
Organizations typically wrestle with constructing scalable and maintainable information lakes—particularly when dealing with advanced information transformations, implementing information high quality, and monitoring compliance with established governance. Conventional approaches usually contain customized scripts and disparate instruments, which might enhance operational overhead and complicate entry management. A scalable, built-in strategy is required to simplify these processes, enhance information reliability, and help enterprise-grade governance.
Apache Airflow has emerged as a strong resolution for orchestrating advanced information pipelines within the cloud. Amazon Managed Workflows for Apache Airflow (MWAA) extends this functionality by offering a completely managed service that eliminates infrastructure administration overhead. This service permits groups to give attention to constructing and scaling their information workflows whereas AWS handles the underlying infrastructure, safety, and upkeep necessities.
dbt enhances information transformation workflows by bringing software program engineering greatest practices to analytics. It permits analytics engineers to remodel warehouse information utilizing acquainted SQL choose statements whereas offering important options like model management, testing, and documentation. As a part of the ELT (Extract, Load, Remodel) course of, dbt handles the transformation part, working immediately inside an information warehouse to allow environment friendly and dependable information processing. This strategy permits groups to take care of a single supply of fact for metrics and enterprise definitions whereas enabling information high quality via built-in testing capabilities.
On this submit, we present learn how to construct a ruled information lake that makes use of trendy information instruments and AWS providers.
Resolution overview
We discover a complete resolution that features:
- A metadata-driven framework in MWAA that dynamically generates directed acyclic graphs (DAGs), considerably bettering pipeline scalability and lowering upkeep overhead.
- dbt with Amazon Athena adapter to implement modular, SQL-based information transformations immediately on an information lake, enabling well-structured, and totally examined transformations.
- An automatic framework that proactively identifies and segregates problematic data, sustaining the integrity of information belongings.
- AWS Lake Formation to implement fine-grained entry controls for Athena tables, guaranteeing correct information governance and safety all through an information lake setting.
Collectively, these parts create a sturdy, maintainable, and safe information administration resolution appropriate for enterprise-scale deployments.
The next structure illustrates the parts of the answer.

The workflow comprises the next steps:
- A number of information sources (PostgreSQL, MySQL, SFTP) push information to an Amazon S3 uncooked bucket
- S3 occasion triggers AWS Lambda Operate
- Lambda perform triggers the MWAA DAG to transform file codecs to parquet
- Information is saved in Amazon S3 formatted bucket below formatted_stg prefix
- Crawler crawls the information in formatted_stg prefix within the formatted bucket and creates catalog tables
- dbt utilizing Athena adapter processes the information and places the processed information after information high quality checks below formatted prefix in Formatted bucket
- dbt utilizing Athena adapter can carry out additional transformations on the formatted information and put the remodeled information in Printed bucket
Conditions
To implement this resolution, the next stipulations must be met.
- An AWS account with create/function entry for the next AWS providers:
Deploy the answer
For this resolution, we offer an AWS CloudFormation (CFN) template that units up the providers included within the structure, to allow repeatable deployments.
Observe:
- US-EAST-1 Area is required for the deployment.
- Deploying this resolution will contain prices related to AWS providers.
To deploy the answer, full the next steps:
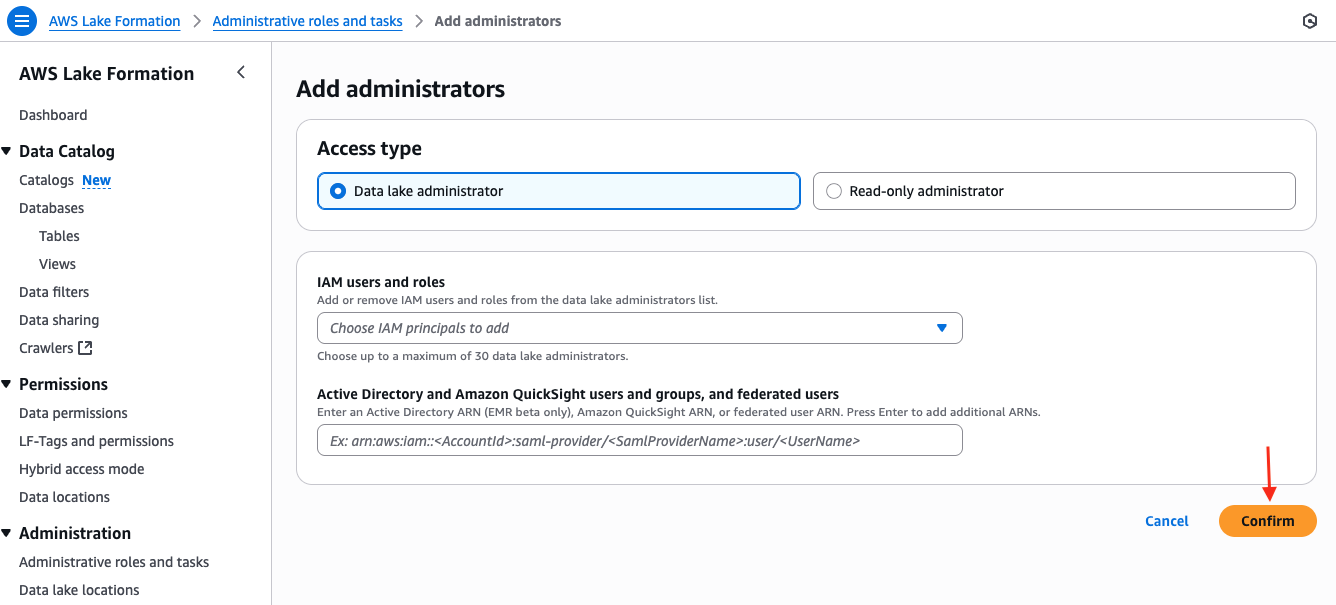
- Earlier than deploying the stack, open the AWS Lake Formation console. Add your console function as a Information Lake Administrator and select Affirm to avoid wasting the adjustments.
