
In Half 1 of this sequence, we mentioned elementary operations to manage the lifecycle of your Amazon Managed Service for Apache Flink software. If you’re utilizing higher-level instruments corresponding to AWS CloudFormation or Terraform, the device will execute these operations for you. Nonetheless, understanding the elemental operations and what the service robotically does can present some stage of Mechanical Sympathy to confidently implement a extra strong automation.
Within the first a part of this sequence, we centered on the blissful paths. In a super world, failures don’t occur, and each change you deploy works completely. Nonetheless, the actual world is much less predictable. Quoting Werner Vogels, Amazon’s CTO, “Every thing fails, on a regular basis.”
On this publish, we discover failure situations that may occur throughout regular operations or whenever you deploy a change or scale the applying, and how you can monitor operations to detect and recuperate when one thing goes unsuitable.
The much less blissful path
A sturdy automation have to be designed to deal with failure situations, specifically throughout operations. To try this, we have to perceive how Apache Flink can deviate from the blissful path. Because of the nature of Flink as a stateful stream processing engine, detecting and resolving failure situations requires totally different methods in comparison with different long-running functions, corresponding to microservices or short-lived serverless features (corresponding to AWS Lambda).
Flink’s conduct on runtime errors: The fail-and-restart loop
When a Flink job encounters an surprising error at runtime (an unhandled exception), the traditional conduct is to fail, cease the processing, and restart from the newest checkpoint. Checkpoints permit Flink to help knowledge consistency and no knowledge loss in case of failure. Additionally, as a result of Flink is designed for stream processing functions, which run repeatedly, if the error occurs once more, the default conduct is to maintain restarting, hoping the issue is transient and the applying will finally recuperate the traditional processing.In some instances, the issue will not be transient, nevertheless. For instance, whenever you deploy a code change that comprises a bug, inflicting the job to fail as quickly because it begins processing knowledge, or if the anticipated schema doesn’t match the data within the supply, inflicting deserialization or processing errors. The identical state of affairs may also occur if you happen to mistakenly modified a configuration that stops a connector to succeed in the exterior system. In these instances, the job is caught in a fail-and-restart loop, indefinitely, or till you actively force-stop it.
When this occurs, the Managed Service for Apache Flink software standing could be RUNNING, however the underlying Flink job is definitely failing and restarting. The AWS Administration Console offers you a touch, pointing that the applying may want consideration (see the next screenshot).
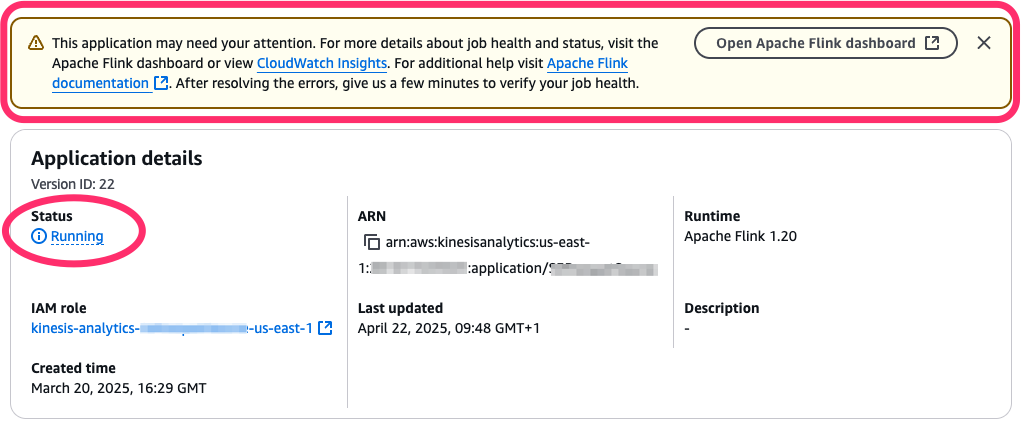
Within the following sections, we discover ways to monitor the applying and job standing, to robotically react to this case.
When beginning or updating the applying goes unsuitable
To know the failure mode, let’s assessment what occurs robotically whenever you begin the applying, or when the applying restarts after you issued UpdateApplication command, as we explored in Half 1 of this sequence. The next diagram illustrates what occurs when an software begins.
