
Apache Flink is an open supply framework for stream and batch processing functions. It excels in dealing with real-time analytics, event-driven functions, and sophisticated information processing with low latency and excessive throughput. Flink is designed for stateful computation with exactly-once consistency ensures for the appliance state.
Amazon Managed Service for Apache Flink is a completely managed stream processing service that you need to use to run Apache Flink jobs at scale with out worrying about managing clusters and provisioning sources. You’ll be able to deal with implementing your software utilizing your built-in improvement atmosphere (IDE) of selection, and construct and bundle the appliance utilizing customary construct and steady integration and supply (CI/CD) instruments.
With Managed Service for Apache Flink, you possibly can management the appliance lifecycle by means of easy AWS API actions. You should utilize the API to start out and cease the appliance, and to use any modifications to the code, runtime configuration, and scale. The service takes care of managing the underlying Flink cluster, providing you with a serverless expertise. You’ll be able to implement automation resembling CI/CD pipelines with instruments that may work together with the AWS API or AWS Command Line Interface (AWS CLI).
You’ll be able to management the appliance utilizing the AWS Administration Console, AWS CLI, AWS SDK, and instruments utilizing the AWS API, resembling AWS CloudFormation or Terraform. The service will not be prescriptive on the automation software you employ to deploy and orchestrate the appliance.
Paraphrasing Jackie Stewart, the well-known racing driver, you don’t want to grasp tips on how to function a Flink cluster to make use of Managed Service for Apache Flink, however some Mechanical Sympathy will assist you implement a strong and dependable automation.
On this two-part collection, we discover what occurs throughout an software’s lifecycle. This submit covers core ideas and the appliance workflow throughout regular operations. In Half 2, we have a look at potential failures, tips on how to detect them by means of monitoring, and methods to rapidly resolve points once they happen.
Definitions
Earlier than analyzing the appliance lifecycle steps, we have to make clear the utilization of sure phrases within the context of Managed Service for Apache Flink:
- Utility – The principle useful resource you create, management, and run in Managed Service for Apache Flink is an software.
- Utility code bundle – For every Managed Service for Apache Flink software, you implement the appliance code bundle (software artifact) of the Flink software code you need to run. This code is compiled and packaged together with dependencies right into a JAR or a ZIP file, that you just add to an Amazon Easy Storage Service (Amazon S3) bucket.
- Configuration – Every software has a configuration that accommodates the knowledge to run it. The configuration factors to the appliance code bundle within the S3 bucket and defines the parallelism, which can even decide the appliance sources, by way of KPUs. It additionally defines safety, networking, and runtime properties, that are handed to your software code at runtime.
- Job – If you begin the appliance, Managed Service for Apache Flink creates a devoted cluster for you and runs your software code as a Flink job.
The next diagram reveals the connection between these ideas.
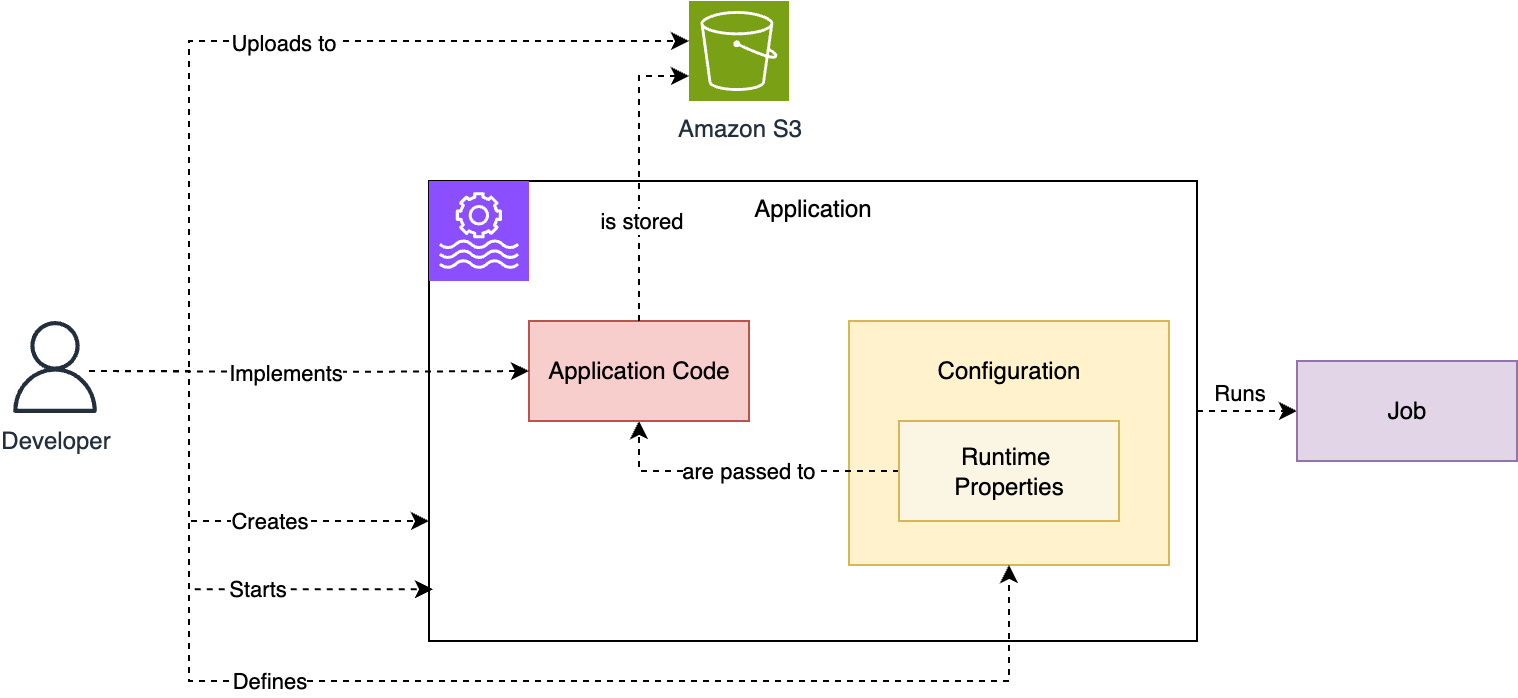
There are two extra vital ideas: checkpoints and savepoints, the mechanisms Flink makes use of to ensure state consistency throughout failures and operations. In Managed Service for Apache Flink, each checkpoints and savepoints are totally managed.
