
As organizations efficiently develop their Apache Spark workloads on Amazon EMR on EKS, they might search to optimize useful resource scheduling to additional improve cluster utilization, decrease job queuing, and maximize efficiency. Though Kubernetes’ default scheduler, kube-scheduler, works effectively for many containerized functions, it lacks characteristic units able to managing advanced large knowledge workloads with particular necessities equivalent to gang scheduling, useful resource quotas, job priorities, multi-tenancy, and hierarchical queue administration. This limitation can lead to inefficient useful resource utilization, longer job completion instances, and elevated operational prices for organizations operating large-scale knowledge processing workloads.
Apache YuniKorn addresses these limitations by offering a customized useful resource scheduler particularly designed for large knowledge and machine studying (ML) workloads operating on Kubernetes. In contrast to kube-scheduler, YuniKorn affords options equivalent to gang scheduling, ensuring all containers of a Spark software begin collectively, useful resource equity amongst a number of tenants, precedence and preemption capabilities, and queue administration with hierarchical useful resource allocation. For knowledge engineering and platform groups managing large-scale Spark workloads on Amazon EMR on EKS, YuniKorn can enhance useful resource utilization charges, cut back job completion instances, and supply improved useful resource allocation for multi-tenant clusters. That is notably helpful for organizations operating blended workloads with various useful resource necessities, strict SLA necessities, or advanced useful resource sharing insurance policies throughout totally different groups and functions.
This publish explores Kubernetes scheduling fundamentals, examines the constraints of the default kube-scheduler for batch workloads, and demonstrates how YuniKorn addresses these challenges. We talk about tips on how to deploy YuniKorn as a customized scheduler for Amazon EMR on EKS, its integration with job submissions, tips on how to configure queues and placement guidelines, and tips on how to set up useful resource quotas. We additionally present these options in motion via sensible Spark job examples.
Understanding Kubernetes scheduling and the necessity for YuniKorn
On this part, we dive into the small print of Kubernetes scheduling and the necessity for YuniKorn.
How Kubernetes scheduling works
Kubernetes scheduling is the method of assigning pods to nodes inside a cluster whereas contemplating useful resource necessities, scheduling constraints, and isolation constraints. The scheduler evaluates every pod individually towards all schedulable employee nodes, contemplating a number of elements, together with useful resource necessities equivalent to CPU, reminiscence and I/O requests, node affinity preferences for particular node traits, inter-pod affinity and anti-affinity guidelines that decide whether or not the pods ought to be distributed throughout a number of employee nodes or require colocation, taints and tolerations that dictate scheduling constraints, and High quality of Service classifications that affect scheduling precedence.
The scheduling course of operates via a two-phase strategy. In the course of the filtering part, the scheduler identifies all employee nodes that might doubtlessly host the pod by eliminating people who don’t meet the fundamental necessities. The scoring part then ranks all possible employee nodes utilizing scoring algorithms to find out the optimum placement, finally deciding on the highest-scoring node for pod project.
Default implementation of kube-scheduler
kube-scheduler serves because the Kubernetes default scheduler. This scheduler operates on a pod-by-pod foundation, treating every scheduling resolution as an impartial operation with out consideration for the broader software context.When kube-scheduler processes scheduling requests, it follows a steady workflow. The API server is monitored for newly created pods awaiting node project, applies filtering logic to get rid of unsuitable employee nodes, executes its scoring algorithm to rank the remaining candidates, binds the chosen pod to the optimum node, and repeats the method with the subsequent unscheduled pod within the queue.This particular person pod scheduling strategy works effectively for microservices and net functions the place every pod has fewer interdependencies. Nevertheless, this design creates vital challenges when utilized to distributed large knowledge frameworks like Spark that require coordinated scheduling of a number of interdependent pods.
Challenges utilizing kube-scheduler for batch jobs
Batch processing workloads, notably these constructed on Spark, current totally different scheduling necessities that expose limitations in kube-scheduler algorithm. Such functions encompass a number of pods that should function as a cohesive unit, but kube-scheduler lacks the application-level consciousness essential to deal with coordinated scheduling necessities.
