
Databricks Agent Bricks is a platform for constructing, evaluating, and deploying production-grade AI brokers for enterprise workflows. Our purpose is to assist prospects obtain the optimum high quality–value stability on the Pareto frontier for his or her domain-specific duties, and to constantly enhance their brokers that motive on their very own knowledge. To assist this, we develop enterprise-centric benchmarks and run empirical evaluations on brokers that measure accuracy and serving effectivity, reflecting actual tradeoffs enterprises face in manufacturing.
Inside our broader agent optimization toolkit, this put up focuses on automated immediate optimization, a method that leverages iterative, structured search guided by suggestions indicators from analysis to robotically enhance prompts. We exhibit how we are able to:
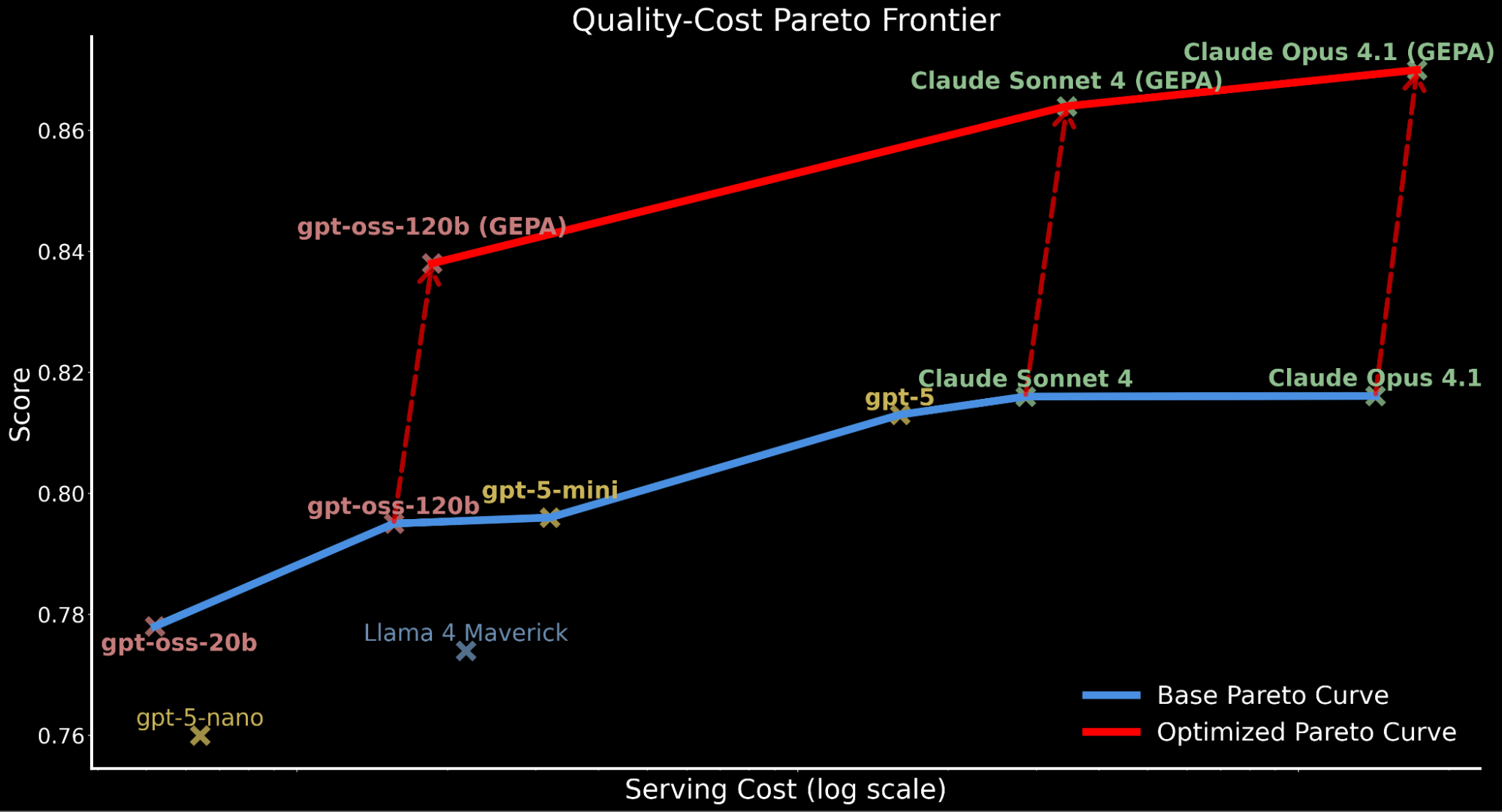
- Allow open-source fashions to surpass frontier-model high quality for enterprise duties: leveraging GEPA, a newly-released immediate optimization approach popping out of analysis from Databricks and UC Berkeley, we current how gpt-oss-120b surpasses state-of-the-art proprietary fashions Claude Sonnet 4 and Claude Opus 4.1 by ~3% whereas being roughly 20x and 90x cheaper to serve, respectively (see Pareto frontier plot beneath).
- Elevate proprietary frontier fashions even larger: we apply the identical method to main proprietary fashions, elevating Claude Opus 4.1 and Claude Sonnet 4 baseline efficiency by 6-7% and reaching new state-of-the-art efficiency.
- Supply a superior quality-cost tradeoff in comparison with SFT: automated immediate optimization delivers efficiency on par with, or higher than, supervised fine-tuning (SFT), whereas lowering serving prices by 20%. We additionally present that immediate optimization and SFT can work collectively to carry the efficiency additional.
Within the sections that observe, we’ll cowl
- how we consider AI agent efficiency on info extraction as a core use case and why it issues for enterprise workflows;
- an outline of how immediate optimization works, the varieties of advantages it could unlock, particularly in situations the place finetuning just isn’t sensible, and efficiency positive factors on our analysis pipeline;
- to place these positive factors in context, we are going to measure the affect of immediate optimization, and analyze the economics behind these methods;
- efficiency comparability with supervised finetuning (SFT), highlighting the superior quality-cost tradeoff by immediate optimization;
- takeaways and subsequent steps, significantly how one can get began making use of these methods instantly with Databricks Agent Bricks to construct the best-in-class AI brokers optimized for real-world enterprise deployment.
Analysis of the most recent LLMs on IE Bench
Info Extraction (IE) is a core Agent Bricks characteristic, changing unstructured sources reminiscent of PDFs or scanned paperwork into structured data. Regardless of fast progress in generative AI capabilities, IE stays tough at enterprise scale:
- Paperwork are prolonged and stuffed with domain-specific jargon
- Schemas are complicated, hierarchical, and include ambiguities
- Labels are sometimes noisy and inconsistent
- Operational tolerance for error in extraction is low
- Requirement of excessive reliability and price effectivity for giant inference workloads
Consequently, we observe that efficiency can range extensively by area and job complexity, so constructing the suitable compound AI programs for IE throughout various use circumstances requires a radical analysis of various AI agent capabilities.
To discover this, we developed IE Bench, a complete analysis suite spanning a number of real-world enterprise domains like finance, authorized, commerce, and healthcare. The benchmark displays complicated real-world challenges, together with paperwork exceeding 100 pages, spanning extraction entities with over 70 fields, and hierarchical schemas with a number of nested ranges. We report evaluations on the benchmark’s held-out take a look at set to supply a dependable measure of real-world efficiency.
