
Ever felt misplaced in messy folders, so many scripts, and unorganized code? That chaos solely slows you down and hardens the information science journey. Organized workflows and undertaking buildings are usually not simply nice-to-have, as a result of it impacts the reproducibility, collaboration and understanding of what’s taking place within the undertaking. On this weblog, we’ll discover the very best practices plus take a look at a pattern undertaking to information your forthcoming initiatives. With none additional ado let’s look into among the essential frameworks, frequent practices, how to enhance them.
Standard Knowledge Science Workflow Frameworks for Undertaking Construction
Knowledge science frameworks present a structured solution to outline and preserve a transparent information science undertaking construction, guiding groups from downside definition to deployment whereas bettering reproducibility and collaboration.
CRISP-DM
CRISP-DM is the acronym for Cross-Business Course of for Knowledge Mining. It follows a cyclic iterative construction together with:
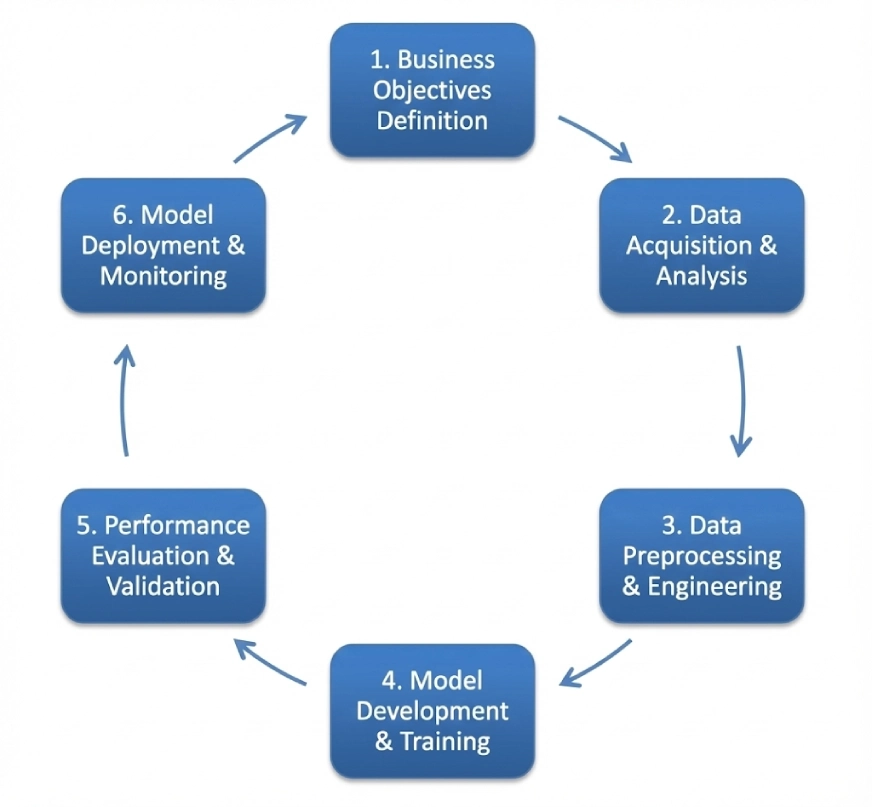
- Enterprise Understanding
- Knowledge Understanding
- Knowledge Preparation
- Modeling
- Analysis
- Deployment
This framework can be utilized as a typical throughout a number of domains, although the order of steps of it may be versatile and you may transfer again in addition to against the unidirectional circulation. We’ll take a look at a undertaking utilizing this framework afterward on this weblog.
OSEMN
One other standard framework on the earth of information science. The concept right here is to interrupt the advanced issues into 5 steps and clear up them step-by-step, the 5 steps of OSEMN (pronounced as Superior) are:
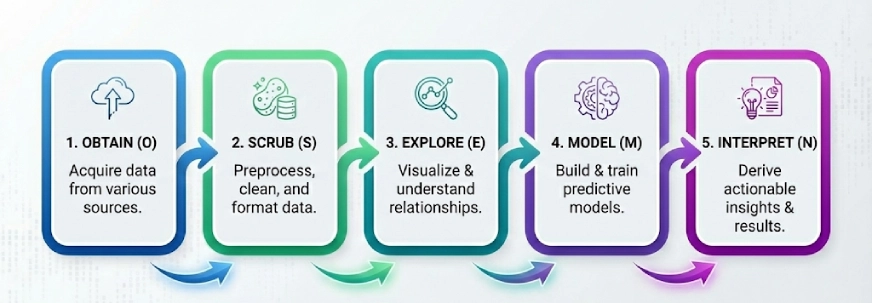
- Acquire
- Scrub
- Discover
- Mannequin
- Interpret
Observe: The ‘N’ in “OSEMN” is the N in iNterpret.
