
HBase clusters on Amazon Easy Storage Service (Amazon S3) want common upgrades for brand spanking new options, safety patches, and efficiency enhancements. On this publish, we introduce the EMR read-replica prewarm function in Amazon EMR and present you find out how to use it to attenuate HBase improve downtime from hours to minutes utilizing blue-green deployments. This method works effectively for single-cluster deployments the place minimizing service interruption throughout infrastructure adjustments is essential.
Understanding HBase operational challenges
HBase cluster upgrades have required full cluster shutdowns, leading to prolonged downtime whereas areas initialize and RegionServers come on-line. Model upgrades require a whole cluster switchover, with time-consuming steps that embody loading and verifying area metadata, performing HFile checks, and confirming correct area task throughout RegionServers. Throughout this crucial interval—which might lengthen to hours relying on cluster dimension and information quantity—your purposes are utterly unavailable.
The problem doesn’t cease at model upgrades. You need to usually apply safety patches and kernel updates to take care of compliance. For Amazon EMR 7.0 and later clusters operating on Amazon Linux 2023, situations don’t routinely set up safety updates after launch; they continue to be on the patch stage from cluster creation time. AWS recommends periodically recreating clusters with newer AMIs, requiring the identical laborious cutover and downtime dangers as a full model improve. Equally, when that you must use completely different occasion sorts, conventional approaches imply taking your cluster offline.
Answer overview
Amazon EMR 7.12 introduces read-replica prewarm, a brand new function that tackles these challenges. This function helps you to make infrastructure adjustments to Apache HBase on Amazon S3 at scale whereas decreasing downtime threat and sustaining information consistency.
With read-replica prewarm, you may put together and validate your adjustments in a read-replica cluster earlier than selling it to lively standing, slicing service interruption from hours to minutes. You’ll learn to put together your read-replica cluster with the goal model, execute cutover procedures that reduce downtime, and confirm profitable migration earlier than finishing the switchover.
Learn-replica prewarm structure
The next diagram exhibits the structure and workflow. Each major and read-replica clusters work together with the identical Amazon S3 storage, accessing the identical S3 bucket and root listing.
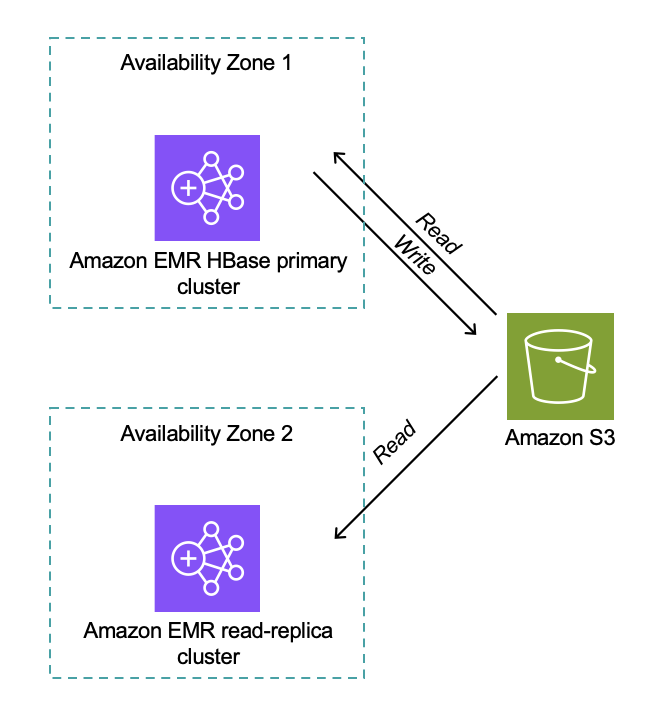
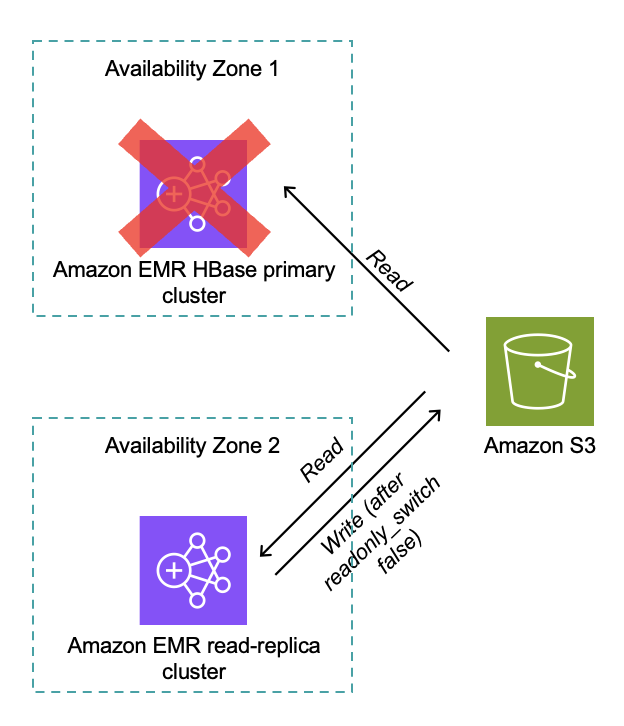
Distributed locking confirms just one HBase cluster can write at a time (for clusters model 7.12.0 and later). The read-replica cluster performs full HBase area initialization with out time stress, and after promotion, the learn duplicate turns into the lively author as proven within the following diagram.
