
This submit can be authored by Vedha Avali and Genavieve Chick who carried out the code evaluation described and summarized under.
For the reason that launch of OpenAI’s ChatGPT, many firms have been releasing their very own variations of enormous language fashions (LLMs), which can be utilized by engineers to enhance the method of code improvement. Though ChatGPT continues to be the preferred for common use circumstances, we now have fashions created particularly for programming, resembling GitHub Copilot and Amazon Q Developer. Impressed by Mark Sherman’s weblog submit analyzing the effectiveness of Chat GPT-3.5 for C code evaluation, this submit particulars our experiment testing and evaluating GPT-3.5 versus 4o for C++ and Java code overview.
We collected examples from the SEI CERT Safe Coding requirements for C++ and Java. Every rule in the usual comprises a title, an outline, noncompliant code examples, and compliant options. We analyzed whether or not ChatGPT-3.5 and ChatGPT-4o would accurately determine errors in noncompliant code and accurately acknowledge compliant code as error-free.
General, we discovered that each the GPT-3.5 and GPT-4o fashions are higher at figuring out errors in noncompliant code than they’re at confirming correctness of compliant code. They’ll precisely uncover and proper many errors however have a tough time figuring out compliant code as such. When evaluating GPT-3.5 and GPT-4o, we discovered that 4o had greater correction charges on noncompliant code and hallucinated much less when responding to compliant code. Each GPT 3.5 and GPT-4o had been extra profitable in correcting coding errors in C++ when in comparison with Java. In classes the place errors had been typically missed by each fashions, immediate engineering improved outcomes by permitting the LLM to give attention to particular points when offering fixes or recommendations for enchancment.
Evaluation of Responses
We used a script to run all examples from the C++ and Java safe coding requirements by means of GPT-3.5 and GPT-4o with the immediate
What’s flawed with this code?
Every case merely included the above phrase because the system immediate and the code instance because the consumer immediate. There are a lot of potential variations of this prompting technique that might produce completely different outcomes. As an illustration, we might have warned the LLMs that the instance is perhaps right or requested a particular format for the outputs. We deliberately selected a nonspecific prompting technique to find baseline outcomes and to make the outcomes akin to the earlier evaluation of ChatGPT-3.5 on the CERT C safe coding commonplace.
We ran noncompliant examples by means of every ChatGPT mannequin to see whether or not the fashions had been able to recognizing the errors, after which we ran the compliant examples from the identical sections of the coding requirements with the identical prompts to check every mannequin’s skill to acknowledge when code is definitely compliant and freed from errors. Earlier than we current general outcomes, we wish to current the categorization schemes that we created for noncompliant and compliant responses from ChatGPT and supply one illustrative instance for every response class. In these illustrative examples, we included responses underneath completely different experimental circumstances—in each C++ and Java, in addition to responses from GPT-3.5 and GPT-4o—for selection. The complete set of code examples, responses from each ChatGPT fashions, and the classes that we assigned to every response, could be discovered at this hyperlink.
Noncompliant Examples
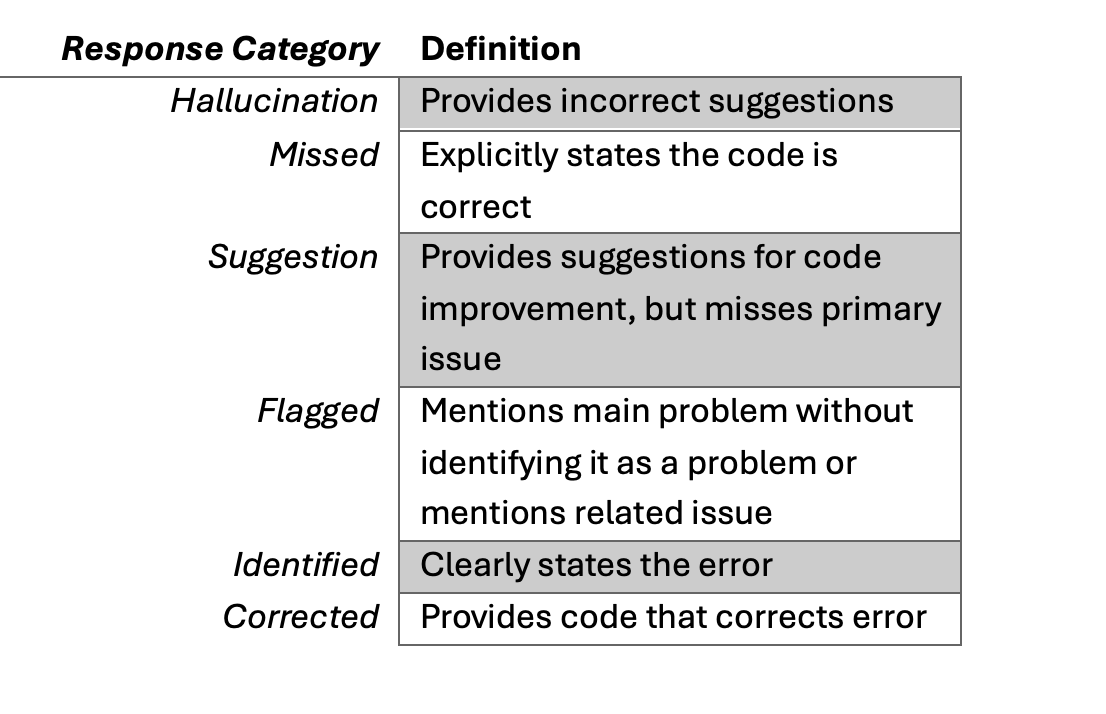
We labeled the responses to noncompliant code into the next classes:
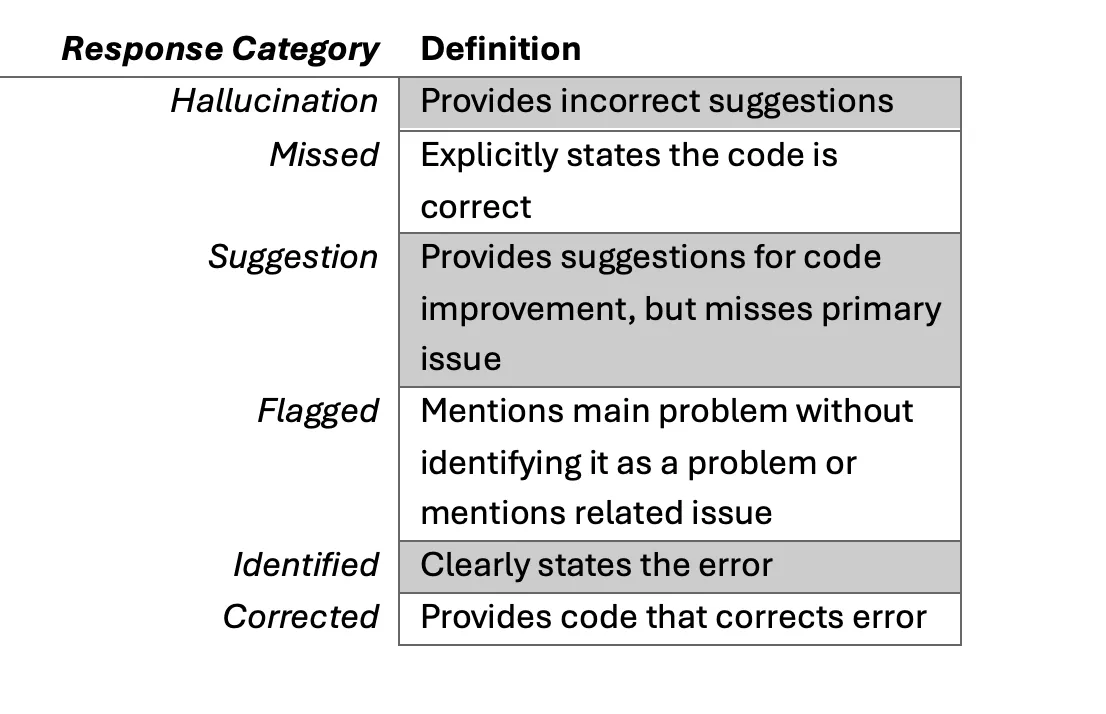
Our first purpose was to see if OpenAI’s fashions would accurately determine and proper errors in code snippets from C++ and Java and produce them into compliance with the SEI coding commonplace for that language. The next sections present one consultant instance for every response class as a window into our evaluation.
Instance 1: Hallucination
NUM01-J, Ex. 3: Don’t carry out bitwise and arithmetic operations on the identical knowledge.
This Java instance makes use of bitwise operations on unfavourable numbers ensuing within the flawed reply for -50/4.