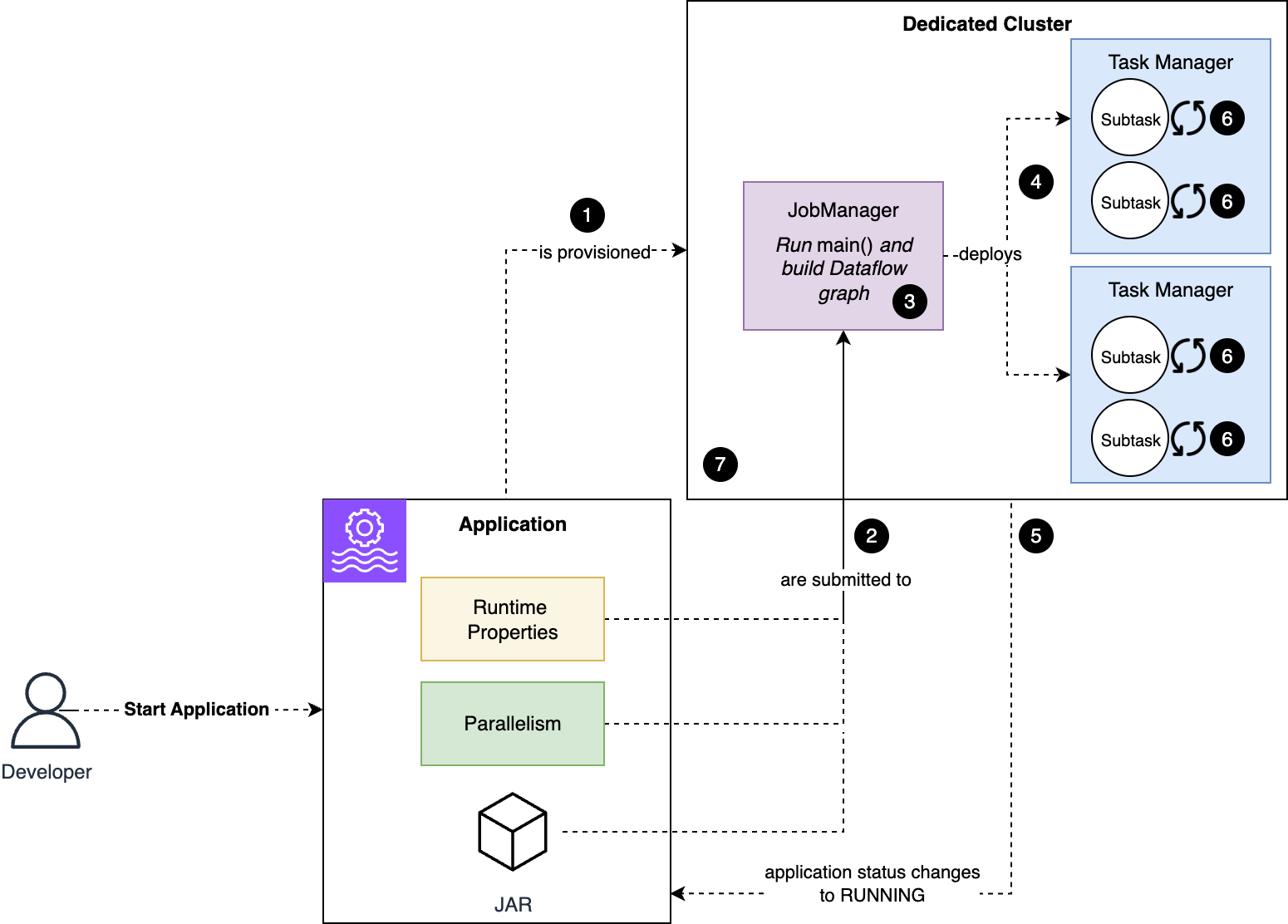
The workflow consists of the next steps:
- Managed Service for Apache Flink provisions a cluster devoted to your software.
- The code and configuration are submitted to the Job Supervisor node.
- The code within the
predominant()technique of your software runs, defining the dataflow of your software. - Flink deploys to the Process Supervisor nodes the substasks that make up your job.
- The job and software standing change to
RUNNING. Nonetheless, subtasks begin initializing now. - Subtasks restore their state, if relevant, and initialize any assets. For instance, a Kafka connector’s subtask initializes the Kafka consumer and subscribes the subject.
- When all subtasks are efficiently initialized, they modify to
RUNNINGstanding and the job begins processing knowledge.
