
Fashionable information groups face a important problem: their analytical datasets are scattered throughout a number of storage methods and codecs, creating operational complexity that slows down insights and hampers collaboration. Knowledge scientists waste precious time navigating between totally different instruments to entry information saved in numerous places, whereas information engineers wrestle to take care of constant efficiency and governance throughout disparate storage options. Groups usually discover themselves locked into particular question engines or analytics instruments based mostly on the place their information resides, limiting their capacity to decide on the perfect software for every analytical process.
Amazon SageMaker Unified Studio addresses this fragmentation by offering a single surroundings the place groups can entry and analyze organizational information utilizing AWS analytics and AI/ML companies. The brand new Amazon S3 Tables integration solves a elementary drawback: it permits groups to retailer their information in a unified, high-performance desk format whereas sustaining the flexibleness to question that very same information seamlessly throughout a number of analytics engines—whether or not via JupyterLab notebooks, Amazon Redshift, Amazon Athena, or different built-in companies. This eliminates the necessity to duplicate information or compromise on software alternative, permitting groups to deal with producing insights moderately than managing information infrastructure complexity.
Desk buckets are the third sort of S3 bucket, happening alongside the prevailing basic goal buckets, listing buckets, and now the fourth sort – vector buckets. You possibly can consider a desk bucket as an analytics warehouse that may retailer Apache Iceberg tables with numerous schemas. Moreover, S3 Tables ship the identical sturdiness, availability, scalability, and efficiency traits as S3 itself, and routinely optimize your storage to maximise question efficiency and to attenuate value.
On this publish, you learn to combine SageMaker Unified Studio with S3 tables and question your information utilizing Athena, Redshift, or Apache Spark in EMR and Glue.
Integrating S3 Tables with AWS analytics companies
S3 desk buckets combine with AWS Glue Knowledge Catalog and AWS Lake Formation to permit AWS analytics companies to routinely uncover and entry your desk information. For extra data, see creating an S3 Tables catalog.
Earlier than you get began with SageMaker Unified Studio, your administrator should first create a site within the SageMaker Unified Studio and offer you the URL. For extra data, see the SageMaker Unified Studio Administrator Information.
Should you’ve by no means used S3 Tables in SageMaker Studio, you may enable it to allow the S3 Tables analytics integration once you create a brand new S3 Tables catalog in SageMaker Unified Studio.
Be aware: This integration must be configured individually in every AWS Area.
While you combine utilizing SageMaker Unified Studio, it takes the next actions in your account:
- Creates a brand new AWS Identification and Entry Administration (IAM) service position that provides AWS Lake Formation entry to all of your tables and desk buckets in the identical AWS Area the place you’ll provision the assets. This permits Lake Formation to handle entry, permissions, and governance for all present and future desk buckets.
- Creates a catalog from an S3 desk bucket within the AWS Glue Knowledge Catalog.
- Add the Redshift service position (
AWSServiceRoleForRedshift)as a Lake Formation Learn-only administrator permissions.


Conditions
Creating catalogs from S3 desk buckets in SageMaker Unified Studio
To get began utilizing S3 Tables in SageMaker Unified Studio you create a brand new Lakehouse catalog with S3 desk bucket supply utilizing the next steps.
- Open the SageMaker console and use the area selector within the prime navigation bar to decide on the suitable AWS Area.
- Choose your SageMaker area.
- Choose or create a brand new mission you need to create a desk bucket in.
- Within the navigation menu choose Knowledge, then choose + so as to add a brand new information supply.
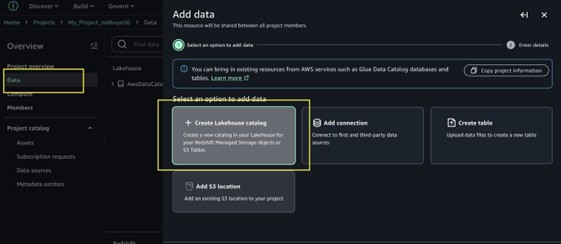
- Select Create Lakehouse catalog.
- Within the add catalog menu, select S3 Tables because the supply.
