
As Databricks Engineers, we’ve got the privilege of engaged on difficult issues with nice colleagues. On this Engineering weblog submit, we’ll stroll you thru how we constructed a excessive efficiency charge limiting system at Databricks. In case you are a Databricks person, you don’t want to know this weblog to have the ability to use the platform to its fullest. However in case you’re involved in taking a peek below the hood, learn on to listen to about a few of the cool stuff we’ve been engaged on!
Background
Fee limiting is about controlling useful resource utilization to offer isolation and overload safety between tenants in a multitenant system. Within the context of Databricks, this could possibly be offering isolation between accounts, workspaces, customers, and so on., and is most frequently seen externally as a per time unit restrict, such because the variety of jobs launched per second, variety of API requests per second, and so on. However there is also inner usages of charge limits, comparable to managing capability between purchasers of a service. Fee restrict enforcement performs an vital function in making Databricks dependable, but it surely’s vital to notice that this enforcement incurs overhead that must be minimized.
The Drawback
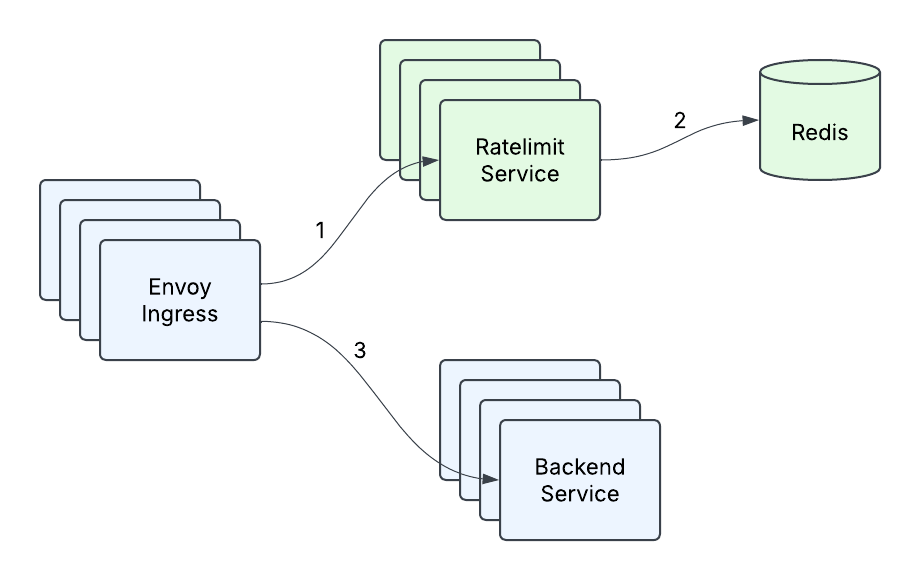
Again in early 2023, the present Ratelimit infrastructure at Databricks consisted of an Envoy ingress gateway making calls to the Ratelimit Service, with a single occasion of Redis backing the service (Determine 1). This was completely appropriate for the present queries per second (QPS) that any cluster of machines inside a area was anticipated to obtain, in addition to for the transient nature of per second counting. However as the corporate expanded its buyer base and added new use circumstances, it turned clear that what had gotten us to that time wouldn’t be enough to fulfill our future wants. With the introduction of real-time mannequin serving and different excessive qps use circumstances, the place one buyer could possibly be sending orders of magnitude extra visitors than what the Ratelimit Service may at the moment deal with, a couple of issues emerged:
- Excessive tail latency – the tail latency of our service was unacceptably excessive below heavy visitors, particularly when contemplating there are two community hops concerned and that there was P99 community latency of 10ms-20ms in one of many cloud suppliers.
- Restricted Throughput – at a sure level, including extra machines and doing level optimizations (comparable to caching) not allowed us to deal with extra visitors.
- Redis as a single level of failure – Our single Redis occasion was our single level of failure, and we needed to do one thing about that. It was time to revamp our service.