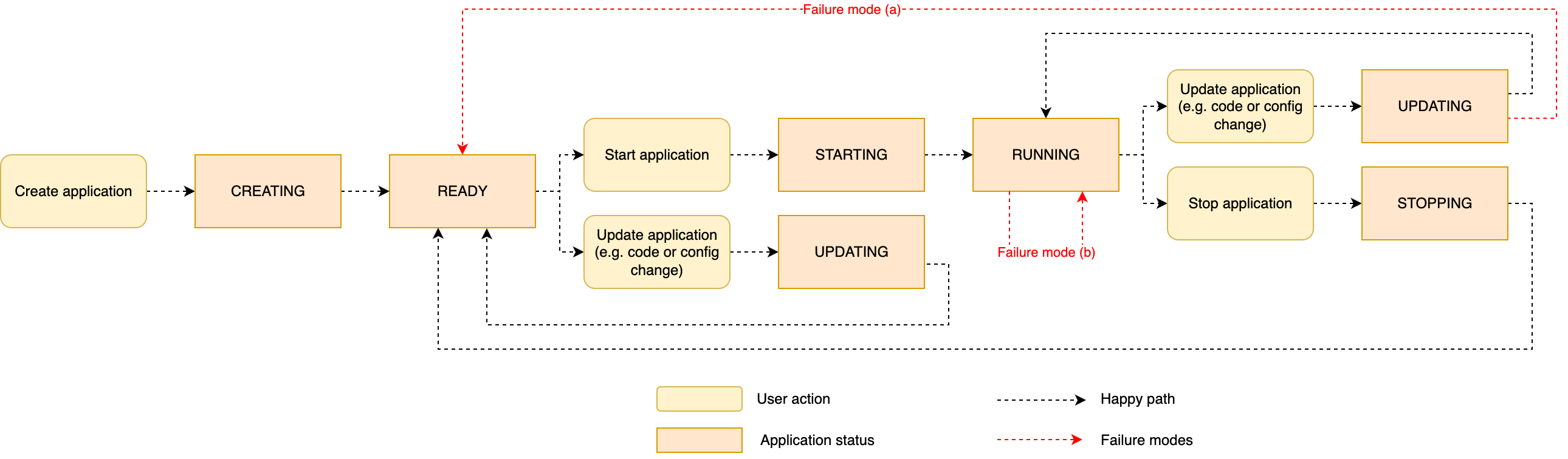
To new Flink customers, it may be complicated {that a} RUNNING standing doesn’t essentially suggest the job is wholesome and processing knowledge.When one thing goes unsuitable throughout the strategy of beginning (or restarting) the applying, relying on the part when the issue arises, you may observe two several types of failure modes:
- (a) An issue prevents the applying code from being deployed – Your software may encounter this failure state of affairs if the deployment fails as quickly because the code and configuration are handed to the Job Supervisor (step 2 of the method), for instance if the applying code bundle is malformed. A typical error is when the JAR is lacking a
mainClassor ifmainClassfactors to a category that doesn’t exist. This failure mode may also occur if the code of yourpredominant()technique throws an unhandled exception (step 3). In these instances, the applying fails to vary toRUNNING, and reverts toREADYafter the try. - (b) The appliance is began, the job is caught in a fail-and-restart loop – An issue may happen later within the course of, after the applying standing has modified
RUNNING. For instance, after the Flink job has been deployed to the cluster (step 4 of the method), a part may fail to initialize (step 6). This may occur when a connector is misconfigured, or an issue prevents it from connecting to the exterior system. For instance, a Kafka connector may fail to hook up with the Kafka cluster due to the connector’s misconfiguration or networking points. One other potential state of affairs is when the Flink job efficiently initializes, but it surely throws an exception as quickly because it begins processing knowledge (step 7). When this occurs, Flink reacts to a runtime error and may get caught in a fail-and-restart loop.
The next diagram illustrates the sequence of software standing, together with the 2 failure situations simply described.
Troubleshooting
We’ve examined what can go unsuitable throughout operations, specifically whenever you replace a RUNNING software or restart an software after altering its configuration. On this part, we discover how we are able to act on these failure situations.