- Obtain the CloudFormation template.
After the file is downloaded to the native machine, observe the steps under to deploy the stack utilizing this template:- Open the AWS CloudFormation Console.
- Select Create stack and select With new assets (customary).
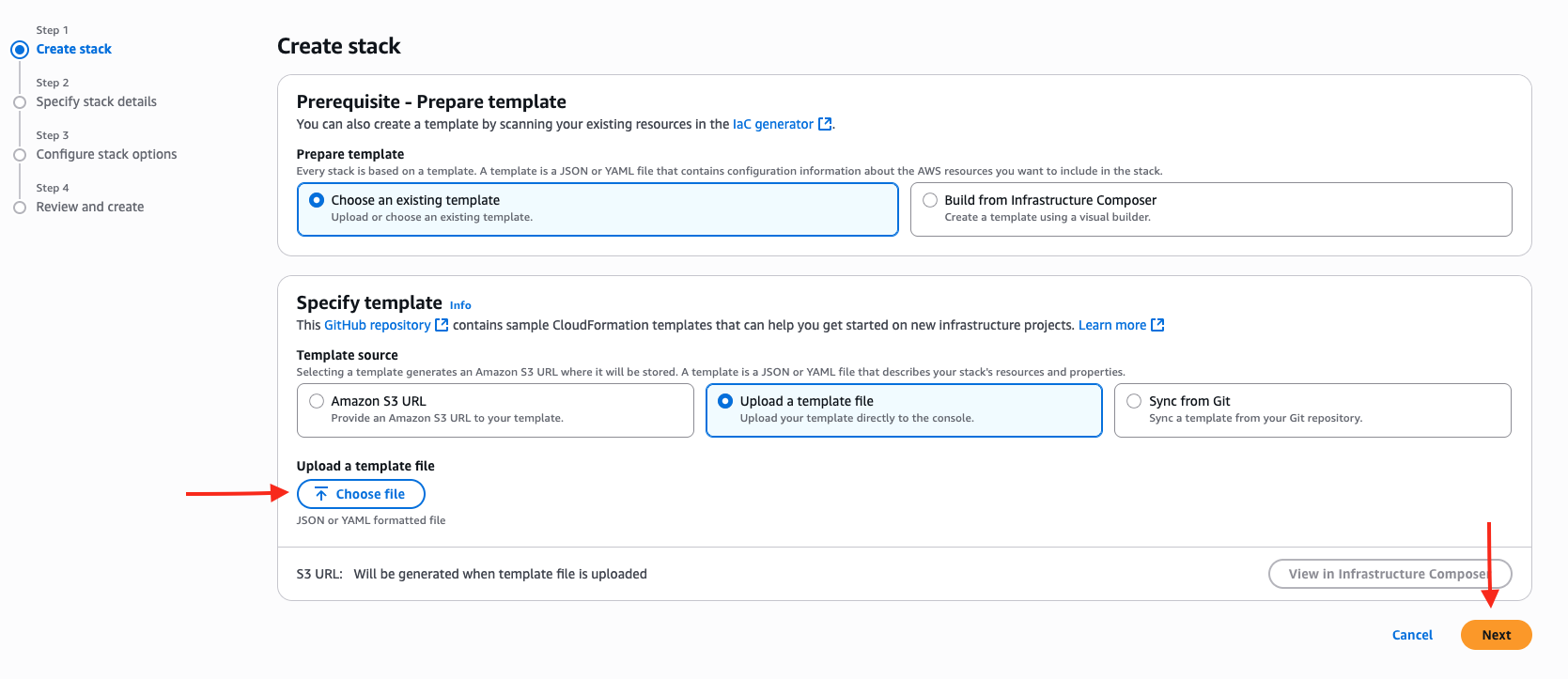
- Underneath Specify template, choose Add a template file.
- Choose Select file and add the CFN template that was downloaded earlier.
- Select Subsequent to proceed.
