 Framework for CUDA Optimization Unlocking 3x Extra Energy from GPUs")
Estimated studying time: 6 minutes
AI has simply unlocked triple the facility from GPUs—with out human intervention. DeepReinforce Crew launched a brand new framework referred to as CUDA-L1 that delivers a mean 3.12× speedup and as much as 120× peak acceleration throughout 250 real-world GPU duties. This isn’t mere tutorial promise: each outcome may be reproduced with open-source code, on broadly used NVIDIA {hardware}.
The Breakthrough: Contrastive Reinforcement Studying (Contrastive-RL)
On the coronary heart of CUDA-L1 lies a significant leap in AI studying technique: Contrastive Reinforcement Studying (Contrastive-RL). In contrast to conventional RL, the place an AI merely generates options, receives numerical rewards, and updates its mannequin parameters blindly, Contrastive-RL feeds again the efficiency scores and prior variants straight into the following technology immediate.
- Efficiency scores and code variants are given to the AI in every optimization spherical.
- The mannequin should then write a “Efficiency Evaluation” in pure language—reflecting on which code was quickest, why, and what methods led to that speedup.
- Every step forces advanced reasoning, guiding the mannequin to synthesize not only a new code variant however a extra generalized, data-driven psychological mannequin of what makes CUDA code quick.
The outcome? The AI discovers not simply well-known optimizations, but in addition non-obvious methods that even human consultants typically overlook—together with mathematical shortcuts that solely bypass computation, or reminiscence methods tuned to particular {hardware} quirks.
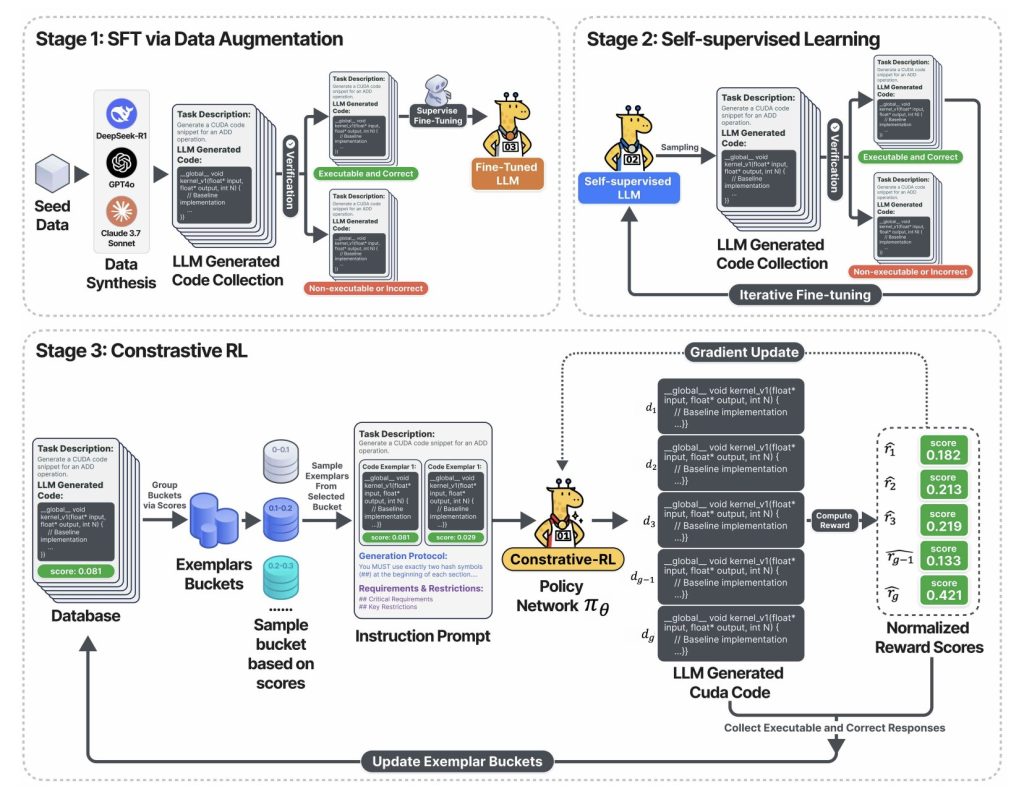
The above diagram captures the three-stage coaching pipeline:
- Stage 1: The LLM is fine-tuned utilizing validated CUDA code—collected by sampling from main basis fashions (DeepSeek-R1, GPT-4o, Claude, and many others.), however retaining solely right and executable outputs.
- Stage 2: The mannequin enters a self-training loop: it generates numerous CUDA code, retains solely the practical ones, and makes use of these to additional study. Consequence: speedy enchancment in code correctness and protection—all with out handbook labeling.
- Stage 3: Within the Contrastive-RL part, the system samples a number of code variants, reveals every with its measured velocity, and challenges the AI to debate, analyze, and outreason earlier generations earlier than producing the following spherical of optimizations. This reflection-and-improvement loop is the important thing flywheel that delivers huge speedups.
