
While you’re spinning up your Amazon OpenSearch Service area, it’s good to determine the storage, occasion sorts, and occasion rely; determine the sharding methods and whether or not to make use of a cluster supervisor; and allow zone consciousness. Usually, we contemplate storage as a tenet for figuring out occasion rely, however not different parameters. On this publish, we provide some suggestions primarily based on T-shirt sizing for log analytics workloads.
Log analytics and streaming workload traits
While you use OpenSearch Service to your streaming workloads, you ship knowledge from a number of sources into OpenSearch Service. OpenSearch Service indexes your knowledge in an index that you simply outline.
Log knowledge naturally follows a time collection sample, and subsequently a time-based indexing technique (every day or weekly indexes) is really helpful. For environment friendly administration of log knowledge, you will need to implement time-based index patterns and set retention intervals. You additional outline time slicing and a retention interval for the information to handle its lifecycle in your area.
For illustration, contemplate that you’ve a knowledge supply producing a steady stream of log knowledge, and also you’ve configured a every day rolling index and set a retention interval of three days. Because the logs arrive, OpenSearch Service creates an index per day with names like stream1_2025.05.21, stream1_2025.05.22, and so forth. The prefix stream1_* is what we name an index sample, a naming conference that helps group-related indexes.
The next diagram reveals three major shards for every every day index. These shards are deployed throughout three OpenSearch Service knowledge cases, with one duplicate for every major shard. (For simplicity, the diagram doesn’t present that major and duplicate shards are all the time positioned on totally different cases for fault tolerance.)
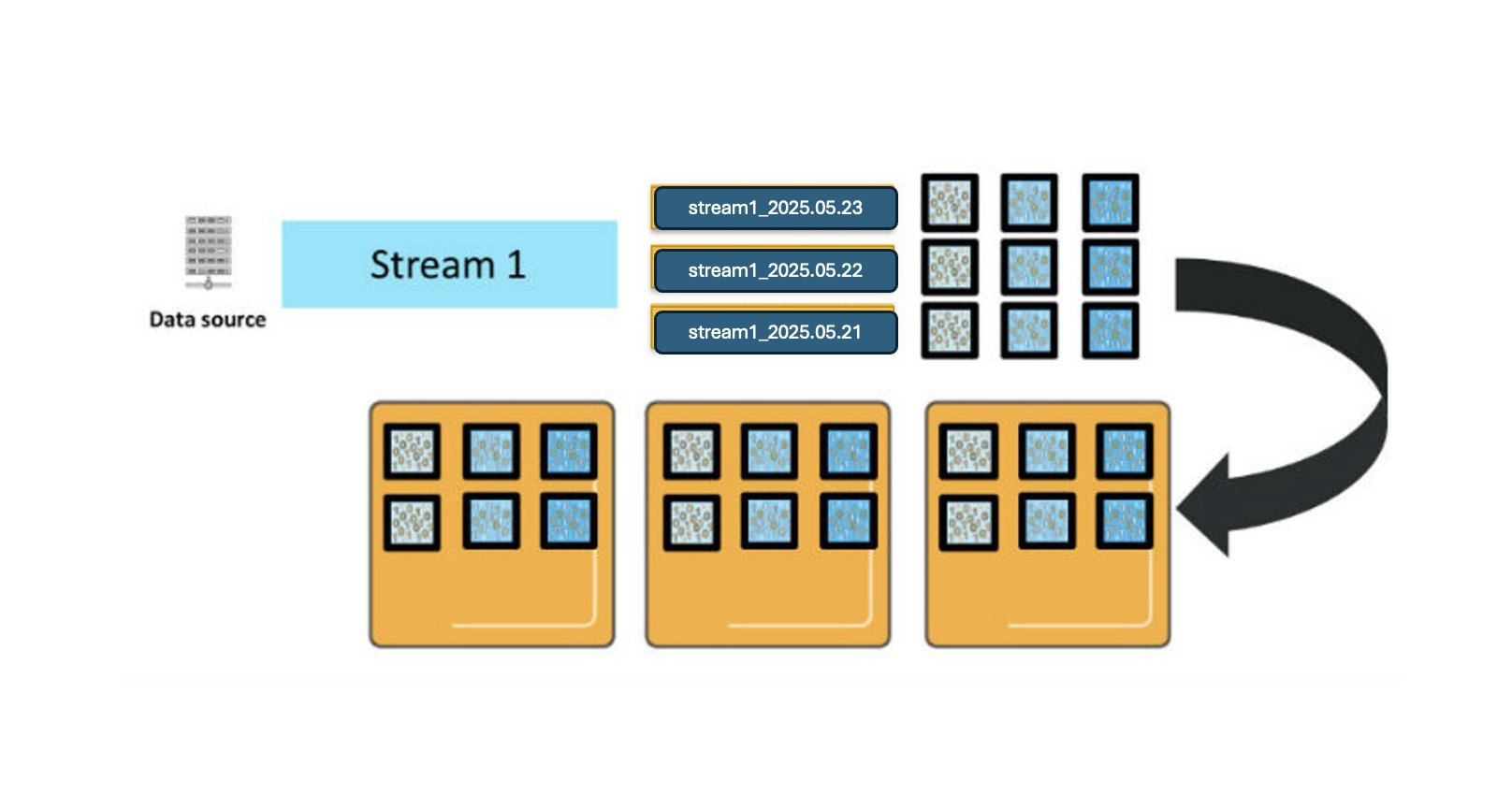
When OpenSearch Service processes new log entries, they’re despatched to all related major shards and their replicas within the energetic index, which on this instance is just at present’s index because of the every day index configuration.