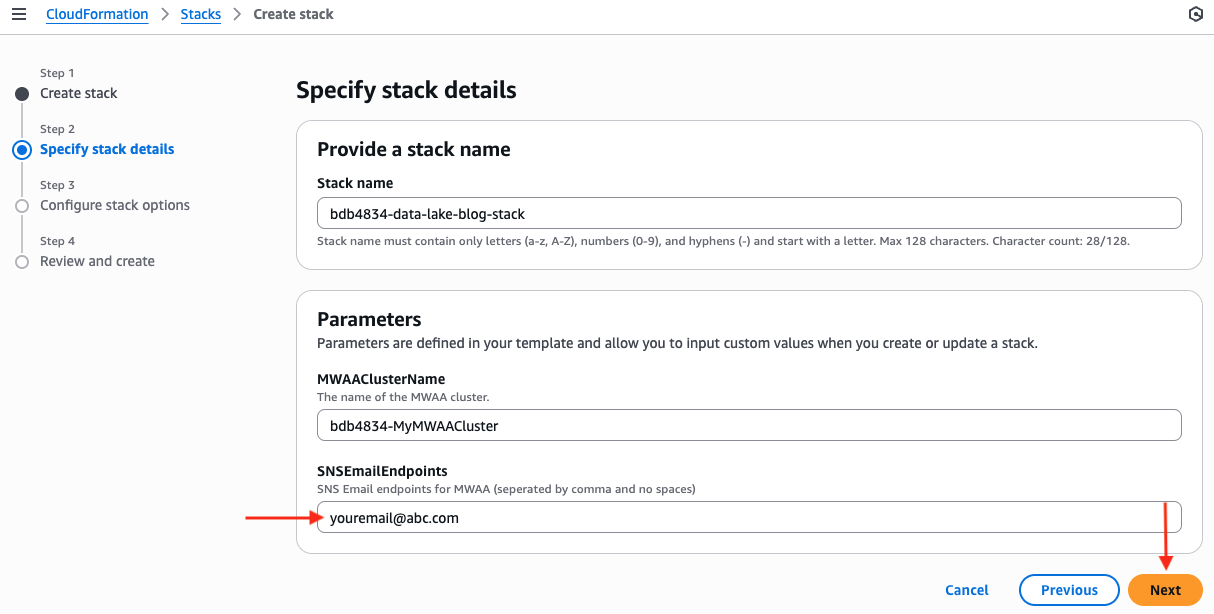
- Enter a stack title (for instance, bdb4834-data-lake-blog-stack) and configure the parameters (bdb4834-MWAAClusterName will be left because the default worth and replace SNSEmailEndpoints together with your e mail deal with), then select Subsequent.
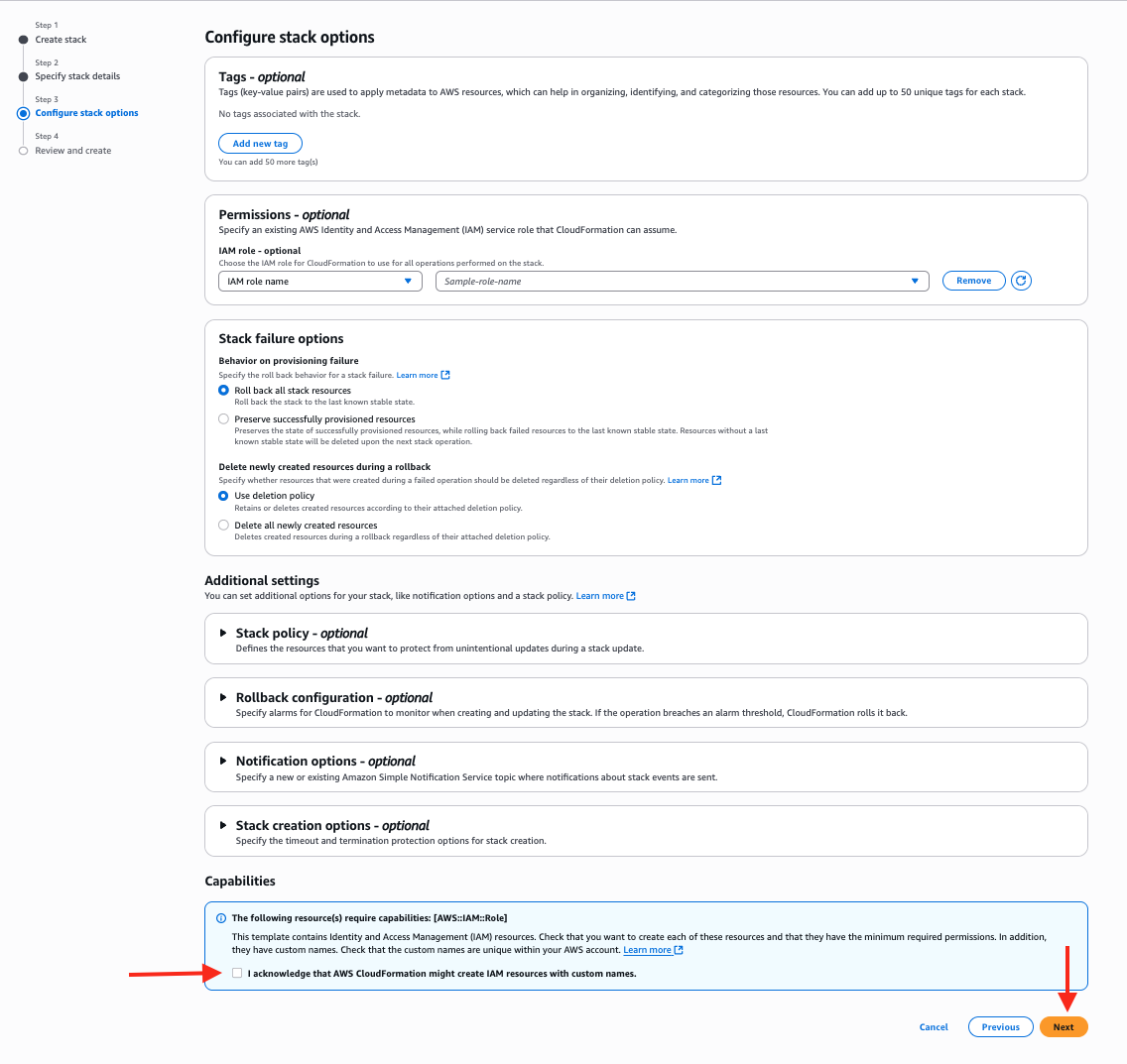
- Choose “I acknowledge that AWS CloudFormation would possibly create IAM assets with customized names” and select Subsequent
- Evaluate all of the configuration particulars on the following web page, then select Submit.
- Look forward to the stack creation to finish within the AWS CloudFormation console. The method usually takes roughly 35 to 40 minutes to provision all required assets.
The next desk exhibits assets accessible within the AWS Account after CloudFormation template deployment is efficiently accomplished:
Useful resource Kind Description Instance Useful resource Title S3 Buckets For storing uncooked, processed information and belongings bdb4834-mwaa-bucket- – ,bdb4834-raw-bucket- – ,bdb4834-formatted-bucket- – ,bdb4834-published-bucket- – IAM Function Function assumed by MWAA for permissions bdb4834-mwaa-role MWAA Atmosphere Managed Airflow setting for orchestration bdb4834-MyMWAACluster VPC Community setup required by MWAA bdb4834-MyVPC Glue Catalog Databases Logical grouping of metadata for tables bdb4834_formatted_stg,bdb4834_formatted_exception, bdb4834_formatted, bdb4834_published Glue Crawlers Routinely catalog metadata from S3 bdb4834-formatted-stg-crawler Lambda Lambda to Set off MWAA DAG on file arrival and to setup Lake Formation Permissions bdb4834_mwaa_trigger_process_s3_files,bdb4834-lf-tags-automation Lake Formation Setup Centralized governance and permissions LF-Setup for the above Sources Airflow DAGs Airflow DAGs are saved within the S3 bucket named mwaa-bucket- – below the dags/ prefix. These DAGs are liable for triggering information pipelines based mostly on both file arrival occasions or scheduled intervals. The precise performance of every DAG is defined within the following sections. blog-test-data-processingcrawler-daily-runcreate-audit-tableprocess_raw_to_formatted_stage - When the stack is full carry out the under steps:
- Open the Amazon Managed Workflows for Apache Airflow (MWAA) console, select on Open Airflow UI
- Within the DAGs console, find the next DAGs and unpause them by unchecking the toggle swap (radio button) subsequent to every DAG.

Add pattern information to uncooked S3 bucket and create catalog tables
On this part, we add pattern information to uncooked S3 bucket (bucket title beginning with bdb4834-raw-bucket) and convert the file codecs to parquet and run AWS Glue crawler to create catalog tables which can be utilized by dbt within the ELT Course of. Glue Crawler robotically scans the information in S3 and creates or updates tables within the Glue Information Catalog, making the information queryable and accessible for transformation.
- Obtain the pattern information.
- Zip folder comprises two pattern information recordsdata, playing cards.json and prospects.json
Schema for playing cards.jsonSubject Information Kind Description cust_id String Distinctive buyer identifier cc_number String Bank card quantity cc_expiry_date String Bank card expiry date Schema for purchasers.json
Subject Information Kind Description cust_id String Distinctive buyer identifier fname String First title lname String Final title gender String Gender deal with String Full deal with dob String Date of delivery (YYYY/MM/DD) cellphone String Cellphone quantity e mail String E-mail deal with - Open S3 console, select Common goal buckets within the navigation pane.
- Find the S3 bucket with a reputation beginning with bdb4834-raw-bucket. This bucket is created by the CloudFormation stack and can be discovered below the stack’s Sources tab within the CloudFormation console.