Gang scheduling challenges
Essentially the most vital problem emerges from the necessity for gang scheduling, the place all elements of a distributed software have to be scheduled concurrently. A typical Spark software requires a driver pod and a number of executor pods operating in parallel to operate accurately. With out YuniKorn, kube-scheduler first schedules the driving force pod with out understanding the overall quantity of assets that the driving force and executors will want collectively. When the driving force pod begins operating, it makes an attempt to spin up the required executor pods however would possibly fail to seek out enough assets within the cluster. This sequential strategy can lead to the driving force being scheduled efficiently whereas some or all executor pods stay in a pending state attributable to inadequate cluster capability.This partial scheduling creates a problematic state of affairs the place the applying consumes cluster assets however can’t execute significant work. The partially scheduled software will maintain onto allotted assets indefinitely whereas ready for the lacking elements, stopping different functions from using these assets and leading to a impasse scenario.
Useful resource fragmentation points
Useful resource fragmentation represents one other crucial subject that emerges from particular person pod scheduling. When a number of batch functions compete for cluster assets, the dearth of coordinated scheduling results in situations the place enough whole assets exist for a given software, however they develop into fragmented throughout a number of incomplete functions. This fragmentation prevents environment friendly useful resource utilization and may depart functions in perpetual pending states.
The absence of hierarchical queue administration additional compounds these challenges. kube-scheduler gives restricted assist for hierarchical useful resource allocation, making it troublesome to implement honest sharing insurance policies throughout totally different tenants. Organizations can’t simply set up useful resource quotas that assure minimal allocations whereas setting most limits, nor can they implement preemption insurance policies that enable higher-priority jobs to reclaim assets from lower-priority workloads.
The Want for YuniKorn
YuniKorn addresses these batch scheduling limitations via a set of options designed for distributed computing workloads. In contrast to the pod-centric strategy of kube-scheduler, YuniKorn operates with application-level consciousness, understanding the relationships between totally different elements of distributed functions and making scheduling selections accordingly. The options are as follows:
- Gang scheduling for atomic software deployment – Gang scheduling represents YuniKorn’s benefit for batch workloads. This functionality makes positive pods belonging to an software are scheduled atomically—both all elements obtain node assignments, or none are scheduled till enough assets develop into accessible. YuniKorn’s all-or-nothing strategy to scheduling minimizes useful resource deadlocks and partial software failures that influence
kube-schedulerbased mostly deployments, leading to extra predictable job execution and better completion charges. - Hierarchical queue administration and useful resource group – YuniKorn’s queue administration system gives the hierarchical useful resource group that enterprise batch processing environments require. Organizations can set up multi-level queue constructions that mirror their organizational hierarchy, implementing useful resource quotas at every stage to facilitate honest useful resource distribution. The scheduler helps assured useful resource allocations that present minimal useful resource commitments and most limits that stop a single queue from monopolizing cluster assets.
- Dynamic useful resource preemption based mostly on precedence – The preemption capabilities constructed into YuniKorn allow dynamic useful resource reallocation based mostly on job priorities and queue insurance policies. When higher-priority functions require assets presently allotted to lower-priority workloads, YuniKorn can gracefully cease lower-priority pods and reallocate their assets, ensuring crucial jobs obtain the assets they want with out guide intervention.
- Clever useful resource pooling and fair proportion distribution – Useful resource pooling and fair proportion scheduling additional improve YuniKorn’s effectiveness for batch workloads. Relatively than treating every scheduling resolution in isolation, YuniKorn considers the broader useful resource allocation panorama, implementing fair-share algorithms that facilitate equitable useful resource distribution throughout totally different functions and customers whereas maximizing total cluster utilization.
These options add to the prevailing capabilities of Amazon EMR on EKS by establishing an enhanced setting wherein the distinctive necessities of distributed computing workloads are glad.