We benchmarked the most recent technology of open-source fashions served by way of the Databricks Basis Fashions API, together with the newly launched gpt-oss collection, in addition to main proprietary fashions from a number of suppliers, together with the most recent GPT-5 household.1
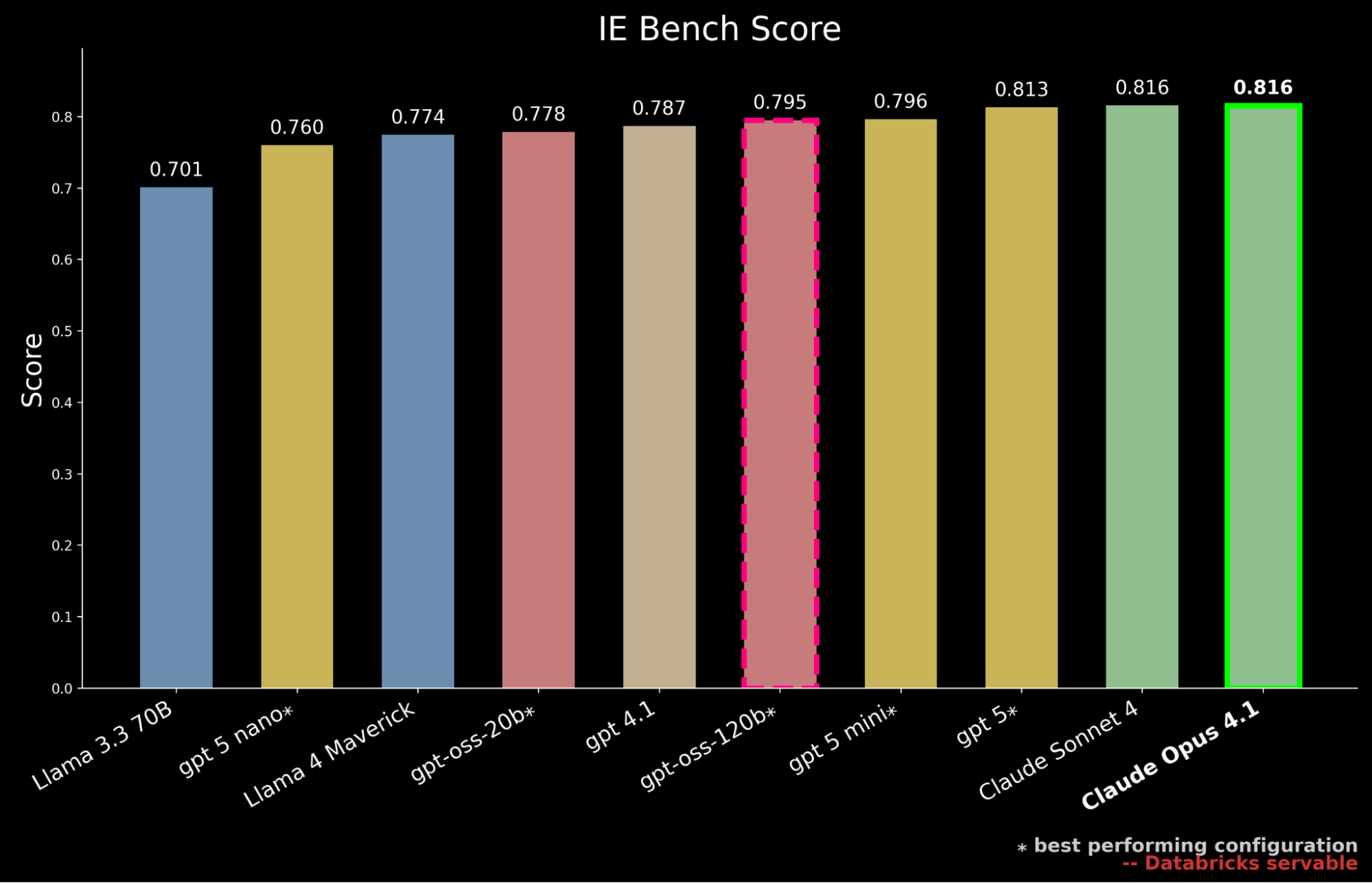
Our outcomes present that gpt-oss-120b is the very best performing open-source mannequin on IE Bench, surpassing beforehand open-source state-of-the-art efficiency from Llama 4 Maverick by ~3% whereas approaching the efficiency stage of gpt-5-mini, marking a significant step ahead for open-source fashions. Nonetheless, it nonetheless falls behind proprietary frontier mannequin efficiency, trailing gpt-5, Claude Sonnet 4, and Claude Opus 4.1—which achieves the very best rating on the benchmark.
But in enterprise settings, efficiency should even be weighed towards serving value. We additional contextualize our earlier findings by highlighting that gpt-oss-120b matches the efficiency of gpt-5-mini whereas solely incurring roughly 50% of the serving value. 2 Proprietary frontier fashions are largely dearer with gpt-5 at ~10x the serving value of gpt-oss-120b, Claude Sonnet 4 at ~20x and Claude Opus 4.1 at ~90x.
For instance the quality-cost tradeoff throughout fashions, we plot the Pareto frontier beneath, depicting the baseline efficiency for all fashions previous to any enhancements..
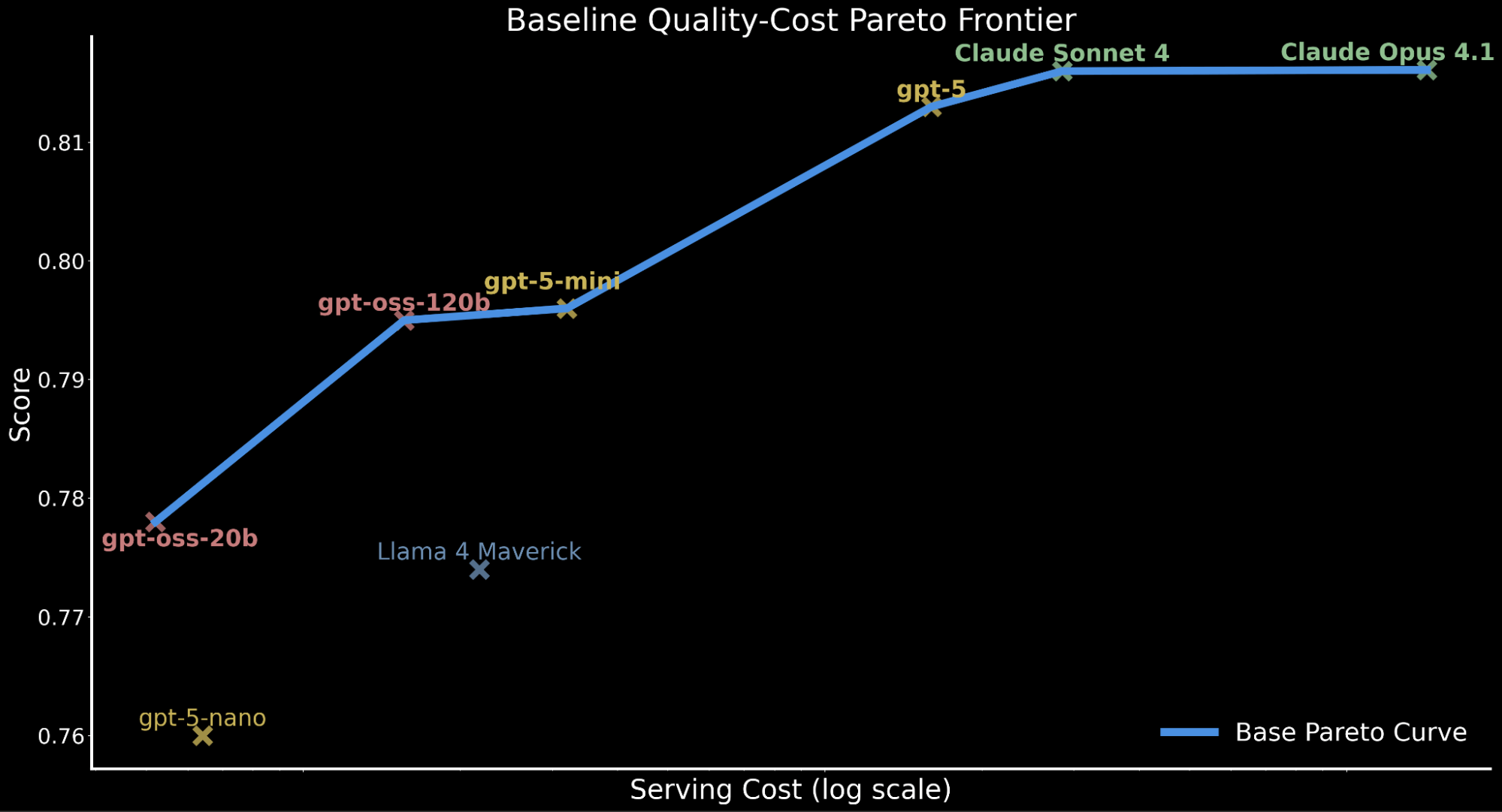
This quality-cost tradeoff has main implications for enterprise workloads requiring large-scale inference that should take into account compute price range and serving throughput whereas sustaining performant accuracy.
This motivates our exploration: Can we push gpt-oss-120b to frontier-level high quality whereas preserving its value effectivity? If that’s the case, this could ship main efficiency on the cost-quality Pareto frontier whereas being servable for enterprise adoption at Databricks.
Optimizing open-source fashions to outperform frontier mannequin efficiency
We discover automated immediate optimization as a scientific technique for elevating mannequin efficiency. Handbook immediate engineering can ship positive factors, but it surely usually depends upon area experience and trial-and-error experimentation. This complexity grows additional in compound AI programs integrating a number of LLM calls and exterior instruments that have to be optimized collectively, making guide immediate tuning impractical to scale or keep throughout manufacturing pipelines.
Immediate optimization affords a unique method, leveraging structured search guided by suggestions indicators to robotically enhance prompts. Such optimizers are pipeline-agnostic and are in a position to collectively optimize a number of interdependent prompts in multi-stage pipelines, making these methods sturdy and adaptable throughout compound AI programs and various duties.
To check this, we apply automated immediate optimization algorithms, particularly MIPROv2, SIMBA, and GEPA, a brand new immediate optimizer popping out of analysis from Databricks and UC Berkeley that mixes language-based reflection with evolutionary search to enhance AI programs. We apply these algorithms to judge how optimized prompting can shut the hole between the best-performing open-source mannequin, gpt-oss-120b, and state-of-the-art closed-source frontier fashions.
We take into account the next configurations of automated immediate optimizers in our exploration
Every immediate optimization approach depends on an optimizer mannequin to refine completely different points of the immediate for a goal scholar mannequin. Relying on the algorithm, the optimizer mannequin can generate few-shot examples from bootstrapped traces to use in-context studying and/or suggest and enhance the duty directions by way of search algorithms that carry out iterative reflection utilizing suggestions to mutate and choose higher prompts throughout optimization trials. These insights are distilled into improved prompts for the scholar mannequin to make use of throughout inference time at serving. Whereas the identical LLM can be utilized for each roles, we additionally experiment with utilizing a “stronger-performing mannequin” because the optimizer mannequin to discover if higher-quality steerage can additional enhance the scholar mannequin efficiency.
Constructing on our earlier findings of gpt-oss-120b because the main open-source mannequin on IE Bench, we take into account it our scholar mannequin baseline to discover additional enhancements.
