

Imaginative and prescient-language fashions (VLMs) play a vital position in in the present day’s clever programs by enabling an in depth understanding of visible content material. The complexity of multimodal intelligence duties has grown, starting from scientific problem-solving to the event of autonomous brokers. Present calls for on VLMs have far exceeded easy visible content material notion, with rising consideration on superior reasoning. Whereas latest works present that long-form reasoning and scalable RL considerably improve LLMs’ problem-solving skills, present efforts primarily give attention to particular domains to enhance VLM reasoning. The open-source neighborhood presently lacks a multimodal reasoning mannequin that outperforms conventional non-thinking fashions of comparable parameter scale throughout numerous duties.
Researchers from Zhipu AI and Tsinghua College have proposed GLM-4.1V-Pondering, a VLM designed to advance general-purpose multimodal understanding and reasoning. The strategy then introduces Reinforcement Studying with Curriculum Sampling (RLCS) to unlock the mannequin’s full potential, enabling enhancements throughout STEM downside fixing, video understanding, content material recognition, coding, grounding, GUI-based brokers, and lengthy doc understanding. Researchers open-sourced GLM-4.1V-9B-Pondering, which units a brand new benchmark amongst equally sized fashions. It additionally delivers aggressive, and in some circumstances superior efficiency in comparison with proprietary fashions like GPT-4o on difficult duties comparable to lengthy doc understanding and STEM reasoning.


GLM-4.1V-Pondering incorporates three core parts: a imaginative and prescient encoder, an MLP adapter, and an LLM decoder. It makes use of AIMv2-Large because the imaginative and prescient encoder and GLM because the LLM, changing the unique 2D convolutions with 3D convolutions for temporal downsampling. The mannequin integrates 2D-RoPE to help arbitrary picture resolutions and facet ratios, and course of excessive facet ratios over 200:1 and excessive resolutions past 4K. Researchers lengthen RoPE to 3D-RoPE within the LLM to enhance spatial understanding in multimodal contexts. For temporal modeling in movies, time index tokens are added after every body token, with timestamps encoded as strings to assist the mannequin perceive real-world temporal gaps between frames
Throughout pre-training, the researchers use a wide range of datasets, combining giant educational corpora with interleaved image-text information wealthy in data. By together with pure textual content information, the mannequin’s core language capabilities are preserved, leading to higher go@ok efficiency than different state-of-the-art pre-trained base fashions of comparable measurement. The supervised fine-tuning stage transforms the bottom VLM into one able to lengthy CoT inference utilizing a curated long-CoT corpus throughout verifiable, like STEM issues, and non-verifiable duties comparable to instruction following. Lastly, the RL section employs a mixture of RLVR and RLHF to conduct large-scale coaching throughout all multimodal domains, together with STEM downside fixing, grounding, optical character recognition, GUI brokers, and plenty of extra.
GLM-4.1V-9B-Pondering outperforms all competing open-source fashions underneath 10B parameters in Common VQA duties overlaying each single-image and multi-image settings. It achieves the best efficiency on difficult STEM benchmarks, together with MMMU_Val, MMMU_Pro, VideoMMMU, and AI2D. Within the OCR and Chart domains, the mannequin units new state-of-the-art scores on ChartQAPro and ChartMuseum. For Lengthy Doc Understanding, GLM-4.1V-9B-Pondering outperforms all different fashions on MMLongBench, whereas establishing new state-of-the-art ends in GUI Brokers and multimodal Coding duties. Lastly, the mannequin exhibits strong Video Understanding efficiency, outperforming VideoMME, MMVU, and MotionBench benchmarks.
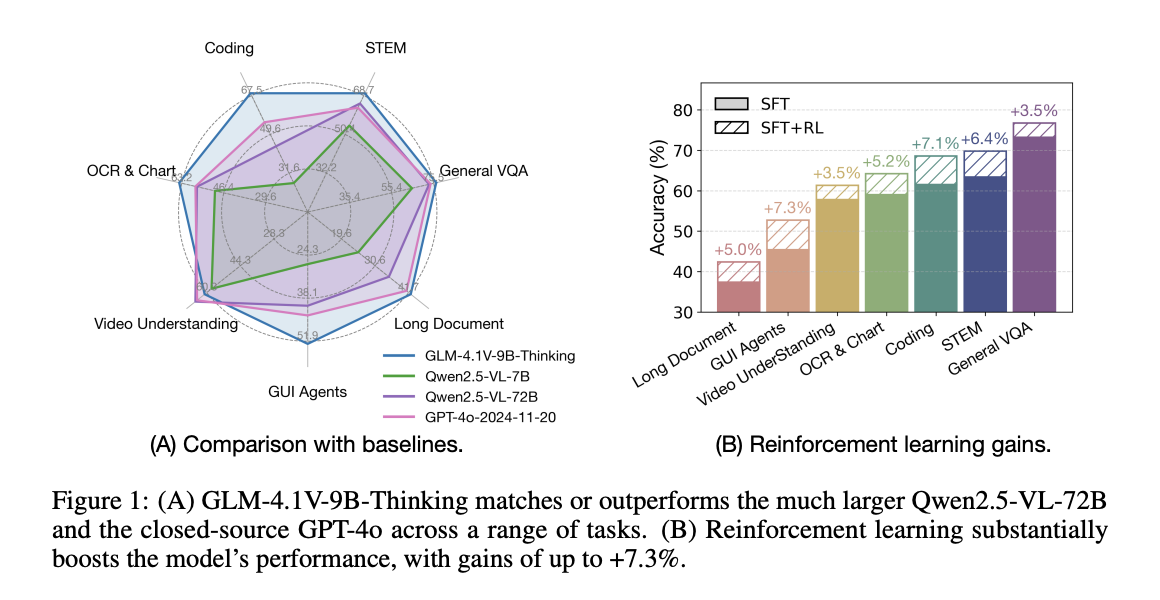
In conclusion, researchers launched GLM-4.1V-Pondering, which represents a step towards general-purpose multimodal reasoning. Its 9B-parameter mannequin outperforms bigger fashions just like the one which exceeds 70B parameters. Nevertheless, a number of limitations stay, comparable to inconsistent enhancements in reasoning high quality by way of RL, instability throughout coaching, and difficulties with advanced circumstances. Future developments ought to give attention to bettering supervision and analysis of mannequin reasoning, with reward fashions evaluating intermediate reasoning steps whereas detecting hallucinations and logical inconsistencies. Furthermore, exploring methods to forestall reward hacking in subjective analysis duties is essential to attain general-purpose intelligence.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking.
| Sponsorship Alternative |
|---|
| Attain essentially the most influential AI builders worldwide. 1M+ month-to-month readers, 500K+ neighborhood builders, infinite prospects. [Explore Sponsorship] |

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the affect of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.

{kind=link}