Roll again a change
If you deploy a change and understand one thing will not be fairly proper, you usually wish to roll again the change and put the applying again in working order, till you examine and repair the issue. Managed Service for Apache Flink supplies a swish solution to revert (roll again) a change, additionally restarting the processing from the purpose it was stopped earlier than making use of the fault change, offering consistency and no knowledge loss.In Managed Service for Apache Flink, there are two varieties of rollbacks:
- Computerized – Throughout an computerized rollback (additionally referred to as system rollback), if enabled, the service robotically detects when the applying fails to restart after a change, or when the job begins however instantly falls right into a fail-and-restart loop. In these conditions, the rollback course of robotically restores the applying configuration model earlier than the final change was utilized and restarts the applying from the snapshot taken when the change was deployed. See Enhance the resilience of Amazon Managed Service for Apache Flink software with system-rollback function for extra particulars. This function is disabled by default. You may allow it as a part of the applying configuration.
- Handbook – A handbook rollback API operation is sort of a system rollback, but it surely’s initiated by the person. If the applying is operating however you observe one thing not behaving as anticipated after making use of a change, you may set off the rollback operation utilizing the RollbackApplication API motion or the console. Handbook rollback is feasible when the applying is
RUNNINGorUPDATING.
Each rollbacks work equally, restoring the configuration model earlier than the change and restarting with the snapshot taken earlier than the change. This prevents knowledge loss and brings you again to a model of the applying that was working. Additionally, this makes use of the code bundle that was saved on the time you created the earlier configuration model (the one you’re rolling again to), so there is no such thing as a inconsistency between code, configuration, and snapshot, even when within the meantime you have got changed or deleted the code bundle from the Amazon Easy Storage Service (Amazon S3) bucket.
Implicit rollback: Replace with an older configuration
A 3rd solution to roll again a change is to easily replace the configuration, bringing it again to what it was earlier than the final change. This creates a brand new configuration model, and requires the right model of the code bundle to be out there within the S3 bucket whenever you concern the UpdateApplication command.
Why is there a 3rd possibility when the service supplies system rollback and the managed RollbackApplication motion? As a result of most high-level infrastructure-as-code (IaC) frameworks corresponding to Terraform use this technique, explicitly overwriting the configuration. You will need to perceive this risk though you’ll in all probability use the managed rollback if you happen to implement your automation primarily based on the low-level actions.
The next are two essential caveats to contemplate for this implicit rollback:
- You’ll usually wish to restart the applying from the snapshot that was taken earlier than the defective change was deployed. If the applying is presently
RUNNINGand wholesome, this isn’t the newest snapshot (RESTORE_FROM_LATEST_SNAPSHOT), however somewhat the earlier one. You will need to set the restart fromRESTORE_FROM_CUSTOM_SNAPSHOTand choose the right snapshot. - UpdateApplication solely works if the applying is
RUNNINGand wholesome, and the job could be gracefully stopped with a snapshot. Conversely, if the applying is caught in a fail-and-restart loop, you should force-stop it first, change the configuration whereas the applying isREADY, and later begin the applying from the snapshot that was taken earlier than the defective change was deployed.
Power-stop the applying
In regular situations, you cease the applying gracefully, with the automated snapshot creation. Nonetheless, this may not be potential in some situations, corresponding to if the Flink job is caught in a fail-and-restart loop. This may occur, for instance, if an exterior system the job makes use of stops working, or as a result of the AWS Id and Entry Administration (IAM) configuration was erroneously modified, eradicating permissions required by the job.
When the Flink job will get caught in a fail-and-restart loop after a defective change, your first possibility needs to be utilizing RollbackApplication, which robotically restores the earlier configuration and begins from the right snapshot. Within the uncommon instances you may’t cease the applying gracefully or use RollbackApplication, the final resort is force-stopping the applying. Power-stop makes use of the StopApplication command with Power=true. You may as well force-stop the applying from the console.
If you force-stop an software, no snapshot is taken (if that have been potential, you’ll have been in a position to gracefully cease). If you restart the applying, you may both skip restoring from a snapshot (SKIP_RESTORE_FROM_SNAPSHOT) or use a snapshot that was beforehand taken, scheduled utilizing Snapshot Supervisor, or manually, utilizing the console or CreateApplicationSnapshot API motion.
We strongly advocate organising scheduled snapshots for all manufacturing functions that you may’t afford restarting with no state.
Monitoring Apache Flink software operations
Efficient monitoring of your Apache Flink functions throughout and after operations is essential to confirm the end result of the operation and permit lifecycle automation to boost alarms or react, in case one thing goes unsuitable.
The principle indicators you need to use throughout operations embrace the FullRestarts metric (out there in Amazon CloudWatch) and the applying, job, and process standing.