Resolution overview
Take into account HomeMax, a fictitious firm working a shared Amazon EMR on EKS cluster the place three groups usually submit Spark jobs with distinct traits and priorities:
- Analytics staff – Runs time-sensitive buyer evaluation jobs requiring fast processing for enterprise selections
- Advertising staff – Executes massive in a single day batch jobs for marketing campaign optimization with predictable useful resource patterns
- Knowledge science staff – Runs experimental workloads with various useful resource wants all through the day for mannequin improvement and analysis
With out correct useful resource scheduling, these groups face frequent challenges: useful resource rivalry, job failures attributable to partial scheduling, and incapacity to ensure SLAs for crucial workloads.For our YuniKorn demonstration, we configured an Amazon EMR on EKS cluster with the next specs:
- Amazon EKS cluster: 4 employee nodes utilizing m5.2xlarge Amazon Elastic Compute Cloud (Amazon EC2) cases
- Per-node assets: 8 vCPUs, 32 GiB reminiscence
- Whole cluster capability: 32 vCPU cores and 128 GiB reminiscence
- Accessible for Spark: Roughly 30 vCPUs and roughly 120 GiB reminiscence (after system overhead)
- Kubernetes model: 1.30+ (required for YuniKorn 1.6.x compatibility)
The next code reveals the node group configuration:
We deliberately use a fixed-capacity cluster to supply a managed setting that showcases YuniKorn’s scheduling capabilities with constant, predictable assets. This strategy makes useful resource rivalry situations extra obvious and demonstrates how YuniKorn resolves them.
Amazon EMR on EKS affords strong scaling capabilities via Karpenter. The ideas demonstrated on this fastened setting apply equally to dynamic environments, the place YuniKorn’s capabilities complement the scaling options of Amazon EMR on EKS to optimize useful resource utilization throughout peak demand durations or when scaling limits are reached.
The next diagram reveals the high-level structure of the YuniKorn scheduler operating on Amazon EMR on EKS. This answer additionally features a safe bastion host not proven within the structure diagram that gives entry to the EKS cluster by way of AWS Techniques Supervisor (SSM) Session Supervisor. The bastion host is deployed in a non-public subnet with all essential instruments pre-installed with correct permissions for seamless cluster interplay.
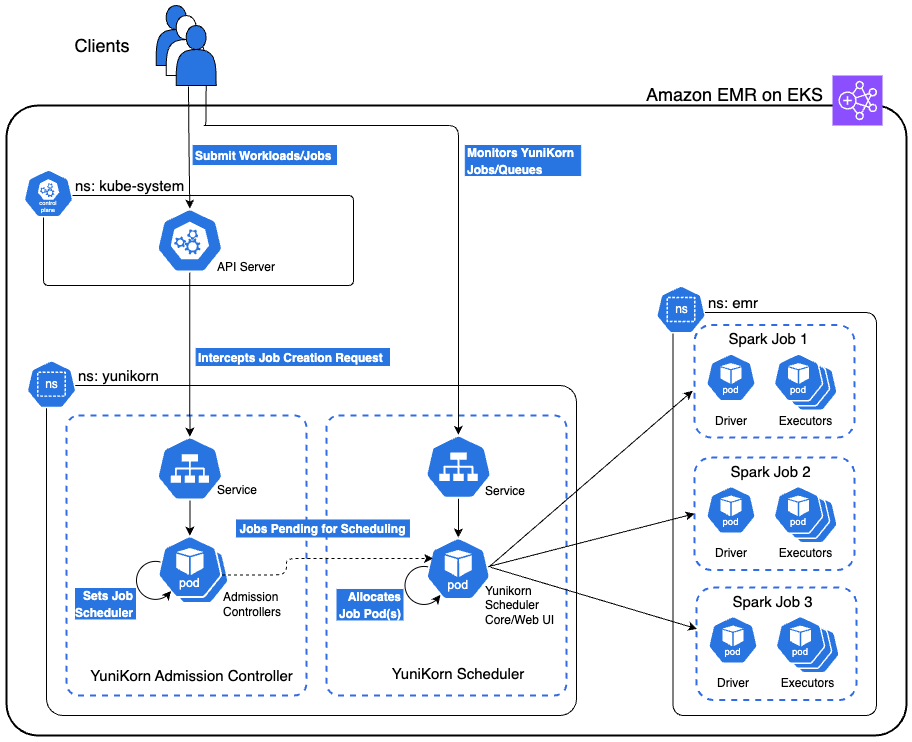
Within the following sections, we discover YuniKorn’s queue structure optimized for this use case. We look at varied demonstration situations, together with gang scheduling, queue-based useful resource administration, priority-based preemption, and fair proportion distribution. We stroll via the method of deploying an Amazon EMR on EKS cluster, implementing the YuniKorn scheduler, configuring the desired queues, and submitting Spark jobs to showcase these situations.
