 Whereas Sustaining Benchmark Parity")
DeepSeek launched DeepSeek-V3.2-Exp, an “intermediate” replace to V3.1 that provides DeepSeek Sparse Consideration (DSA)—a trainable sparsification path geared toward long-context effectivity. DeepSeek additionally decreased API costs by 50%+, in step with the acknowledged effectivity positive aspects.
DeepSeek-V3.2-Exp retains the V3/V3.1 stack (MoE + MLA) and inserts a two-stage consideration path: (i) a light-weight “indexer” that scores context tokens; (ii) sparse consideration over the chosen subset.
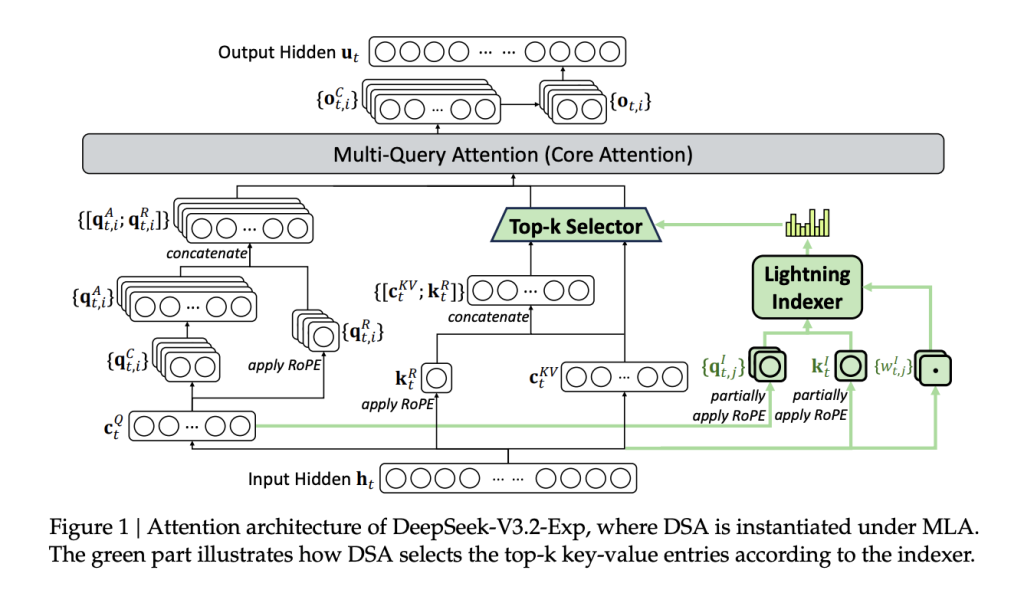
FP8 index → top-k choice → sparse core consideration
DeepSeek Sparse Consideration (DSA) splits the eye path into two compute tiers:
(1) Lightning indexer (FP8, few heads): For every question token
ℎ
𝑡
∈
𝑅
𝑑
h
t
∈R
d
, a light-weight scoring perform computes index logits
𝐼
𝑡
,
𝑠
I
t,s
in opposition to previous tokens
ℎ
𝑠
h
s
. It makes use of small indexer heads with a ReLU nonlinearity for throughput. As a result of this stage runs in FP8 and with few heads, its wall-time and FLOP value are minor relative to dense consideration.
(2) Advantageous-grained token choice (top-k): The system selects solely the top-k=2048 key-value entries for every question after which performs normal consideration solely over that subset. This modifications the dominant time period from
𝑂
(
𝐿
2
)
O(L
2
) to
𝑂
(
𝐿
𝑘
)
O(Lk) with
𝑘
≪
𝐿
ok≪L, whereas preserving the flexibility to take care of arbitrarily distant tokens when wanted.
Coaching sign: The indexer is educated to mimic the dense mannequin’s head-summed consideration distribution through KL-divergence, first underneath a brief dense warm-up (indexer learns targets whereas the primary mannequin is frozen), then throughout sparse coaching the place gradients for the indexer stay separate from the primary mannequin’s language loss. Heat-up makes use of ~2.1B tokens; sparse stage makes use of ~943.7B tokens with top-k=2048, LR ~7.3e-6 for the primary mannequin.
Instantiation: DSA is applied underneath MLA (Multi-head Latent Consideration) in MQA mode for decoding so every latent KV entry is shared throughout question heads, aligning with the kernel-level requirement that KV entries be reused throughout queries for throughput.