Terminology
At Databricks, we’ve got an idea of a RatelimitGroup (RLG), which is a string identifier that represents a useful resource or set of assets that we have to shield, comparable to an API endpoint. These assets can be protected on sure Dimensions, comparable to setting limits on the workspace/person/account stage. For instance, a dimension would convey “I need to shield FooBarAPI on workspaceId and the workspaceId for this request is 12345.” A Dimension can be represented like this:
A single shouldRateLimit request may have a number of descriptors, and an instance could be setting limits, for a selected API, on the workspace and on the person stage.
The place the Descriptor schema will appear to be this:
Resolution
Low Latency Responses
The primary drawback we wished to deal with was to enhance the latency of our Ratelimit Service. Fee Limiting is in the end only a counting drawback, and we knew we ideally wished to maneuver to a mannequin the place we may at all times reply charge restrict requests in-memory, as a result of it’s ultra-fast and most of our charge limits had been primarily based on QPS, which meant that these counts had been transient and didn’t should be resilient to service cases restarting or crashing. Our current setup did a restricted quantity of in-memory counting already by utilizing Envoy’s constant hashing to extend cache hit charges, by sending the identical request to the identical machine. Nonetheless, 1) this was not doable to share with non-Envoy companies, 2) the task churn throughout service resizes and restarts meant we nonetheless needed to repeatedly synchronize with Redis, and three) constant hashing is susceptible to hotspotting, and when load wasn’t distributed evenly we oftentimes may solely improve the variety of cases to try to distribute load higher, resulting in suboptimal service utilization.
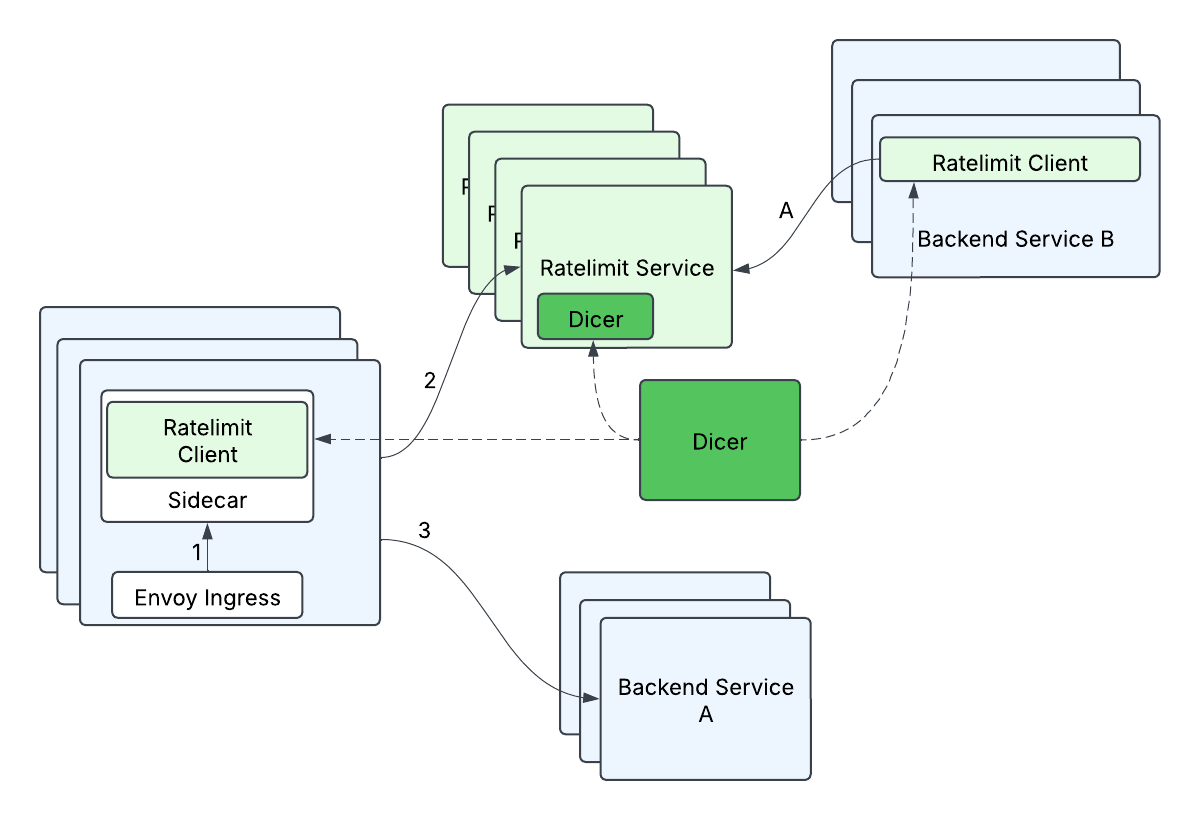
As luck would have it, we had some superior people be part of Databricks, and so they had been designing Dicer, an autosharding know-how that might make stateful companies simpler to handle, whereas nonetheless maintaining all the advantages of a stateless service deployment. This might enable us to tame our server facet latency by maintaining all the charge restrict counting in reminiscence, as a result of the purchasers would be capable of ask Dicer to map a request to a vacation spot server, and the server would be capable of validate with Dicer that it was the correct proprietor of a request. Counting in reminiscence is clearly a lot easier and sooner than wanting up this data from one other supply, and Dicer enabled us to each enhance our server facet tail latency and scale horizontally with out worrying a few storage answer. i.e this eliminated our single level of failure (Redis) and gave us sooner requests on the identical time!