- Checkpoints – These are managed by the appliance configuration and enabled by default with a interval of 1 minute. In Managed Service for Apache Flink, checkpoints are used when a job routinely restarts after a runtime failure. They aren’t sturdy and are deleted when the appliance is stopped or up to date and when the appliance routinely scales.
- Savepoints – These are referred to as snapshots in Managed Service for Apache Flink, and are used to persist the appliance state when the appliance is intentionally restarted by the consumer, on account of an replace or an automated scaling occasion. Snapshots might be triggered by the consumer. Snapshots (if enabled) are additionally routinely used to avoid wasting and restore the appliance state when the appliance is stopped and restarted, for instance to deploy a change or routinely scale. Computerized use of snapshots is enabled within the software configuration (enabled by default once you create an software utilizing the console).
Lifecycle of an software in Managed Service for Apache Flink
Beginning with the comfortable path, a typical lifecycle of a Managed Service for Apache Flink software includes the next steps:
- Create and configure a brand new software.
- Begin the appliance.
- Deploy a change (replace the runtime configuration, replace the appliance code, change the parallelism to scale up or down).
- Cease the appliance.
Beginning, stopping, and updating the appliance use snapshots (if enabled) to retain software state consistency throughout operations. We advocate enabling snapshots on each manufacturing and staging software, to help the persistence of the appliance state throughout operations.
In Managed Service for Apache Flink, the appliance lifecycle is managed by means of the console, API actions within the kinesisanalyticsv2 API, or equal actions within the AWS CLI and SDK. On high of those basic operations, you possibly can construct your personal automation utilizing completely different instruments, instantly utilizing low-level actions or utilizing larger stage infrastructure-as-code (IaC) tooling resembling AWS CloudFormation or Terraform.
On this submit, we confer with the low-level API actions used at every step. Any higher-level IaC tooling will use mixture of those operations. Understanding these operations is prime to designing a strong automation.
The next diagram summarizes the appliance lifecycle, displaying typical operations and software statuses.
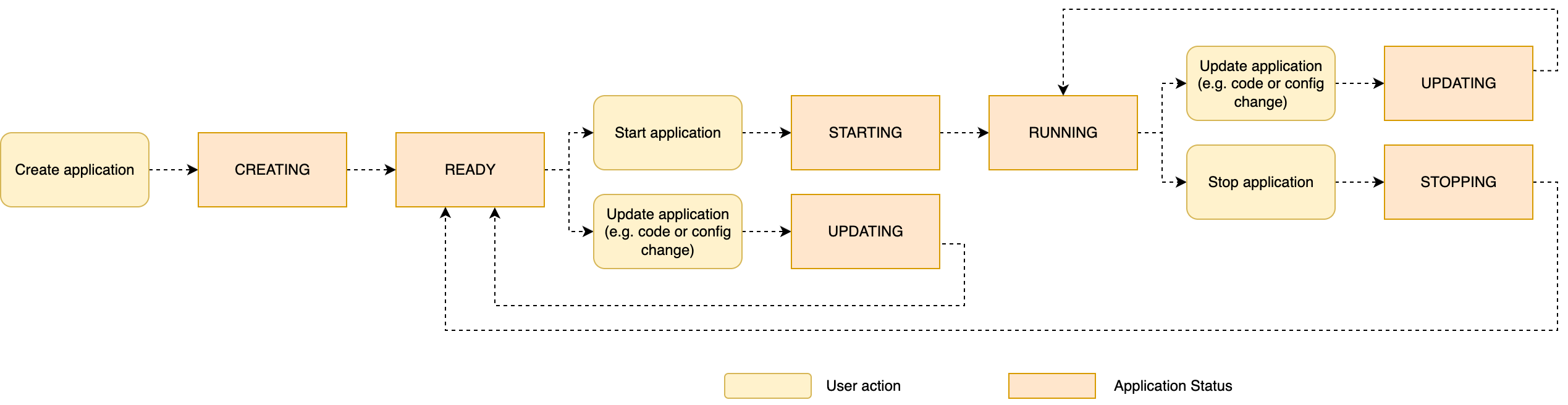
The standing of your software, READY, STARTING, RUNNING, UPDATING, and so forth, might be noticed on the console and utilizing the DescribeApplication API motion.
