
Google Analysis has unveiled a groundbreaking methodology for fine-tuning massive language fashions (LLMs) that slashes the quantity of required coaching information by as much as 10,000x, whereas sustaining and even enhancing mannequin high quality. This strategy facilities on lively studying and focusing professional labeling efforts on essentially the most informative examples—the “boundary instances” the place mannequin uncertainty peaks.
The Conventional Bottleneck
High-quality-tuning LLMs for duties demanding deep contextual and cultural understanding—like advert content material security or moderation—has sometimes required large, high-quality labeled datasets. Most information is benign, which means that for coverage violation detection, solely a small fraction of examples matter, driving up the associated fee and complexity of information curation. Customary strategies additionally wrestle to maintain up when insurance policies or problematic patterns shift, necessitating costly retraining.
Google’s Lively Studying Breakthrough
How It Works:
- LLM-as-Scout: The LLM is used to scan an unlimited corpus (a whole bunch of billions of examples) and establish instances it’s least sure about.
- Focused Skilled Labeling: As a substitute of labeling 1000’s of random examples, human specialists solely annotate these borderline, complicated objects.
- Iterative Curation: This course of repeats, with every batch of latest “problematic” examples knowledgeable by the most recent mannequin’s confusion factors.
- Speedy Convergence: Fashions are fine-tuned in a number of rounds, and the iteration continues till the mannequin’s output aligns intently with professional judgment—measured by Cohen’s Kappa, which compares settlement between annotators past probability.
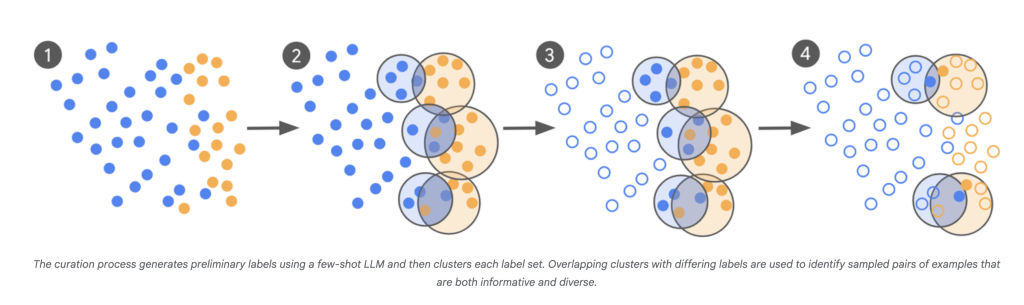
Impression:
- Information Wants Plummet: In experiments with Gemini Nano-1 and Nano-2 fashions, alignment with human specialists reached parity or higher utilizing 250–450 well-chosen examples moderately than ~100,000 random crowdsourced labels—a discount of three to 4 orders of magnitude.
- Mannequin High quality Rises: For extra advanced duties and bigger fashions, efficiency enhancements reached 55–65% over baseline, demonstrating extra dependable alignment with coverage specialists.
- Label Effectivity: For dependable features utilizing tiny datasets, excessive label high quality was persistently crucial (Cohen’s Kappa > 0.8).
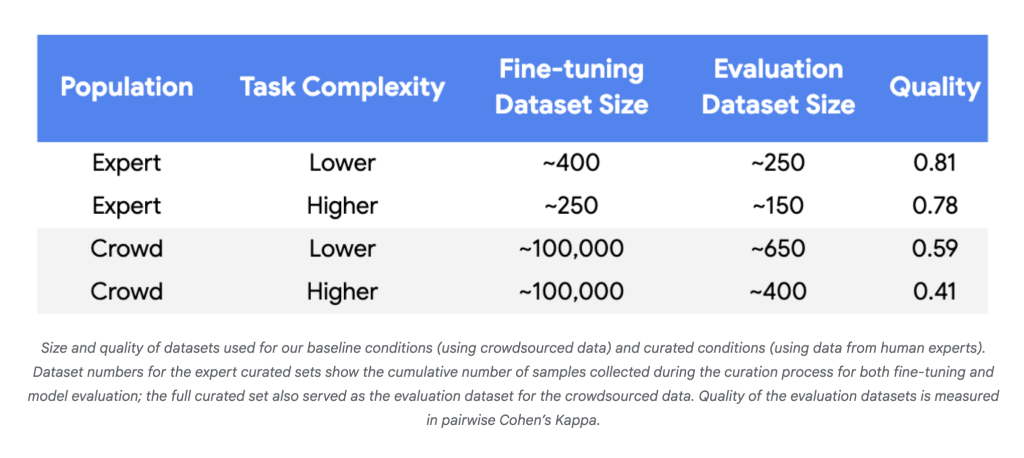
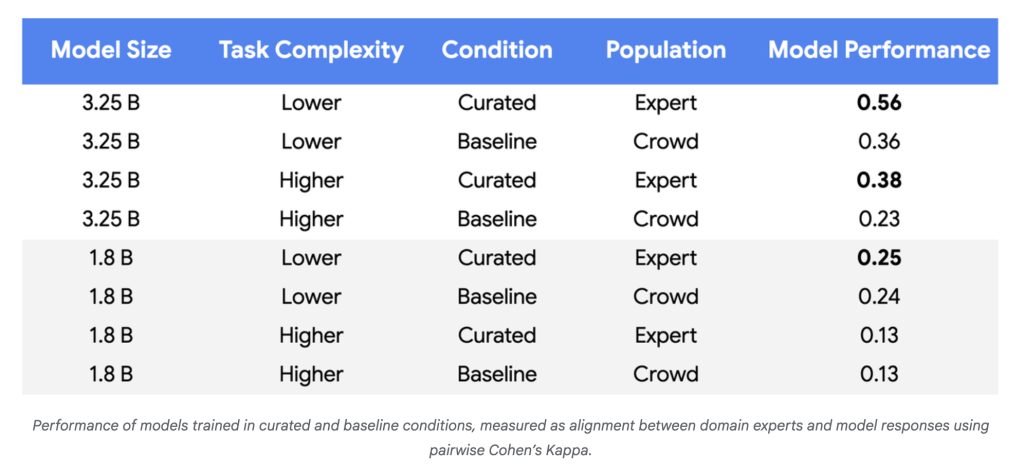
Why It Issues
This strategy flips the normal paradigm. Quite than drowning fashions in huge swimming pools of noisy, redundant information, it leverages each LLMs’ skill to establish ambiguous instances and the area experience of human annotators the place their enter is most useful. The advantages are profound:
- Price Discount: Vastly fewer examples to label, dramatically reducing labor and capital expenditure.
- Sooner Updates: The power to retrain fashions on a handful of examples makes adaptation to new abuse patterns, coverage adjustments, or area shifts fast and possible.
- Societal Impression: Enhanced capability for contextual and cultural understanding will increase the security and reliability of automated programs dealing with delicate content material.
In Abstract
Google’s new methodology permits LLM fine-tuning on advanced, evolving duties with simply a whole bunch (not a whole bunch of 1000’s) of focused, high-fidelity labels—ushering in far leaner, extra agile, and cost-effective mannequin improvement.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling advanced datasets into actionable insights.

{kind=link}