GPT-4o Response

On this instance, the reported downside is that the shift is just not carried out on byte, quick, int, or lengthy, however the shift is clearly carried out on an int, so we marked this as a hallucination.
Instance 2: Missed
ERR59-CPP, Ex. 1: Don’t throw an exception throughout execution boundaries.
This C++ instance throws an exception from a library perform signifying an error. This may produce unusual responses when the library and software have completely different ABIs.

GPT-4o Response

This response signifies that the code works and handles exceptions accurately, so it’s a miss although it makes different recommendations.
Instance 3: Options
DCL55-CPP, Ex. 1: Keep away from info leakage when passing a category object throughout a belief boundary.
On this C++ instance, the padding bits of information in kernel house could also be copied to consumer house after which leaked, which could be harmful if these padding bits comprise delicate info.

GPT-3.5 Response

This response fails to acknowledge this situation and as an alternative focuses on including a const declaration to a variable. Whereas this can be a legitimate suggestion, this advice doesn’t immediately have an effect on the performance of the code, and the safety situation talked about beforehand continues to be current. Different widespread recommendations embrace including import statements, exception dealing with, lacking variable and performance definitions, and executing feedback.
Instance 4: Flagged
MET04-J, Ex. 1: Don’t improve the accessibility of overridden or hidden strategies
This flagged Java instance exhibits a subclass rising accessibility of an overriding technique.

GPT-3.5 Response

This flagged instance acknowledges the error pertains to the override, but it surely doesn’t determine the primary situation: the subclasses’ skill to alter the accessibility when overriding.
Instance 5: Recognized
EXP57-CPP, Ex. 1: Don’t forged or delete tips that could incomplete courses
This C++ instance removes a pointer to an incomplete class sort; thus, creating undefined conduct.

GPT-3.5 Response

This response identifies the error of making an attempt to delete a category pointer earlier than defining the category. Nevertheless, it doesn’t present the corrected code, so it’s labeled as recognized.
Instance 6: Corrected
DCL00-J, Ex. 2: Stop class initialization cycles
This easy Java instance contains an interclass initialization cycle, which might result in a mixture up in variable values. Each GPT-3.5 and GPT-4o corrected this error.