- Enter a reputation for the catalog blogcatalog.
- Enter database identify taxidata.
- Select Create catalog.
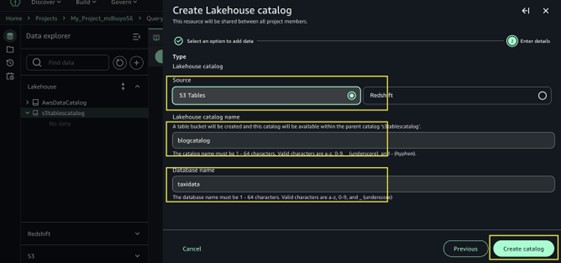
- The next steps will aid you create these assets in your AWS account:
- A new S3 desk bucket and the corresponding Glue youngster catalog underneath the mum or dad Catalog
s3tablescatalog. - Go to Glue console, increase Knowledge Catalog, Click on databases, a brand new database inside that Glue youngster catalog. The database identify will match the database identify you offered.
- Look forward to the catalog provisioning to complete.
- A new S3 desk bucket and the corresponding Glue youngster catalog underneath the mum or dad Catalog
- Create tables in your database, then use the Question Editor or a Jupyter pocket book to run queries in opposition to them.
Creating and querying S3 desk buckets
After including an S3 Tables catalog, it may be queried utilizing the format s3tablescatalog/blogcatalog. You possibly can start creating tables inside the catalog and question them in SageMaker Studio utilizing the Question Editor or JupyterLab. For extra data, see Querying S3 Tables in SageMaker Studio.
Be aware: In SageMaker Unified Studio, you may create S3 tables solely utilizing the Athena engine. Nevertheless, as soon as the tables are created, they are often queried utilizing Athena, Redshift, or via Spark in EMR and Glue.
Utilizing the question editor
Making a desk within the question editor
- Navigate to the mission you created within the prime heart menu of the SageMaker Unified Studio house web page.
- Develop the Construct menu within the prime navigation bar, then select Question editor.
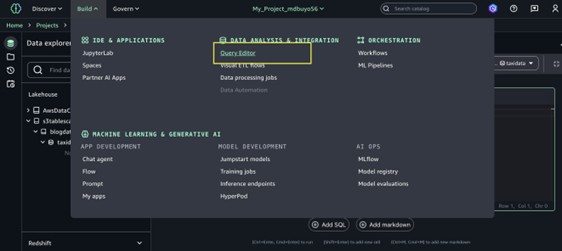
- Launch a brand new Question Editor tab. This software features as a SQL pocket book, enabling you to question throughout a number of engines and construct visible information analytics options.
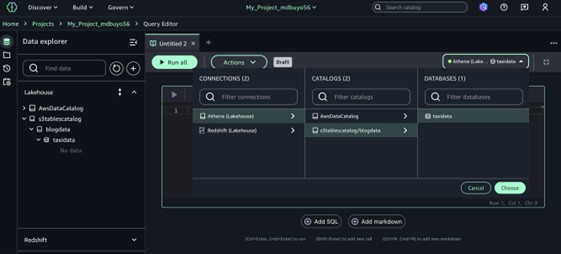
- Choose a knowledge supply in your queries through the use of the menu within the upper-right nook of the Question Editor.
- Underneath Connections, select Lakehouse (Athena) to connect with your Lakehouse assets.
- Underneath Catalogs, select S3tablescatalog/blogcatalog.
- Underneath Databases, select the identify of the database in your S3 tables.
- Choose Select to connect with the database and question engine.
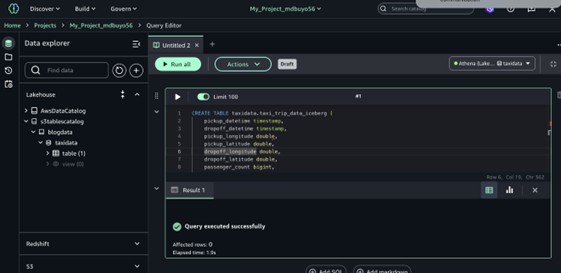
- Run the next SQL question to create a brand new desk within the catalog.