How Good Is CUDA-L1? Laborious Information
Speedups Throughout the Board
KernelBench—the gold-standard benchmark for GPU code technology (250 real-world PyTorch workloads)—was used to measure CUDA-L1:
| Mannequin/Stage | Avg. Speedup | Max Speedup | Median | Success Fee |
|---|---|---|---|---|
| Vanilla Llama-3.1-405B | 0.23× | 3.14× | 0× | 68/250 |
| DeepSeek-R1 (RL-tuned) | 1.41× | 44.2× | 1.17× | 248/250 |
| CUDA-L1 (All Levels) | 3.12× | 120× | 1.42× | 249/250 |
- 3.12× common speedup: The AI discovered enhancements in nearly each job.
- 120× most speedup: Some computational bottlenecks and inefficient code (like diagonal matrix multiplications) have been remodeled with essentially superior options.
- Works throughout {hardware}: Codes optimized on NVIDIA A100 GPUs retained substantial good points ported to different architectures (L40, H100, RTX 3090, H20), with imply speedups from 2.37× to three.12×, median good points persistently above 1.1× throughout all units.
Case Examine: Discovering Hidden 64× and 120× Speedups
diag(A) * B—Matrix Multiplication with Diagonal
- Reference (inefficient):
torch.diag(A) @ Bconstructs a full diagonal matrix, requiring O(N²M) compute/reminiscence. - CUDA-L1 optimized:
A.unsqueeze(1) * Bleverages broadcasting, reaching solely O(NM) complexity—leading to a 64× speedup. - Why: The AI reasoned that allocating a full diagonal was useless; this perception was unreachable by way of brute-force mutation, however surfaced by way of comparative reflection throughout generated options.
3D Transposed Convolution—120× Sooner
- Unique code: Carried out full convolution, pooling, and activation—even when enter or hyperparameters mathematically assured all zeros.
- Optimized code: Used “mathematical short-circuit”—detected that given
min_value=0, the output might be instantly set to zero, bypassing all computation and reminiscence allocation. This one perception delivered orders of magnitude extra speedup than hardware-level micro-optimizations.
Enterprise Impression: Why This Issues
For Enterprise Leaders
- Direct Price Financial savings: Each 1% speedup in GPU workloads interprets to 1% much less cloud GPUseconds, decrease power prices, and extra mannequin throughput. Right here, the AI delivered, on common, over 200% further compute from the identical {hardware} funding.
- Sooner Product Cycles: Automated optimization reduces the necessity for CUDA consultants. Groups can unlock efficiency good points in hours, not months, and give attention to options and analysis velocity as a substitute of low-level tuning.
For AI Practitioners
- Verifiable, Open Supply: All 250 optimized CUDA kernels are open-sourced. You may check the velocity good points your self throughout A100, H100, L40, or 3090 GPUs—no belief required.
- No CUDA Black Magic Required: The method doesn’t depend on secret sauce, proprietary compilers, or human-in-the-loop tuning.
For AI Researchers
- Area Reasoning Blueprint: Contrastive-RL affords a brand new method to coaching AI in domains the place correctness and efficiency—not simply pure language—matter.
- Reward Hacking: The authors deep dive into how the AI found refined exploits and “cheats” (like asynchronous stream manipulation for false speedups) and description strong procedures to detect and stop such habits.
Technical Insights: Why Contrastive-RL Wins
- Efficiency suggestions is now in-context: In contrast to vanilla RL, the AI can study not simply by trial and error, however by reasoned self-critique.
- Self-improvement flywheel: The reflection loop makes the mannequin strong to reward gaming and outperforms each evolutionary approaches (fastened parameter, in-context contrastive studying) and conventional RL (blind coverage gradient).
- Generalizes & discovers elementary rules: The AI can mix, rank, and apply key optimization methods like reminiscence coalescing, thread block configuration, operation fusion, shared reminiscence reuse, warp-level reductions, and mathematical equivalence transformations.
Desk: High Strategies Found by CUDA-L1
| Optimization Approach | Typical Speedup | Instance Perception |
|---|---|---|
| Reminiscence Format Optimization | Constant boosts | Contiguous reminiscence/storage for cache effectivity |
| Reminiscence Entry (Coalescing, Shared) | Average-to-high | Avoids financial institution conflicts, maximizes bandwidth |
| Operation Fusion | Excessive w/ pipelined ops | Fused multi-op kernels scale back reminiscence reads/writes |
| Mathematical Brief-circuiting | Extraordinarily excessive (10-100×) | Detects when computation may be skipped solely |
| Thread Block/Parallel Config | Average | Adapts block sizes/shapes to {hardware}/job |
| Warp-Stage/Branchless Reductions | Average | Lowers divergence and sync overhead |
| Register/Shared Reminiscence Optimization | Average-high | Caches frequent information near computation |
| Async Execution, Minimal Sync | Varies | Overlaps I/O, allows pipelined computation |
Conclusion: AI Is Now Its Personal Optimization Engineer
With CUDA-L1, AI has grow to be its personal efficiency engineer, accelerating analysis productiveness and {hardware} returns—with out counting on uncommon human experience. The outcome isn’t just larger benchmarks, however a blueprint for AI methods that educate themselves how you can harness the total potential of the {hardware} they run on.
AI is now constructing its personal flywheel: extra environment friendly, extra insightful, and higher in a position to maximize the sources we give it—for science, trade, and past.
Try the Paper, Codes and Venture Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


{kind=link}