GPT-4o Response

This snippet from 4o’s response identifies the error and gives an answer just like the supplied compliant answer.
Compliant Examples
We examined GPT-3.5 and GPT-4o on every of the compliant C++ and Java code snippets to see if they’d acknowledge that there’s nothing flawed with them. As with the noncompliant examples, we submitted every compliant instance because the consumer immediate with a system prompts that said, “What’s flawed with this code?” We labeled responses to compliant examples into the next classes.

It ought to be famous {that a} completely different prompting technique might simply enhance the outcomes by giving the LLM extra particular info. For instance, we might have said that the code snipped is perhaps right, and if that’s the case, that the LLM ought to explicitly state that it’s right. Our purpose on this part is to explain the baseline conduct of the LLM and to stay comparable with the prior outcomes. We discover the results of refining the immediate within the remaining part of this submit.
This part gives examples of the several types of responses (right, suggestion, and hallucination) ChatGPT supplied. Once more, we selected examples from each C++ and Java, and from each ChatGPT fashions for selection. readers can see the complete outcomes for all compliant examples at this hyperlink.
Instance 1: Hallucination
EXP51-CPP, C. Ex. 1: Don’t delete an array by means of a pointer of the inaccurate sort
On this compliant C++ instance, an array of Derived objects is saved in a pointer with the static sort of Derived, which doesn’t end in undefined conduct.

GPT-4o Response

We labeled this response as a hallucination because it brings the compliant code into noncompliance with the usual. The GPT-4o response treats the array of Derived objects as Base objects earlier than deleting it. Nevertheless, this can end in undefined conduct regardless of the digital destructor declaration, and this might additionally end in pointer arithmetic being carried out incorrectly on polymorphic objects.
Instance 2: Suggestion
EXP00-J, EX.1: Don’t ignore values returned by strategies
This compliant Java code demonstrates a technique to test values returned by a way.

GPT-4o Response

This response gives legitimate recommendations for code enchancment however doesn’t explicitly state that the code is right or that it’ll accurately execute as written.
Instance 3: Right
CTR52-CPP, Ex. 1: Assure that library capabilities don’t overflow
The next compliant C++ code copies integer values from the src vector to the dest vector and ensures that overflow won’t happen by initializing dest to a enough preliminary capability.

GPT-3.5 Response

In examples like this one, the place the LLM explicitly states that the code has no errors earlier than offering recommendations, we determined to label this as “Right.”
Outcomes: LLMs Confirmed Higher Accuracy with Noncompliant Code

First, our evaluation confirmed that the LLMs had been much more correct at figuring out flawed code than they had been at confirming right code. To extra clearly present this comparability, we mixed among the classes. Thus, for compliant responses suggestion and hallucination grew to become incorrect. For noncompliant code samples, corrected and recognized counted in direction of right and the remainder incorrect. Within the graph above, GPT-4o (the extra correct mannequin, as we talk about under) accurately discovered the errors 83.6 p.c of the time for noncompliant code, but it surely solely recognized 22.5 p.c of compliant examples as right. This pattern was fixed throughout Java and C++ for each LLMs. The LLMs had been very reluctant to acknowledge compliant code as legitimate and virtually at all times made recommendations even after stating, “this code is right.”
GPT-4o Out-performed GPT-3.5
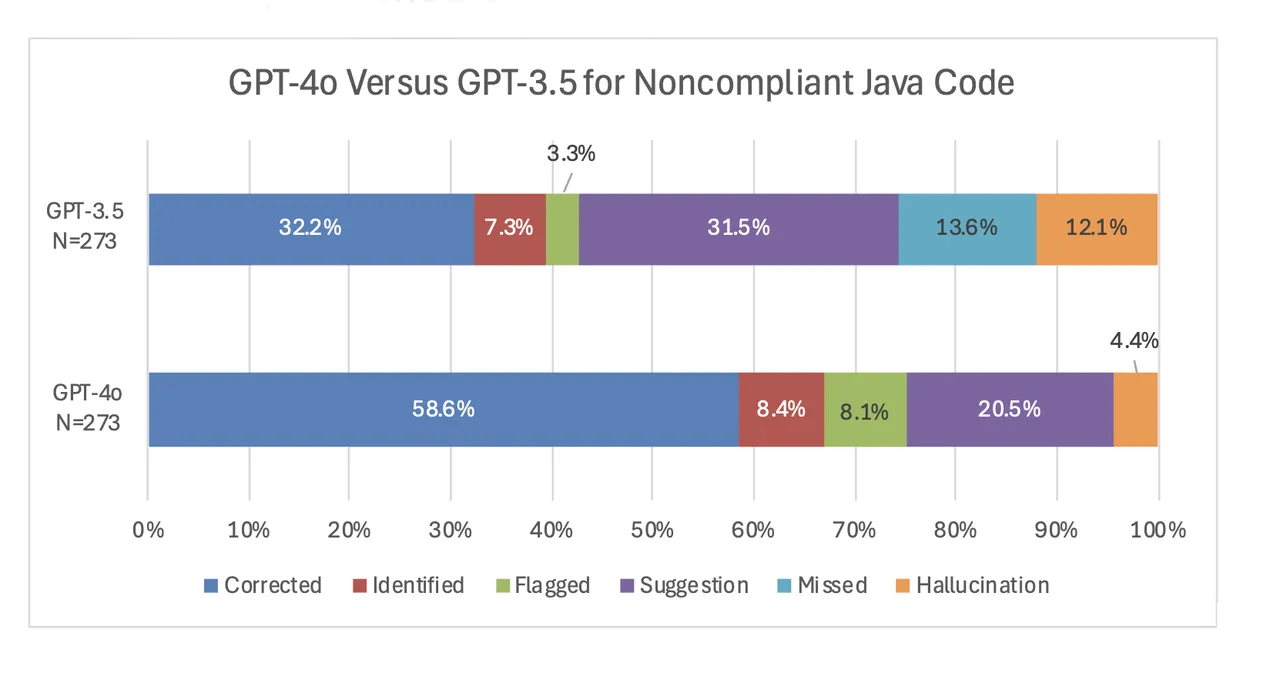
General, the outcomes additionally confirmed that GPT-4o carried out considerably higher than GPT-3.5. First, for the noncompliant code examples, GPT-4o had the next price of correction or identification and decrease charges of missed errors and hallucinations. The above determine exhibits actual outcomes for Java, and we noticed comparable outcomes for the C++ examples with an identification/correction price of 63.0 p.c for GPT-3.5 versus a considerably greater price of 83.6 p.c for GPT-4o.
The next Java instance demonstrates the distinction between GPT-3.5 and GPT-4o. This noncompliant code snippet comprises a race situation within the getSum() technique as a result of it isn’t thread secure. On this instance, we submitted the noncompliant code on the left to every LLM because the consumer immediate, once more with the system immediate stating, “What’s flawed with this code?”
VNA02-J, Ex. 4: Be certain that compound operations on shared variables are atomic