After you create the desk, you may browse to it within the Knowledge explorer by selecting S3tablescatalog →s3tableCatalog →taxidata→taxi_trip_data_iceberg.
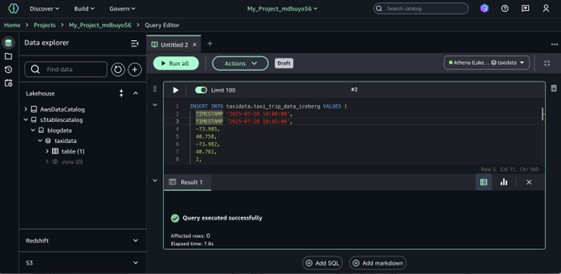
- Insert information right into a desk with the next DML assertion.
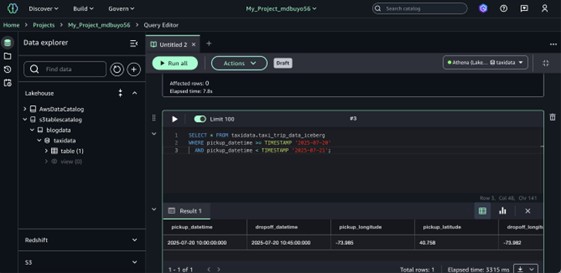
- Choose information from a desk with the next question.
You possibly can study extra concerning the Question Editor and discover further SQL examples within the SageMaker Unified Studio documentation.
Earlier than continuing with JupyterLab setup:
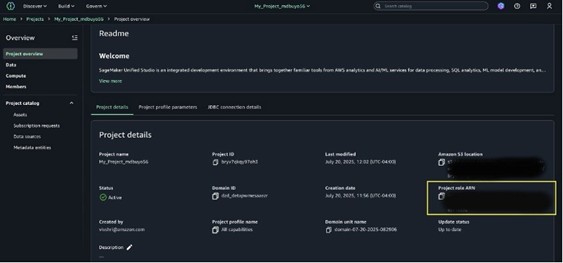
To create tables utilizing the Spark engine by way of a Spark connection, you should grant the S3TableFullAccess permission to the Challenge Function ARN.
- Find the Challenge Function ARN in SageMaker Unified Studio Challenge Overview.
- Go to the IAM console then choose Roles.
- Seek for and choose the Challenge Function.
- Connect the S3TableFullAccess coverage to the position, in order that the mission has full entry to work together with S3 Tables.
Utilizing JupyterLab
- Navigate to the mission you created within the prime heart menu of the SageMaker Unified Studio house web page.
- Develop the Construct menu within the prime navigation bar, then select JupyterLab.
- Create a brand new pocket book.
- Choose Python3 Kernel.
- Select PySpark because the connection sort.

- Choose your desk bucket and namespace as the info supply in your queries:
- For Spark engine, execute question
USE s3tablescatalog_blogdata
- For Spark engine, execute question
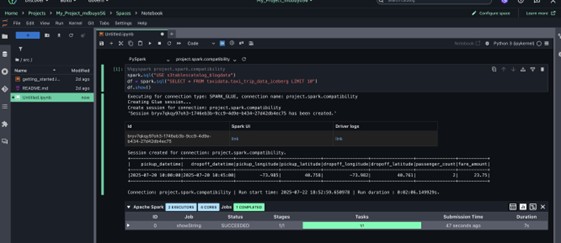
Querying information utilizing Redshift:
On this part, we stroll via how you can question the info utilizing Redshift inside SageMaker Unified Studio.
- From the SageMaker Studio house web page, select your mission identify within the prime heart navigation bar.
- Within the navigation panel, increase the Redshift mission folder.
- Open the blogdata@s3tablescatalog database.
- Develop the taxidata schema.
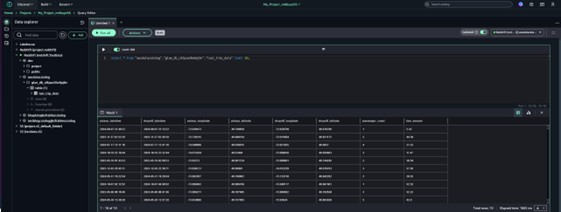
- Underneath the Tables part, find and increase taxi_trip_data_iceberg.