When optimizing gpt-oss-120b, we take into account two configurations:
- gpt-oss-120b (optimizer) → gpt-oss-120b (scholar)
- Claude Sonnet 4 (optimizer) → gpt-oss-120b (scholar)
Since Claude Sonnet 4 achieves main efficiency on IE Bench over gpt-oss-120b, and is comparatively cheaper in comparison with Claude Opus 4.1 with related efficiency, we discover the speculation of whether or not making use of a stronger optimizer mannequin can produce higher efficiency for gpt-oss-120b.
We consider every configuration throughout the optimization methods and examine with the respective gpt-oss-120b baseline:
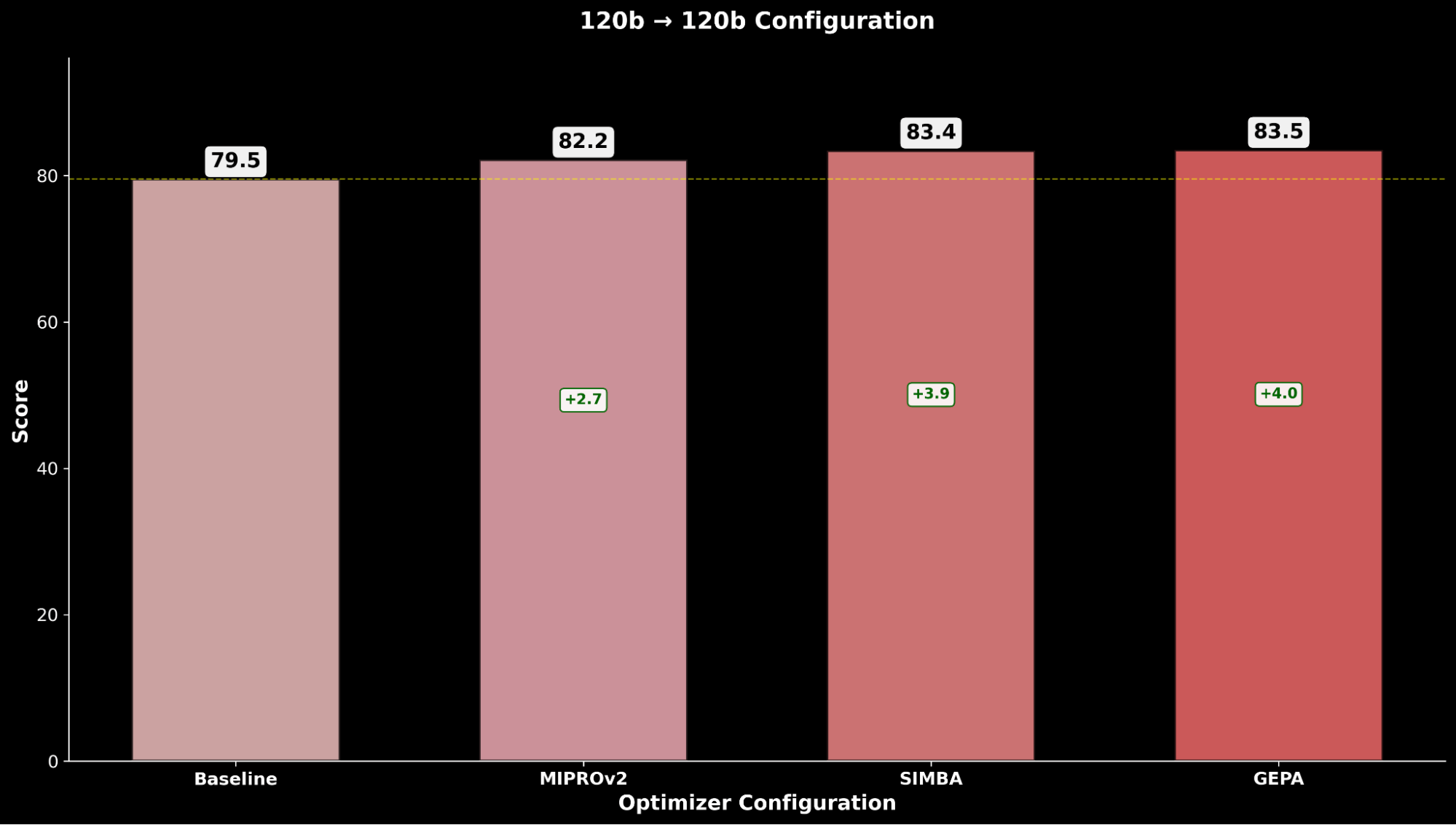
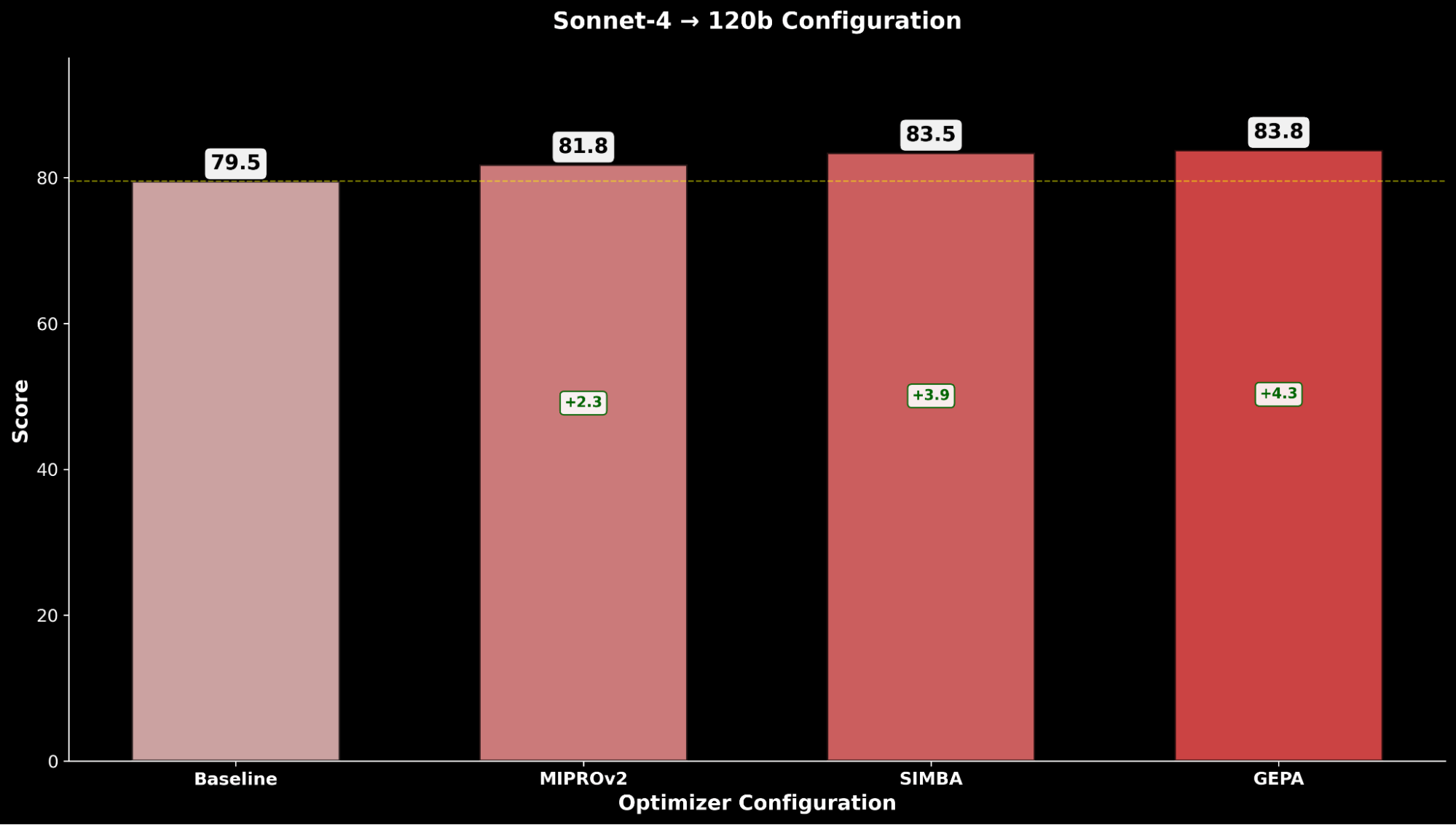
Throughout IE Bench, we discover that optimizing gpt-oss-120b with Claude Sonnet 4 because the optimizer mannequin achieves probably the most enchancment over baseline efficiency of gpt-oss-120b, with a big +4.3 level enchancment over the baseline and a +0.3 level enchancment over optimizing gpt-oss-120b with itself because the optimizer mannequin, highlighting carry by way of using a stronger optimizer mannequin.
