
Since generative AI started to garner public curiosity, the pc imaginative and prescient analysis area has deepened its curiosity in creating AI fashions able to understanding and replicating bodily legal guidelines; nonetheless, the problem of instructing machine studying methods to simulate phenomena similar to gravity and liquid dynamics has been a major focus of analysis efforts for not less than the previous 5 years.
Since latent diffusion fashions (LDMs) got here to dominate the generative AI scene in 2022, researchers have more and more targeted on LDM structure’s restricted capability to grasp and reproduce bodily phenomena. Now, this problem has gained further prominence with the landmark improvement of OpenAI’s generative video mannequin Sora, and the (arguably) extra consequential current launch of the open supply video fashions Hunyuan Video and Wan 2.1.
Reflecting Badly
Most analysis geared toward enhancing LDM understanding of physics has targeted on areas similar to gait simulation, particle physics, and different features of Newtonian movement. These areas have attracted consideration as a result of inaccuracies in primary bodily behaviors would instantly undermine the authenticity of AI-generated video.
Nonetheless, a small however rising strand of analysis concentrates on one in all LDM’s largest weaknesses – it is relative incapability to provide correct reflections.

From the January 2025 paper ‘Reflecting Actuality: Enabling Diffusion Fashions to Produce Devoted Mirror Reflections’, examples of ‘reflection failure’ versus the researchers’ personal strategy. Supply: https://arxiv.org/pdf/2409.14677
This problem was additionally a problem throughout the CGI period and stays so within the area of video gaming, the place ray-tracing algorithms simulate the trail of sunshine because it interacts with surfaces. Ray-tracing calculates how digital mild rays bounce off or move by means of objects to create reasonable reflections, refractions, and shadows.
Nonetheless, as a result of every further bounce vastly will increase computational price, real-time purposes should commerce off latency in opposition to accuracy by limiting the variety of allowed light-ray bounces.
![A representation of a virtually-calculated light-beam in a traditional 3D-based (i.e., CGI) scenario, using technologies and principles first developed in the 1960s, and which came to fulmination between 1982-93 (the span between Tron [1982] and Jurassic Park [1993]. Source: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://www.unite.ai/wp-content/uploads/2025/04/ray-tracing.jpg)
A illustration of a virtually-calculated light-beam in a conventional 3D-based (i.e., CGI) situation, utilizing applied sciences and rules first developed within the Nineteen Sixties, and which got here to fulmination between 1982-93 (the span between ‘Tron’ [1982] and ‘Jurassic Park’ [1993]. Supply: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
As an illustration, depicting a chrome teapot in entrance of a mirror may contain a ray-tracing course of the place mild rays bounce repeatedly between reflective surfaces, creating an nearly infinite loop with little sensible profit to the ultimate picture. Most often, a mirrored image depth of two to a few bounces already exceeds what the viewer can understand. A single bounce would end in a black mirror, because the mild should full not less than two journeys to type a visual reflection.
Every further bounce sharply will increase computational price, typically doubling render occasions, making quicker dealing with of reflections some of the vital alternatives for enhancing ray-traced rendering high quality.
Naturally, reflections happen, and are important to photorealism, in far much less apparent situations – such because the reflective floor of a metropolis avenue or a battlefield after the rain; the reflection of the opposing avenue in a store window or glass doorway; or within the glasses of depicted characters, the place objects and environments could also be required to seem.

A simulated twin-reflection achieved by way of conventional compositing for an iconic scene in ‘The Matrix’ (1999).
Picture Issues
Because of this, frameworks that have been in style previous to the arrival of diffusion fashions, similar to Neural Radiance Fields (NeRF), and a few more moderen challengers similar to Gaussian Splatting have maintained their very own struggles to enact reflections in a pure means.
The REF2-NeRF mission (pictured beneath) proposed a NeRF-based modeling technique for scenes containing a glass case. On this technique, refraction and reflection have been modeled utilizing parts that have been dependent and unbiased of the viewer’s perspective. This strategy allowed the researchers to estimate the surfaces the place refraction occurred, particularly glass surfaces, and enabled the separation and modeling of each direct and mirrored mild parts.