Within the following sections, we analyze every lifecycle operation in additional element.
Create and configure the appliance
Step one is creating a brand new Managed Service for Apache Flink software, together with defining the appliance configuration. You are able to do this in a single step utilizing the CreateApplication motion, or by creating the essential software configuration after which updating the configuration earlier than beginning it utilizing UpdateApplication. The latter method is what you do once you create an software from the console.
On this section, the developer packages the appliance they’ve applied in a JAR file (for Java) or ZIP file (for Python) and uploads it to an S3 bucket the consumer has beforehand created. The bucket title and the trail to the appliance code bundle are a part of the configuration you outline.
When UpdateApplication or CreateApplication is invoked, Managed Service for Apache Flink takes a duplicate of the appliance code bundle (JAR or ZIP file) referred by the configuration. The configuration is rejected if the file pointed by the configuration doesn’t exist.
The next diagram illustrates this workflow.
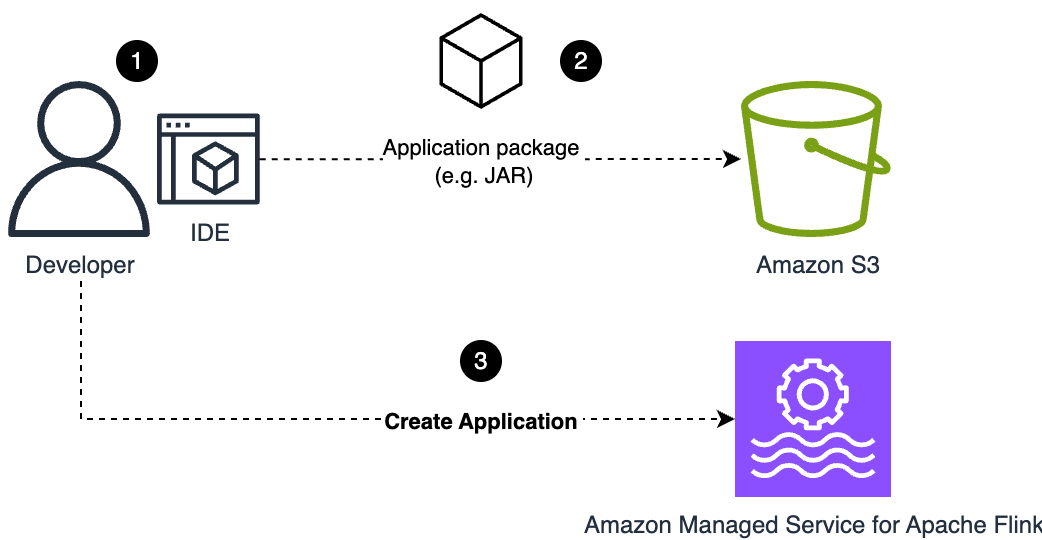
Merely updating the appliance code bundle within the S3 bucket doesn’t set off an replace. You should run UpdateApplication to make the brand new file seen to the service and set off the replace, even once you overwrite the code bundle with the identical title.
Begin the appliance
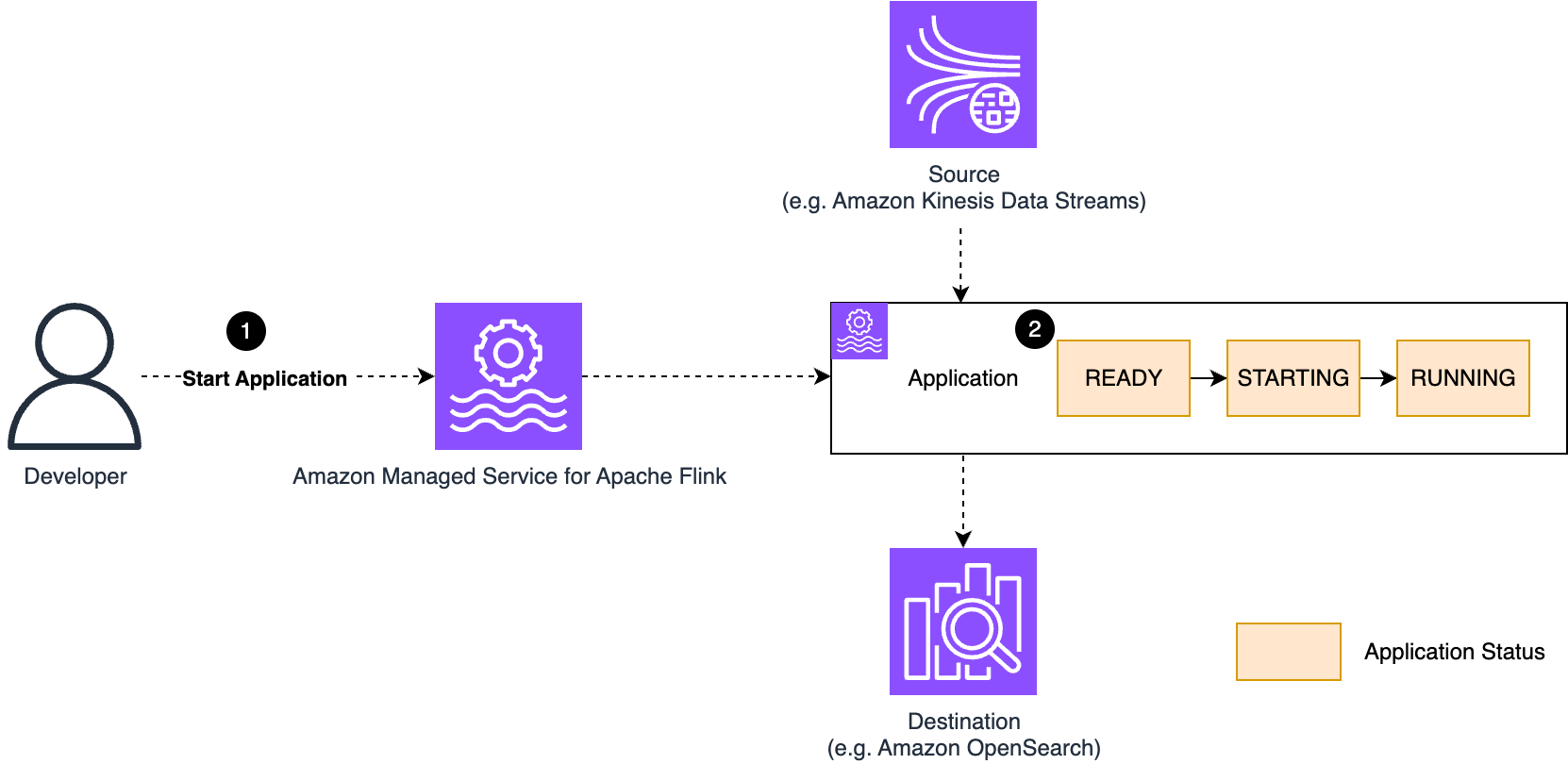
Managed Service for Apache Flink provisions sources when the appliance is definitely working, and also you solely pay for the sources of working functions. You explicitly management when to start out the appliance by issuing a StartApplication.
Managed Service for Apache Flink indexes on excessive availability and runs your software in a devoted Flink cluster. If you begin the appliance, Managed Service for Apache Flink deploys a devoted cluster and deploys and runs the Flink job based mostly on the configuration you outlined.
If you begin the appliance, the standing of the appliance strikes from READY, to STARTING, after which RUNNING.
The next diagram illustrates this workflow.
Managed Service for Apache Flink helps each streaming mode, the default for Apache Flink, and batch mode:
- Streaming mode – In streaming mode, after an software is efficiently began and goes into
RUNNINGstanding, it retains working till you cease it explicitly. From this level on, the habits on failure is routinely restarting the job from the newest checkpoint, so there isn’t a information loss. We talk about extra particulars about this failure state of affairs later on this submit. - Batch mode – A Flink software working in batch mode behaves in another way. After you begin it, it goes into
RUNNINGstanding, and the job continues working till it completes the processing. At that time the job will gracefully cease, and the Managed Service for Apache Flink software goes again toREADYstanding.
This submit focuses on streaming functions solely.
Replace the appliance