- Select the bucket title to open it, and observe these steps to create the required prefix:
- Select Create folder.
- Enter the folder title as mwaa/weblog/partition_dt=YYYY-MM-DD/, changing YYYY-MM-DD with the precise date for use for the partition.
- Select Create folder to verify.
- Add the pattern information recordsdata from the placement to the s3 uncooked bucket prefix.
- As quickly because the recordsdata are uploaded, the on_put object occasion on the uncooked bucket invokes
thebdb4834_mwaa_trigger_process_s3_fileslambda which triggers the process_raw_to_formatted_stg MWAA DAG.- Within the Airflow UI, select the process_raw_to_formatted_stg DAG to view execution standing. This DAG converts the file codecs to parquet and usually completes inside a couple of seconds.
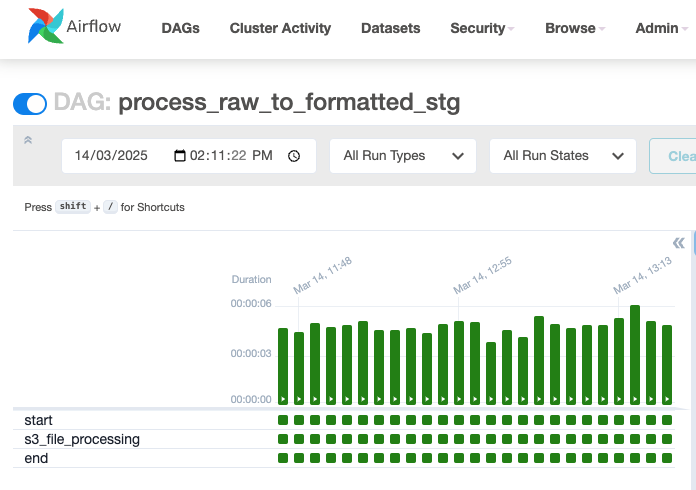
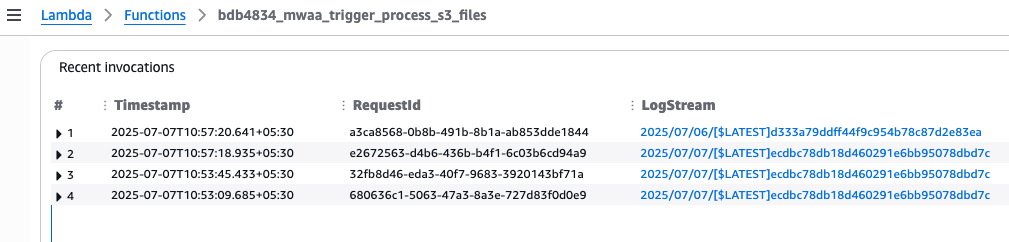
- (Elective) To test the Lambda execution particulars:
- On the AWS Lambda Console, select Capabilities within the navigation pane.
- Choose the perform named bdb4834_mwaa_trigger_process_s3_files.
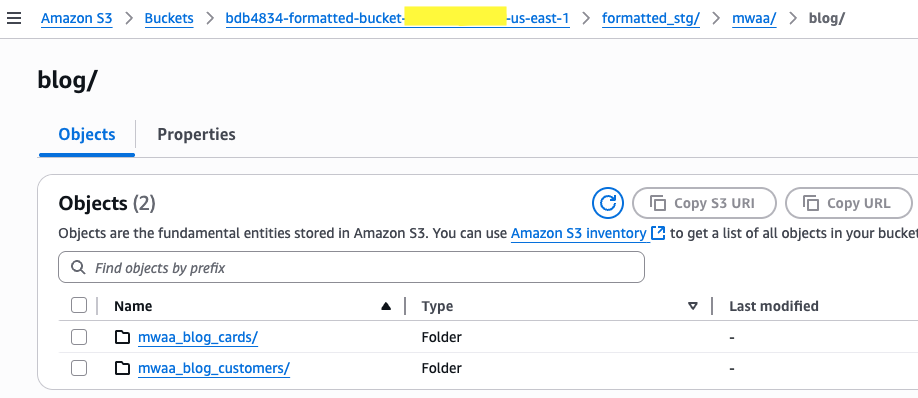
- Within the Airflow UI, select the process_raw_to_formatted_stg DAG to view execution standing. This DAG converts the file codecs to parquet and usually completes inside a couple of seconds.
- Validate the parquet recordsdata are created in formatted bucket (bucket title beginning with
bdb4834-formatted) below the respective information object prefix.
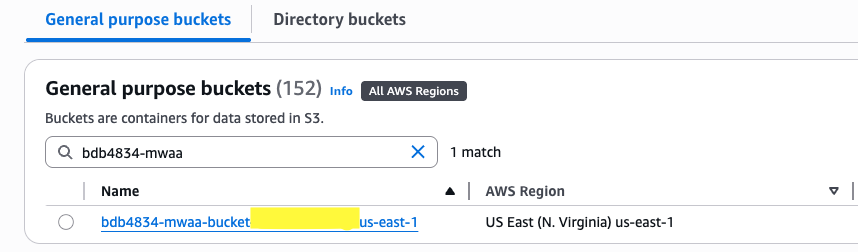
- Earlier than continuing additional, re-upload the Lake Formation metadata file in MWAA bucket.