Examples from the Ref2Nerf paper. Supply: https://arxiv.org/pdf/2311.17116
Different NeRF-facing reflection options of the final 4-5 years have included NeRFReN, Reflecting Actuality, and Meta’s 2024 Planar Reflection-Conscious Neural Radiance Fields mission.
For GSplat, papers similar to Mirror-3DGS, Reflective Gaussian Splatting, and RefGaussian have provided options relating to the reflection drawback, whereas the 2023 Nero mission proposed a bespoke technique of incorporating reflective qualities into neural representations.
MirrorVerse
Getting a diffusion mannequin to respect reflection logic is arguably tougher than with explicitly structural, non-semantic approaches similar to Gaussian Splatting and NeRF. In diffusion fashions, a rule of this type is just prone to grow to be reliably embedded if the coaching knowledge incorporates many diverse examples throughout a variety of situations, making it closely depending on the distribution and high quality of the unique dataset.
Historically, including specific behaviors of this type is the purview of a LoRA or the fine-tuning of the bottom mannequin; however these aren’t splendid options, since a LoRA tends to skew output in the direction of its personal coaching knowledge, even with out prompting, whereas fine-tunes – apart from being costly – can fork a significant mannequin irrevocably away from the mainstream, and engender a bunch of associated customized instruments that may by no means work with any different pressure of the mannequin, together with the unique one.
Generally, enhancing diffusion fashions requires that the coaching knowledge pay better consideration to the physics of reflection. Nonetheless, many different areas are additionally in want of comparable particular consideration. Within the context of hyperscale datasets, the place customized curation is expensive and tough, addressing each single weak point on this means is impractical.
Nonetheless, options to the LDM reflection drawback do crop up from time to time. One current such effort, from India, is the MirrorVerse mission, which presents an improved dataset and coaching technique able to enhancing of the state-of-the-art on this specific problem in diffusion analysis.

Rightmost, the outcomes from MirrorVerse pitted in opposition to two prior approaches (central two columns). Supply: https://arxiv.org/pdf/2504.15397
As we are able to see within the instance above (the characteristic picture within the PDF of the brand new research), MirrorVerse improves on current choices tackling the identical drawback, however is much from excellent.
Within the higher proper picture, we see that the ceramic jars are considerably to the best of the place they need to be, and within the picture beneath, which ought to technically not characteristic a mirrored image of the cup in any respect, an inaccurate reflection has been shoehorned into the best–hand space, in opposition to the logic of pure reflective angles.
Due to this fact we’ll check out the brand new technique not a lot as a result of it might characterize the present state-of-the-art in diffusion-based reflection, however equally as an example the extent to which this will likely show to be an intractable problem for latent diffusion fashions, static and video alike, because the requisite knowledge examples of reflectivity are most certainly to be entangled with specific actions and situations.
Due to this fact this specific operate of LDMs could proceed to fall in need of structure-specific approaches similar to NeRF, GSplat, and likewise conventional CGI.
The new paper is titled MirrorVerse: Pushing Diffusion Fashions to Realistically Mirror the World, and comes from three researchers throughout Imaginative and prescient and AI Lab, IISc Bangalore, and the Samsung R&D Institute at Bangalore. The paper has an related mission web page, in addition to a dataset at Hugging Face, with supply code launched at GitHub.
Methodology
The researchers word from the outset the issue that fashions similar to Steady Diffusion and Flux have in respecting reflection-based prompts, illustrating the difficulty adroitly:

From the paper: Present state-of-the-art text-to-image fashions, SD3.5 and Flux, exhibiting vital challenges in producing constant and geometrically correct reflections when prompted to generate them in a scene.
The researchers have developed MirrorFusion 2.0, a diffusion-based generative mannequin geared toward enhancing the photorealism and geometric accuracy of mirror reflections in artificial imagery. Coaching for the mannequin was based mostly on the researchers’ personal newly-curated dataset, titled MirrorGen2, designed to deal with the generalization weaknesses noticed in earlier approaches.
MirrorGen2 expands on earlier methodologies by introducing random object positioning, randomized rotations, and specific object grounding, with the purpose of guaranteeing that reflections stay believable throughout a wider vary of object poses and placements relative to the mirror floor.
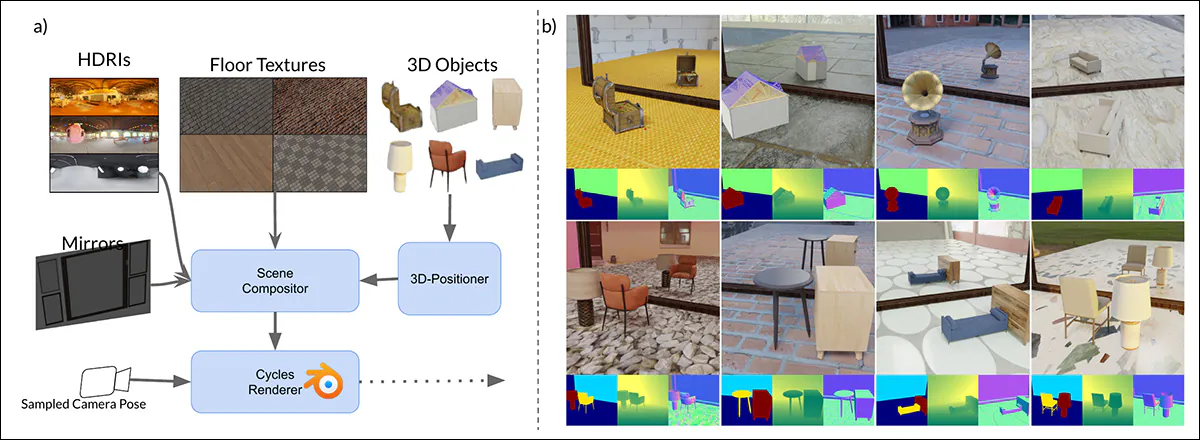
Schema for the technology of artificial knowledge in MirrorVerse: the dataset technology pipeline utilized key augmentations by randomly positioning, rotating, and grounding objects throughout the scene utilizing the 3D-Positioner. Objects are additionally paired in semantically constant mixtures to simulate complicated spatial relationships and occlusions, permitting the dataset to seize extra reasonable interactions in multi-object scenes.
To additional strengthen the mannequin’s potential to deal with complicated spatial preparations, the MirrorGen2 pipeline incorporates paired object scenes, enabling the system to higher characterize occlusions and interactions between a number of parts in reflective settings.
The paper states:
‘Classes are manually paired to make sure semantic coherence – for example, pairing a chair with a desk. Throughout rendering, after positioning and rotating the first [object], an extra [object] from the paired class is sampled and organized to forestall overlap, guaranteeing distinct spatial areas throughout the scene.’
In regard to specific object grounding, right here the authors ensured that the generated objects have been ‘anchored’ to the bottom within the output artificial knowledge, reasonably than ‘hovering’ inappropriately, which may happen when artificial knowledge is generated at scale, or with extremely automated strategies.
Since dataset innovation is central to the novelty of the paper, we are going to proceed sooner than standard to this part of the protection.
Knowledge and Exams
SynMirrorV2
The researchers’ SynMirrorV2 dataset was conceived to enhance the variety and realism of mirror reflection coaching knowledge, that includes 3D objects sourced from the Objaverse and Amazon Berkeley Objects (ABO) datasets, with these alternatives subsequently refined by means of OBJECT 3DIT, in addition to the filtering course of from the V1 MirrorFusion mission, to get rid of low-quality asset. This resulted in a refined pool of 66,062 objects.

Examples from the Objaverse dataset, used within the creation of the curated dataset for the brand new system. Supply: https://arxiv.org/pdf/2212.08051
Scene building concerned inserting these objects onto textured flooring from CC-Textures and HDRI backgrounds from the PolyHaven CGI repository, utilizing both full-wall or tall rectangular mirrors. Lighting was standardized with an area-light positioned above and behind the objects, at a forty-five diploma angle. Objects have been scaled to suit inside a unit dice and positioned utilizing a precomputed intersection of the mirror and digicam viewing frustums, guaranteeing visibility.
Randomized rotations have been utilized across the y-axis, and a grounding method used to forestall ‘floating artifacts’.
To simulate extra complicated scenes, the dataset additionally included a number of objects organized in keeping with semantically coherent pairings based mostly on ABO classes. Secondary objects have been positioned to keep away from overlap, creating 3,140 multi-object scenes designed to seize diverse occlusions and depth relationships.

Examples of rendered views from the authors’ dataset containing a number of (greater than two) objects, with illustrations of object segmentation and depth map visualizations seen beneath.
Coaching Course of
Acknowledging that artificial realism alone was inadequate for sturdy generalization to real-world knowledge, the researchers developed a three-stage curriculum studying course of for coaching MirrorFusion 2.0.
In Stage 1, the authors initialized the weights of each the conditioning and technology branches with the Steady Diffusion v1.5 checkpoint, and fine-tuned the mannequin on the single-object coaching break up of the SynMirrorV2 dataset. Not like the above-mentioned Reflecting Actuality mission, the researchers didn’t freeze the technology department. They then educated the mannequin for 40,000 iterations.
In Stage 2, the mannequin was fine-tuned for an extra 10,000 iterations, on the multiple-object coaching break up of SynMirrorV2, so as to train the system to deal with occlusions, and the extra complicated spatial preparations present in reasonable scenes.
Lastly, In Stage 3, an extra 10,000 iterations of finetuning have been carried out utilizing real-world knowledge from the MSD dataset, utilizing depth maps generated by the Matterport3D monocular depth estimator.