GPT-3.5 Response

GPT-4o Response

GPT-3.5 said there have been no issues with the code whereas GPT-4o caught and glued three potential points, together with the thread security situation. GPT-4o did transcend the compliant answer, which synchronizes the getSum() and setValues() strategies, to make the category immutable. In follow, builders would have the chance to work together with the LLM if they didn’t need this alteration of intent.
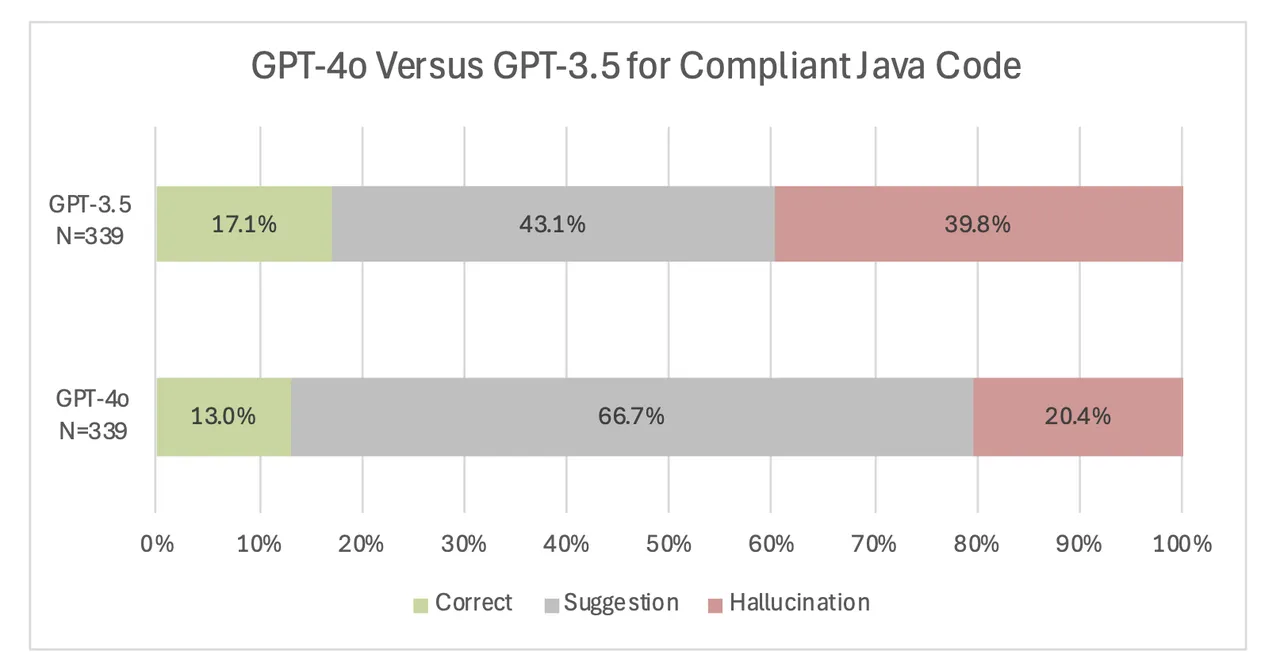
With the grievance code examples, we typically noticed decrease charges of hallucinations, however GPT 4o’s responses had been a lot wordier and supplied many recommendations, making the mannequin much less more likely to cleanly determine the Java code as right. We noticed this pattern of decrease hallucinations within the C++ examples as properly, as GPT-3.5 hallucinated 53.6 p.c of the time on the compliant C++ code, however solely 16.3 p.c of the time when utilizing GPT-4o.
The next Java instance demonstrates this tendency for GPT-3.5 to hallucinate whereas GPT-4o gives recommendations whereas being reluctant to substantiate correctness. This compliant perform clones the date object earlier than returning it to make sure that the unique inner state throughout the class is just not mutable. As earlier than, we submitted the compliant code to every LLM because the consumer immediate, with the system immediate, “What’s flawed with this code?”
OBJ-05, Ex 1: Don’t return references to non-public mutable class members