YuniKorn integration on Amazon EMR on EKS
The mixing entails three key elements working collectively: the Amazon EMR on EKS digital cluster configuration, YuniKorn’s admission webhook system, and job-level queue annotations.
Namespace and digital cluster basis
The mixing begins with a devoted Kubernetes namespace the place your Amazon EMR on EKS jobs will run. In our demonstration, we use the emr namespace, created as a normal Kubernetes namespace:
The Amazon EMR on EKS digital cluster is configured to deploy all jobs inside this particular namespace. When creating the digital cluster, you specify the namespace within the container supplier configuration:
This configuration makes positive all jobs submitted to this digital cluster shall be deployed within the emr namespace, establishing the muse for YuniKorn integration.
The YuniKorn interception mechanism
When YuniKorn is put in utilizing Helm, it robotically registers a MutatingAdmissionWebhook with the Kubernetes API server. This webhook acts as an interceptor that displays pod creation occasions in your designated namespace. The webhook registration tells Kubernetes to name YuniKorn every time pods are created within the emr namespace:
This webhook is triggered by any pod creation within the emr namespace, not particularly by YuniKorn annotations. Nevertheless, the webhook’s logic solely modifies pods that include YuniKorn queue annotations, leaving different pods unchanged.
Finish-to-end job stream
If you submit a Spark job via the Spark Operator, the next sequence happens:
- Your Spark job contains YuniKorn queue annotations on each driver and executor pods:
- The Spark Operator processes your
SparkApplicationand creates particular person Kubernetes pods for the driving force and executors. These pods inherit the YuniKorn annotations out of your job template. - When the Spark Operator makes an attempt to create pods within the
emrnamespace, Kubernetes calls YuniKorn’s admission webhook. The webhook examines every pod and performs the next actions:- Detects pods with
yunikorn.apache.org/queueannotations. - Provides
schedulerName: yunikornto these pods. - Leaves pods with out YuniKorn annotations unchanged.
- Detects pods with
This interception means you don’t have to manually specify schedulerName: yunikorn in your Spark jobs—YuniKorn claims the pods transparently based mostly on the presence of queue annotations.
- The YuniKorn scheduler receives the scheduling requests and applies the queue placement guidelines configured within the YuniKorn
ConfigMap:
The supplied rule reads the yunikorn.apache.org/queue annotation and locations the job within the specified queue (for instance, root.analytics-queue). YuniKorn then applies gang scheduling logic, holding all pods till enough assets can be found for the complete software, stopping the partial scheduling points that include kube-scheduler.
- After YuniKorn determines that each one pods will be scheduled in accordance with the queue’s useful resource ensures and limits, it schedules all driver and executor pods. The Spark job begins execution with the assured useful resource allocation outlined within the queue configuration.
The mixture of namespace-based digital cluster configuration, admission webhook interception, and annotation-driven queue placement creates an integration that transforms Amazon EMR on EKS job scheduling with out disrupting current workflows.