Scaling Effectively
Though we understood how we may clear up a part of our issues, we nonetheless didn’t have a extremely good approach to deal with the anticipated large quantity of requests. We needed to be extra environment friendly and smarter about this, fairly than throwing an enormous variety of servers on the drawback. In the end, we didn’t need one shopper request to translate into one request to the Ratelimit Service, as a result of at scale, thousands and thousands of requests to the Ratelimit Service can be costly.
What had been our choices? We thought by a lot of them however a few of the choices we thought of had been
- Prefetching tokens on the shopper and attempting to reply requests domestically.
- Batching up a set of requests, sending, after which ready for a response to let the visitors by.
- Solely sending a fraction of the requests (i.e. Sampling).
None of those choices had been notably engaging; Prefetching (a) has quite a lot of edge circumstances throughout initialization and when the tokens run out on the shopper or expire. Batching (b) provides pointless delay and reminiscence strain. And Sampling (c) would solely be appropriate for top qps circumstances, however not basically, the place we truly may have low charge limits.
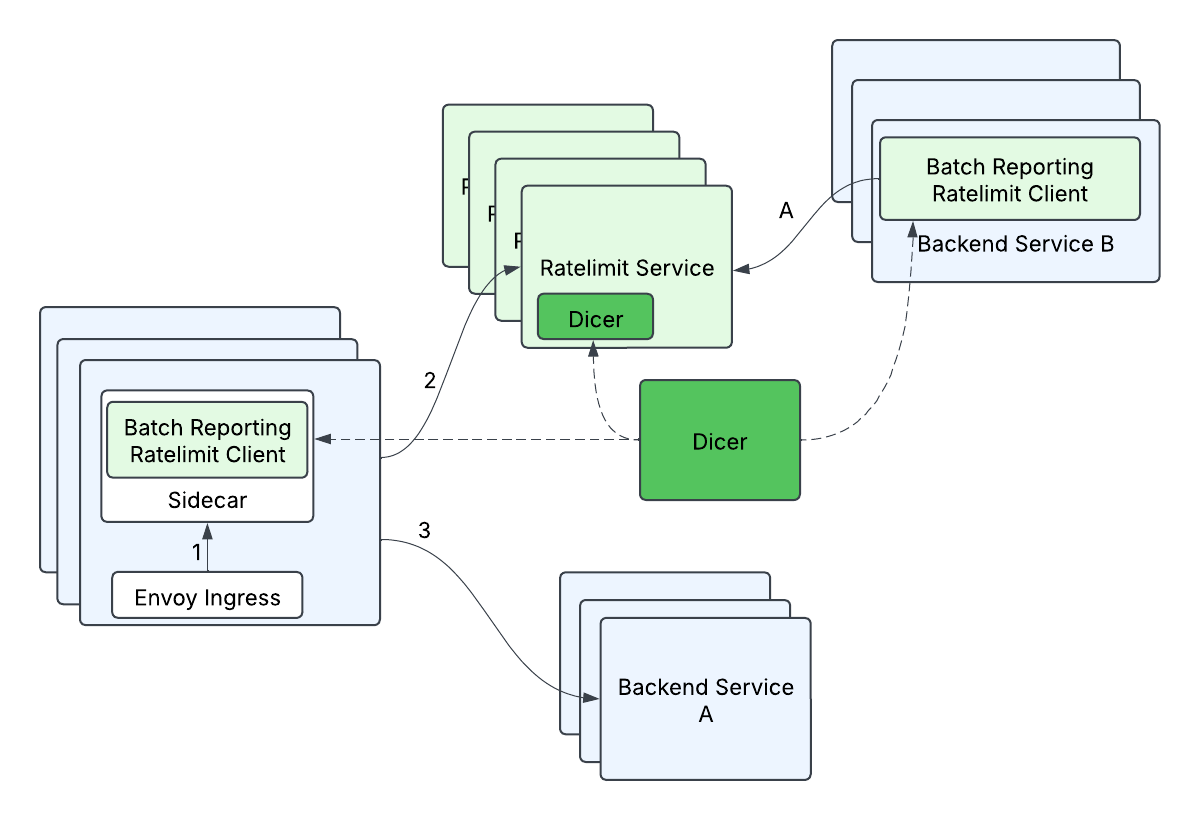
What we ended up designing is a mechanism we name batch-reporting, that mixes two ideas: 1) Our purchasers wouldn’t make any distant calls within the essential charge restrict path, and a pair of) our purchasers would carry out optimistic charge limiting, the place by default requests can be let by until we already knew we wished to reject these specific requests. We had been effective with not having strict ensures on charge limits as a tradeoff for scalability as a result of backend companies may tolerate some proportion of overlimit. At a excessive stage, batch-reporting does native relying on the shopper facet, and periodically (e.g. 100ms) studies again the counts to the server. The server would inform the shopper whether or not any of the entries wanted to be charge restricted.