We examine the best-performing GEPA-optimized gpt-oss-120b configuration towards the frontier Claude fashions:
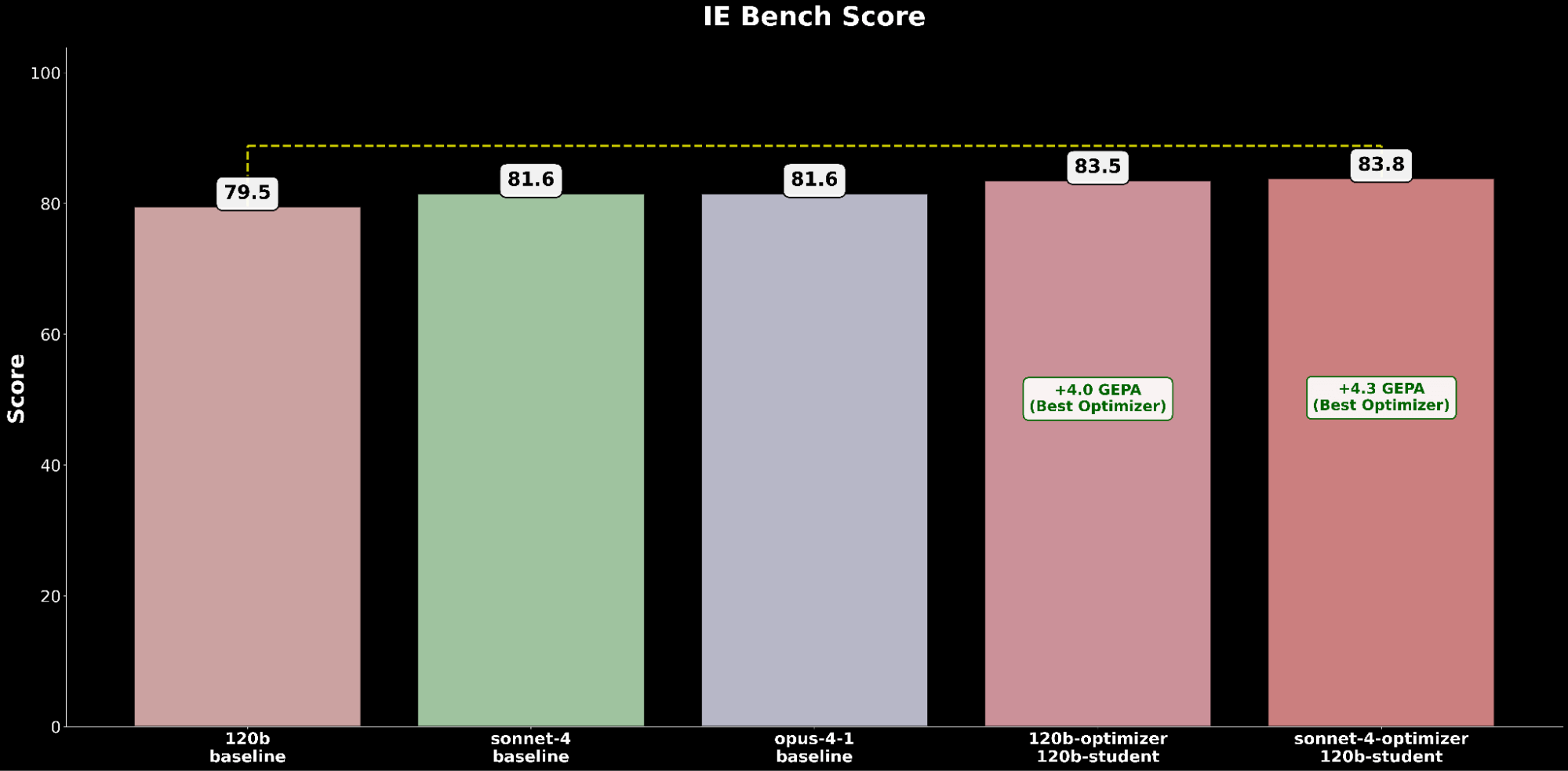
The optimized gpt-oss-120b configuration outperforms the state-of-the-art baseline efficiency of Claude Opus 4.1 by a +2.2 absolute acquire, highlighting the advantages of automated immediate optimization in elevating an open-source mannequin to outperform main proprietary fashions on IE capabilities.
Optimize frontier fashions to additional elevate efficiency ceiling
As we see the importance of automated immediate optimization, we discover whether or not making use of the identical precept to the main frontier fashions Claude Sonnet 4 and Claude Opus 4.1 can additional push the achievable efficiency frontier for IE Bench.
When optimizing every proprietary mannequin, we take into account the next configurations:
- Claude Sonnet 4 (optimizer) → Claude Sonnet 4 (scholar)
- Claude Opus 4.1 (optimizer) → Claude Opus 4.1 (scholar)
We select to contemplate the default optimizer mannequin configurations as these fashions already outline the efficiency frontier.
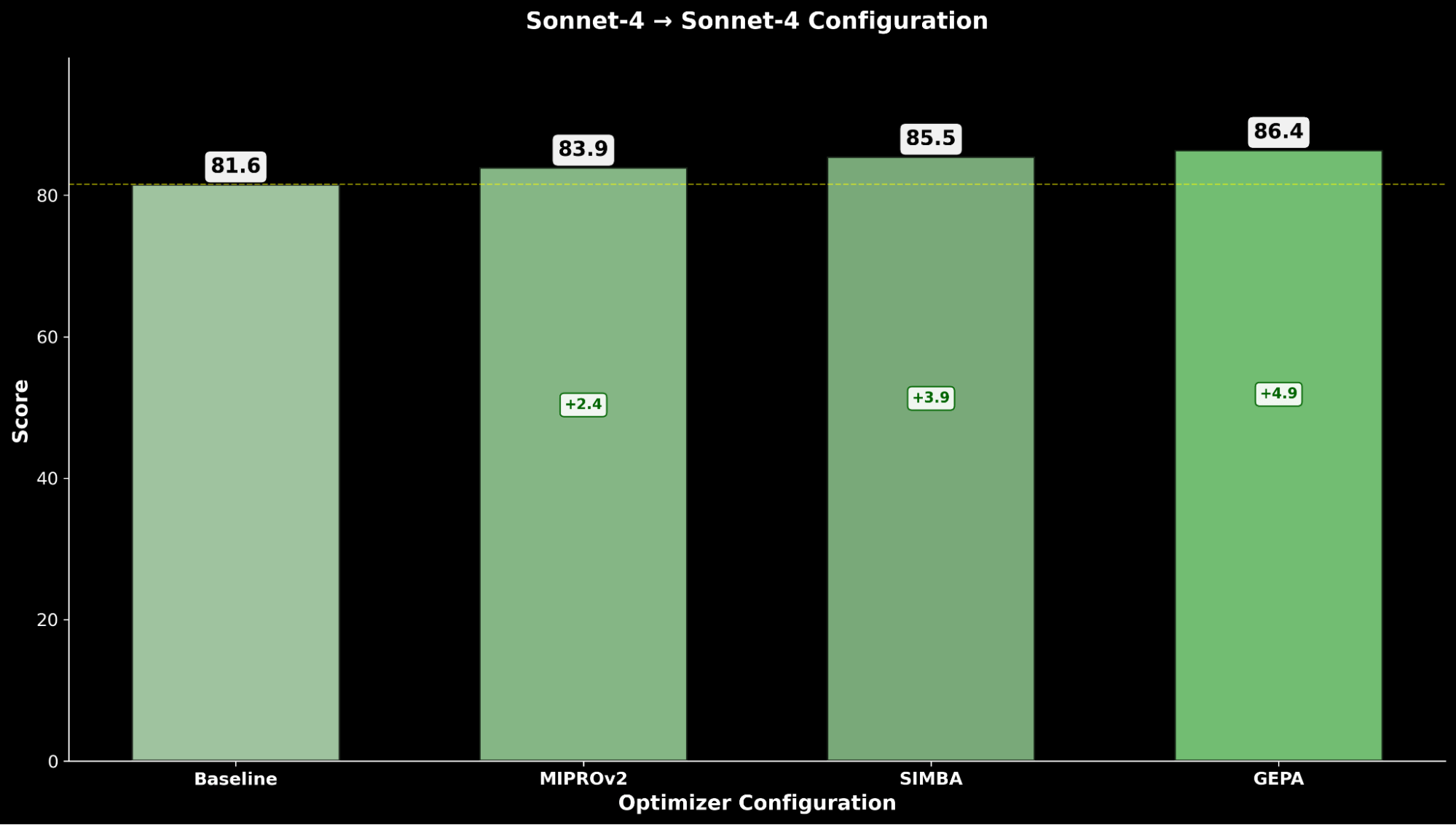
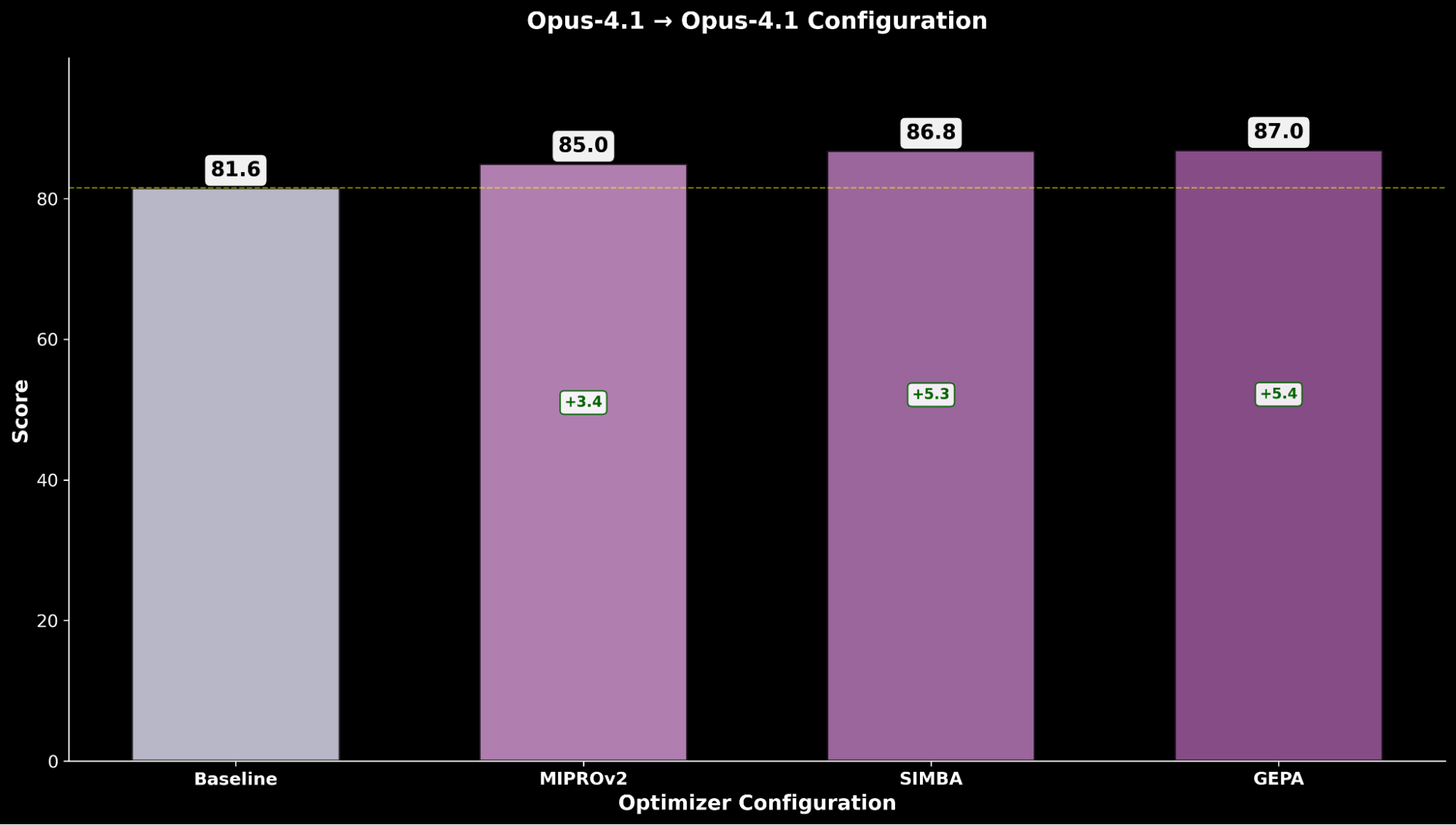
Optimizing Claude Sonnet 4 achieves a +4.8 enchancment over the baseline efficiency, whereas optimized Claude Opus 4.1 achieves the general greatest efficiency, with a big +6.4 level enchancment over the earlier state-of-the-art efficiency.