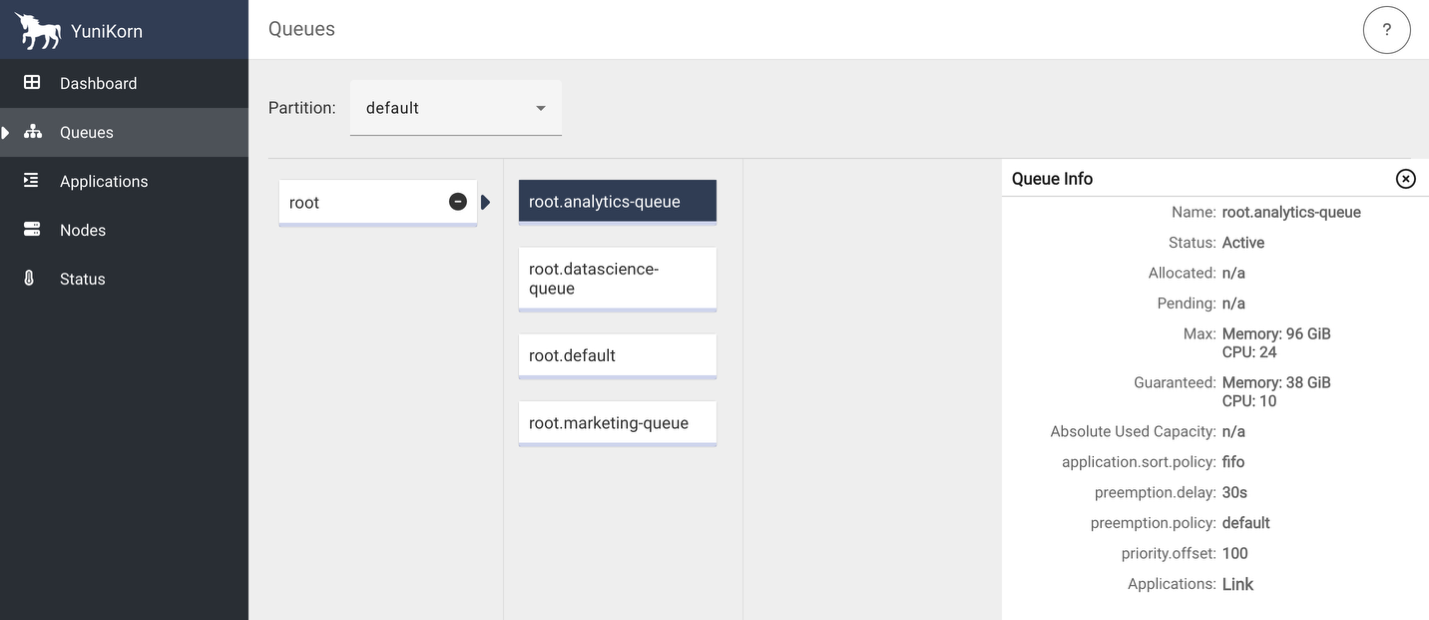
YuniKorn queue structure
To show the assorted YuniKorn options described within the subsequent part, we configured three job-specific queues and a default queue representing our enterprise groups with rigorously balanced useful resource allocations:
Demonstration situations
This part outlines key YuniKorn scheduling capabilities and their corresponding Spark job submissions. These situations show assured useful resource allocation and burst capability utilization. Assured assets symbolize minimal allocations that queues can at all times entry, however jobs would possibly exceed these allocations when extra cluster capability is obtainable. The marketing-job particularly demonstrates burst capability utilization past its assured allocation.
- Gang scheduling – On this state of affairs, we submit
analytics-job.py(analytics-queue, 9 whole cores) andmarketing-job.py(marketing-queue, 17 whole cores) concurrently. YuniKorn makes positive all pods for every job are scheduled atomically, stopping partial useful resource allocation that might trigger job failures in our resource-constrained cluster. - Queue-based useful resource administration – We run all three jobs concurrently to watch assured useful resource allocation. YuniKorn distributes remaining capability proportionally based mostly on queue weights and most limits.
analytics-job.py(analytics-queue) receives assured 10 vCPUs and 38 GB reminiscence.marketing-job.py(marketing-queue) receives assured 8 vCPUs and 32 GB reminiscence.datascience-job.py(datascience-queue) receives assured 6 vCPUs and 26 GB reminiscence.