The batch-reporting stream appeared like this:
- The shopper information what number of requests it let by (outstandingHits) and what number of requests it rejected (rejectedHits)
- Periodically, a course of on the shopper will report the collected counts to the server.
- E.g.
KeyABC_SubKeyXYZ: outstandingHits=624, rejectedHits=857;KeyQWD_SubKeyJHP: outstandingHits=876, rejectedHits=0
- E.g.
- Server returns an array of responses
- KeyABC_SubKeyXYZ: rejectTilTimestamp=…, rejectionRate=…
KeyQWD_SubKeyJHP: rejectTilTimestamp=…, rejectionRate=…
- KeyABC_SubKeyXYZ: rejectTilTimestamp=…, rejectionRate=…
The advantages of this strategy had been large; we may have virtually zero-latency charge restrict calls, a 10x enchancment when in comparison with some tail latency calls, and switch spiky charge restrict visitors into (comparatively) fixed qps visitors! Mixed with the Dicer answer for in-memory charge limiting, it’s all easy crusing from right here, proper?
Satan’s within the Particulars
Though we had a good suggestion of the tip purpose, there was quite a lot of laborious engineering work to truly make it a actuality. Listed here are a few of the challenges we encountered alongside the best way, and the way we solved them.
Excessive Fanout
As a result of we wanted to shard primarily based on the RateLimitGroup and dimension, this meant {that a} beforehand single RateLimitRequest with N dimensions may flip into N requests, i.e. a typical fanout request. This could possibly be particularly problematic when mixed with batch-reporting, since a single batched request may fan-out to many (500+) totally different distant calls. If unaddressed, the client-side tail latency would improve drastically (from ready on just one distant name to ready on 500+ distant calls), and the server-side load would improve (from 1 distant request general to 500+ distant requests general). We optimized this by grouping descriptors by their Dicer assignments – descriptors assigned to the identical reproduction had been grouped right into a single charge restrict batch request and despatched to that corresponding vacation spot server. This helped to attenuate the rise in client-side tail latencies (some improve in tail latency is appropriate since batched requests should not on the essential path however fairly processed in a background thread), and minimizes the elevated load to the server (every server reproduction will deal with at most 1 distant request from a shopper reproduction per batch cycle).