GPT-3.5 Response

GPT-3.5’s response states that the clone technique is just not outlined for the Date class, however this assertion is inaccurate because the Date class will inherit the clone technique from the Object class.
GPT-4o Response

GPT-4o’s response nonetheless doesn’t determine the perform as right, however the potential points described are legitimate recommendations, and it even gives a suggestion to make this system thread-safe.
LLMs Had been Extra Correct for C++ Code than for Java Code
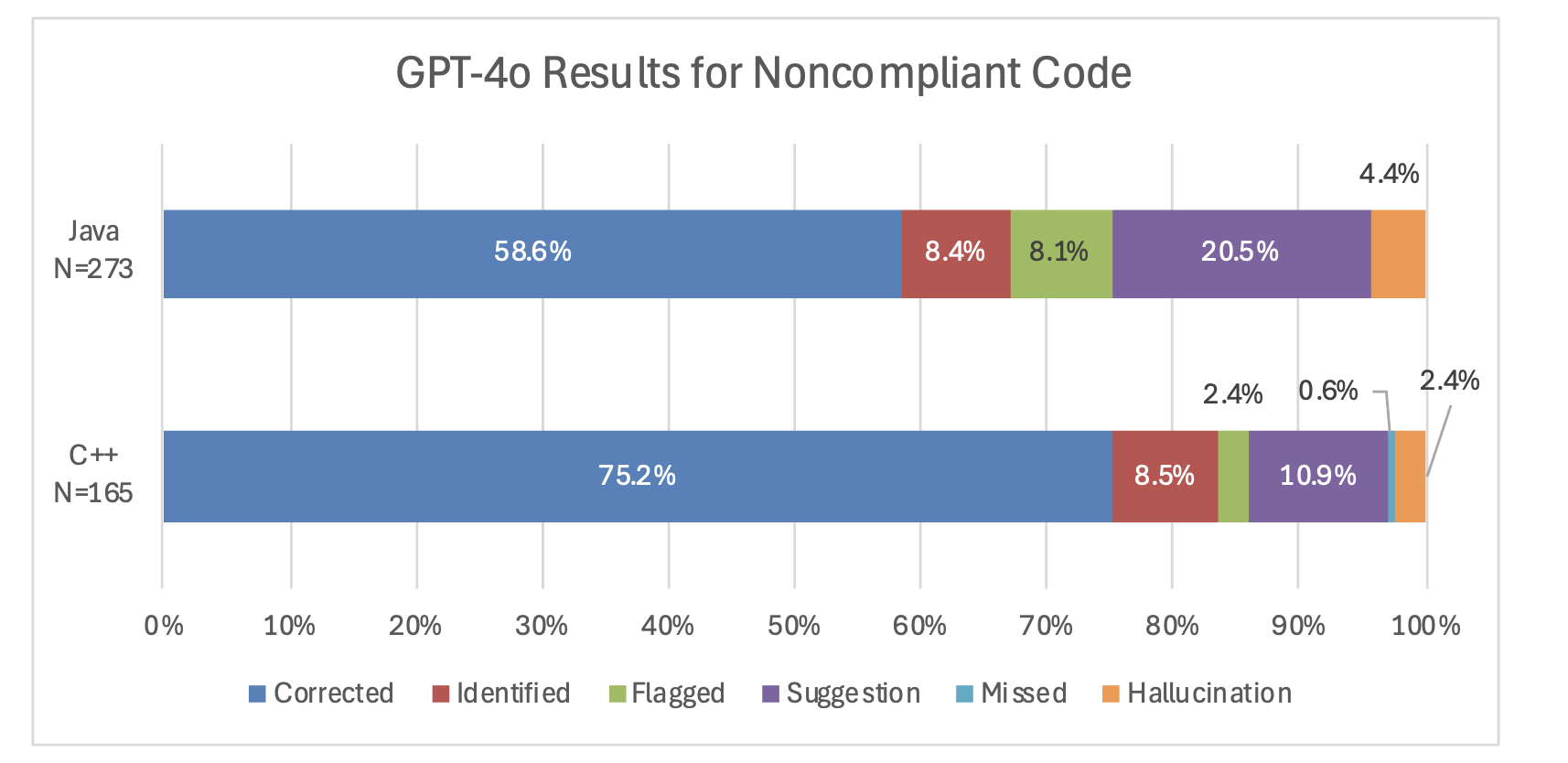
This graph exhibits the distribution of responses from GPT-4o for each Java and C++ noncompliant examples.
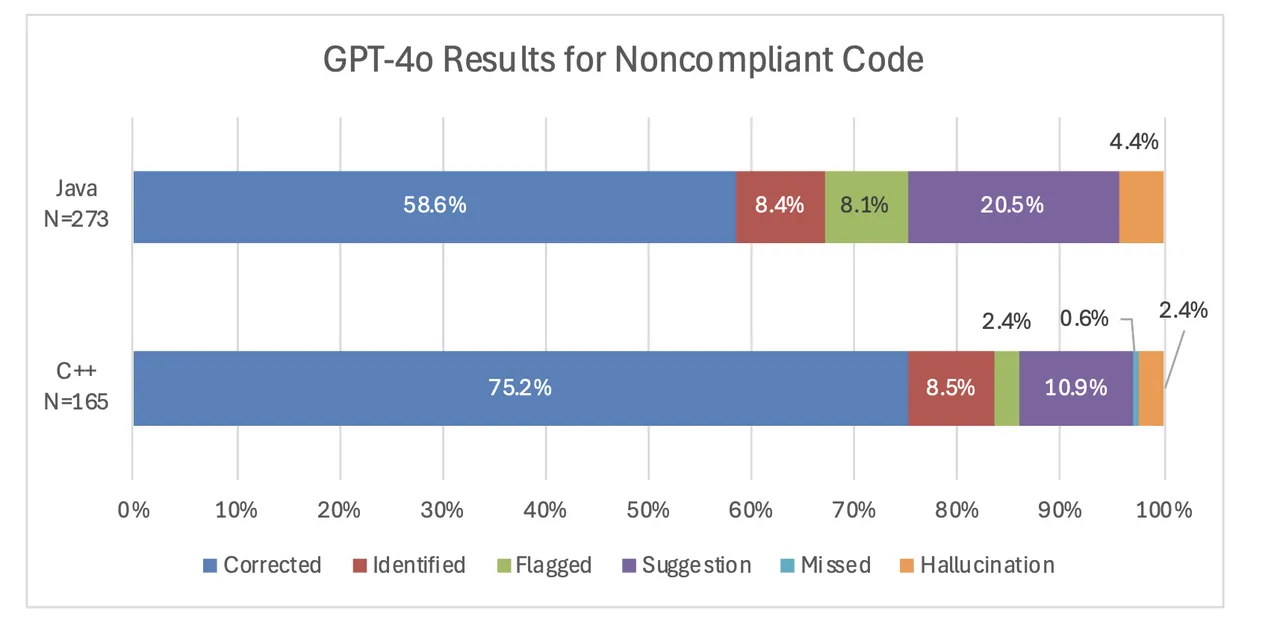
GPT-4o persistently carried out higher on C++ examples in comparison with java examples. It corrected 75.2 p.c of code samples in comparison with 58.6 p.c of Java code samples. This sample was additionally constant in GPT-3.5’s responses. Though there are variations between the rule classes mentioned within the C++ and Java requirements, GPT-4o carried out higher on the C++ code in comparison with the Java code in virtually the entire widespread classes: expressions, characters and strings, object orientation/object-oriented programming, distinctive conduct/exceptions, and error dealing with, enter/output. The one exception was the Declarations and Initializations Class, the place GPT-4o recognized 80 p.c of the errors within the Java code (4 out of 5), however solely 78 p.c