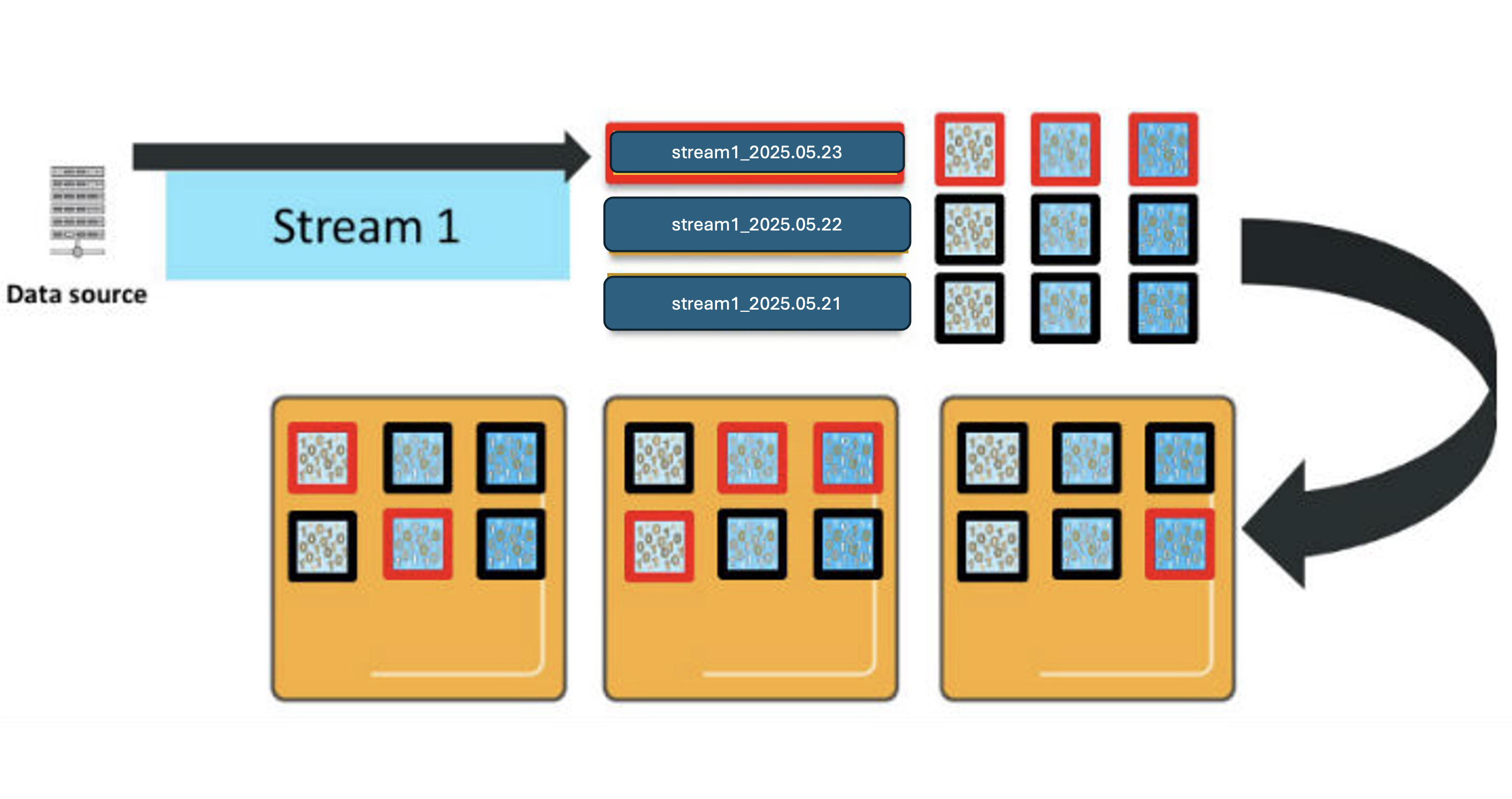
There are a number of vital traits of how OpenSearch Service processes your new entries:
- Whole shard rely – Every index sample can have a D * P * (1 + R) whole shards, the place D represents retention in days, P represents major shards, and R is the variety of replicas. These shards are distributed throughout your knowledge nodes.