- Precedence-based preemption – We begin
datascience-job.py(datascience-queue, precedence 25) andmarketing-job.py(marketing-queue, precedence 50) consuming cluster assets, then submit high-priorityanalytics-job.py(analytics-queue, precedence 100). YuniKorn preempts lower-priority jobs to ensure the time-sensitive analytics workload will get its assured assets, sustaining SLA compliance. - Fair proportion distribution – We submit a number of jobs to every queue when all queues have accessible capability. YuniKorn applies configured fair proportion insurance policies inside queues—the analytics queue makes use of First In, First Out (FIFO) technique for predictable scheduling, and the advertising and marketing and knowledge science queues use honest sharing technique for balanced useful resource distribution.
Supply code
You’ll find the codebase within the AWS Samples GitHub repository.
Conditions
Earlier than you deploy this answer, make sure that the next stipulations are in place:
Arrange the answer infrastructure
Full the next steps to arrange the infrastructure:
- Clone the repository to your native machine and set the 2 setting variables. Substitute
- Execute the next script to create the infrastructure:
- To confirm profitable infrastructure deployment, open the AWS CloudFormation console, select your stack, and examine the Occasions, Assets, and Outputs tabs for completion standing, particulars, and checklist of assets created.
Deploy YuniKorn on Amazon EMR on EKS
Run the next script to deploy the Yunikorn helm chart and replace the configmap with the queues and placement guidelines:
Set up EKS cluster connectivity
Full the next steps to determine safe connectivity to your personal EKS cluster:
- Execute the next script in a brand new terminal window. This script establishes port forwarding via the bastion host to make your personal EKS cluster accessible out of your native machine. Hold this terminal window open and operating all through your work session. The script maintains the connection to your EKS cluster.
- Check
kubectlconnectivity in the principle terminal window to confirm which you could efficiently talk with the EKS cluster. You must see the EKS employee nodes listed, confirming that the port forwarding is working accurately.
kubectl get nodes
Confirm profitable YuniKorn deployment
Full the next steps to confirm a profitable deployment:
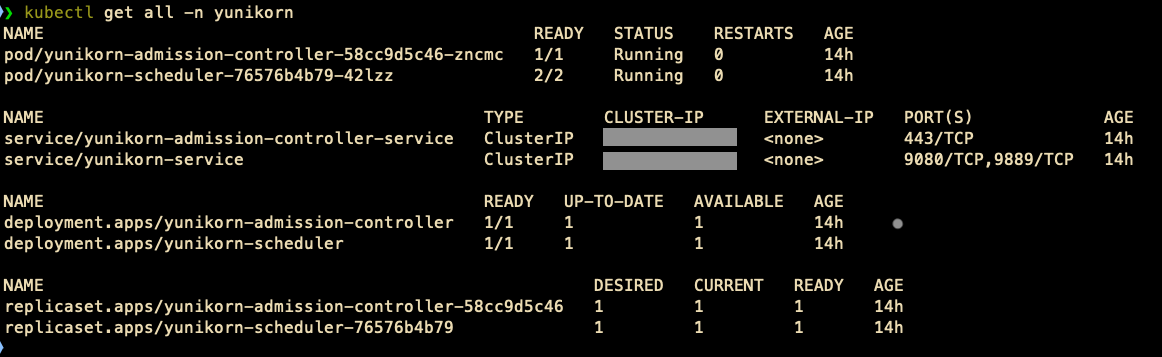
- Record all Kubernetes objects within the yunikorn namespace:
kubectl get all -n yunikorn
You will notice particulars like the next screenshot.