Implementation steps HBase cluster improve
Now that you just perceive how read-replica prewarm works and the structure behind it, let’s put this information into follow. You’ll comply with a course of that consists of three fundamental phases: preparation, cutover, and verification. Every section contains particular steps, proven within the following determine, that you’ll execute in sequence to finish the migration.
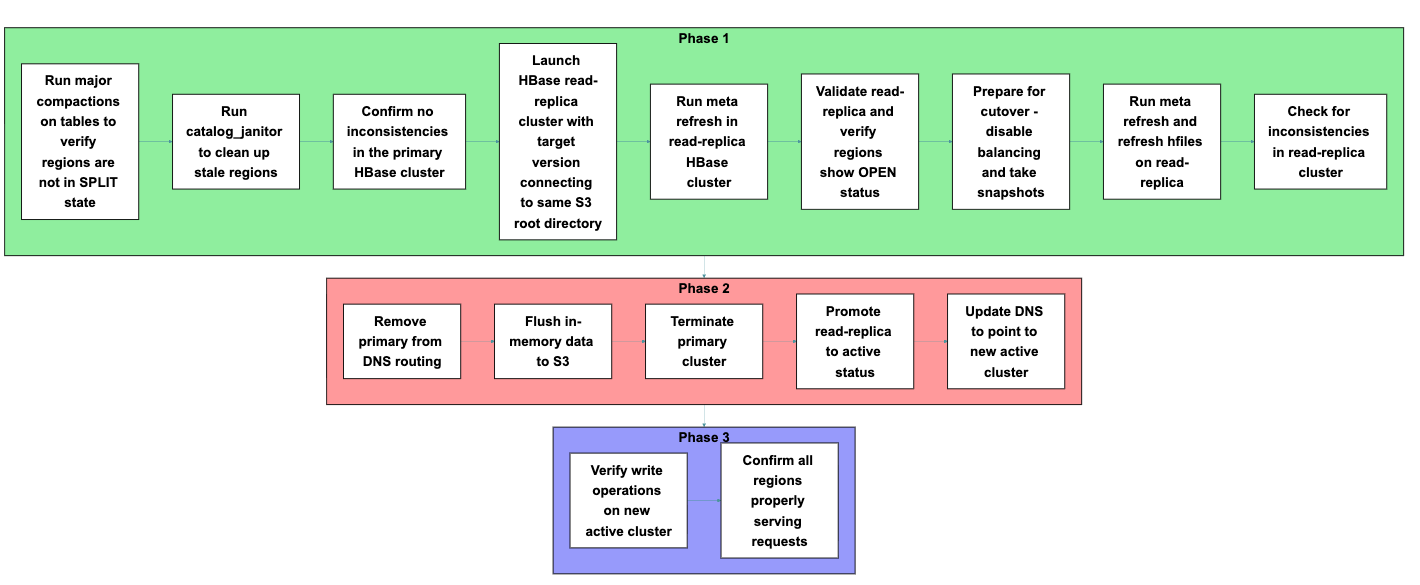
Part 1: Preparation
Earlier than beginning the migration, put together each your major cluster and launch a brand new read-replica cluster. Every step on this section builds towards confirming that your new cluster can correctly entry and serve your present information.
- Run main compactions on tables to confirm areas aren’t in SPLIT state
Run main compactions to consolidate information information and confirm areas aren’t in SPLIT state. Break up areas could cause task conflicts throughout migration, so resolving them initially helps preserve cluster stability all through the transition. - Run
catalog_janitorto scrub up stale areas
Execute thecatalog_janitorcourse of (HBase’s built-in upkeep device) to take away stale area references from the metadata. Cleansing up these references prevents confusion throughout area task within the read-replica cluster. - Verify no inconsistencies within the major HBase cluster
Confirm cluster integrity earlier than migration:Working the HBase Consistency Test device model 2 (HBCK2) performs a diagnostic scan that identifies and reviews issues in metadata, areas, and desk states, confirming your cluster is prepared for migration.
