM steps. Failures grow to be detrimental constraints (“don’t depend on search when the positioning disables indexing; affirm save state earlier than navigation”), which prevents repeated errors.
Reminiscence-aware test-time scaling (MaTTS) proposed as properly!
Take a look at-time scaling (operating extra rollouts or refinements per job) is efficient provided that the system can study from the additional trajectories. The analysis staff additionally propsoed Reminiscence-aware test-time scaling (MaTTS) that integrates scaling with ReasoningBank:
- Parallel MaTTS: generate (okay) rollouts in parallel, then self-contrast them to refine technique reminiscence.
- Sequential MaTTS: iteratively self-refine a single trajectory, mining intermediate notes as reminiscence indicators.
The synergy is two-way: richer exploration produces higher reminiscence; higher reminiscence steers exploration towards promising branches. Empirically, MaTTS yields stronger, extra monotonic positive factors than vanilla best-of-N with out reminiscence.
So, how good are these proposed analysis frameworks?
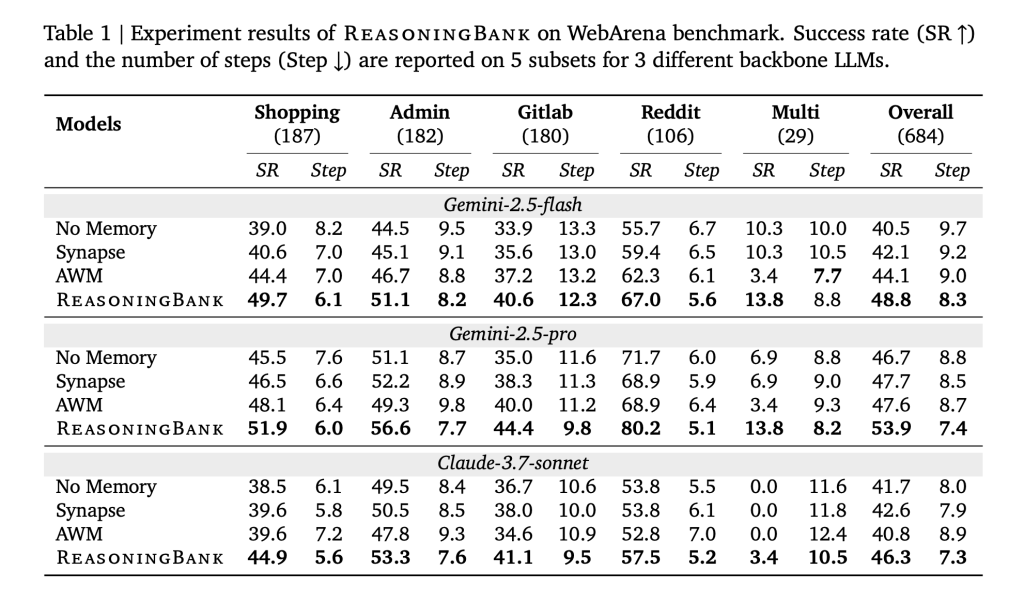
- Effectiveness: ReasoningBank + MaTTS improves job success as much as 34.2% (relative) over no-memory and outperforms prior reminiscence designs that reuse uncooked traces or success-only routines.
- Effectivity: Interplay steps drop by 16% total; additional evaluation exhibits the largest reductions on profitable trials, indicating fewer redundant actions fairly than untimely aborts.
The place does this matches within the agent stack?
ReasoningBank is a plug-in reminiscence layer for interactive brokers that already use ReAct-style choice loops or best-of-N test-time scaling. It doesn’t substitute verifiers/planners; it amplifies them by injecting distilled classes on the immediate/system degree. On net duties, it enhances BrowserGym/WebArena/Mind2Web; on software program duties, it layers atop SWE-Bench-Verified setups.
Take a look at the Paper right here. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}