
Organizations managing large-scale analytical workloads more and more face challenges with conventional Apache Parquet-based knowledge lakes with Hive-style partitioning, together with sluggish queries, complicated file administration, and restricted consistency ensures. Apache Iceberg addresses these ache factors by offering ACID transactions, seamless schema evolution, and point-in-time knowledge restoration capabilities that remodel how enterprises deal with their knowledge infrastructure.
On this submit, we display how one can obtain migration at scale from present Parquet tables to Apache Iceberg tables. Utilizing Amazon DynamoDB as a central orchestration mechanism, we present how one can implement in-place migrations which are extremely configurable, repeatable, and fault-tolerant—unlocking the total potential of contemporary knowledge lake architectures with out intensive knowledge motion or duplication.
Answer overview
When performing in-place migration, Apache Iceberg makes use of its capability to immediately reference present knowledge information. This functionality is barely supported for codecs corresponding to Parquet, ORC, and Avro, as a result of these codecs are self-describing and embody constant schema and metadata info. In contrast to uncooked codecs corresponding to CSV or JSON, they implement construction and help environment friendly columnar or row-based entry, which permits Iceberg to combine them with out rewriting the info.
On this submit, we display how one can migrate an present Parquet-based knowledge lake that isn’t cataloged in AWS Glue by utilizing two methodologies:
- Apache Iceberg migrate and
register_tablemethod. Excellent for changing present Hive-registered Parquet tables into Iceberg-managed tables. - Iceberg
add_filesmethod. Greatest fitted to shortly onboarding uncooked Parquet knowledge into Iceberg with out rewriting information.
The answer additionally incorporates a DynamoDB desk that acts as a scalable management aircraft, so you possibly can carry out in-place migration of your knowledge lake from Parquet format to Iceberg format.
The next diagram reveals totally different methodologies that you should use to realize this in-place migration of your Hive-style partitioned knowledge lake:
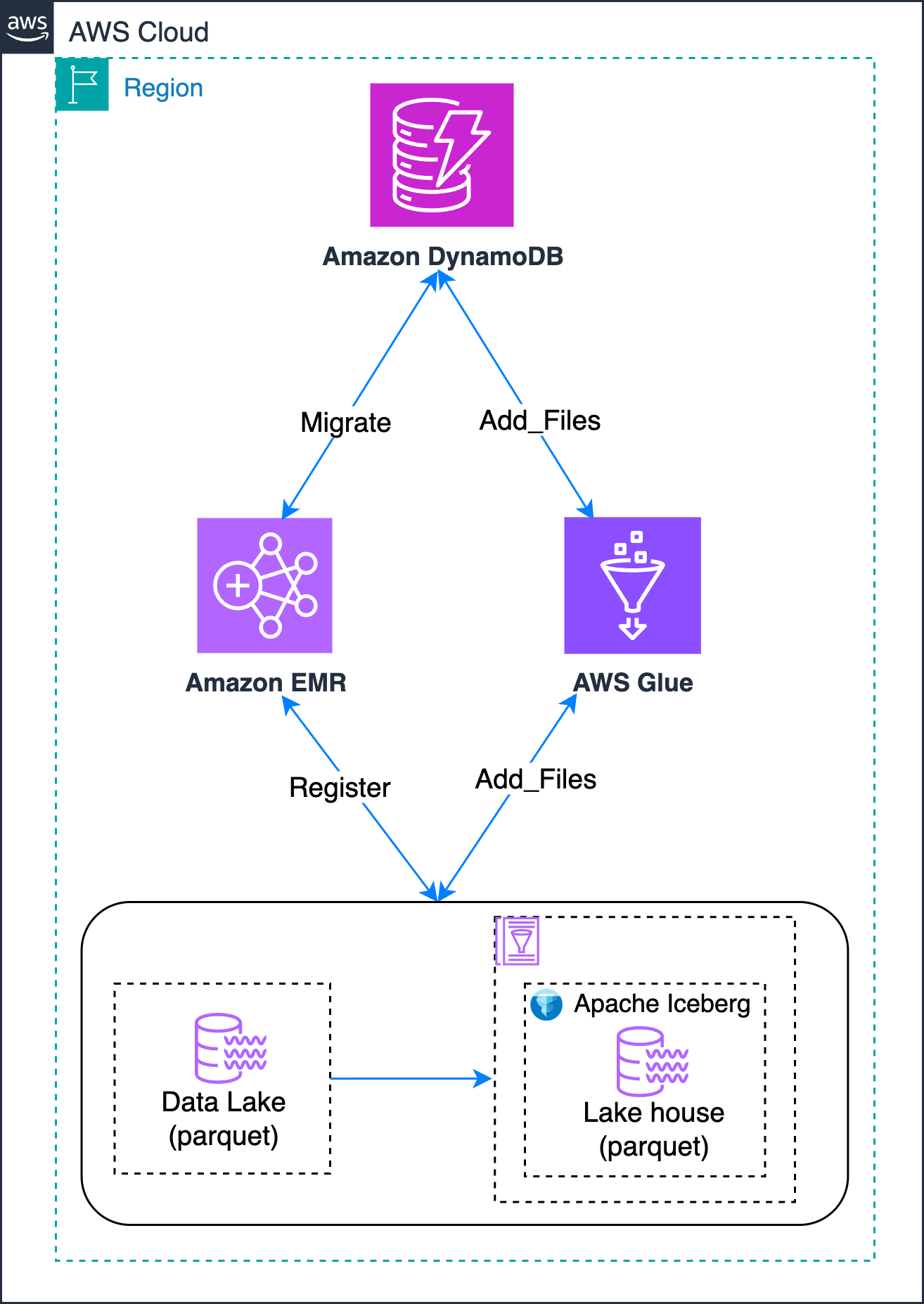
You employ DynamoDB to trace the migration state, dealing with retries and recording errors and outcomes. This gives the next advantages:
- Centralized management over which Amazon Easy Storage Service (Amazon S3) paths want migration.
- Lifecycle monitoring of every dataset by migration phases.
- Seize and audit errors on a per-path foundation.
- Allow re-runs by updating stateful flags or clearing failure messages.
Conditions
Earlier than you start, you want:
Create pattern Parquet dataset as a supply
You possibly can create the pattern Parquet dataset for testing the totally different methodologies utilizing the Athena question editor. Change
- Create an AWS Glue database(
test_db), if not current. - Create a pattern Parquet desk (
table1) and add for use for testing theadd_filesmethod. - Create a pattern Parquet desk (
table2) and add knowledge for use for testing the migrate andregister_tablemethod. Change - Drop the tables from the Knowledge Catalog since you solely want Parquet knowledge with the Hive-style partitioning construction.
Create a DynamoDB management desk
Earlier than starting the migration course of, you could create a DynamoDB desk that serves because the management aircraft. This desk maps supply Amazon S3 paths to their corresponding Iceberg database and desk locations, enabling systematic monitoring of the migration course of.
To implement this management mechanism, create a desk with the next construction:
- A main key
s3_paththat shops the supply Parquet knowledge location - Two attributes that outline the goal Iceberg location:
target_db_nametarget_table_name
To create the DynamoDB management desk
- Create the Amazon DynamoDB desk utilizing the next AWS CLI command:
- Confirm the desk is created efficiently. Change
- Create a
migration_data.jsonfile with the next contents.
On this instance:- Change
- Change
- Change
This file defines the mapping between Amazon S3 paths and their corresponding Iceberg desk locations.
- Change
- Run the next CLI command to load the DynamoDB management desk.
Migration methodologies
On this part, you discover two methodologies for migrating your present Parquet tables to Apache Iceberg format:
- Apache Iceberg migrate and register_table method – This method first converts your Parquet desk to Iceberg format utilizing the native migrate process, adopted by registering it in AWS Glue utilizing the
register_tableprocess. - Apache Iceberg add_files method – This technique creates an empty Iceberg desk and makes use of the
add_filesprocess to import present Parquet knowledge information with out bodily transferring them.