- Lively index – Time slicing implies that new log entries are solely written to at present’s index.
- Useful resource utilization – When sending a _bulk request with log entries, these are distributed throughout all shards within the energetic index. In our instance with three major shards and one duplicate per shard, that’s a complete of six shards processing new knowledge concurrently, requiring 6 vCPUs to effectively deal with a single
_bulkrequest.
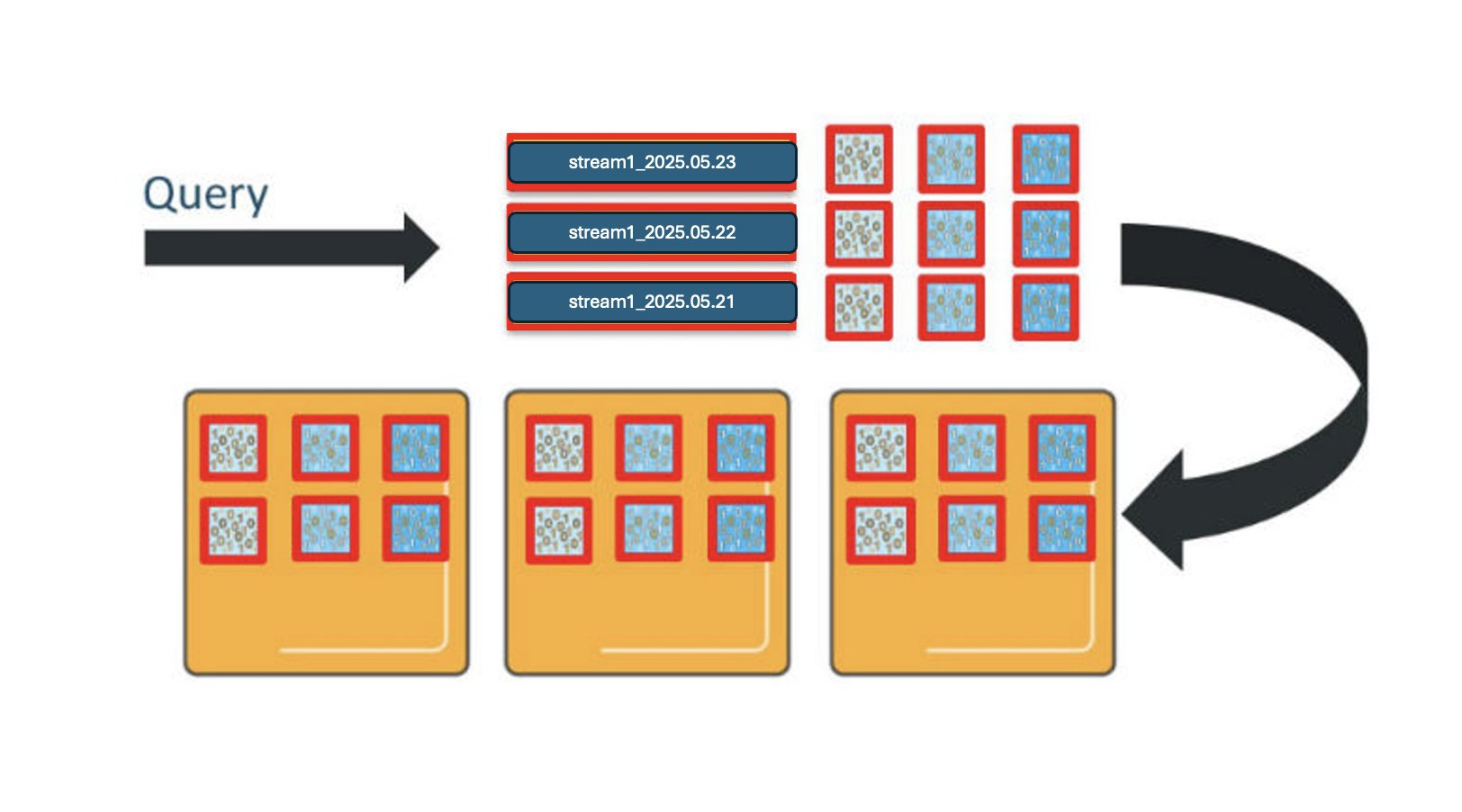
Equally, OpenSearch Service distributes queries throughout the shards for the indexes concerned. If you happen to question this index sample throughout all 3 days, you’ll interact 9 shards, and wish 9 vCPUs to course of the request.