Monitoring the end result of an operation
The best solution to detect the end result of an operation, corresponding to StartApplication or UpdateApplication, is to make use of the ListApplicationOperations API command. This command returns an inventory of the newest operations of a particular software, together with upkeep occasions that power an software restart.
For instance, to retrieve the standing of the newest operation, you need to use the next command:
The output might be much like the next code:
OperationStatus will observe the identical logic as the applying standing reported by the console and by DescribeApplication. This implies it may not detect a failure throughout the operator initialization or whereas the job begins processing knowledge. As we have now discovered, these failures may put the applying in a fail-and-restart loop. To detect these situations utilizing your automation, you should use different methods, which we cowl in the remainder of this part.
Detecting the fail-and-restart loop utilizing the FullRestarts metric
The best solution to detect whether or not the applying is caught in a fail-and-restart loop is utilizing the fullRestarts metric, out there in CloudWatch Metrics. This metric counts the variety of restarts of the Flink job after you began the applying with a StartApplication command or restarted with UpdateApplication.
In a wholesome software, the variety of full restarts ought to ideally be zero. A single full restart could be acceptable throughout deployment or deliberate upkeep; a number of restarts usually point out some concern. We advocate to not set off an alarm on a single restart, and even a few consecutive restarts.
The alarm ought to solely be triggered when the applying is caught in a fail-and-restart loop. This means checking whether or not a number of restarts have occurred over a comparatively brief time frame. Deciding the interval will not be trivial, as a result of the time the Flink job takes to restart from a checkpoint depends upon the scale of the applying state. Nonetheless, if the state of your software is decrease than a number of GB per KPU, you may safely assume the applying ought to begin in lower than a minute.