- Evaluation the desk metadata to view all columns and their corresponding information sorts.
- Open the Pattern information tab to preview a small, consultant subset of information.
- Select Actions.
- Choose Preview information from the dropdown to open and think about the total dataset within the information viewer.
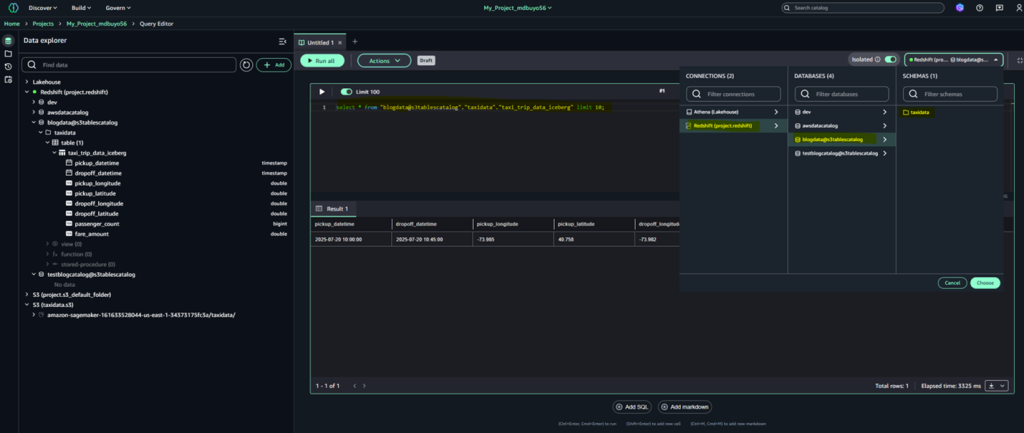
When you choose your desk, the Question Editor routinely opens with a pre-populated SQL question. This default question retrieves the prime 10 information from the desk, supplying you with an prompt preview of your information. It makes use of normal SQL naming conventions, referencing the desk by its absolutely certified identify within the format database_schema.table_name. This strategy ensures the question precisely targets the supposed desk, even in environments with a number of databases or schemas.
Greatest practices and concerns
The next are some concerns it’s best to pay attention to.
- While you create an S3 desk bucket utilizing the S3 console, integration with AWS analytics companies is enabled routinely by default. You may also select to arrange the mixing manually via a guided course of within the console. Additionally, once you create S3 Desk bucket programmatically utilizing the AWS SDK, or AWS CLI, or REST APIs, the mixing with AWS analytics companies will not be routinely configured. That you must manually carry out the steps required to combine the S3 Desk bucket with AWS Glue Knowledge Catalog and Lake Formation, permitting these companies to find and entry the desk information.
- When creating an S3 desk bucket to be used with AWS analytics companies like Athena, we advocate utilizing all lowercase letters for the desk bucket identify. This requirement ensures correct integration and visibility inside the AWS analytics ecosystem. Study extra about it from getting began with S3 tables.
- S3 Tables supply automated desk upkeep options like compaction, snapshot administration, and unreferenced file elimination to optimize information for analytics workloads. Nevertheless, there are some limitations to contemplate. Please learn extra on it from concerns and limitations for upkeep jobs.
Conclusion
On this publish, we mentioned how you can use SageMaker Unified Studio’s integration with S3 Tables to boost your information analytics workflows. The publish defined the setup course of, together with making a Lakehouse catalog with S3 desk bucket supply, configuring crucial IAM roles, and establishing integration with AWS Glue Knowledge Catalog and Lake Formation. We walked you thru sensible implementation steps, from creating and managing Apache Iceberg based mostly S3 tables to executing queries via each the Question Editor and JupyterLab with PySpark, in addition to accessing and analyzing information utilizing Redshift.
To get began with SageMaker Unified Studio and S3 Tables integration, go to Entry Amazon SageMaker Unified Studio documentation.
About authors

{kind=link}