of the C++ examples (25 out of 32). Nevertheless, this distinction might be attributed to the low pattern dimension, and the fashions nonetheless general carry out higher on the C++ examples. Be aware that it’s obscure precisely why the OpenAI LLMs carry out higher on C++ in comparison with java, as our job falls underneath the area of reasoning, which is an emergent LLM skill. ( See the article “Emergent Skills of Massive Language Fashions,” by Jason Wei et al. (2022) for a dialogue of emergent LLM skills.)
The Influence of Immediate Engineering
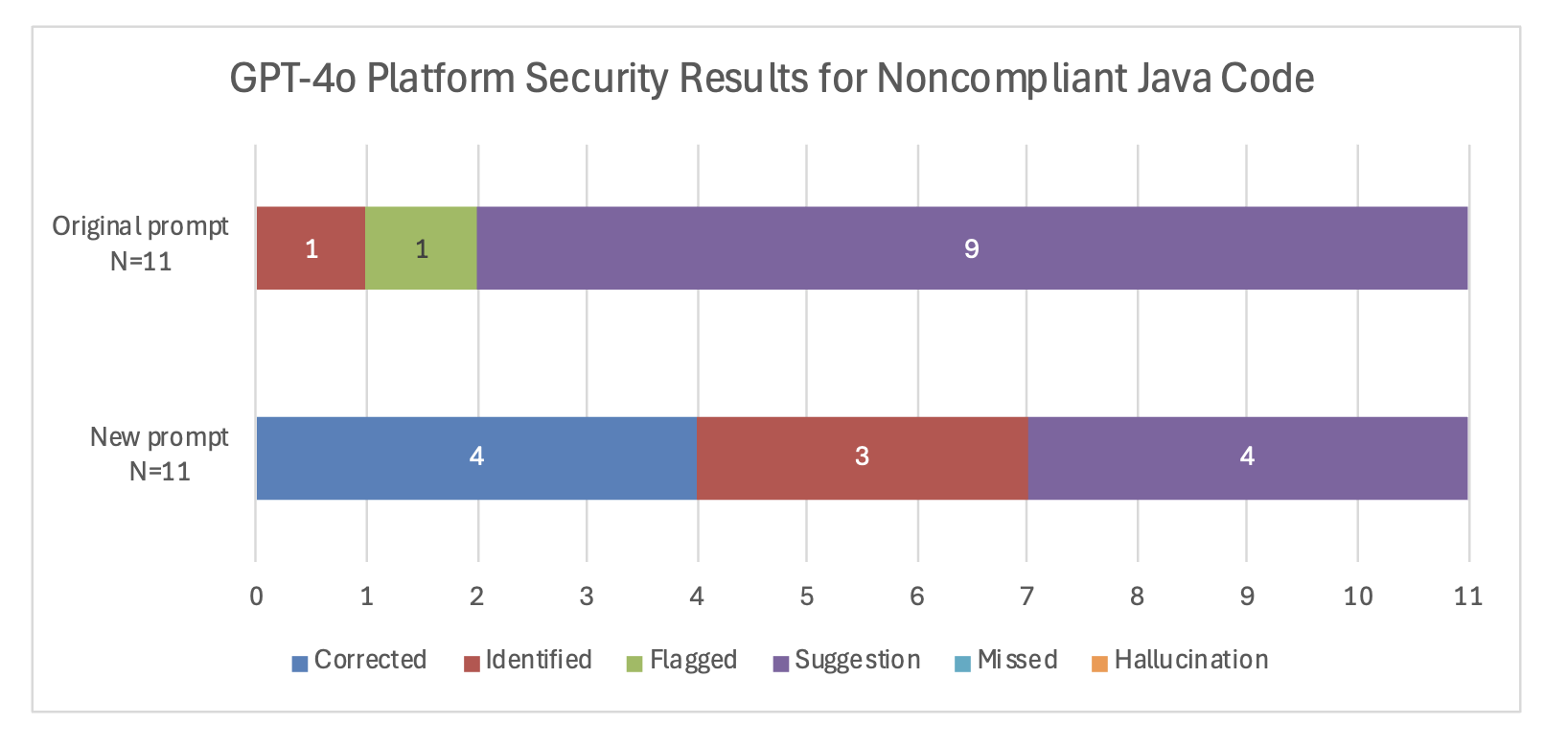
So far, we now have discovered that LLMs have some functionality to guage C++ and Java code when supplied with minimal up-front instruction. However, one might simply think about methods to enhance efficiency by offering extra particulars concerning the required job. To check this most effectively, we selected code samples that the LLMs struggled to determine accurately relatively than re-evaluating the a whole bunch of examples we beforehand summarized. In our preliminary experiments, we observed the LLMs struggled on part 15 – Platform Safety, so we gathered the compliant and noncompliant examples from Java in that part to run by means of GPT-4o, the higher performing mannequin of the 2, as a case examine. We modified the immediate to ask particularly for platform safety points and requested that it ignore minor points like import statements. The brand new immediate grew to become