Apache Iceberg migrate and register_table process
Use the Apache Iceberg Migrate process that’s used for in-place conversion of an present Hive or Parquet desk into an Iceberg-managed desk. Thereafter, you should use the Apache Iceberg RegisterTable process to register the respective desk in AWS Glue.

Migrate
- In your EMR cluster with Hive because the metastore, create a PySpark session with the next Iceberg Packages:
This submit makes use of Iceberg v1.9.1 (Amazon EMR construct), which is native to Amazon EMR 7.11. At all times confirm the most recent supported model and replace bundle coordinates accordingly.
- Subsequent, create your corresponding desk in your Hive catalog (you possibly can skip this step if you have already got tables created in your hive catalog). Change
Within the following snippet, change or take away thePARTITIONED BYcommand based mostly on the partition technique of your desk, theMSCK Restore deskcommand ought to solely be run in case your respective desk is partitioned. - Convert the Parquet desk to an Iceberg desk in Hive
Run the migrate command to transform the Parquet-based desk to an Iceberg desk, creating the metadata folder and the metadata.json file therein
You possibly can cease at this level if you happen to don’t intend emigrate your present iceberg desk from Hive to the Knowledge Catalog.
Register
- Register to the AWS Glue as Spark Catalog enabled EMR cluster.
- Register the Iceberg desk to your Knowledge Catalog.
Create the session with the respective Iceberg Packages. Change
- Run the
register_tablecommand to make the Iceberg desk seen in AWS Glue.register_tableregisters an present Iceberg desk’s metadata file (metadata.json) with a catalog(glue_catalog) in order that Spark (and different engines) can question it.- The process creates a Knowledge Catalog entry for the desk, pointing it to the given metadata location.
Change
Make sure that your EMR Spark Cluster has been configured with acceptable AWS Glue permissions
- Validate that the Iceberg desk is now seen within the Knowledge Catalog.
Apache Iceberg’s add_files process
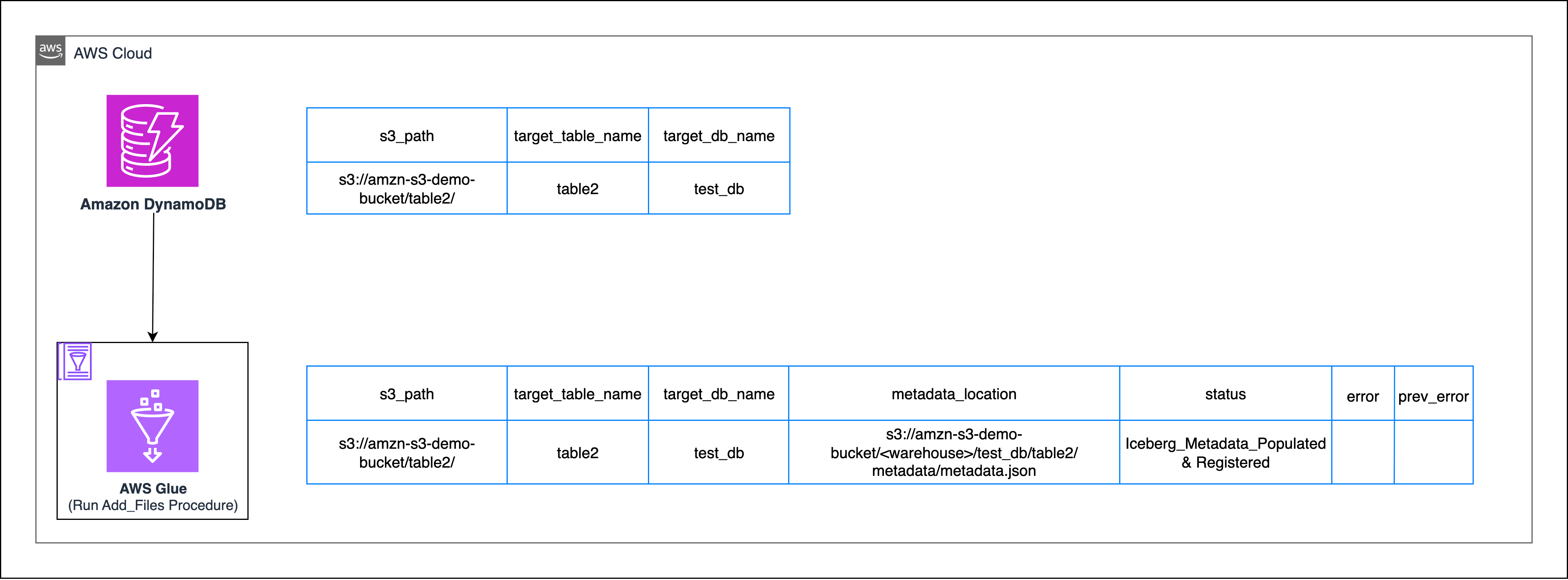
Right here, you’re going to make use of Iceberg’s add_files process to import uncooked knowledge information (Parquet, ORC, Avro) into an present Iceberg desk by updating its metadata. This process works for each Hive and Knowledge Catalog, it doesn’t bodily transfer or rewrite the information—it solely registers them so Iceberg can handle them.