We observe these 5 logical steps to “Acquire” the information, “Scrub” or preprocess the information, then “Discover” the information through the use of visualizations and understanding the relationships between the information, after which we “Mannequin” the information to make use of the inputs to foretell the outputs. Lastly, we “Interpret” the outcomes and discover actionable insights.
KDD
KDD or Information Discovery in Databases consists of a number of processes that goal to show uncooked information into data discovery. Listed here are the steps on this framework:

- Choice
- Pre-Processing
- Transformation
- Knowledge Mining
- Interpretation/Analysis
It’s value mentioning that individuals check with KDD as Knowledge Mining, however Knowledge Mining is the precise step the place algorithms are used to search out patterns. Whereas, KDD covers the complete lifecycle from the beginning to finish.
SEMMA
This framework emphasises extra on the mannequin growth. The SEMMA comes from the logical steps within the framework that are:
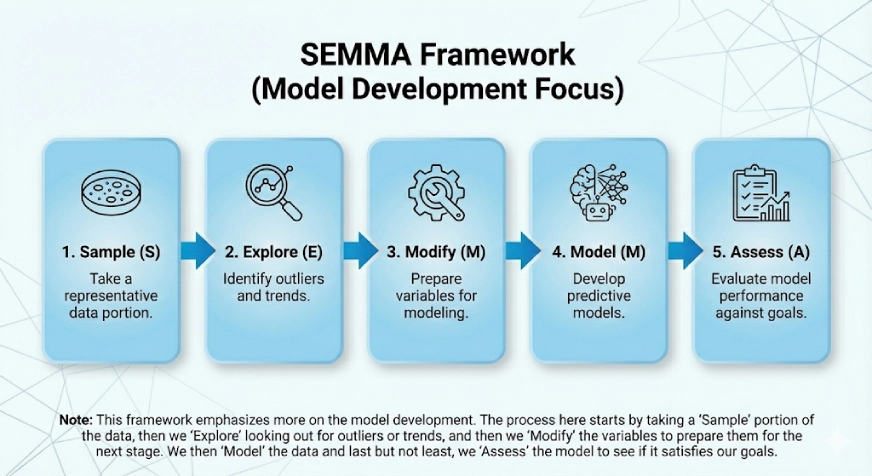
- Pattern
- Discover
- Modify
- Mannequin
- Assess
The method right here begins by taking a “Pattern” portion of the information, then we “Discover” looking for outliers or traits, after which we “Modify” the variables to organize them for the subsequent stage. We then “Mannequin” the information and final however not least, we “Assess” the mannequin to see if it satisfies our objectives.
Frequent Practices that Have to be Improved
Bettering these practices is important for sustaining a clear and scalable information science undertaking construction, particularly as initiatives develop in measurement and complexity.
1. The issue with “Paths”
Folks usually hardcode absolute paths like pd.read_csv(“C:/Customers/Title/Downloads/information.csv”). That is fantastic whereas testing issues out on Jupyter Pocket book however when used within the precise undertaking it breaks the code for everybody else.
The Repair: At all times use relative paths with the assistance of libraries like “os” or “pathlib”. Alternatively, you possibly can select so as to add the paths in a config file (for example: DATA_DIR=/house/ubuntu/path).
2. The Cluttered Jupyter Pocket book
Typically folks use a single Jupyter Pocket book with 100+ cells containing imports, EDA, cleansing, modeling, and visualization. This is able to make it inconceivable to check or model management.
The Repair: Use Jupyter Notebooks just for Exploration and stick with Python Scripts for Automation. As soon as a cleansing operate works, add it to a src/processing.py file after which you possibly can import it into the pocket book. This provides modularity and re-usability and in addition makes testing and understanding the pocket book quite a bit less complicated.
3. Model the Code not the Knowledge
Git can wrestle in dealing with giant CSV recordsdata. Folks on the market usually push information to GitHub which might take quite a lot of time and in addition trigger different problems.
The Repair: Point out and use Knowledge Model Management (DVC briefly). It’s like Git however for information.