Aggregating experiment outcomes, we observe a constant development of automated immediate optimization delivering substantial efficiency positive factors throughout all fashions’ baseline efficiency.
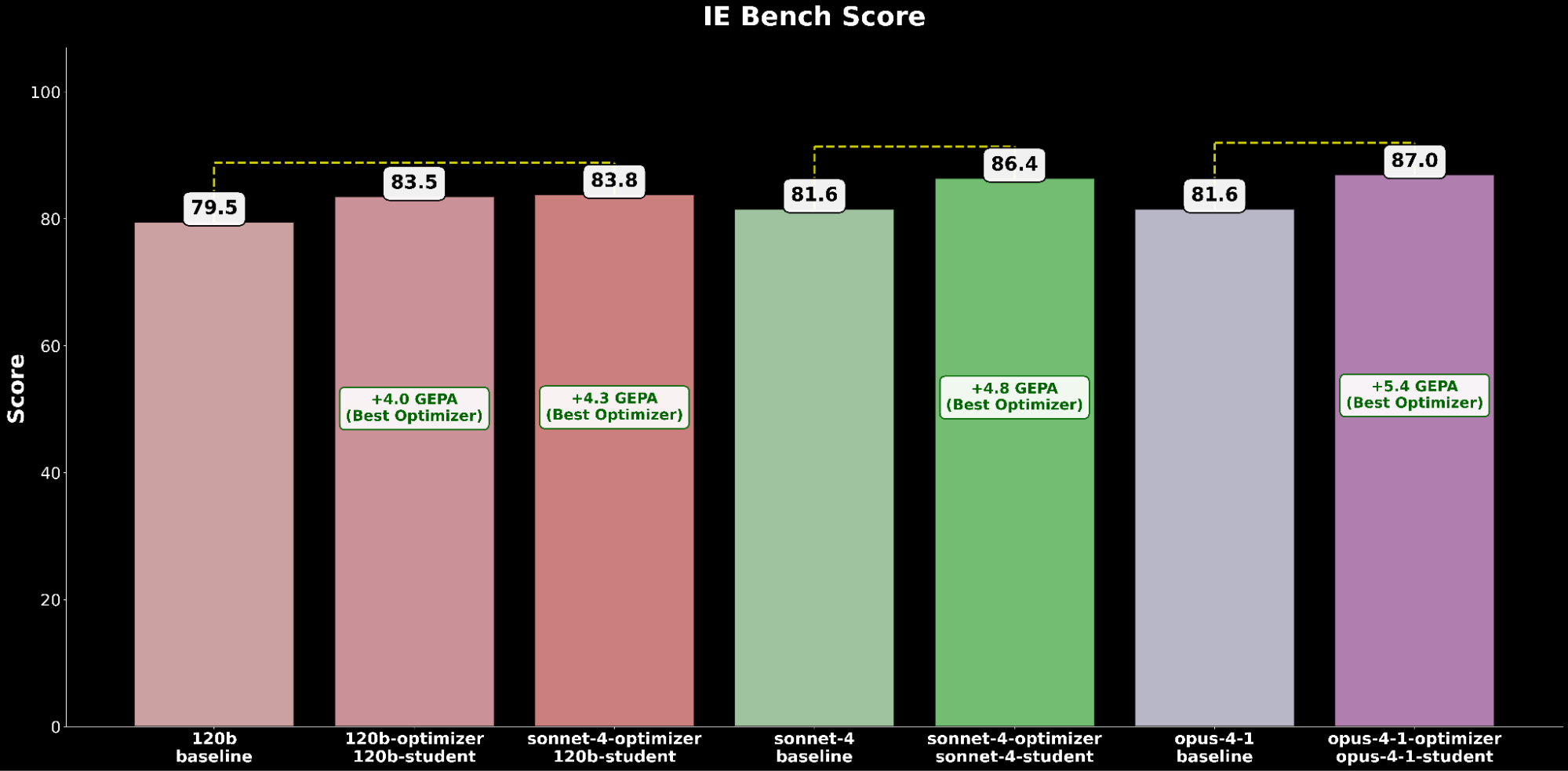
Throughout each open-source and closed-source mannequin evaluations, we constantly discover that GEPA is the highest-performing optimizer, adopted by SIMBA after which MIPRO, unlocking vital high quality positive factors utilizing automated immediate optimization.
Nonetheless, when contemplating value, we observe that GEPA has comparatively larger runtime overhead (because the optimization exploration can tackle the order of O(3x) extra LLM calls (~2-3 hrs) than MIPRO and SIMBA (~1 hr))3 throughout this empirical evaluation of IE Bench. We therefore think about value effectivity and replace our quality-cost Pareto frontier together with the optimized mannequin performances.