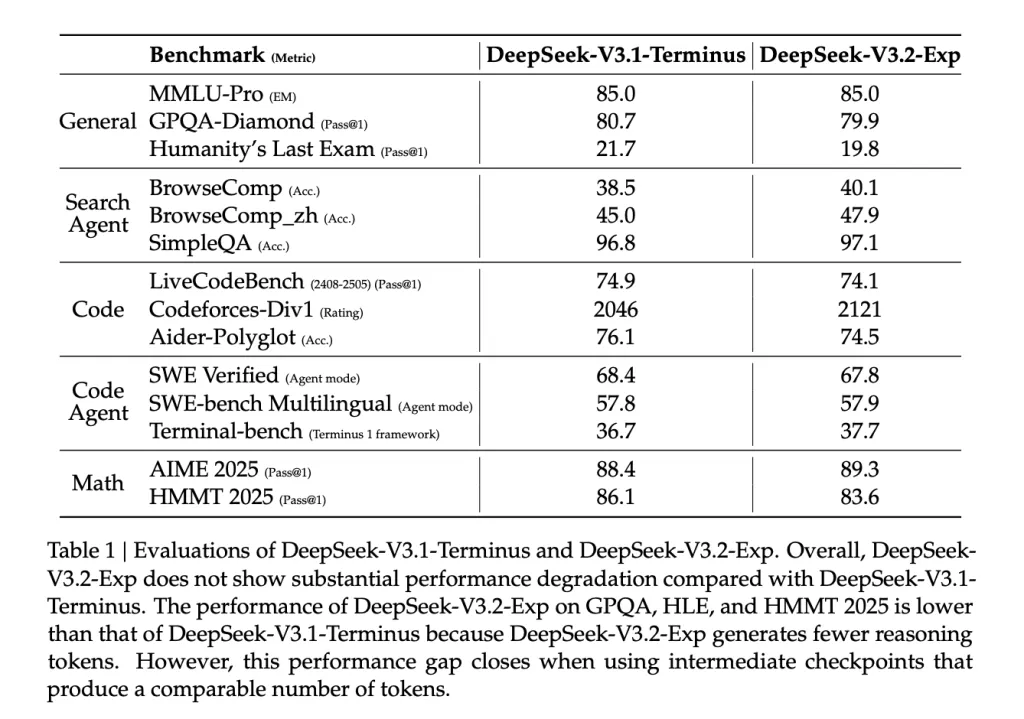
Lets Discuss it’s effectivity and accuracy
- Prices vs. place (128k): DeepSeek offers per-million-token value curves for prefill and decode on H800 clusters (reference worth $2/GPU-hour). Decode prices fall considerably with DSA; prefill additionally advantages through a masked MHA simulation at brief lengths. Whereas the precise 83% determine circulating on social media maps to “~6× cheaper decode at 128k,” deal with it as DeepSeek-reported till third-party replication lands.
- Benchmark parity: The launched desk reveals MMLU-Professional = 85.0 (unchanged), small motion on GPQA/HLE/HMMT as a consequence of fewer reasoning tokens, and flat/optimistic motion on agentic/search duties (e.g., BrowseComp 40.1 vs 38.5). The authors observe the gaps shut when utilizing intermediate checkpoints that produce comparable token counts.
- Operational alerts: Day-0 assist in SGLang and vLLM suggests the kernels and scheduler modifications are production-aimed, not research-only. DeepSeek additionally references TileLang, DeepGEMM (indexer logits), and FlashMLA (sparse kernels) for open-source kernels.
- Pricing: DeepSeek says API costs had been lower by 50%+, in step with model-card messaging about effectivity and Reuters/TechCrunch protection that the discharge targets decrease long-context inference economics.
Abstract
DeepSeek V3.2-Exp reveals that trainable sparsity (DSA) can maintain benchmark parity whereas materially bettering long-context economics: official docs decide to 50%+ API worth cuts, with day-0 runtime assist already accessible, and neighborhood threads declare bigger decode-time positive aspects at 128k that warrant impartial replication underneath matched batching and cache insurance policies. The near-term takeaway for groups is straightforward: deal with V3.2-Exp as a drop-in A/B for RAG and long-document pipelines the place O(L2)O(L^2)O(L2) consideration dominates prices, and validate end-to-end throughput/high quality in your stack.
FAQs
1) What precisely is DeepSeek V3.2-Exp?
V3.2-Exp is an experimental, intermediate replace to V3.1-Terminus that introduces DeepSeek Sparse Consideration (DSA) to enhance long-context effectivity.
2) Is it actually open supply, and underneath what license?
Sure. The repository and mannequin weights are licensed underneath MIT, per the official Hugging Face mannequin card (License part).
3) What’s DeepSeek Sparse Consideration (DSA) in follow?
DSA provides a light-weight indexing stage to attain/choose a small set of related tokens, then runs consideration solely over that subset—yielding “fine-grained sparse consideration” and reported long-context coaching/inference effectivity positive aspects whereas retaining output high quality on par with V3.1.
Take a look at the GitHub Web page and Hugging Face Mannequin Card. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}