This system contains the next steps:
- Create an empty Iceberg desk in AWS Glue.
As a result of the add_files process expects the iceberg desk to be already current, you might want to create an empty Iceberg desk by inferring the desk schema. - Register present knowledge areas to the Iceberg desk
Utilizing the add_files process in a Glue-backed Iceberg catalog will register the goal S3 path together with all its subdirectories to the empty Iceberg desk created within the earlier step.
You possibly can consolidate each steps right into a single Spark job. For the next AWS Glue job, you’ve specified iceberg as a worth for the --datalake-formats job parameter. See the AWS Glue job configuration documentation for extra particulars.
Change
When working with non-Hive partitioned datasets, a direct migration to Apache Iceberg utilizing add_files may not behave as anticipated. See Appendix C for extra info.
Concerns
Let’s discover two key issues that it’s best to handle when implementing your migration technique.
State administration utilizing DynamoDB management desk
Use the next pattern code snippet to replace the state of DynamoDB desk:
This ensures that any errors are logged and saved to DynamoDB as error_message. On successive retries, earlier errors transfer to prev_error_message and new errors overwrite error_message. Profitable operations clear error_message and archive the final error.
Defending your knowledge from unintended deletion
To guard your knowledge from unintended deletion, by no means delete knowledge or metadata information from Amazon S3 immediately. Iceberg tables which are registered in AWS Glue or Athena are managed tables and must be deleted utilizing the DROP TABLE command from Spark or Athena. The DROP TABLE command deletes each the desk metadata and the underlying knowledge information in S3. See Appendix D for extra info.
Clear up
Full the next steps to wash up your sources:
- Delete the DynamoDB management desk
- Delete the database and tables
- Delete the EMR clusters and AWS Glue job used for testing
Conclusion
On this submit, we confirmed you methods to modernize your Parquet-based knowledge lake into an Apache Iceberg–powered lakehouse with out rewriting or duplicating knowledge. You realized two complementary approaches for this in-place migration:
- Migrate and register – Excellent for changing present Hive-registered Parquet tables into Iceberg-managed tables.
- add_files – Greatest fitted to shortly onboarding uncooked Parquet knowledge into Iceberg with out rewriting information.
Each approaches profit from DynamoDB centralized state monitoring, which allows retries, error auditing, and lifecycle administration throughout a number of datasets.
By combining Apache Iceberg with Amazon EMR, AWS Glue, and Amazon DynamoDB, you possibly can create a production-ready migration pipeline that’s observable, automated, and simple to increase to future knowledge format upgrades. This sample kinds a stable basis for constructing an Iceberg-based lakehouse on AWS, serving to you obtain quicker analytics, higher knowledge governance, and long-term flexibility for evolving workloads.
To get began, strive implementing this resolution utilizing the pattern tables (table1 and table2) that you simply created utilizing Athena queries. we encourage you to share your migration experiences and questions within the feedback.