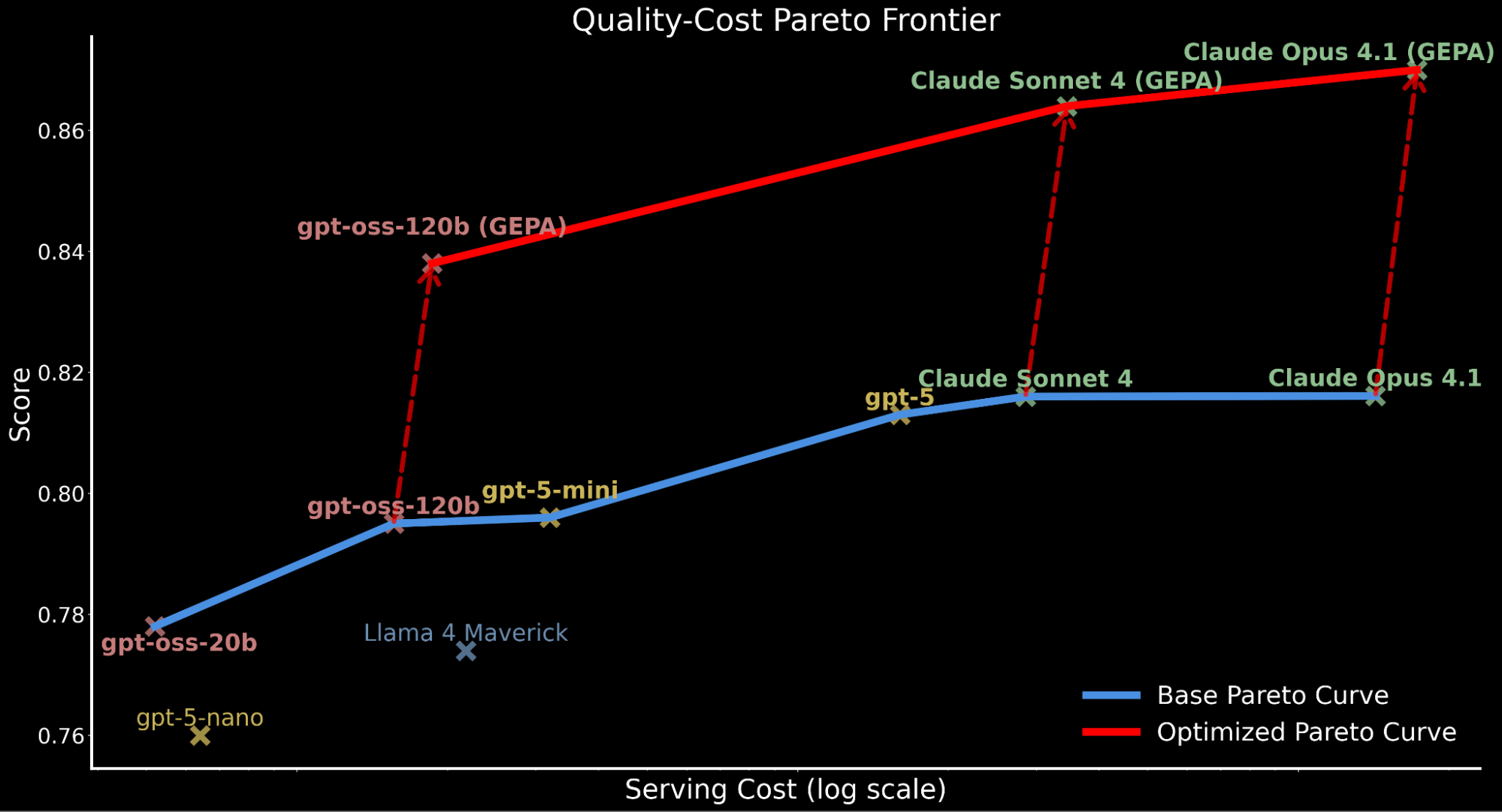
We spotlight how making use of automated immediate optimization shifts the complete Pareto curve upwards, establishing new state-of-the-art effectivity:
- GEPA-optimized gpt-oss-120b surpasses baseline efficiency of Claude Sonnet 4 and Claude Opus 4.1 whereas being 22x and 90x cheaper.
- For purchasers who prioritize high quality over value, GEPA-optimized Claude Opus 4.1 results in new state-of-the-art efficiency, highlighting highly effective positive factors for frontier fashions that can not be finetuned.
- We attribute the accounted whole serving value enhance for GEPA-optimized fashions to the longer, extra detailed prompts in comparison with the baseline immediate produced by way of optimization
By making use of automated immediate optimizations to brokers, we showcase an answer that delivers on Agent Bricks’ core ideas of excessive efficiency and price effectivity.
Comparability with SFT
Supervised Advantageous-Tuning (SFT) is usually thought-about the default technique for bettering mannequin efficiency, however how does it examine to automated immediate optimization
To reply this, we performed an experiment on a subset of IE Bench, selecting gpt 4.1 to judge SFT and automatic immediate optimization efficiency (We exclude gpt-oss and gpt-5 from these comparisons because the fashions weren’t launched on the time of analysis).
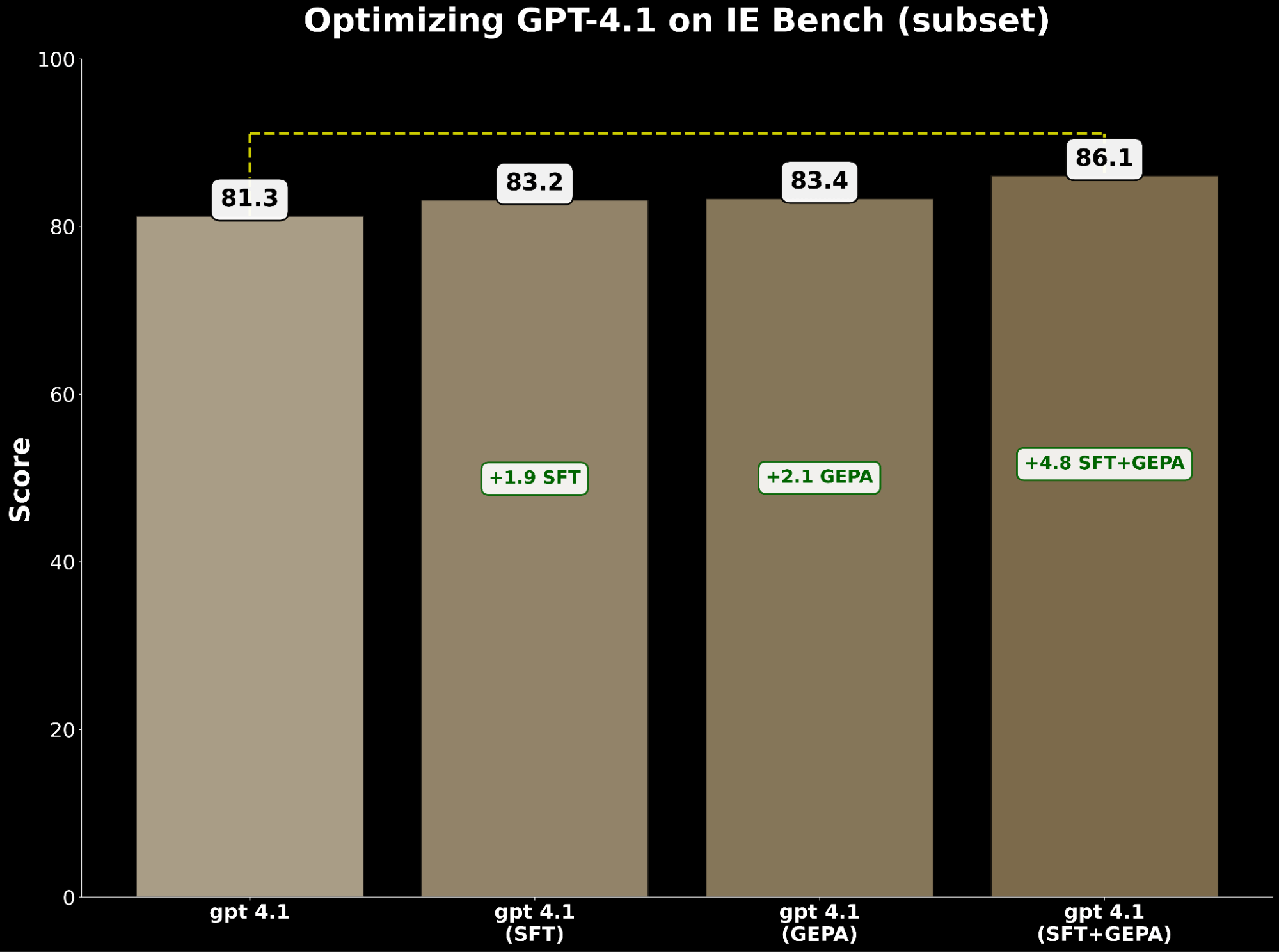
Each SFT and immediate optimization independently enhance gpt-4.1. Particularly:
- SFT gpt-4.1 gained +1.9 factors over baseline.
- GEPA-optimized gpt-4.1 gained +2.1 factors, barely exceeding SFT.
This demonstrates that immediate optimization can match—and even surpass—the enhancements of supervised fine-tuning.
Impressed by BetterTogether, a method that considers alternating immediate optimization and mannequin weight finetuning to enhance LLM efficiency, we apply GEPA on high of SFT and obtain a +4.8 level acquire over the baseline—highlighting the sturdy potential of compounding these methods collectively.