4. Not offering a README for the undertaking
A repository can include nice code however with out directions on how one can set up dependencies or run the scripts may be chaotic.
The Repair: Be sure that you all the time craft a superb README.md that has data on arrange the setting, The place and how one can get the information, How to run the mannequin and different essential scripts.
Constructing a Buyer Churn Prediction System [Sample Project]
Now utilizing the CRISP-DM framework I’ve created a pattern undertaking known as “Buyer Churn Prediction System”, let’s perceive the complete course of and the steps by taking a greater take a look at the identical.
Right here’s the GitHub hyperlink of the repository.
Observe: It is a pattern undertaking and is crafted to know how one can implement the framework and observe a typical process.
Making use of CRISP-DM Step by Step
- Enterprise Understanding: Right here we should outline what we’re truly making an attempt to resolve. In our case it’s recognizing clients who’re prone to churn. We set clear targets for the system, 85%+ accuracy and 80%+ recall, and the enterprise objective right here is to retain the purchasers.
- Knowledge Understanding In our case the Telco Buyer Churn dataset. We’ve to look into the descriptive statistics, verify the information high quality, search for lacking values (additionally take into consideration how we will deal with them), additionally we’ve got to see how the goal variable is distributed, additionally lastly we have to discover the correlations between the variables to see what options matter.
- Knowledge Preparation: This step can take time however must be executed rigorously. Right here we cleanse the messy information, cope with the lacking values and outliers, create new options if required, encode the specific variables, cut up the dataset into coaching (70%), validation (15%), and take a look at (15%), and at last normalizing the options for our fashions.
- Modeling: In this important step, we begin with a easy mannequin or baseline (logistic regression in our case), then experiment with different fashions like Random Forest, XGBoost to realize our enterprise objectives. We then tune the hyperparameters.
- Analysis: Right here we determine which mannequin is working the very best for us and is assembly our enterprise objectives. In our case we have to take a look at the precision, recall, F1-scores, ROC-AUC curves and the confusion matrix. This step helps us decide the ultimate mannequin for our objective.
- Deployment: That is the place we truly begin utilizing the mannequin. Right here we will use FastAPI or another alternate options, containerize it with Docker for scalability, and set-up monitoring for observe functions.
Clearly utilizing a step-by-step course of helps present a transparent path to the undertaking, additionally throughout the undertaking growth you can also make use of progress trackers and GitHub’s model controls can absolutely assist. Knowledge Preparation wants intricate care because it gained’t want many revisions if rightly executed, if any subject arises after deployment it may be fastened by going again to the modeling section.
Conclusion
As talked about within the begin of the weblog, organized workflows and undertaking buildings are usually not simply nice-to-have, they’re a should. With CRISP-DM, OSEMN, KDD, or SEMMA, a step-by-step course of retains initiatives clear and reproducible. Additionally don’t overlook to make use of relative paths, preserve Jupyter Notebooks for Exploration, and all the time craft a superb README.md. At all times keep in mind that growth is an iterative course of and having a transparent structured framework to your initiatives will ease your journey.
Often Requested Questions
A. Reproducibility in information science means having the ability to receive the identical outcomes utilizing the identical dataset, code, and configuration settings. A reproducible undertaking ensures that experiments may be verified, debugged, and improved over time. It additionally makes collaboration simpler, as different workforce members can run the undertaking with out inconsistencies brought on by setting or information variations.
A. Mannequin drift happens when a machine studying mannequin’s efficiency degrades as a result of real-world information modifications over time. This could occur as a consequence of modifications in person conduct, market situations, or information distributions. Monitoring for mannequin drift is important in manufacturing methods to make sure fashions stay correct, dependable, and aligned with enterprise targets.
A. A digital setting isolates undertaking dependencies and prevents conflicts between completely different library variations. Since information science initiatives usually depend on particular variations of Python packages, utilizing digital environments ensures constant outcomes throughout machines and over time. That is important for reproducibility, deployment, and collaboration in real-world information science workflows.
A. A knowledge pipeline is a sequence of automated steps that transfer information from uncooked sources to a model-ready format. It sometimes contains information ingestion, cleansing, transformation, and storage.
Captivated with expertise and innovation, a graduate of Vellore Institute of Know-how. At the moment working as a Knowledge Science Trainee, specializing in Knowledge Science. Deeply concerned about Deep Studying and Generative AI, desirous to discover cutting-edge strategies to resolve advanced issues and create impactful options.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}