- Test the YuniKorn scheduler logs for configuration loading and search for queue configuration messages:
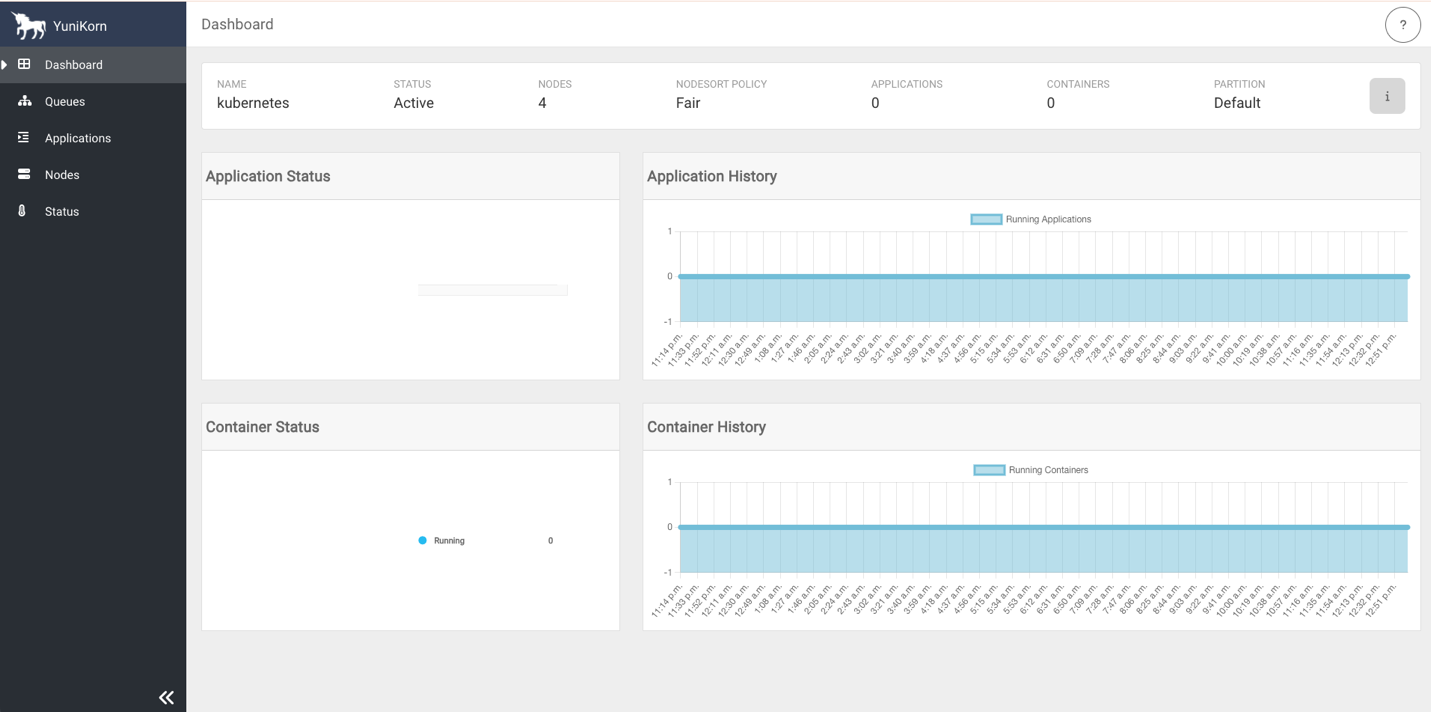
- Entry the YuniKorn net UI by navigating to http://127.0.0.1:9889 in your browser. Port
9889is the default port for the YuniKorn net UI.
The next screenshots present the YuniKorn net UI with queues however no operating functions.
Run Spark jobs with YuniKorn on Amazon EMR on EKS
Full the next steps to run Spark jobs with YuniKorn on Amazon EMR on EKS:
- Execute the next script to arrange the Spark jobs setting. The script uploads PySpark scripts to Amazon Easy Storage Service (Amazon S3) bucket places and creates ready-to-use
YAMLrecordsdata from templates.