- Open the S3 console, select Common goal buckets within the navigation pane.
- Seek for the bucket beginning with bdb4834-mwaa-bucket
- Select the bucket title and go to the lakeformation prefix. Obtain the file named
lf_tags_metadata.json. Now, re-upload the identical file to the identical location.
Observe: This re-upload is critical as a result of the Lambda perform is configured to set off on file arrival. When the assets have been initially created by the CloudFormation stack, the recordsdata have been merely moved to S3 and didn’t set off the Lambda. Re-uploading the file ensures the Lambda perform is executed as meant. - As quickly because the file is uploaded, the on_put object occasion on the MWAA bucket invokes the lf_tags_automation lambda, which creates the Lake Formation (LF) tags as outlined within the metadata file and grants entry to the required AWS Id and Entry Administration (IAM) roles for learn/write.
- Validate that the LF-Tags have been created by visiting the Lake Formation Console. Within the left navigation pane, select Permissions, after which choose LF-Tags and permissions.
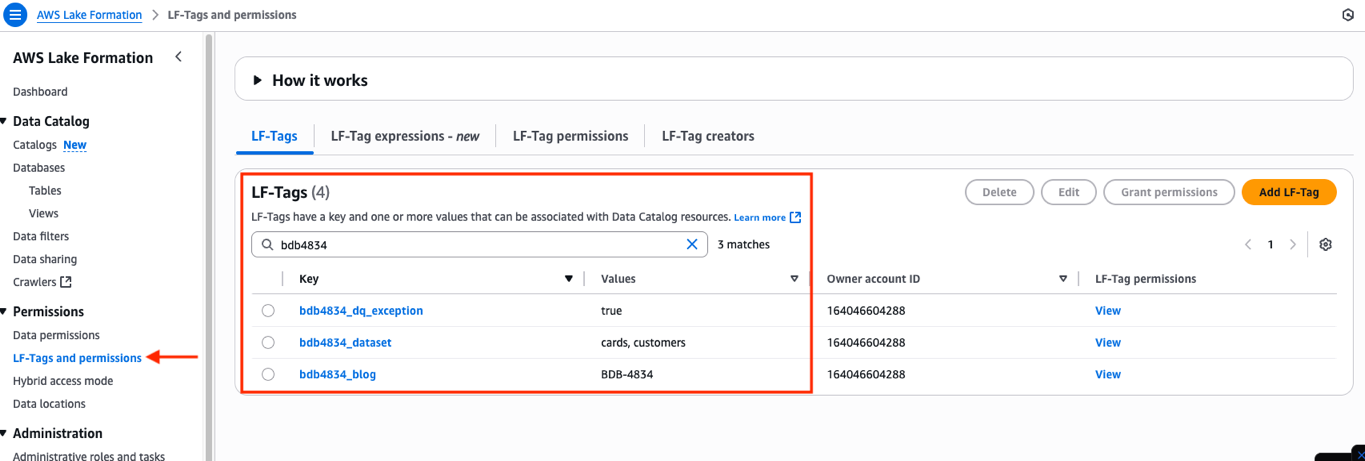
- Now, run the crawler DAG to create/replace the catalog tables:
crawler-daily-run- Within the Airflow UI choose the
crawler-daily-runDAG and select Set off DAG to execute it. - This DAG is configured to set off Glue Crawler which crawls the
formatted_stgprefix below thebdb4834-formatteds3 bucket to create catalog tables as per the prefixes accessible below theformatted_stgprefix.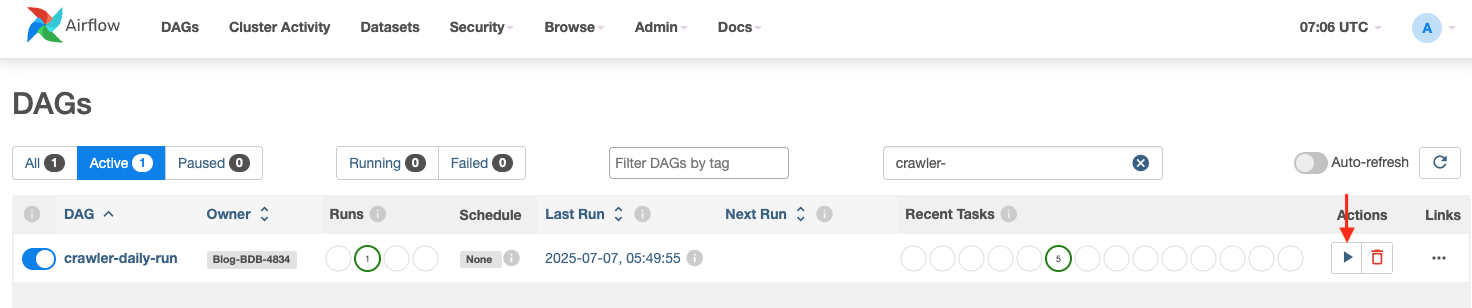
- Monitor the execution of the crawler-daily-run DAG till it completes, which usually takes 2 to three minutes. The crawler run standing will be verified within the AWS Glue Console by following these steps:
- Open the AWS Glue Console.