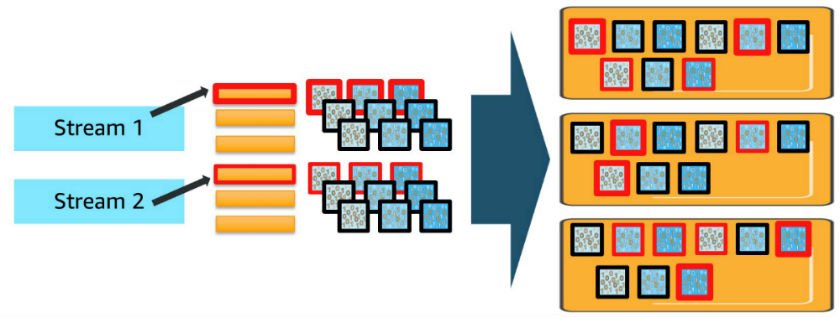
This may get much more sophisticated while you add in additional knowledge streams and index patterns. For every further knowledge stream or index sample, you deploy shards for every of the every day indexes and use vCPUs to course of requests in proportion to the shards deployed, as proven within the previous diagram. While you make concurrent requests to a couple of index, every shard for all of the indexes concerned should course of these requests.
Cluster capability
Because the variety of index patterns and concurrent requests will increase, you possibly can rapidly overwhelm the cluster’s assets. OpenSearch Service contains inside queues that buffer requests and mitigate this concurrency demand. You possibly can monitor these queues utilizing the _cat/thread_pool API, which reveals queue depths and helps you perceive when your cluster is approaching capability limits.
One other complicating dimension is that the time to course of your updates and queries is determined by the contents of the updates and queries. As requests are available in, the queues are filling on the price you might be sending them. They’re draining at a price that’s ruled by the out there vCPUs, the time they tackle every request, and the processing time for that request. You possibly can interleave extra requests if these requests clear in a millisecond than in the event that they clear in a second. You should utilize the _nodes/stats OpenSearch API to observe common load in your CPUs. For extra details about the question phases, discuss with A question, or There and Again Once more on the OpenSearch weblog.
If you happen to see the queue depths growing, you might be transferring right into a “warning” space, the place the cluster is dealing with load. However for those who proceed, you can begin to exceed the out there queues and should scale so as to add extra CPUs. If you happen to begin to see load growing, which is correlated with queue depth growing, you might be additionally in a “warning” space and may contemplate scaling.
Suggestions
For sizing a website, contemplate the next steps:
- Decide the storage required – Whole storage = (every day supply knowledge in bytes × 1.45) × (number_of_replicas + 1) × variety of days retained. This accounts for the extra 45% overhead on every day supply knowledge, damaged down as follows:
- 10% for bigger index dimension than supply knowledge.
- 5% for working system overhead (reserved by Linux for system restoration and disk defragmentation safety).
- 20% for OpenSearch reserved area per occasion (section merges, logs, and inside operations).
- 10% for added storage buffer (minimizes affect of node failure and Availability Zone outages).
- Outline the shard rely – Approximate variety of major shards = storage dimension required per index / desired shard dimension. Spherical as much as the closest a number of of your knowledge node rely to take care of even distribution. For extra detailed steerage on shard sizing and distribution methods, discuss with “Amazon OpenSearch Service 101: What number of shards do I want” For log analytics workloads, contemplate the next:
- Beneficial shard dimension: 30–50 GB
- Optimum goal: 50 GB per shard
- Calculate CPU necessities – Beneficial ratio is 1.25 vCPU:1 Shard for decrease knowledge volumes. Increased ratios are really helpful for bigger volumes. Goal utilization is 60% common, 80% most.