Examples from the MSD dataset, with real-world scenes analyzed into depth and segmentation maps. Supply: https://arxiv.org/pdf/1908.09101
Throughout coaching, textual content prompts have been omitted for 20 p.c of the coaching time so as to encourage the mannequin to make optimum use of the out there depth data (i.e., a ‘masked’ strategy).
Coaching came about on 4 NVIDIA A100 GPUs for all phases (the VRAM spec just isn’t provided, although it might have been 40GB or 80GB per card). A studying price of 1e-5 was used on a batch dimension of 4 per GPU, below the AdamW optimizer.
This coaching scheme progressively elevated the issue of duties offered to the mannequin, starting with less complicated artificial scenes and advancing towards tougher compositions, with the intention of creating sturdy real-world transferability.
Testing
The authors evaluated MirrorFusion 2.0 in opposition to the earlier state-of-the-art, MirrorFusion, which served because the baseline, and carried out experiments on the MirrorBenchV2 dataset, masking each single and multi-object scenes.
Further qualitative checks have been carried out on samples from the MSD dataset, and the Google Scanned Objects (GSO) dataset.
The analysis used 2,991 single-object photos from seen and unseen classes, and 300 two-object scenes from ABO. Efficiency was measured utilizing Peak Sign-to-Noise Ratio (PSNR); Structural Similarity Index (SSIM); and Realized Perceptual Picture Patch Similarity (LPIPS) scores, to evaluate reflection high quality on the masked mirror area. CLIP similarity was used to judge textual alignment with the enter prompts.
In quantitative checks, the authors generated photos utilizing 4 seeds for a selected immediate, and deciding on the ensuing picture with one of the best SSIM rating. The 2 reported tables of outcomes for the quantitative checks are proven beneath.

Left, Quantitative outcomes for single object reflection technology high quality on the MirrorBenchV2 single object break up. MirrorFusion 2.0 outperformed the baseline, with one of the best outcomes proven in daring. Proper, quantitative outcomes for a number of object reflection technology high quality on the MirrorBenchV2 a number of object break up. MirrorFusion 2.0 educated with a number of objects outperformed the model educated with out them, with one of the best outcomes proven in daring.
The authors remark:
‘[The results] present that our technique outperforms the baseline technique and finetuning on a number of objects improves the outcomes on complicated scenes.’
The majority of outcomes, and people emphasised by the authors, regard qualitative testing. Because of the dimensions of those illustrations, we are able to solely partially reproduce the paper’s examples.

Comparability on MirrorBenchV2: the baseline failed to take care of correct reflections and spatial consistency, displaying incorrect chair orientation and distorted reflections of a number of objects, whereas (the authors contend) MirrorFusion 2.0 accurately renders the chair and the sofas, with correct place, orientation, and construction.
Of those subjective outcomes, the researchers opine that the baseline mannequin did not precisely render object orientation and spatial relationships in reflections, typically producing artifacts similar to incorrect rotation and floating objects. MirrorFusion 2.0, educated on SynMirrorV2, the authors contend, preserves appropriate object orientation and positioning in each single-object and multi-object scenes, leading to extra reasonable and coherent reflections.
Beneath we see qualitative outcomes on the aforementioned GSO dataset:

Comparability on the GSO dataset. The baseline misrepresents object construction and produced incomplete, distorted reflections, whereas MirrorFusion 2.0, the authors contend, preserves spatial integrity and generates correct geometry, shade, and element, even on out-of-distribution objects.
Right here the authors remark:
‘MirrorFusion 2.0 generates considerably extra correct and reasonable reflections. As an illustration, in Fig. 5 (a – above), MirrorFusion 2.0 accurately displays the drawer handles (highlighted in inexperienced), whereas the baseline mannequin produces an implausible reflection (highlighted in crimson).
‘Likewise, for the “White-Yellow mug” in Fig. 5 (b), MirrorFusion 2.0 delivers a convincing geometry with minimal artifacts, not like the baseline, which fails to precisely seize the article’s geometry and look.’
The ultimate qualitative take a look at was in opposition to the aforementioned real-world MSD dataset (partial outcomes proven beneath):