Appendix A — Creating an EMR cluster for Hive metastore utilizing console and AWS CLI
Console steps:
- Open AWS Administration Console for Amazon EMR and select Create cluster.
- Choose Spark or Hive underneath functions.
- Below AWS Glue Knowledge Catalog settings, be sure that the following choices will not be chosen:
- Use for Hive desk metadata
- Use for Spark desk metadata
- Configure SSH entry (KeyName).
- Configure community (VPC, subnets, SGs) to permit entry to S3.
AWS CLI steps:
Appendix B — EMR cluster with AWS Glue as Spark Metastore
Console steps:
- Open the Amazon EMR console, select Create cluster after which choose EMR Serverless or provisioned EMR.
- Below Software program Configuration, confirm that Spark is put in.
- Below AWS Glue Knowledge Catalog settings, choose Use Glue Knowledge Catalog for Spark metadata.
- Configure SSH entry (KeyName).
- Configure community settings (VPC, subnets, and safety teams) to permit entry to Amazon S3 and AWS Glue.
AWS CLI (provisioned Amazon EMR):
Appendix C — Non-Hive partitioned datasets and Iceberg add_files
This appendix explains why a direct in-place migration utilizing an add_files-style process may not behave as anticipated for datasets that aren’t Hive-partitioned and reveals advisable fixes and examples.
AWS Glue and Athena comply with Hive-style partitioning, the place partition column values are encoded within the S3 path relatively than inside the info information. For instance, following the Parquet dataset created within the Create Pattern Parquet Dataset as a supply part of this submit:
- Partition columns (
event_date,hour) are represented within the folder construction. - Non-partition columns (for instance,
id,title,age) stay contained in the Parquet information. - Iceberg
add_filescan accurately map partitions based mostly on the folder path, even when partition columns are lacking from the Parquet file itself.
Partition column |
Saved in path |
Saved in file |
Athena or AWS Glue and Iceberg habits |
| event_date | Sure | Sure | Partitions inferred accurately |
| hour | Sure | No | Partitions nonetheless inferred from path |
Non-Hive partitioning structure (downside case)
- No partition columns within the path.
- File may not include partition columns.
For those who attempt to create an empty Iceberg desk and immediately load it utilizing add_files on a non-hive structure, the next occurs:
- Iceberg can not routinely map partitions,
add_filesoperations fail or register information with incorrect or lacking partition metadata. - Queries in Athena or AWS Glue will return sudden NULLs or incomplete outcomes.
- Successive incremental writes utilizing
add_fileswill fail.
Advisable approaches:
Create an AWS Glue desk and use the Iceberg snapshot process:
- Create a desk in AWS Glue pointing to your present Parquet dataset.
You would possibly must manually present the schema as a result of glue crawler would possibly fail to routinely infer it for you.
- Use Iceberg’ s snapshot process to transform and transfer the AWS Glue desk into your goal Iceberg desk.
This works as a result of Iceberg depends on AWS Glue for schema inference, so this method ensures right mapping of columns and partitions with out rewriting the info. For extra info, see Snapshot process.
Appendix D — Understanding desk sorts: Managed in comparison with exterior
By default, all non-Iceberg tables created in AWS Glue or Athena are exterior tables, Athena doesn’t handle the underlying knowledge. For those who use CREATE TABLE with out the EXTERNAL key phrase for non-Iceberg tables, Athena points an error.
Nevertheless, when coping with Iceberg tables, AWS Glue and Athena additionally handle the underlying knowledge for the respective tables, so these tables are handled as inner tables.
Working DROP TABLE on Iceberg tables will delete the desk and the underlying knowledge.
The next desk describes how the impact of DELETE and DROP TABLE actions on Iceberg tables in AWS Glue and Athena:
| Operation | What it does | Impact on S3 knowledge |
| DELETE FROM mydb.products_iceberg WHERE date = 2025-10-06; | Creates new snapshot, hides deleted rows | Knowledge information keep till cleanup |
| DROP TABLE test_db.table1; | Deletes desk and all knowledge | Recordsdata are completely eliminated |
Concerning the authors

{kind=link}