In Managed Service for Apache Flink, you deal with the next modifications by updating the appliance configuration, utilizing the console or the UpdateApplication API motion:
- Utility code modifications, changing the bundle (JAR or ZIP file) with one containing a brand new model
- Runtime properties modifications
- Scaling, which means altering parallelism and sources (KPU) modifications
- Operational parameter modifications, resembling checkpoint, logging stage, and monitoring setup
- Networking configuration modifications
If you modify the appliance configuration, Managed Service for Apache Flink creates a brand new configuration model, recognized by a model ID quantity, routinely incremented at each change.
Replace the code bundle
We talked about how the service takes a duplicate of the code bundle (JAR or ZIP file) once you replace the appliance configuration. The copy is related to the brand new software configuration model that has been created. The service makes use of its personal copy of the code bundle to start out the appliance. You’ll be able to safely exchange or delete the code bundle after you might have up to date the configuration. The brand new bundle will not be taken under consideration till you replace the appliance configuration once more.
Replace a READY (not working) software
If you happen to replace an software in READY standing, nothing particular occurs past creating the brand new configuration model that might be used the following time you begin the appliance. Nonetheless, in manufacturing, you’ll usually replace the configuration of an software in RUNNING standing to use a change. Managed Service for Apache Flink routinely handles the operations required to replace the appliance with no information loss.
Replace a RUNNING software
To know what occurs once you replace a working software, you want to keep in mind that Flink is designed for sturdy consistency and exactly-once state consistency. To keep up these options when a change is utilized, Flink should cease the info processing, take a duplicate of the appliance state, restart the job with the modifications, and restore the state, earlier than processing can restart.
This can be a customary Flink habits, and applies to any modifications, whether or not it’s code modifications, runtime configuration modifications, or new parallelism to scale up and down. Managed Service for Apache Flink routinely orchestrates this course of for you. If snapshots are enabled, the service will take a snapshot earlier than stopping the processing and restart from the snapshot when the change is deployed. This fashion, the change might be deployed with zero information loss.
If snapshots are disabled, the service restarts the job with the change, however the state might be empty, like the primary time you began the appliance. This would possibly trigger information loss. You usually don’t need this to occur, notably in manufacturing functions.
Let’s discover a sensible instance, illustrated by the next diagram. As an illustration, once you need to deploy a code change, the next steps usually occur (on this instance, we assume that snapshots are enabled, which they need to be in a manufacturing software):
- Make modifications to the appliance code.