Actual-world scene outcomes evaluating MirrorFusion, MirrorFusion 2.0, and MirrorFusion 2.0, fine-tuned on the MSD dataset. MirrorFusion 2.0, the authors contend, captures complicated scene particulars extra precisely, together with cluttered objects on a desk, and the presence of a number of mirrors inside a three-dimensional setting. Solely partial outcomes are proven right here, because of the dimensions of the leads to the unique paper, to which we refer the reader for full outcomes and higher decision.
Right here the authors observe that whereas MirrorFusion 2.0 carried out effectively on MirrorBenchV2 and GSO knowledge, it initially struggled with complicated real-world scenes within the MSD dataset. High quality-tuning the mannequin on a subset of MSD improved its potential to deal with cluttered environments and a number of mirrors, leading to extra coherent and detailed reflections on the held-out take a look at break up.
Moreover, a person research was carried out, the place 84% of customers are reported to have most well-liked generations from MirrorFusion 2.0 over the baseline technique.
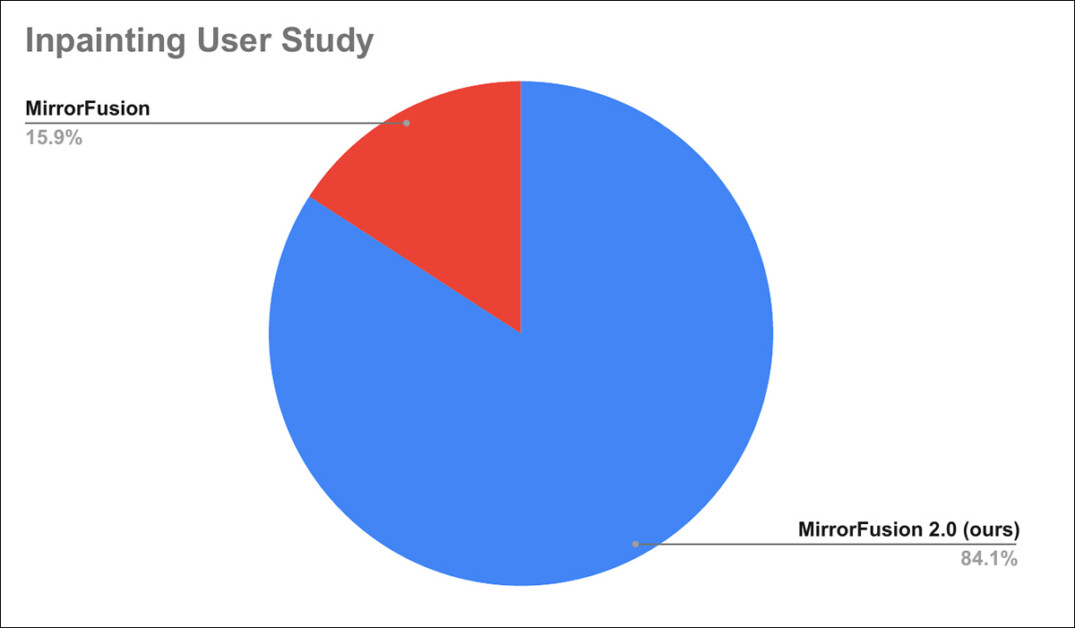
Outcomes of the person research.
Since particulars of the person research have been relegated to the appendix of the paper, we refer the reader to that for the specifics of the research.
Conclusion
Though a number of of the outcomes proven within the paper are spectacular enhancements on the state-of-the-art, the state-of-the-art for this specific pursuit is so abysmal that even an unconvincing mixture resolution can win out with a modicum of effort. The elemental structure of a diffusion mannequin is so inimical to the dependable studying and demonstration of constant physics, that the issue itself is actually posed, and never apparently not disposed towards a chic resolution.
Additional, including knowledge to current fashions is already the usual technique of remedying shortfalls in LDM efficiency, with all of the disadvantages listed earlier. It’s cheap to imagine that if future high-scale datasets have been to pay extra consideration to the distribution (and annotation) of reflection-related knowledge factors, we may count on that the ensuing fashions would deal with this situation higher.
But the identical is true of a number of different bugbears in LDM output – who can say which ones most deserves the hassle and cash concerned within the sort of resolution that the authors of the brand new paper suggest right here?
First revealed Monday, April 28, 2025

{kind=link}