Enforcement Accuracy
As a result of the batch-reporting algorithm is each asynchronous and makes use of a time-based interval to report the up to date counts to the Ratelimit Service, it was very doable that we may enable too many requests by earlier than we may implement the speed restrict. Though we may outline these limits as fuzzy, we nonetheless wished to present ensures that we’d go X% (e.g. 5%) over the restrict. Going excessively over the restrict may occur due to two principal causes:
- The visitors throughout one batching window (e.g. 100ms) may exceed the speed restrict coverage.
- Lots of our use circumstances used the fixed-window algorithm and per-second charge limits. A property of the fixed-window algorithm is that every “window” begins contemporary (i.e. resets and begins from zero), so we may doubtlessly exceed the speed restrict each second, even throughout fixed (however excessive) visitors!
The best way we mounted this was three-fold:
- We added a rejection-rate within the Ratelimit Service response, in order that we may use previous historical past to foretell when and the way a lot visitors to reject on the shopper.
rejectionRate=(estimatedQps-rateLimitPolicy)/estimatedQpsThis makes use of the idea that the upcoming second’s visitors goes to be just like the previous second’s visitors. - We added defense-in-depth by including a client-side native charge limiter to chop off apparent circumstances of extreme visitors instantly.
- As soon as we had autosharding in place, we applied an in-memory token-bucket ratelimiting algorithm, which got here with some nice advantages:
- We may now enable managed bursts of visitors
- Extra importantly, token-bucket “remembers” data throughout time intervals as a result of as a substitute of resetting each time interval just like the fixed-window algorithm, it could actually repeatedly rely, and even go detrimental. Thus, if a buyer sends too many requests, we “bear in mind” how a lot over the restrict they went and may reject requests till the bucket refills to not less than zero. We weren’t in a position to help this token bucket in Redis beforehand as a result of token-bucket wanted pretty complicated operations in Redis, which might improve our Redis latencies. Now, as a result of the token-bucket didn’t endure from amnesia each time interval, we may eliminate the rejection-rate mechanism.
- Token-bucket with out enabling additional burst performance can approximate a sliding-window algorithm, which is a greater model of fixed-window that doesn’t endure from the “reset” drawback.
The advantages of the token-bucket strategy had been so nice that we ended up changing all our ratelimits to token bucket.
Rebuilding a Aircraft In-Flight
We knew the tip state that we wished to get to, however that required making two unbiased main adjustments to a essential service, neither of which had been assured to work properly on their very own. And rolling these two adjustments out collectively was not an possibility, for each technical and danger administration causes. A few of the attention-grabbing stuff we needed to do alongside the best way:
- We constructed a localhost sidecar to our envoy ingress in order that we may apply each batch-reporting and auto-sharding, as a result of envoy is third occasion code we can not change.
- Earlier than we had in-memory charge limiting, we needed to batch writes to Redis by way of a Lua script so as to deliver down the tail latency of batch-reporting requests, as a result of sending descriptors one after the other to Redis was too sluggish with all of the community round-trips, even when we had switched to batch execution.
- We constructed a visitors simulation framework with many alternative visitors patterns and charge restrict insurance policies, so we may consider our accuracy, efficiency, and scalability all through this transition.
Present State and Future Work
With the profitable rollout of each batch-reporting and in-memory token bucket charge limiting, we noticed drastic tail latency enhancements (as much as 10x in some circumstances!) with sub-linear progress in server facet visitors. Our inner service purchasers are notably glad that there’s no distant name once they make charge restrict calls, and that they’ve the liberty to scale independently of the Ratelimit Service.
The workforce has additionally been engaged on different thrilling areas, comparable to service mesh routing and zero-config overload safety, so hold tuned for extra weblog posts! And Databricks is at all times wanting for extra nice engineers who could make a distinction, we’d love so that you can be part of us!

{kind=link}