- The construct course of creates the appliance bundle (JAR or ZIP file), both manually or utilizing CI/CD automation.
- Add the brand new software bundle to an S3 bucket.
- Replace the appliance configuration pointing to the brand new software bundle.
- As quickly as you efficiently replace the configuration, Managed Service for Apache Flink begins the operation for updating the appliance. The appliance standing modifications to
UPDATING. The Flink job is stopped, taking a snapshot of the appliance state. - After the modifications have been utilized, the appliance is restarted utilizing the brand new configuration, which on this case consists of the brand new software code, and the job restores the state from the snapshot. When the method is full, the appliance standing goes again to
RUNNING.
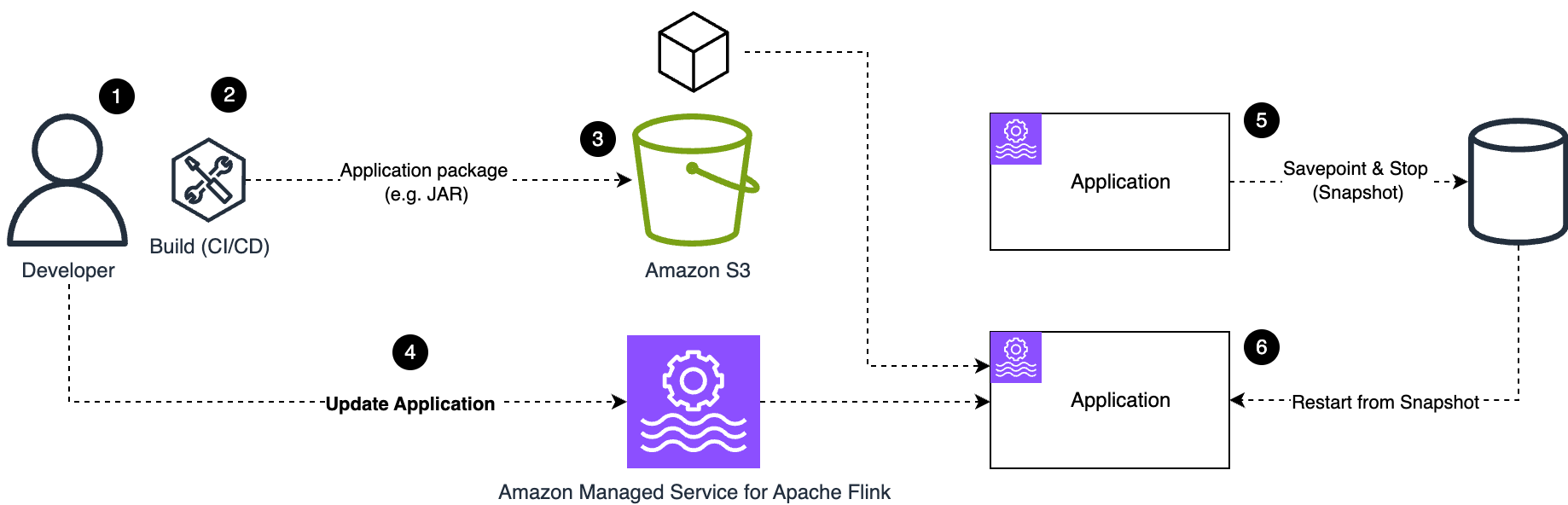
The method is analogous for modifications to the appliance configuration. For instance, you possibly can change the parallelism to scale the appliance updating the appliance configuration, inflicting the appliance to be redeployed with the brand new parallelism and the quantity sources (CPU, reminiscence, native storage) based mostly on the brand new variety of KPU.
Replace the appliance’s IAM position
The appliance configuration accommodates a reference to an AWS Id and Entry Administration (IAM) position. Within the unlikely case you need to use a special position, you possibly can replace the appliance configuration utilizing UpdateApplication. The method would be the similar described earlier.
Nonetheless, you normally need to modify the IAM position, so as to add or take away permissions. This operation doesn’t use the Managed Service for Apache Flink software lifecycle and might be achieved at any time. No software cease and restart is required. IAM modifications take impact instantly, probably inducing a failure if, for instance, you inadvertently take away a required permission. On this case, the habits of the Flink job’s response would possibly range, relying on the affected part.
Cease the appliance
You’ll be able to cease a working Managed Service for Apache Flink software utilizing the StopApplication motion or the console. The service gracefully stops the appliance. The state turns from RUNNING, into STOPPING, and at last into READY.
When snapshots are enabled, the service will take a snapshot of the appliance state when it’s stopped, as proven within the following diagram.