- Within the left navigation pane, select Crawlers.
- Seek for the crawler named
bdb4834-formatted-stg-crawler. - Examine the Final run standing column to verify the crawler executed efficiently.
- Select the crawler title to view further run particulars and logs if wanted.
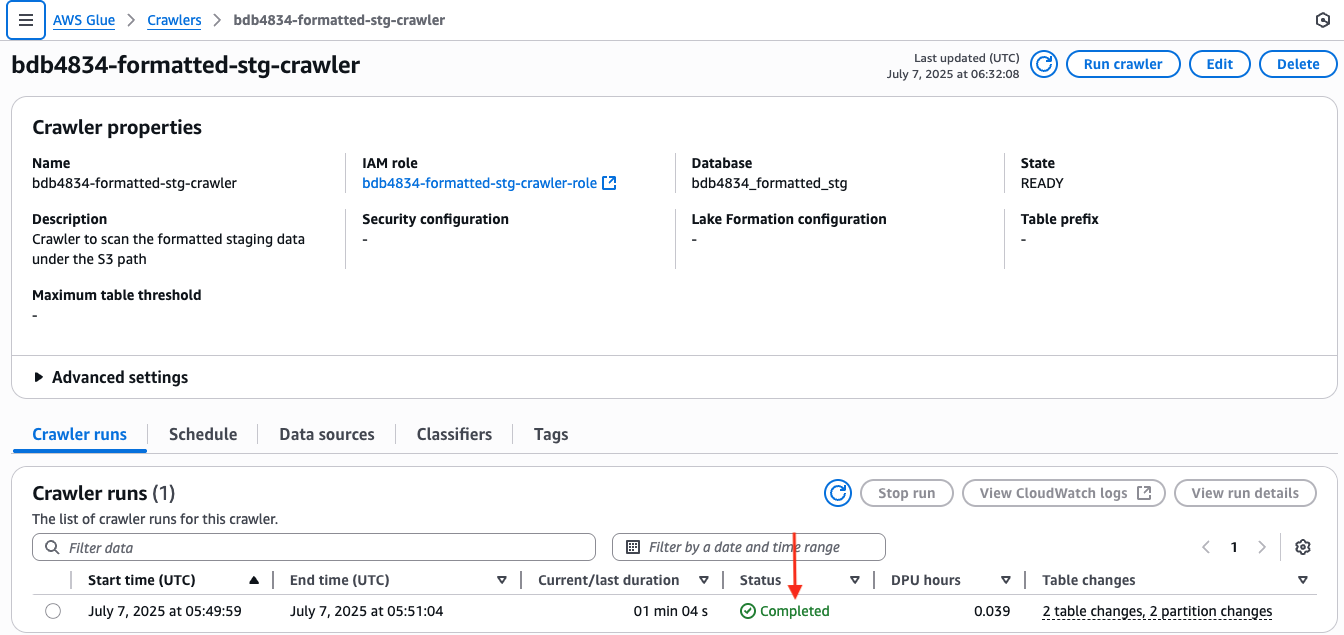
- As soon as the crawler has accomplished efficiently, within the left-hand panel, select Databases and choose the bdb4834_formatted_stg database to view the created tables, which ought to seem as displaying within the following picture. Optionally, choose the desk’s title to view its schema, after which choose Desk information to open Athena for information evaluation. (An error could seem when querying information utilizing Athena as a consequence of Lake Formation permissions. Evaluate the Governance utilizing Lake Formation part on this submit to resolve the difficulty.)
- Within the Airflow UI choose the
Observe: If that is the primary time Athena is getting used, a question outcome location have to be configured by specifying an S3 bucket. Observe the directions within the AWS Athena documentation to arrange the S3 staging bucket for storing question outcomes.