Are there any platform safety points on this code snippet, if that’s the case please right them? Please ignore any points associated to exception dealing with, import statements, and lacking variable or perform definitions. If there aren’t any points, please state the code is right.
Up to date Immediate Improves Efficiency for Noncompliant Code
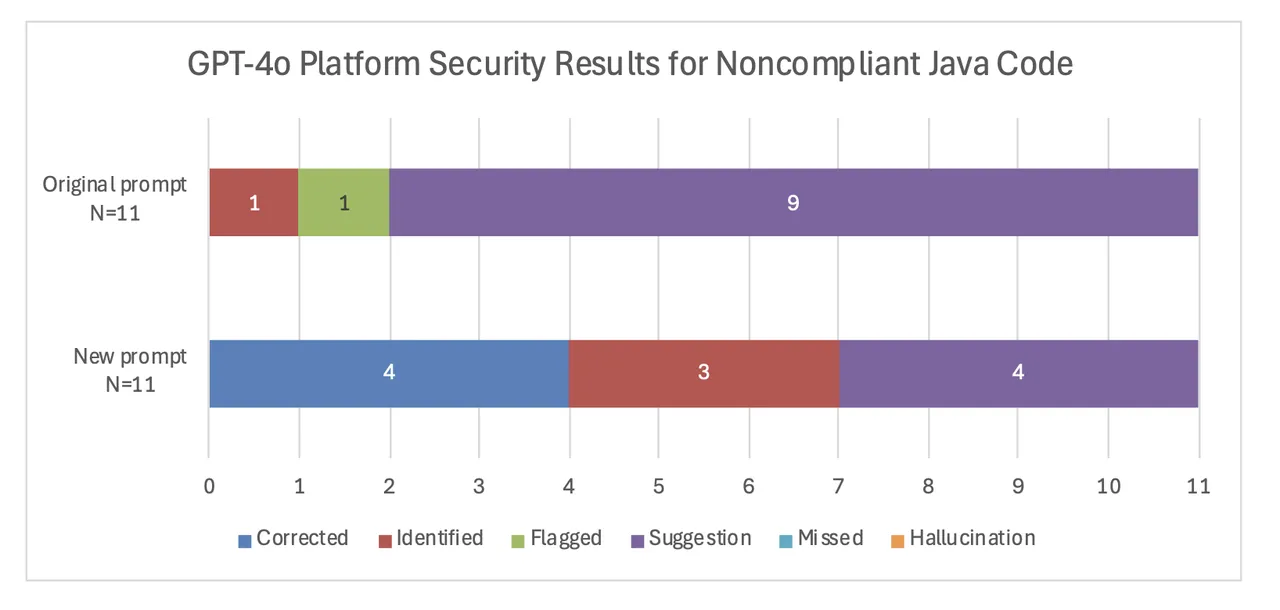
The up to date immediate resulted in a transparent enchancment in GPT-4o’s responses. Underneath the unique immediate, GPT-4o was not in a position to right any platform safety errort, however with the extra particular immediate it corrected 4 of 11. With the extra particular immediate, GPT-4o additionally recognized an extra 3 errors versus just one of underneath the unique immediate. If we think about the corrected and recognized classes to be probably the most helpful, then the improved immediate lowered the variety of non-useful responses from 10 of 11 right down to 4 of 11.
The next responses present an instance of how the revised immediate led to an enchancment in mannequin efficiency.
Within the Java code under, the zeroField() technique makes use of reflection to entry non-public members of the FieldExample class. This may increasingly leak details about area names by means of exceptions or could improve accessibility of delicate knowledge that’s seen to zeroField().
SEC05-J, Ex.1: Don’t use reflection to extend accessibility of courses, strategies, or fields