- Launch HBase read-replica cluster with the goal model connecting to the identical HBase root listing in Amazon S3 as the first cluster
Launch a brand new HBase cluster with the goal model and configure it to hook up with the identical S3 root listing as the first cluster. Verify that read-only mode is enabled by default as proven within the following screenshot.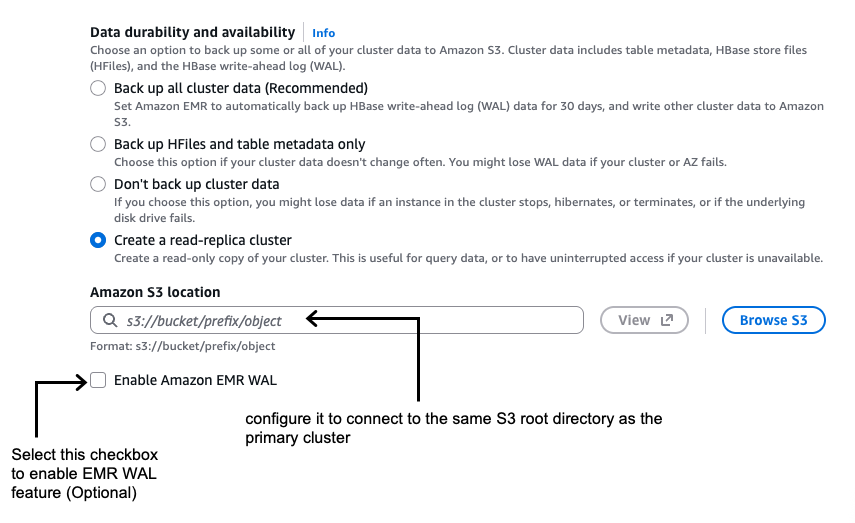
In case you are utilizing AWS Command Line Interface (AWS CLI), you may allow the learn duplicate whereas launching the Amazon EMR HBase on the Amazon S3 cluster by setting the
hbase.emr.readreplica.enabled.v2parameter totruewithin the HBase classification as proven within the following instance: - Run meta refresh on this read-replica HBase cluster
You’re making a parallel setting with the brand new model that may entry present information with out modification threat, permitting validation earlier than committing to the improve.
- Validate the read-replica and confirm that areas present OPEN standing and are correctly assigned:
Execute pattern learn operations towards your key tables to substantiate the learn duplicate can entry your information accurately. Within the HBase Grasp UI, confirm that areas presentOPENstanding and are correctly assigned to RegionServers. You also needs to verify that the whole information dimension matches your earlier cluster to confirm full information visibility. - Put together for cutover on major cluster
Disable balancing and compactions on the first cluster:Stopping background operations from altering information format or triggering area actions maintains a constant state through the migration window.
Take snapshots of your tables for rollback functionality:
These snapshots allow point-in-time restoration if you happen to uncover points after migration.
- Run meta refresh and refresh hfiles on the learn duplicate:
Refreshing confirms the learn duplicate has essentially the most present area assignments, desk construction, and HFile references earlier than taking up manufacturing site visitors.
- Test for inconsistencies within the read-replica cluster
Run the HBCK2 device on the read-replica cluster to establish potential points:When a learn duplicate is created, each the first and duplicate clusters present metadata inconsistencies referencing one another’s meta folders: “There’s a gap within the area chain”. The first cluster complains about meta_
, whereas the learn duplicate complains in regards to the major’s meta folder. This inconsistency doesn’t impression cluster operations however exhibits up in hbck reviews. For a clear hbck report after switching to the learn duplicate and terminating the first cluster, manually delete the outdated major’s meta folder from Amazon S3 after taking a backup of it. Moreover, examine the HBase Grasp UI to visually verify cluster well being. Verifying the read-replica cluster has a clear, constant state earlier than promotion prevents potential information entry points after cutover.
Part 2: Cutover
Carry out the precise migration by shutting down the first cluster and selling the learn duplicate. The steps on this section reduce the window when your cluster is unavailable to purposes.
- Take away the first cluster from DNS routing
Replace DNS entries to direct site visitors away from the first cluster, stopping new requests from reaching it throughout shutdown. - Flush in-memory information to Amazon S3
Flush in-memory information to substantiate sturdiness in Amazon S3:Flushing forces information nonetheless in reminiscence (in MemStores, HBase’s write cache) to be written to persistent storage (Amazon S3), stopping information loss through the transition between clusters.
- Terminate the first cluster
Terminate the first cluster after confirming the information is endured to Amazon S3. This step releases sources and eliminates the potential of split-brain eventualities the place each clusters may settle for writes to the identical dataset. - Promote the learn duplicate to lively standing
Convert the learn duplicate to read-write mode:The promotion course of routinely refreshes meta and HFiles, capturing ultimate adjustments from the flush operations and confirming full information visibility.
Once you promote the cluster, it transitions from read-only to read-write mode, permitting it to simply accept software write operations and absolutely change the outdated cluster’s performance.