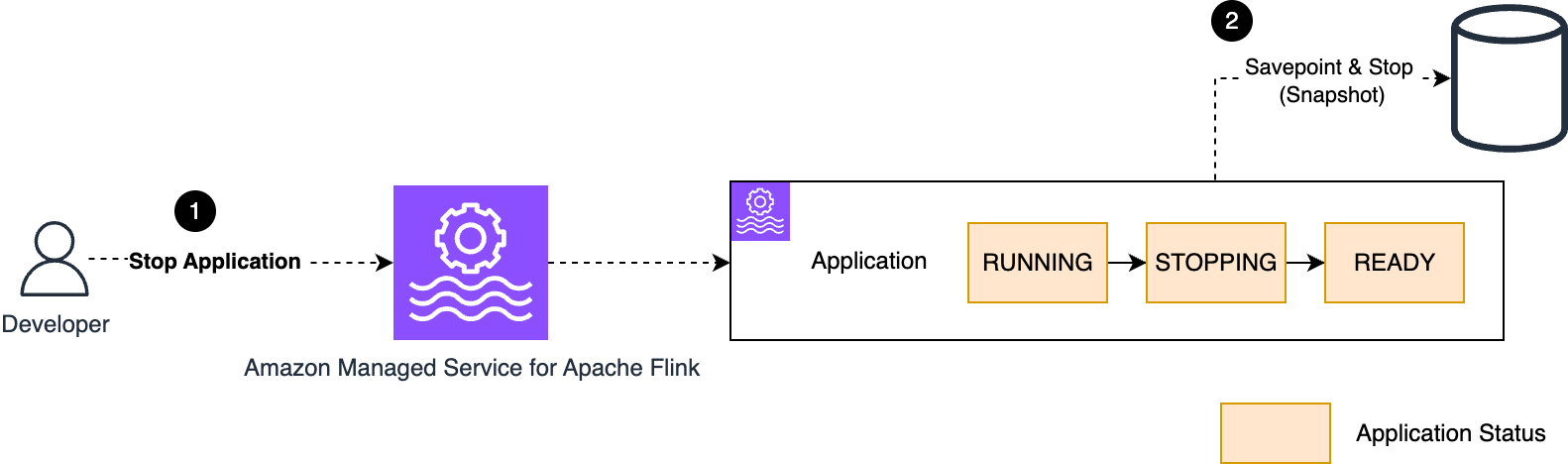
After you cease the appliance, any useful resource beforehand provisioned to run your software is reclaimed. You incur no price whereas the appliance will not be working (READY).
Begin the appliance from a snapshot
Typically, you would possibly need to cease a manufacturing software and restart it later, restarting the processing from the purpose it was stopped. Managed Service for Apache Flink helps beginning the appliance from a snapshot. The snapshot saves not solely the appliance state, but additionally the purpose within the supply—the offsets in a Kafka matter, for instance—the place the appliance stopped consuming.
When snapshots are enabled, Managed Service for Apache Flink routinely takes a snapshot once you cease the appliance. This snapshot can be utilized once you restart the appliance.
The StartApplication API command has three restore choices:
RESTORE_FROM_LATEST_SNAPSHOT: Restore from the newest snapshot.RESTORE_FROM_CUSTOM_SNAPSHOT: Restore from a customized snapshot (you want to specify which one).SKIP_RESTORE_FROM_SNAPSHOT: Skip restoring from the snapshot. The appliance will begin with no state, because the very first time you ran it.
If you begin the appliance for the very first time, no snapshot is obtainable but. Whatever the restore possibility you select, the appliance will begin with no snapshot.
The method of beginning the appliance from a snapshot is visualized within the following diagram.
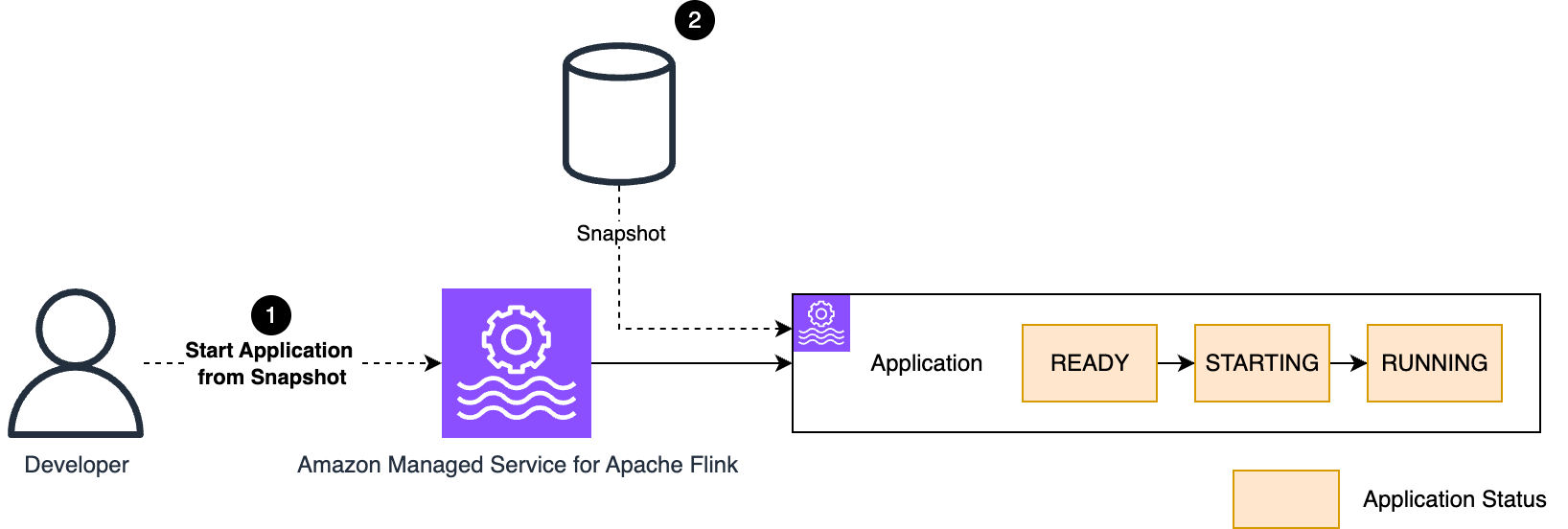
In manufacturing, you usually need to restore from the newest snapshot (RESTORE_FROM_LATEST_SNAPSHOT). This can routinely use the snapshot the service created once you final stopped the appliance.