To deliver this code into compliance, the zeroField() technique could also be declared non-public, or entry could be supplied to the identical fields with out utilizing reflection.


Within the unique answer, GPT-4o makes trivial recommendations, resembling including an import assertion and implementing exception dealing with the place the code was marked with the remark “//Report back to handler.” For the reason that zeroField() technique continues to be accessible to hostile code, the answer is noncompliant. The brand new answer eliminates using reflection altogether and as an alternative gives strategies that may zero i and j with out reflection.
Efficiency with New Immediate is Blended on Compliant Code
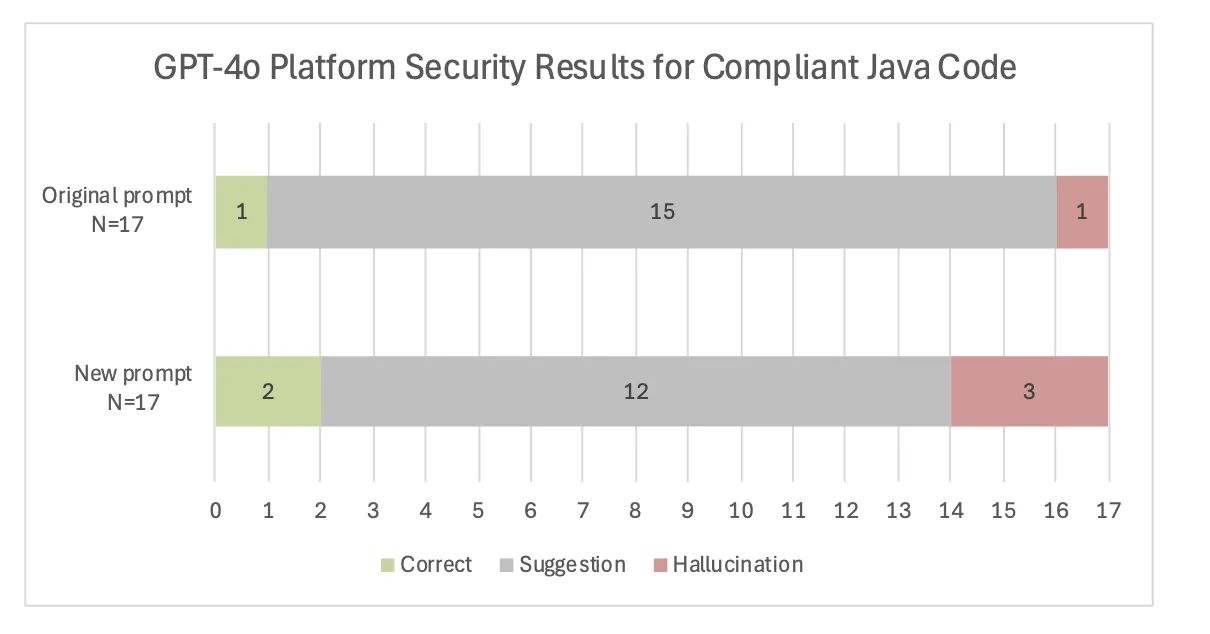
With an up to date immediate, we noticed a slight enchancment on one extra instance in GPT-4o’s skill to determine right code as such, but it surely additionally hallucinated on two others that solely resulted in recommendations underneath the unique immediate. In different phrases, on a couple of examples, prompting the LLM to search for platform safety points brought about it to reply affirmatively, whereas underneath the unique less-specific immediate it might have supplied extra common recommendations with out stating that there was an error. The recommendations with the brand new immediate additionally ignored trivial errors resembling exception dealing with, import statements, and lacking definitions. They grew to become just a little extra centered on platform safety as seen within the instance under.
SEC01-J, Ex.2: Don’t permit tainted variables in privileged blocks

GPT-4o Response to new immediate

Implications for Utilizing LLMs to Repair C++ and Java Errors
As we went by means of the responses, we realized that some responses didn’t simply miss the error however supplied false info, whereas others weren’t flawed however made trivial suggestions. We added hallucination and recommendations to our classes to signify these significant gradations in responses. The outcomes present the GPT-4o hallucinates lower than GPT-3.5; nonetheless, its responses are extra verbose (although we might have doubtlessly addressed this by adjusting the immediate). Consequently, GPT-4o makes extra recommendations than GPT-3.5, particularly on compliant code. Normally, each LLMs carried out higher on noncompliant code for each languages, though they did right the next share of the C++ examples. Lastly, immediate engineering enormously improved outcomes on the noncompliant code, however actually solely improved the main target of the recommendations for the compliant examples. If we had been to proceed this work, we might experiment extra with varied prompts, specializing in bettering the compliant outcomes. This might probably embrace including few-shot examples of compliant and noncompliant code to the immediate. We’d additionally discover fantastic tuning the LLMs to see how a lot the outcomes enhance.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}