- Replace DNS to level to the brand new lively cluster
Replace DNS entries to direct site visitors to the brand new lively cluster. Routing consumer site visitors to the brand new cluster restores service availability and completes the migration from the applying perspective.
Part 3: Validation
Along with your new cluster now lively, you’re able to confirm that every part is working accurately earlier than declaring the migration full.
Execute check write operations to substantiate the cluster accepts writes correctly. Test the HBase Grasp UI to confirm areas are serving each learn and write requests with out errors. At this level, your migration to the brand new Amazon EMR launch is full, and your purposes can connect with the brand new cluster and resume regular read-write operations.
Key advantages
The read-replica prewarm method delivers a number of essential benefits over conventional HBase improve strategies. Most notably, you may cut back service interruption from hours to minutes by getting ready your new cluster in parallel along with your operating manufacturing setting.
Earlier than committing to the improve, you may totally check that information is readable and accessible within the new model. The system hundreds and assigns areas earlier than activation, eliminating the prolonged startup time that historically causes prolonged downtime. This pre-warming course of means your new cluster is able to serve site visitors instantly upon promotion.
You additionally acquire the power to validate a number of points of your deployment earlier than cutover, together with information integrity, learn efficiency, cluster stability, and configuration correctness. This validation occurs whereas your manufacturing cluster continues serving site visitors, decreasing the danger of discovering points throughout your upkeep window.
For testing and validation workflows, you may run parallel testing setting by creating a number of HBase learn replicas. Nevertheless, you need to confirm that just one HBase cluster stays in read-write mode to the Amazon S3 information retailer to stop information corruption and consistency points.
Rollback procedures
All the time totally check your HBase rollback procedures earlier than implementing upgrades in manufacturing environments.
When rolling again HBase clusters in Amazon EMR, you could have two major choices.
- Possibility 1 entails launching a brand new cluster with the earlier HBase model that factors to the identical Amazon S3 information location because the upgraded cluster. This method is simple to implement, preserves information written earlier than and after the improve try, and provides sooner restoration with no extra storage necessities. Nevertheless, it dangers encountering information compatibility points if the improve modified information codecs or metadata constructions, probably resulting in surprising conduct.
- Possibility 2 takes a extra cautious method by launching a brand new cluster with the earlier HBase model and restoring from snapshots taken earlier than the improve. This methodology ensures a return to a identified, constant state, eliminates model compatibility dangers, and offers full isolation from corruption launched through the improve course of. The tradeoff is that information written after the snapshot was taken will likely be misplaced, and the restoration course of requires extra time and planning.
For manufacturing environments the place information integrity is paramount, the snapshot-based method (choice 2) is mostly most well-liked regardless of the potential for some information loss.
Issues
- Retailer file monitoring migration: Migrating from Amazon EMR 7.3 (or earlier) requires disabling and dropping the
hbase:storefiledesk on the first cluster, then flushing metadata. When launching the brand new read-replica cluster, configure theDefaultStoreFileTrackerimplementation utilizing thehbase.retailer.file-tracker.implproperty. When operational, runchange_sftinstructions to change tables toFILEmonitoring methodology, offering seamless information file entry throughout migration. - Multi-AZ deployments: Take into account community latency and Amazon S3 entry patterns when deploying learn replicas throughout Availability Zones. Cross-AZ information switch may impression learn latency for the read-replica cluster.
- Value impression: Working parallel clusters throughout migration incurs extra infrastructure prices till the first cluster is terminated.
- Disabled tables: The disabled state of tables within the major cluster is a cluster-specific administrative property that isn’t propagated to the read-replica cluster. If you’d like them disabled within the learn duplicate, you need to explicitly disable them.
- Amazon EMR 5.x cluster improve: Direct improve from Amazon EMR 5.x to Amazon EMR 7.x utilizing this function isn’t supported due to the main HBase model change from 1.x to 2.x. For upgrading from Amazon EMR 5.x to Amazon EMR 7.x, comply with the steps in our greatest practices: AWS EMR Finest Practices – HBase Migration
Conclusion
On this publish, we confirmed you ways the read-replica prewarm function of Amazon EMR 7.12 improves HBase cluster operations by minimizing the laborious cutover constraints that make infrastructure adjustments difficult. This function offers you a constant blue-green deployment sample that reduces threat and downtime for model upgrades and safety patches.
When you may totally validate adjustments earlier than committing to them and cut back service interruption from hours to minutes, you may preserve HBase infrastructure extra confidently and effectively. Now you can take a extra proactive method to cluster upkeep, safety compliance, and efficiency optimization with better confidence in your operational processes.
To be taught extra about Amazon EMR and HBase on Amazon S3, go to the Amazon EMR documentation. To get began with learn replicas, see the HBase on Amazon S3 information .
Concerning the authors

{kind=link}