- Select the best occasion kind – Take into account the next primarily based in your nodes:
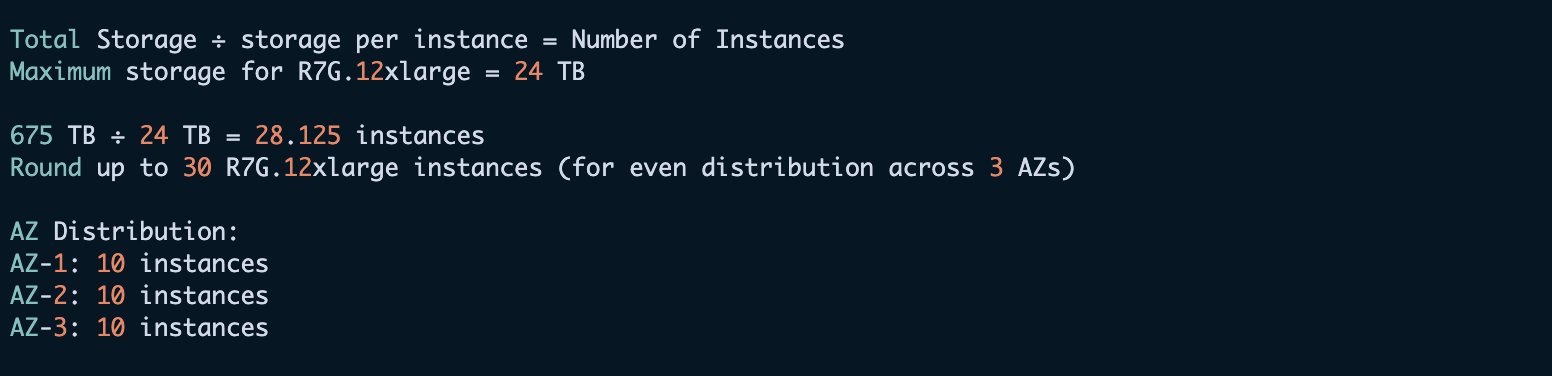
Let’s take a look at an instance for area sizing. The preliminary necessities are as follows:
- Every day log quantity: 3 TB
- Retention interval: 3 months (90 days)
- Reproduction rely: 1

We make the next occasion calculation.
The next desk recommends cases, quantity of supply knowledge, storage wanted for 7 days of retention, and energetic shards primarily based on the previous pointers.
| T-Shirt Measurement | Information (Per Day) | Storage Wanted (with 7 days Retention) | Lively Shards | Information Nodes | Major Nodes |
| XSmall | 10 GB | 175 GB | 2 @ 50 GB | 3 * r7g.massive. search | 3 * m7g.massive. search |
| Small | 100 GB | 1.75 TB | 6 @ 50 GB | 3 * r7g.xlarge. search | 3 * m7g.massive. search |
| Medium | 500 GB | 8.75 TB | 30 @ 50 GB | 6 * r7g.2xlarge.search | 3 * m7g.massive. search |
| Massive | 1 TB | 17.5 TB | 60 @ 50 GB | 6 * r7g.4xlarge.search | 3 * m7g.massive. search |
| XLarge | 10 TB | 175 TB | 600 @ 50 GB | 30 * i4g.8xlarge | 3 * m7g.2xlarge.search |
| XXL | 80 TB | 1.4 PB | 2400 @ 50 GB | 87 * I4g.16xlarge | 3 * m7g.4xlarge.search |
As with all sizing suggestions, these pointers signify a place to begin and are primarily based on assumptions. Your workload will differ, and so your precise wants will differ from these suggestions. Be sure that to deploy, monitor, and alter your configuration as wanted.
For T-shirt sizing the workloads, an extra-small use case encompasses 10 GB or much less of knowledge per day from a single knowledge stream to a single index sample. A small use case falls between 10–100 GB per day of knowledge, a medium use case between 100–500 GB of knowledge, and so forth. Default occasion rely per area is 80 for many of the occasion household. Discuss with the “Amazon OpenSearch Service quotas “ for particulars.
Moreover, contemplate the next finest practices:
Conclusion
This publish supplied complete pointers for sizing your OpenSearch Service area for log analytic workloads, masking a number of vital elements. These suggestions function a strong start line, however every workload has distinctive traits. For optimum efficiency, contemplate implementing further optimizations like knowledge tiering and storage tiers. Consider cost-saving choices comparable to reserved cases, and scale your deployment primarily based on precise efficiency metrics and queue depths.By following these pointers and actively monitoring your deployment, you possibly can construct a well-performing OpenSearch Service area that meets your log analytics wants whereas sustaining effectivity and cost-effectiveness.
In regards to the authors

{kind=link}