The purpose is making a CloudWatch alarm that triggers when fullRestarts retains rising over a time interval enough for a number of restarts. For instance, assuming your software restarts in lower than 1 minute, you may create a CloudWatch alarm that depends on the DIFF math expression of the fullRestarts metric. The next screenshot exhibits an instance of the alarm particulars.

This instance is a conservative alarm, solely triggering if the applying retains restarting for over 5 minutes. This implies you detect the issue after at the least 5 minutes. You may think about decreasing the time to detect the failure earlier. Nonetheless, watch out to not set off an alarm after only one or two restarts. Occasional restarts may occur, for instance throughout regular upkeep (patching) that’s managed by the service, or for a transient error of an exterior system. Flink is designed to recuperate from these situations with minimal downtime and no knowledge loss.
Detecting whether or not the job is up and operating: Monitoring software, job, and process standing
We’ve mentioned how you have got totally different statuses: the standing of the applying, job, and subtask. In Managed Service for Apache Flink, the applying and job standing change to RUNNING when the subtasks are efficiently deployed on the cluster. Nonetheless, the job will not be actually operating and processing knowledge till all of the subtasks are RUNNING.
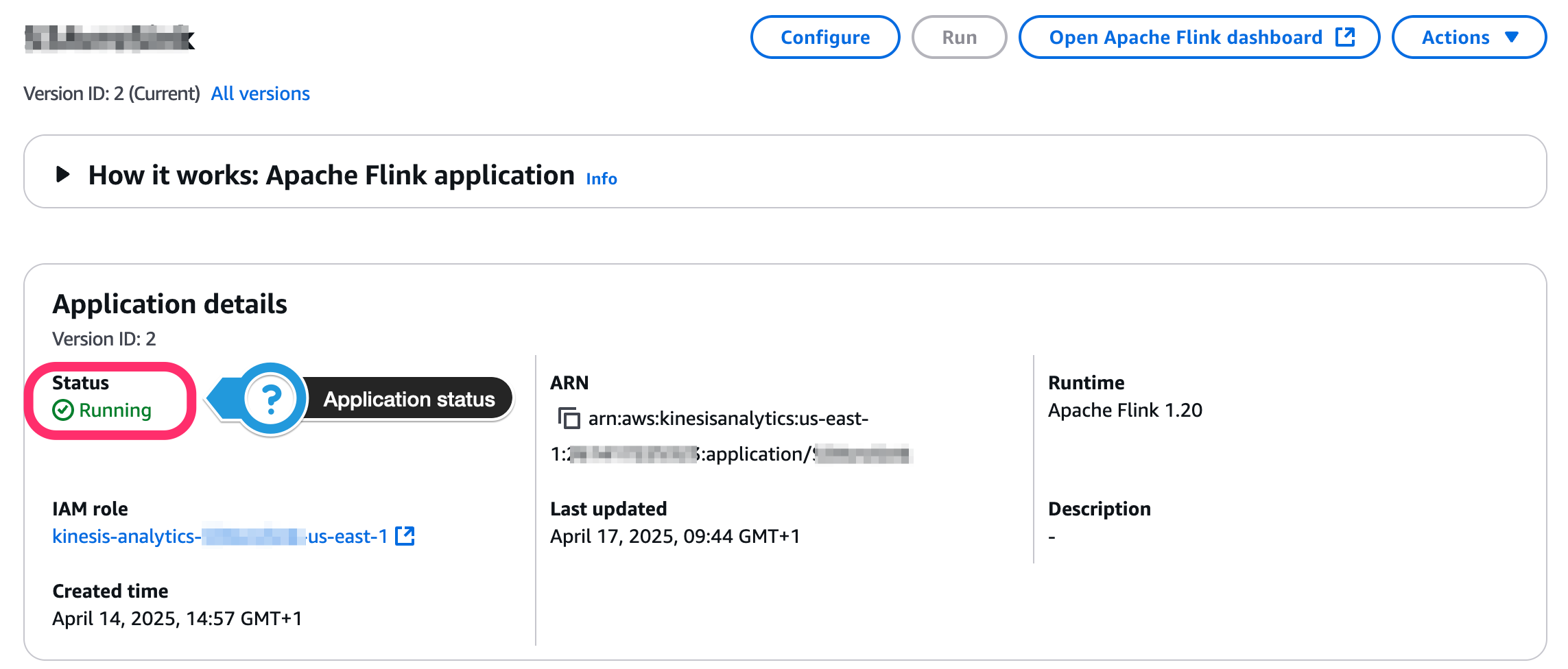
Observing the applying standing throughout operations
The appliance standing is seen on the console, as proven within the following screenshot.
In your automation, you may ballot the DescribeApplication API motion to watch the applying standing. The next command exhibits how you can use the AWS Command Line Interface (AWS CLI) and jq command to extract the standing string of an software:
Observing job and subtask standing
Managed Service for Apache Flink offers you entry to the Flink Dashboard, which supplies helpful info for troubleshooting, together with the standing of all subtasks. The next screenshot, for instance, exhibits a wholesome job the place all subtasks are RUNNING.
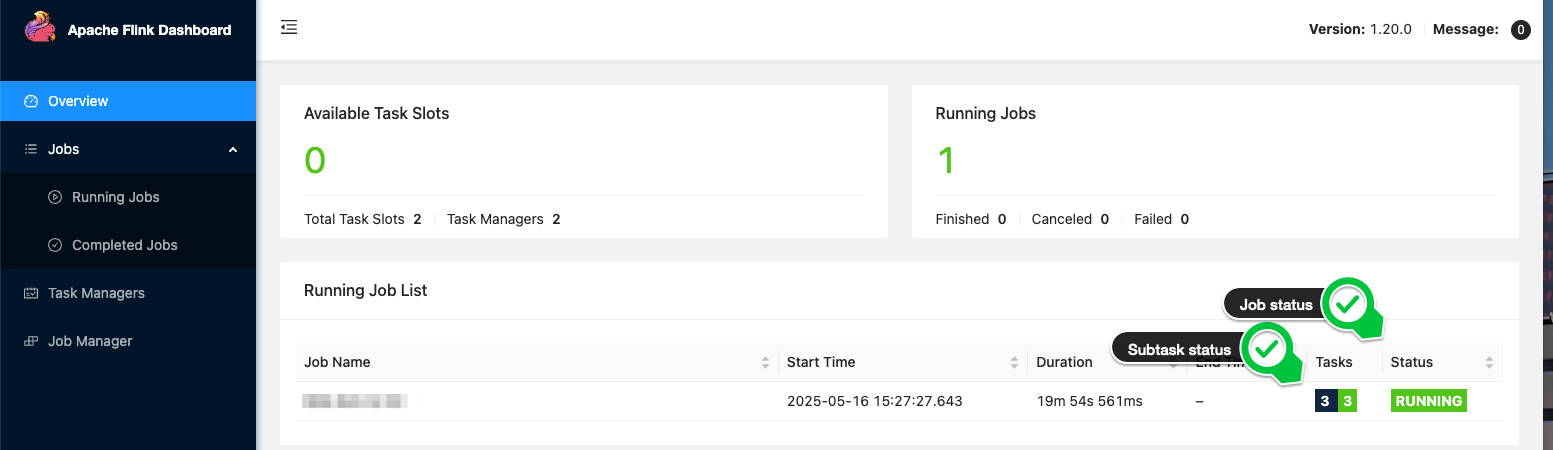
Within the following screenshot, we are able to see a job the place subtasks are failing and restarting.