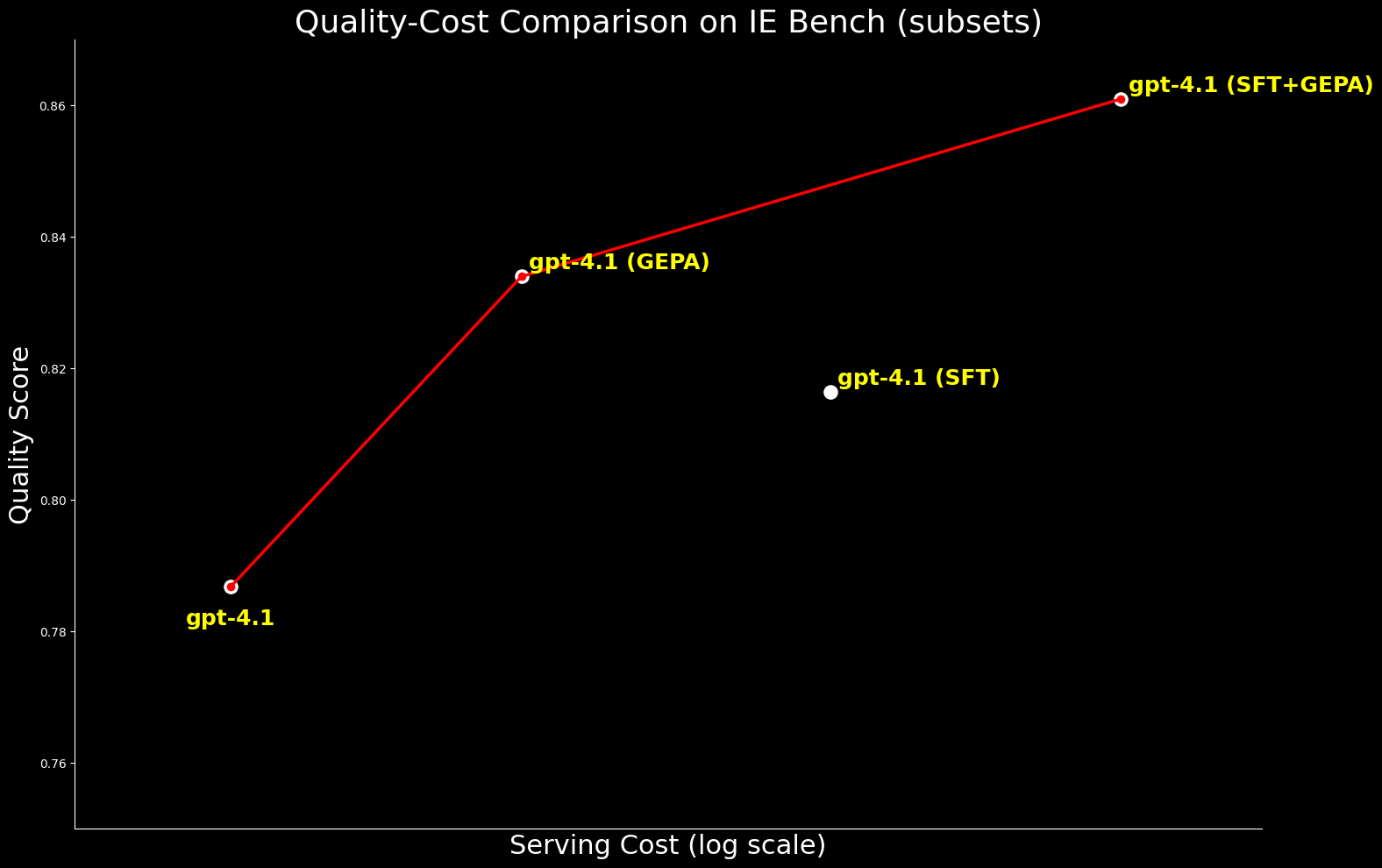
From a price perspective, GEPA-optimized gpt-4.1 is ~20% cheaper to serve than SFT-optimized gpt-4.1, whereas delivering higher high quality. This highlights that GEPA affords a premium quality-cost stability over SFT. Moreover, we are able to maximize absolute high quality by combining GEPA with SFT which performs 2.7% over SFT alone however comes at a ~22% larger serving value.4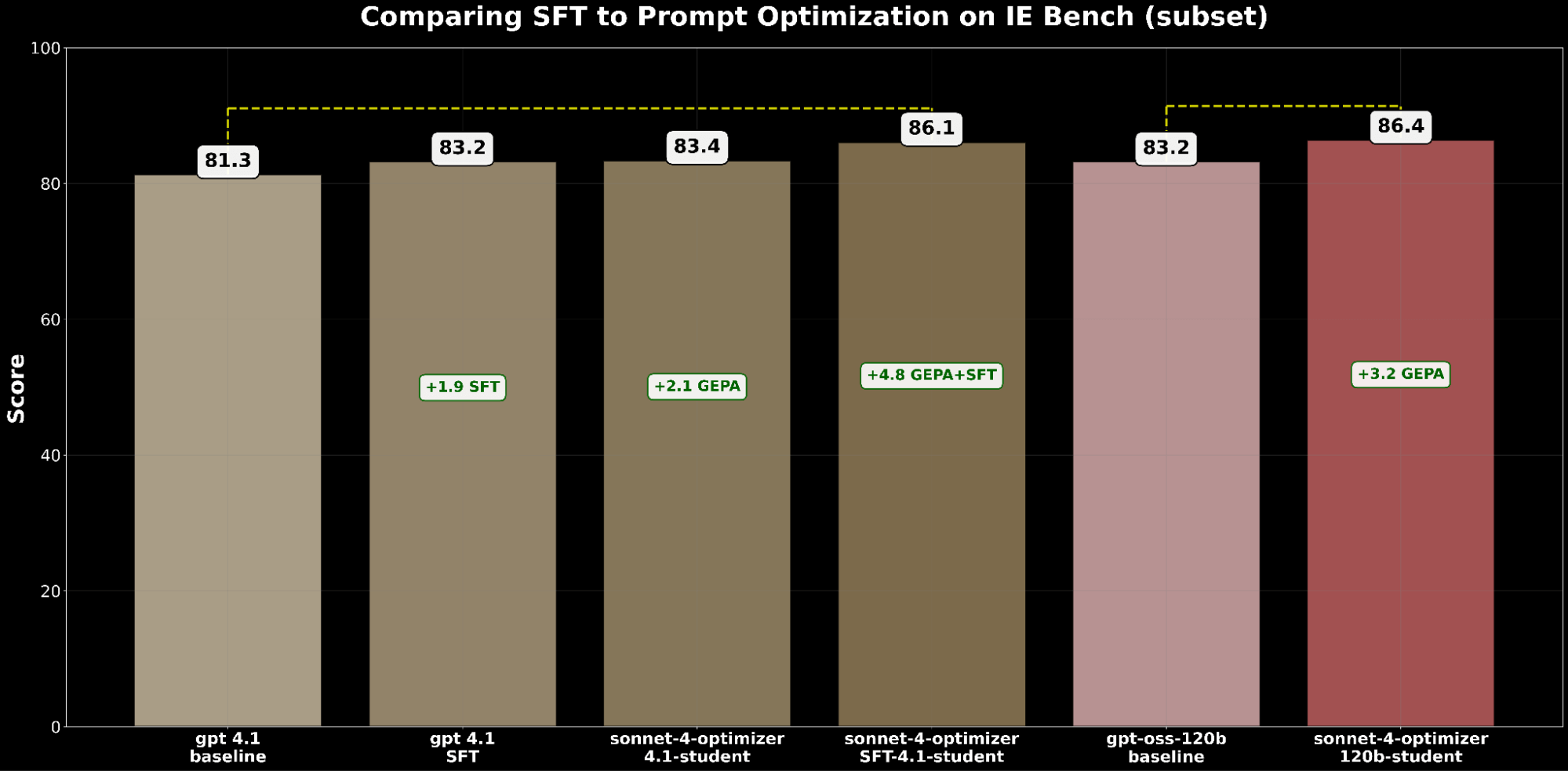
We prolonged the comparability to gpt-oss-120b to look at the standard–value frontier. Whereas SFT+GEPA-optimized gpt-4.1 comes shut—inside 0.3% of the efficiency of GEPA-optimized gpt-oss-120b—the latter delivers the identical high quality at 15× decrease serving value, making it much more sensible and enticing for large-scale deployment.

Collectively, these comparisons spotlight the sturdy efficiency positive factors enabled by GEPA optimization — whether or not used alone or together with SFT. In addition they spotlight the distinctive quality-cost effectivity of gpt-oss-120b when optimized with GEPA.
Lifetime Value
To judge optimization in real-world phrases, we take into account the lifetime value to prospects. The purpose of optimization just isn’t solely to enhance accuracy but in addition to provide an environment friendly agent that may serve requests in manufacturing. This makes it important to have a look at each the value of optimization and the value of serving giant volumes of requests.
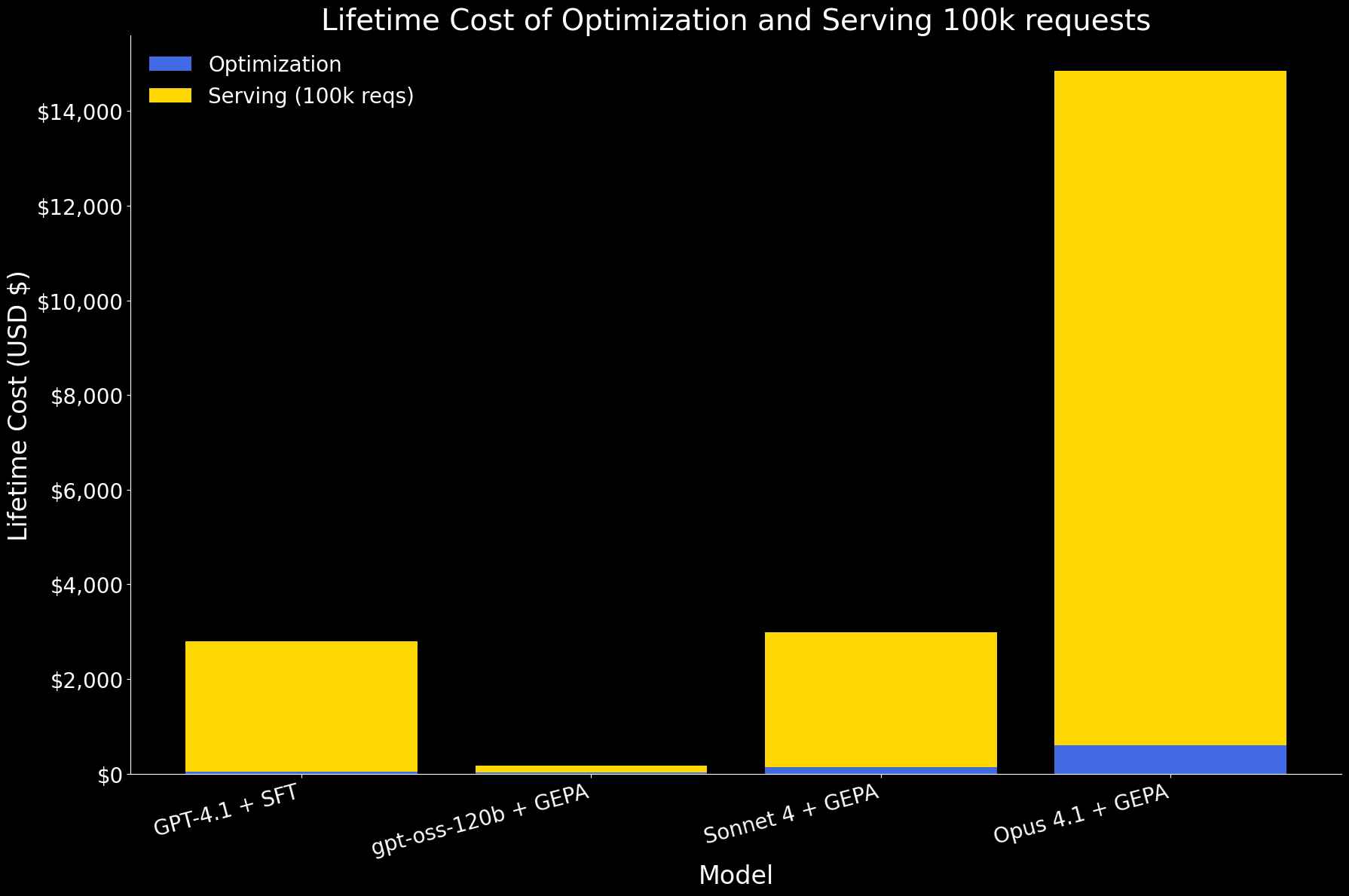
Within the first plot beneath, we present the lifetime value of optimizing an agent and serving 100k requests, damaged down into optimization and serving elements. At this scale, serving dominates the general value. Among the many fashions:
- gpt-oss-120b with GEPA is by far probably the most environment friendly, with prices an order of magnitude decrease for each optimization and serving.