Snapshots are based mostly on Flink’s savepoint mechanism and preserve the exactly-once consistency of the interior state. Additionally, the danger of reprocessing duplicate information from the supply is minimized as a result of the snapshot is taken synchronously whereas the Flink job is stopped.
Begin the appliance from an older snapshot
In Managed Service for Apache Flink, you possibly can schedule taking periodic snapshots of a working manufacturing software, for instance utilizing the Snapshot Supervisor. Taking a snapshot from a working software doesn’t cease the processing and solely introduces a minimal overhead (akin to checkpointing). With the second possibility, RESTORE_FROM_CUSTOM_SNAPSHOT, you possibly can restart the appliance again in time, utilizing a snapshot older than the one taken on the final StopApplication.
As a result of the supply positions—for instance, the offsets in a Kafka matter—are additionally restored with the snapshot, the appliance will revert to the purpose the appliance was processing when the snapshot was taken. This can even restore the state at that actual level, offering consistency.
If you begin an software from an older snapshot, there are two vital concerns:
- Solely restore snapshots taken throughout the supply system retention interval – If you happen to restore a snapshot older than the supply retention, information loss would possibly happen, and the appliance habits is unpredictable.
- Restarting from an older snapshot will seemingly generate duplicate output – That is usually not an issue when the end-to-end system is designed to be idempotent. Nonetheless, this would possibly trigger issues in case you are utilizing a Flink transactional connector, resembling File System sink or Kafka sink with exactly-once ensures enabled. As a result of these sinks are designed to ensure no duplicates (stopping them at any price), they could stop your software from restarting from an older snapshot. There are workarounds to this operational drawback, however they rely upon the particular use case and are past the scope of this submit.
Understanding what occurs once you begin your software
We’ve realized the basic operations within the lifecycle of an software. In Managed Service for Apache Flink, these operations are managed by a number of API actions, resembling StartApplication, UpdateApplication, and StopApplication. The service controls each operation for you. You don’t should provision or handle Flink clusters. Nonetheless, a greater understanding of what occurs throughout the lifecycle provides you with adequate Mechanical Sympathy to acknowledge potential failure modes and implement a extra sturdy automation.
Let’s see intimately what occurs once you subject a StartApplication command on an software in READY (not working). If you subject an UpdateApplication command on a RUNNING software, the appliance is first stopped with a snapshot, after which restarted with the brand new configuration, with a course of equivalent to what we’re going to see.
Composition of a Flink cluster
To know what occurs once you begin the appliance, we have to introduce a few extra ideas. A Flink cluster is comprised of two kinds of nodes:
- A single Job Supervisor, which acts as a coordinator
- A number of Process Managers, which do the precise information processing
In Managed Service for Apache Flink, you possibly can see the cluster nodes within the Flink Dashboard, which you’ll entry from the console.
Flink decomposes the info processing outlined by your software code into a number of subtasks, that are distributed throughout the Process Supervisor nodes, as illustrated within the following diagram.
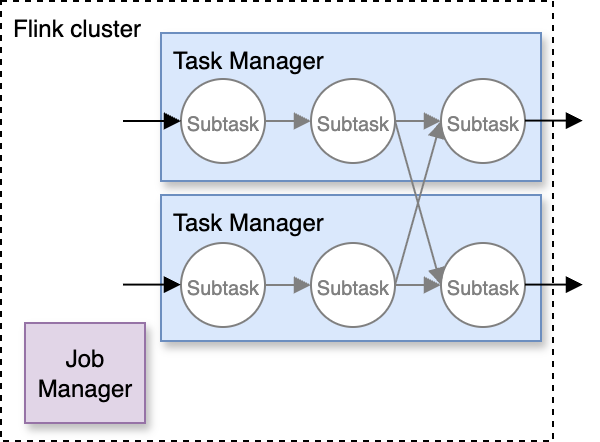
Keep in mind, in Managed Service for Apache Flink, you don’t want to fret about provisioning and configuring the cluster. The service gives a devoted cluster in your software. The whole quantity of vCPU, reminiscence, and native storage of Process Managers matches the variety of KPU you configured.
Beginning your Managed Service for Apache Flink software
Now that we’ve mentioned how a Flink cluster consists, let’s discover what occurs once you subject a StartApplication command, or when the appliance restarts after a change has been deployed with an UpdateApplication command.
The next diagram illustrates the method. Every little thing is carried out routinely for you.