In your automation, whenever you begin the applying or deploy a change, you wish to ensure the job is finally up and operating and processing knowledge. This occurs when all of the subtasks are RUNNING. Be aware that ready for the job standing to turn out to be RUNNING after an operation will not be fully secure. A subtask may nonetheless fail and trigger the job to restart after it was reported as RUNNING.
After you execute a lifecycle operation, your automation can ballot the substasks standing ready for one among two occasions:
- All subtasks report
RUNNING– This means the operation was profitable and your Flink job is up and operating. - Any subtask reviews
FAILINGorCANCELED– This means one thing went unsuitable, and the applying is probably going caught in a fail-and-restart loop. It’s essential intervene, for instance, force-stopping the applying after which rolling again the change.
If you’re restarting from a snapshot and the state of your software is sort of large, you may observe subtasks will report INITIALIZING standing for longer. In the course of the initialization, Flink restores the state of the operator earlier than altering to RUNNING.
The Flink REST API exposes the state of the subtasks, and can be utilized in your automation. In Managed Service for Apache Flink, this requires three steps:
- Generate a pre-signed URL to entry the Flink REST API utilizing the CreateApplicationPresignedUrl API motion.
- Make a GET request to the
/jobsendpoint of the Flink REST API to retrieve the job ID. - Make a GET request to the
/jobs/endpoint to retrieve the standing of the subtasks.
The next GitHub repository supplies a shell script to retrieve the standing of the duties of a given Managed Service for Apache Flink software.
Monitoring subtasks failure whereas the job is operating
The method of polling the Flink REST API can be utilized in your automation, instantly after an operation, to watch whether or not the operation was finally profitable.
We strongly advocate to not repeatedly ballot the Flink REST API whereas the job is operating to detect failures. This operation is useful resource consuming, and may degrade efficiency or trigger errors.
To watch for suspicious subtask standing modifications throughout regular operations, we advocate utilizing CloudWatch Logs as an alternative. The next CloudWatch Logs Insights question extracts all subtask state transitions:
How Managed Service for Apache Flink minimizes processing downtime
We’ve seen how Flink is designed for robust consistency. To ensure exactly-once state consistency, Flink briefly stops the processing to deploy any modifications, together with scaling. This downtime is required for Flink to take a constant copy of the applying state and put it aside in a savepoint. After the change is deployed, the job is restarted from the savepoint, and there’s no knowledge loss. In Managed Service for Apache Flink, updates are absolutely managed. When snapshots are enabled, UpdateApplication robotically stops the job and makes use of snapshots (primarily based on Flink’s savepoints) to retain the state.
Flink ensures no knowledge loss. Nonetheless, what you are promoting necessities or Service Stage Goals (SLOs) may also impose a most delay for the info obtained by downstream techniques, or end-to-end latency. This delay is affected by the processing downtime, or the time the job doesn’t course of knowledge to permit Flink deploying the change.With Flink, some processing downtime is unavoidable. Nonetheless, Managed Service for Apache Flink is designed to reduce the processing downtime whenever you deploy a change.
We’ve seen how the service runs your software in a devoted cluster, for full isolation. If you concern UpdateApplication on a RUNNING software, the service prepares a brand new cluster with the required quantity of assets. This operation may take a while. Nonetheless, this doesn’t have an effect on the processing downtime, as a result of the service retains the job operating and processing knowledge on the unique cluster till the final potential second, when the brand new cluster is prepared. At this level, the service stops your job with a savepoint and restarts it on the brand new cluster.
Throughout this operation, you’re solely charged for the variety of KPU of a single cluster.
The next diagram illustrates the distinction between the period of the replace operation, or the time the applying standing is UPDATING, and the processing downtime, observable from the job standing, seen within the Flink Dashboard.