- GPT 4.1 with SFT and Sonnet 4 with GEPA have related lifetime value.
- Opus 4.1 with GEPA is the most costly, primarily as a result of its excessive serving worth.
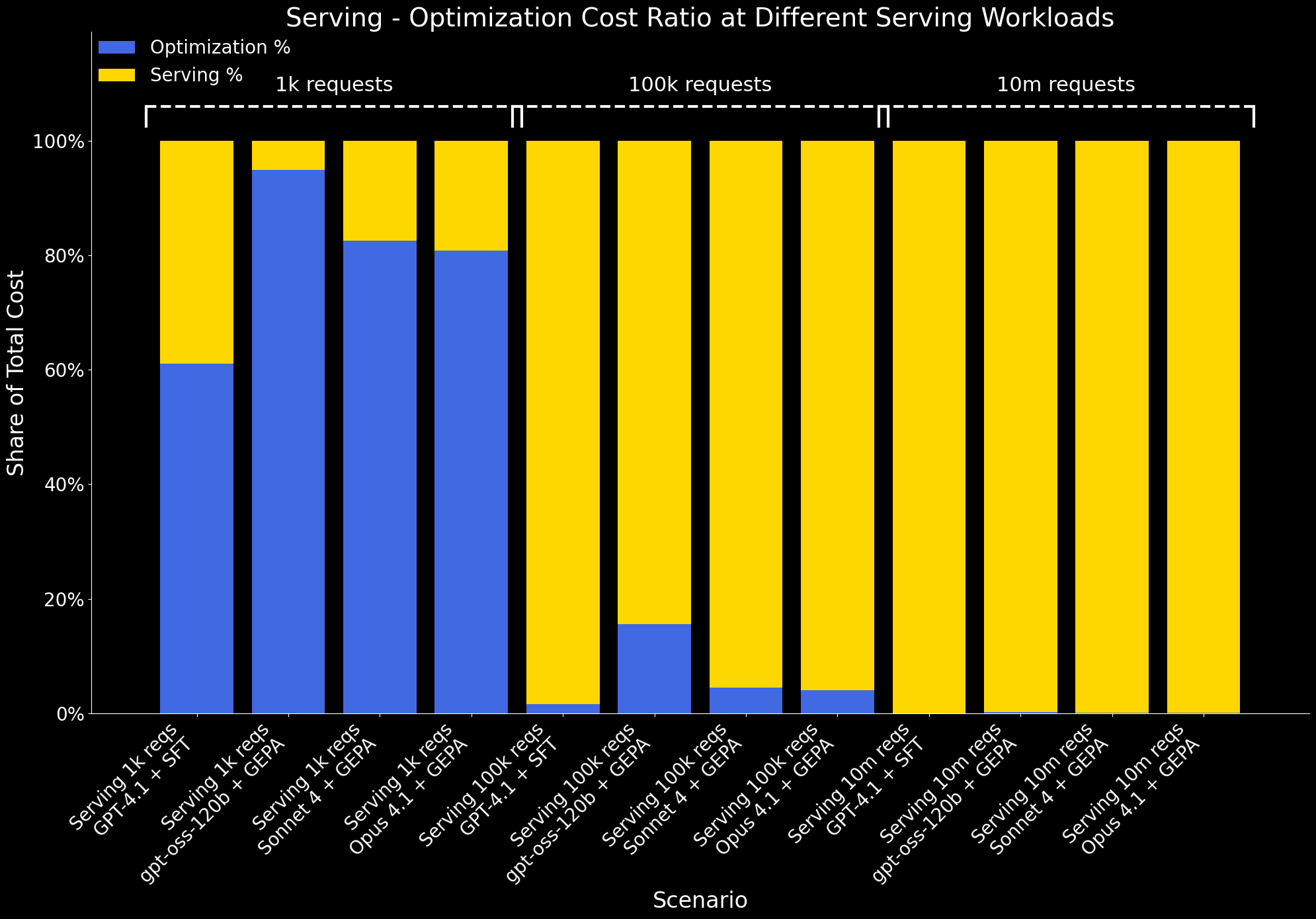
We additionally study how the ratio of optimization to serving value modifications at completely different workload scales:
- At 1k serving workloads, serving prices are minimal, so optimization accounts for a big share of the entire value.
- By 100k requests, serving prices develop considerably, and the optimization overhead is amortized. At this scale, the advantage of optimization – higher efficiency at decrease serving value – clearly outweighs its one-time value.
- At 10M requests, optimization prices grow to be negligible in comparison with serving prices and are now not seen on the chart.
Abstract
On this weblog put up, we demonstrated that automated immediate optimization is a robust lever for advancing LLM efficiency on enterprise AI duties:
- We developed IE Bench, a complete analysis suite spanning real-world domains and capturing complicated info extraction challenges.
- By making use of GEPA automated immediate optimization, we elevate the efficiency of the main open-source mannequin gpt-oss-120b to surpass the efficiency of state-of-the-art proprietary mannequin Claude Opus 4.1 by ~3% whereas being 90x cheaper to serve.
- The identical approach applies to frontier proprietary fashions, boosting Claude Sonnet 4 and Claude Opus 4.1 by 6-7%.
- Compared to Supervised Advantageous-Tuning (SFT), GEPA optimization supplies a superior quality-cost tradeoff for enterprise use. It delivers efficiency on par with or surpassing SFT whereas lowering serving prices by 20%.
- Lifetime value evaluation exhibits that when serving at scale (e.g., 100k requests), the one-time optimization overhead is shortly amortized, and the advantages far outweigh the fee. Notably, GEPA on gpt-oss-120b delivers an order-of-magnitude decrease lifetime value in comparison with different frontier fashions, making it a extremely enticing alternative for enterprise AI brokers.
Taken collectively, our outcomes present that immediate optimization shifts the standard–value Pareto frontier for enterprise AI programs, elevating each efficiency and effectivity.
The automated immediate optimization, together with beforehand revealed TAO, RLVR, and ALHF, is now obtainable in Agent Bricks. The core precept of Agent Bricks is to assist enterprises construct brokers that precisely motive in your knowledge, and obtain state-of-the-art high quality and cost-efficiency on domain-specific duties. By unifying analysis, automated optimization, and ruled deployment, Agent Bricks allows your brokers to adapt to your knowledge and duties, be taught from suggestions, and constantly enhance in your enterprise domain-specific duties. We encourage prospects to attempt Info Extraction and different Agent Bricks capabilities to optimize brokers on your personal enterprise use circumstances.
1 For each gpt-oss and gpt-5 mannequin collection, we observe the perfect practices from OpenAI’s Concord format that inserts the goal JSON schema within the developer message to generate structured output.
We additionally ablate over the completely different reasoning efforts for the gpt-oss collection (low, medium, excessive) and gpt-5 collection (minimal, low, medium, excessive), and report the perfect efficiency of every mannequin throughout all reasoning efforts.
2 For serving value estimates, we use revealed pricing from the mannequin suppliers’ platforms (OpenAI and Anthropic for proprietary fashions) and from Synthetic Evaluation for open-source fashions. Prices are calculated by making use of these costs to the enter and output token distributions noticed in IE Bench, giving us the entire value of serving for every mannequin.
3 The precise runtime of the automated immediate optimization is difficult to estimate, because it depends upon many components. Listed here are are giving a tough estimation based mostly on our empirical expertise.
4 We estimate the serving value of SFT gpt-4.1 utilizing OpenAI’s revealed fine-tuned mannequin pricing. For GEPA-optimized fashions, we calculate serving value based mostly on the measured enter and output token utilization of the optimized prompts.

{kind=link}