- Submit analytics, advertising and marketing, and knowledge science Spark jobs utilizing the next instructions. YuniKorn will place the roles of their respective queues and allocate assets to execution. Consult with Utilizing YuniKorn as a customized scheduler for Apache Spark on Amazon EMR on EKS for supported job submission strategies with YuniKorn as a customized scheduler.
- Evaluate the earlier part describing totally different demonstration situations and submit the Spark jobs utilizing varied combos to see YuniKorn scheduler’s capabilities in motion. We encourage you to regulate the
cores,cases, andreminiscenceparameters and discover the scheduler’s conduct by executing the roles. We additionally encourage you to switch the queues’assuredandmaxcapacities within the fileyunikorn/queue-config-provided.yaml, apply the modifications, and submit jobs to additional perceive Yunikorn scheduler conduct below varied circumstances.
Clear up
To keep away from incurring future prices, full the next steps to delete the assets you created:
- Cease the port forwarding periods:
- Take away all created AWS assets:
Conclusion
YuniKorn addresses the scheduling limitations of default kube-scheduler whereas operating Spark workloads on Amazon EMR on EKS via gang scheduling, clever queue administration, and priority-based useful resource allocation. This publish confirmed how YuniKorn’s queue system allows higher useful resource utilization, prevents job failure attributable to poor allocation of assets, and helps multi-tenant environments.
To get began with YuniKorn on Amazon EMR on EKS, discover the Apache YuniKorn documentation for implementation guides, overview Amazon EMR on EKS finest practices for optimization methods, and interact with the YuniKorn neighborhood for ongoing assist.
Concerning the authors
 Suvojit Dasgupta is a Principal Knowledge Architect at Amazon Internet Providers. He leads a staff of expert engineers in designing and constructing scalable knowledge options for numerous clients. He makes a speciality of growing and implementing revolutionary knowledge architectures to deal with advanced enterprise challenges.
Suvojit Dasgupta is a Principal Knowledge Architect at Amazon Internet Providers. He leads a staff of expert engineers in designing and constructing scalable knowledge options for numerous clients. He makes a speciality of growing and implementing revolutionary knowledge architectures to deal with advanced enterprise challenges.
 Peter Manastyrny is a Senior Product Supervisor at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it easy and environment friendly to run open-source knowledge analytics frameworks equivalent to Spark on Amazon EKS.
Peter Manastyrny is a Senior Product Supervisor at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it easy and environment friendly to run open-source knowledge analytics frameworks equivalent to Spark on Amazon EKS.
 Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Internet Providers. He’s keen about fixing advanced issues and delivering well-structured options for numerous clients. His experience spans throughout a variety of cloud applied sciences, offering scalable and dependable infrastructure tailor-made to every undertaking’s distinctive challenges.
Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Internet Providers. He’s keen about fixing advanced issues and delivering well-structured options for numerous clients. His experience spans throughout a variety of cloud applied sciences, offering scalable and dependable infrastructure tailor-made to every undertaking’s distinctive challenges.
 Gregory Fina is a Principal Startup Options Architect for Generative AI at Amazon Internet Providers, the place he empowers startups to speed up innovation via cloud adoption. He makes a speciality of software modernization, with a robust deal with serverless architectures, containers, and scalable knowledge storage options. He’s keen about utilizing generative AI instruments to orchestrate and optimize large-scale Kubernetes deployments, in addition to advancing GitOps and DevOps practices for high-velocity groups. Exterior of his customer-facing position, Greg actively contributes to open supply tasks, particularly these associated to Backstage.
Gregory Fina is a Principal Startup Options Architect for Generative AI at Amazon Internet Providers, the place he empowers startups to speed up innovation via cloud adoption. He makes a speciality of software modernization, with a robust deal with serverless architectures, containers, and scalable knowledge storage options. He’s keen about utilizing generative AI instruments to orchestrate and optimize large-scale Kubernetes deployments, in addition to advancing GitOps and DevOps practices for high-velocity groups. Exterior of his customer-facing position, Greg actively contributes to open supply tasks, particularly these associated to Backstage.

{kind=link}