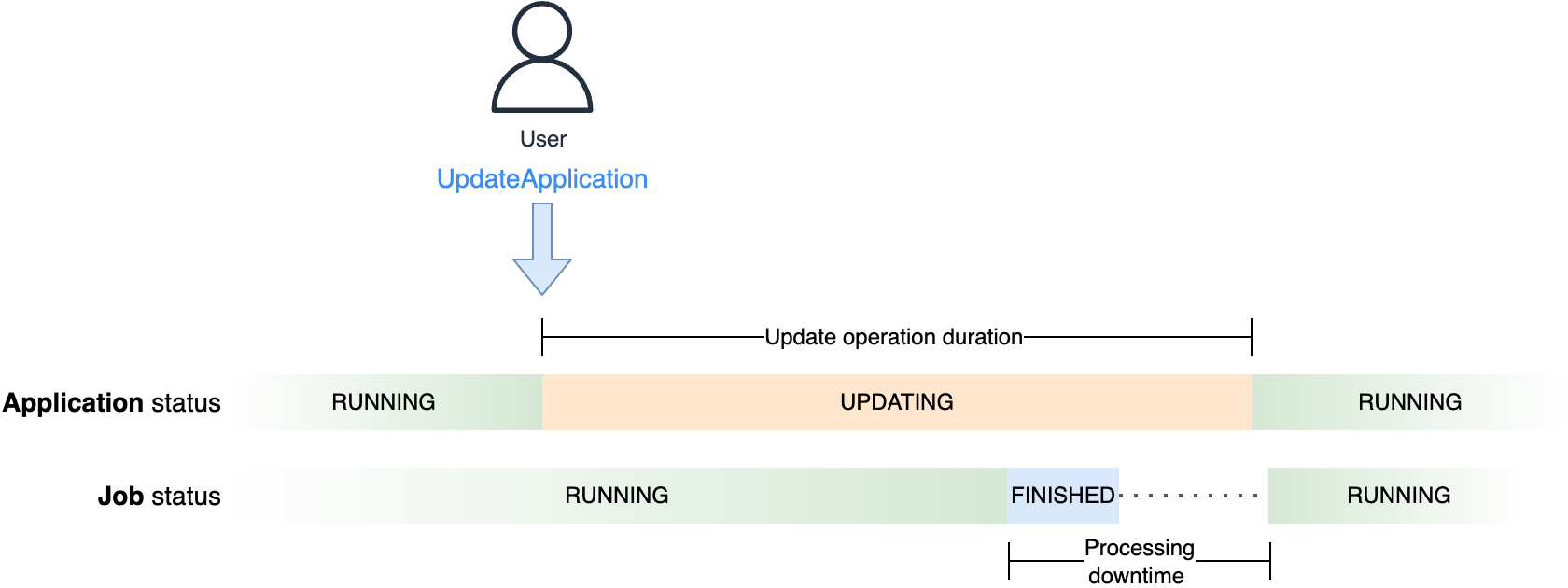
You may observe this course of, preserving each the applying console and Flink Dashboard open, whenever you replace the configuration of a operating software, even with no modifications. The Flink Dashboard will turn out to be briefly unavailable when the service switches to the brand new cluster. Moreover, you may’t use the script we offered to verify the job standing for this scope. Regardless that the cluster retains serving the Flink Dashboard till it’s tore down, the CreateApplicationPresignedUrl motion doesn’t work whereas the applying is UPDATING.
The processing time (the time the job will not be operating on both clusters) depends upon the time the job takes to cease with a savepoint (snapshot) and restore the state within the new cluster. This time largely depends upon the scale of the applying state. Knowledge skew may also have an effect on the savepoint time because of the barrier alignment mechanism. For a deep dive into the Flink’s barrier alignment mechanism, consult with Optimize checkpointing in your Amazon Managed Service for Apache Flink functions with buffer debloating and unaligned checkpoints, preserving in thoughts that savepoints are at all times aligned.
For the scope of your automation, you usually wish to wait till the job is again up and operating and processing knowledge. You usually wish to set a timeout. If each the applying and job don’t return to RUNNING inside this timeout, one thing in all probability went unsuitable and also you may wish to elevate an alarm or power a rollback. This timeout ought to think about your entire replace operation period.
Conclusion
On this publish, we mentioned potential failure situations whenever you deploy a change or scale your software. We confirmed how Managed Service for Apache Flink rollback functionalities can seamlessly convey you again to a secure place after a change went unsuitable. We additionally explored how one can automate monitoring operations to watch software, job, and subtask standing, and how you can use the fullRestarts metric to detect when the job is in a fail-and-restart loop.
For extra info, see Run a Managed Service for Apache Flink software, Implement fault tolerance in Managed Service for Apache Flink, and Handle software backups utilizing Snapshots.
In regards to the authors

{kind=link}