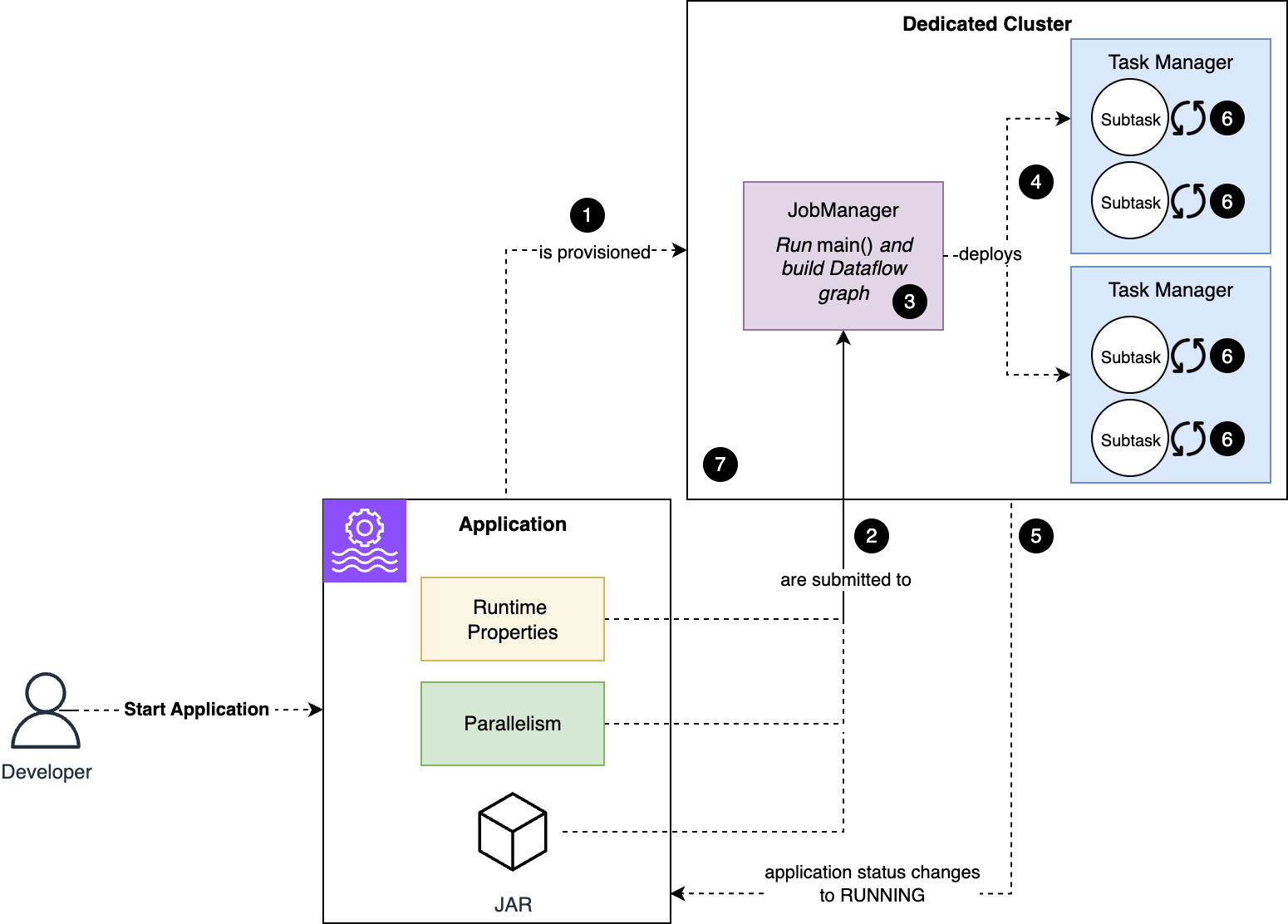
The workflow consists of the next steps:
- A devoted cluster, with the quantity of sources you requested, based mostly on the variety of KPU, is provisioned in your software.
- The appliance code, runtime properties, and different configurations resembling the appliance parallelism are handed to the Job Supervisor node, the coordinator of the cluster.
- The Java or Python code within the
primary()technique of your software is executed. This generates the logical graph of operators of your software (referred to as dataflow). Based mostly on the dataflow you outlined and the appliance parallelism, Flink generates the subtasks, the precise nodes Flink will execute to course of your information. - Flink then distributes the job’s subtasks throughout Process Managers, the precise employee nodes of the cluster.
- When the earlier step succeeds, the Flink job standing and the Managed Service for Apache Flink software standing change to
RUNNING. Nonetheless, the job remains to be not fully working and processing information. All substasks have to be initialized. - Every subtask independently restores its state, if ranging from a snapshot, and initializes runtime sources. For instance, Flink’s Kafka supply connector restores the partition assignments and offsets from the savepoint (snapshot), establishes a connection to the Kafka cluster, and subscribes to the Kafka matter. From this step onward, a Flink job will cease and restart from its final checkpoint when encountering any unhandled error. If the issue inflicting the error will not be transient, the job retains stopping and restarting from the identical checkpoint in a loop.
- When all subtasks are efficiently initialized and alter to
RUNNINGstanding, the Flink job begins processing information and is now correctly working.
Conclusion
On this submit, we mentioned how the lifecycle of a Managed Service for Apache Flink software is managed by easy AWS API instructions, or the equal utilizing the AWS SDK or AWS CLI. In case you are utilizing high-level automation instruments resembling AWS CloudFormation or Terraform, the low-level actions are additionally abstracted away for you. The service handles the complexity of working the Flink cluster and orchestrating the Flink job lifecycle.
Nonetheless, with a greater understanding of how Flink works and what the service does for you, you possibly can implement extra sturdy automation and troubleshoot failures.
Within the Half 2, we proceed analyzing failure situations that may occur throughout regular operations or once you deploy a change or scale the appliance, and tips on how to monitor operations to detect and recuperate when one thing goes improper.
In regards to the authors

{kind=link}