
Google AI has expanded the Gemma household with the introduction of Gemma 3 270M, a lean, 270-million-parameter basis mannequin constructed explicitly for environment friendly, task-specific fine-tuning. This mannequin demonstrates sturdy instruction-following and superior textual content structuring capabilities “out of the field,” that means it’s prepared for quick deployment and customization with minimal further coaching.
Design Philosophy: “Proper Device for the Job”
In contrast to large-scale fashions aimed toward general-purpose comprehension, Gemma 3 270M is crafted for focused use circumstances the place effectivity outweighs sheer energy. That is essential for situations like on-device AI, privacy-sensitive inference, and high-volume, well-defined duties corresponding to textual content classification, entity extraction, and compliance checking.
Core Options
- Large 256k Vocabulary for Professional Tuning:
Gemma 3 270M devotes roughly 170 million parameters to its embedding layer, supporting an enormous 256,000-token vocabulary. This enables it to deal with uncommon and specialised tokens, making it exceptionally match for area adaptation, area of interest business jargon, or customized language duties. - Excessive Power Effectivity for On-System AI:
Inside benchmarks present the INT4-quantized model consumes lower than 1% battery on a Pixel 9 Professional for 25 typical conversations—making it essentially the most power-efficient Gemma but. Builders can now deploy succesful fashions to cell, edge, and embedded environments with out sacrificing responsiveness or battery life. - Manufacturing-Prepared with INT4 Quantization-Conscious Coaching (QAT):
Gemma 3 270M arrives with Quantization-Conscious Coaching checkpoints, so it may function at 4-bit precision with negligible high quality loss. This unlocks manufacturing deployments on gadgets with restricted reminiscence and compute, permitting for native, encrypted inference and elevated privateness ensures. - Instruction-Following Out of the Field:
Out there as each a pre-trained and instruction-tuned mannequin, Gemma 3 270M can perceive and comply with structured prompts immediately, whereas builders can additional specialize conduct with only a handful of fine-tuning examples.
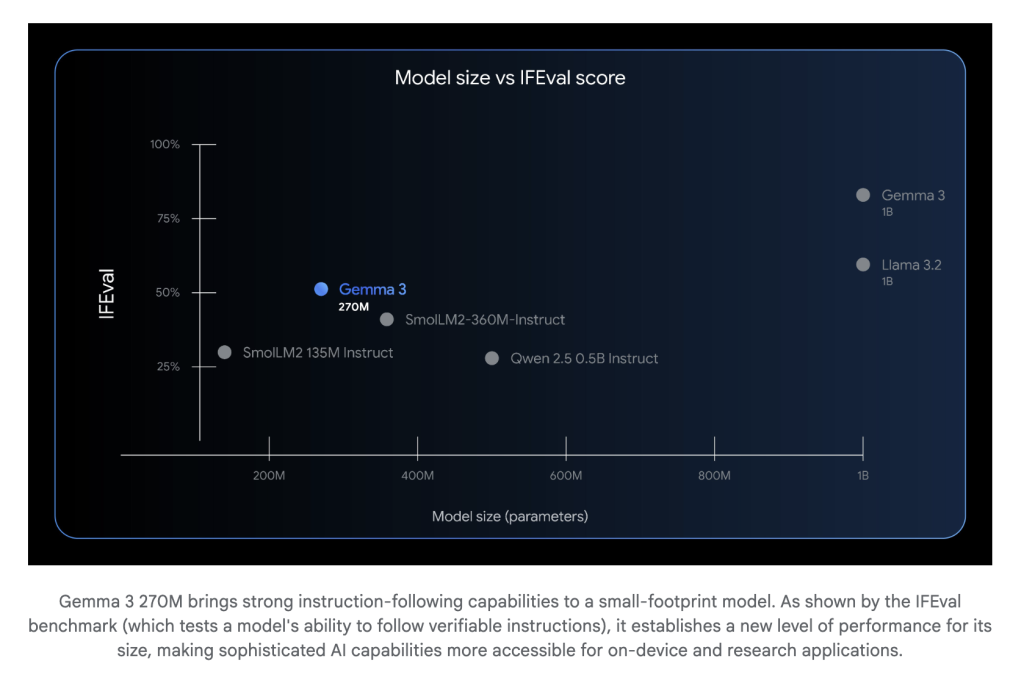
Mannequin Structure Highlights
| Part | Gemma 3 270M Specification |
|---|---|
| Whole Parameters | 270M |
| Embedding Parameters | ~170M |
| Transformer Blocks | ~100M |
| Vocabulary Measurement | 256,000 tokens |
| Context Window | 32K tokens (1B and 270M sizes) |
| Precision Modes | BF16, SFP8, INT4 (QAT) |
| Min. RAM Use (Q4_0) | ~240MB |
Nice-Tuning: Workflow & Finest Practices
Gemma 3 270M is engineered for fast, skilled fine-tuning on targeted datasets. The official workflow, illustrated in Google’s Hugging Face Transformers information, includes:
- Dataset Preparation:
Small, well-curated datasets are sometimes adequate. For instance, educating a conversational model or a selected knowledge format might require simply 10–20 examples. - Coach Configuration:
Leveraging Hugging Face TRL’s SFTTrainer and configurable optimizers (AdamW, fixed scheduler, and so on.), the mannequin might be fine-tuned and evaluated, with monitoring for overfitting or underfitting by evaluating coaching and validation loss curves. - Analysis:
Publish-training, inference checks present dramatic persona and format adaptation. Overfitting, sometimes a difficulty, turns into helpful right here—making certain fashions “neglect” basic data for extremely specialised roles (e.g., roleplaying recreation NPCs, customized journaling, sector compliance). - Deployment:
Fashions might be pushed to Hugging Face Hub, and run on native gadgets, cloud, or Google’s Vertex AI with near-instant loading and minimal computational overhead.
Actual-World Functions
Firms like Adaptive ML and SK Telecom have used Gemma fashions (4B dimension) to outperform bigger proprietary techniques in multilingual content material moderation—demonstrating Gemma’s specialization benefit. Smaller fashions like 270M empower builders to:
- Keep a number of specialised fashions for various duties, lowering value and infrastructure calls for.
- Allow fast prototyping and iteration because of its dimension and computational frugality.
- Guarantee privateness by executing AI completely on-device, without having to switch delicate person knowledge to the cloud.
Conclusion:
Gemma 3 270M marks a paradigm shift towards environment friendly, fine-tunable AI—giving builders the power to deploy high-quality, instruction-following fashions for very targeted wants. Its mix of compact dimension, energy effectivity, and open-source flexibility make it not only a technical achievement, however a sensible answer for the following era of AI-driven functions.
Try the Technical particulars right here and Mannequin on Hugging Face. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}