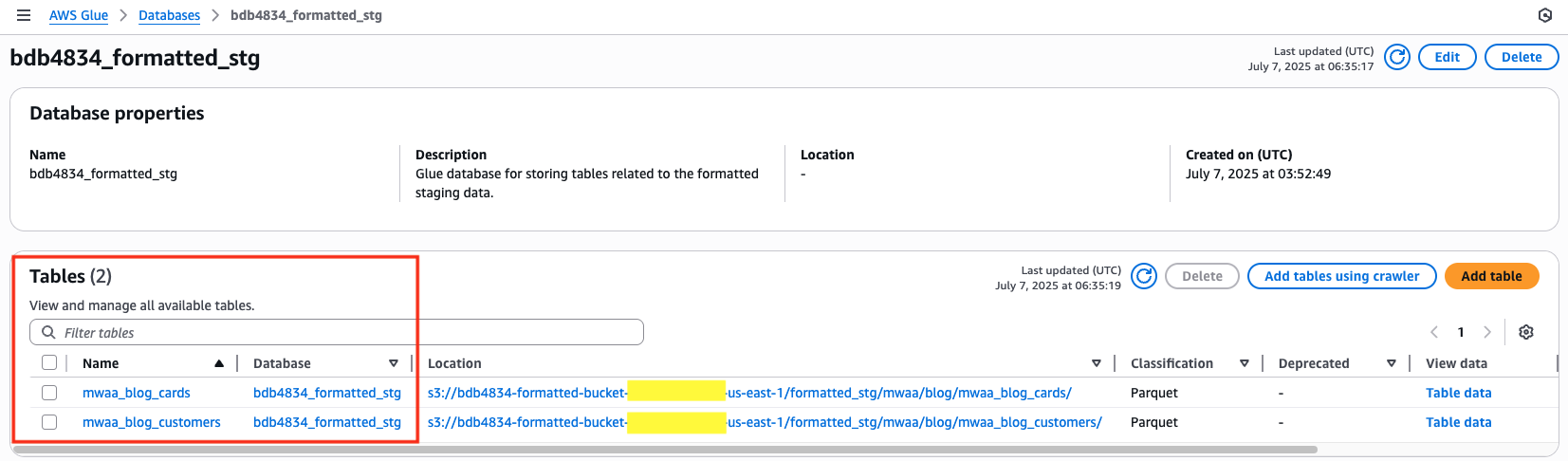
Run mannequin via DAG in MWAA
On this part, we cowl how dbt fashions run in MWAA utilizing Athena adapter to create Glue-catalogued tables and the way auditing is finished for every run.
- After creating the tables within the Glue database utilizing the AWS Glue Crawler within the earlier steps, we are able to now proceed to run the dbt fashions in MWAA. These fashions are saved in S3 within the type of SQL recordsdata, positioned on the S3 prefix: bdb4834-mwaa-bucket-
-us-east-1/dags/dbt/fashions/
The next are the dbt fashions and their performance:mwaa_blog_cards_exception.sqlThis mannequin reads information from themwaa_blog_cardsdesk within thebdb4834_formatted_stgdatabase and writes data with information high quality points to themwaa_blog_cards_exceptiondesk within thebdb4834_formatted_exceptiondatabase.mwaa_blog_customers_exception.sqlThis mannequin reads information from themwaa_blog_customersdesk within thebdb4834_formatted_stgdatabase and writes data with information high quality points to themwaa_blog_customers_exceptiondesk within thebdb4834_formatted_exceptiondatabase.mwaa_blog_cards.sqlThis mannequin reads information from themwaa_blog_cardsdesk within thebdb4834_formatted_stgdatabase and masses it into themwaa_blog_cardsdesk within thebdb4834_formatteddatabase. If the goal desk doesn’t exist, dbt robotically creates it.mwaa_blog_customers.sqlThis mannequin reads information from themwaa_blog_customersdesk within thebdb4834_formatted_stgdatabase and masses it into themwaa_blog_customersdesk within thebdb4834_formatteddatabase. If the goal desk doesn’t exist, dbt robotically creates it.
- The
mwaa_blog_cards.sqlmannequin processes bank card information and is dependent upon themwaa_blog_customers.sqlmannequin to finish efficiently earlier than it runs. This dependency is critical as a result of sure information high quality checks—corresponding to referential integrity validations between buyer and card data—have to be carried out beforehand.- These relationships and checks are outlined within the
schema.ymlfile positioned in the identical S3 path:bdb4834-mwaa-bucket-. The schema.yml file offers metadata for dbt fashions, together with mannequin dependencies, column definitions, and information high quality checks. It makes use of macros like-us-east-1/dags/dbt/fashions/ get_dq_macro.sqlanddq_referentialcheck.sql(discovered below the macros/ listing) to implement these validations.
Because of this, dbt robotically generates a lineage graph based mostly on the declared dependencies. This visible graph helps orchestrate mannequin execution order—guaranteeing fashions like
mwaa_blog_customers.sqlrun earlier than dependent fashions corresponding tomwaa_blog_cards.sql, and identifies which fashions can execute in parallel to optimize the pipeline. - These relationships and checks are outlined within the
- As a pre-step earlier than working fashions, select the set off DAG button for create-audit-table to create audit desk for storing run particulars for every mannequin.

- Set off the
blog-test-data-processingDAG within the Airflow UI to start out the Mannequin run. - Select
blog-test-data-processingto see the execution standing. This DAG runs the fashions so as and creates Glue catalogued iceberg tables. The movement diagram of a DAG from Airflow UI will be discovered by selecting Graph after selecting DAG.

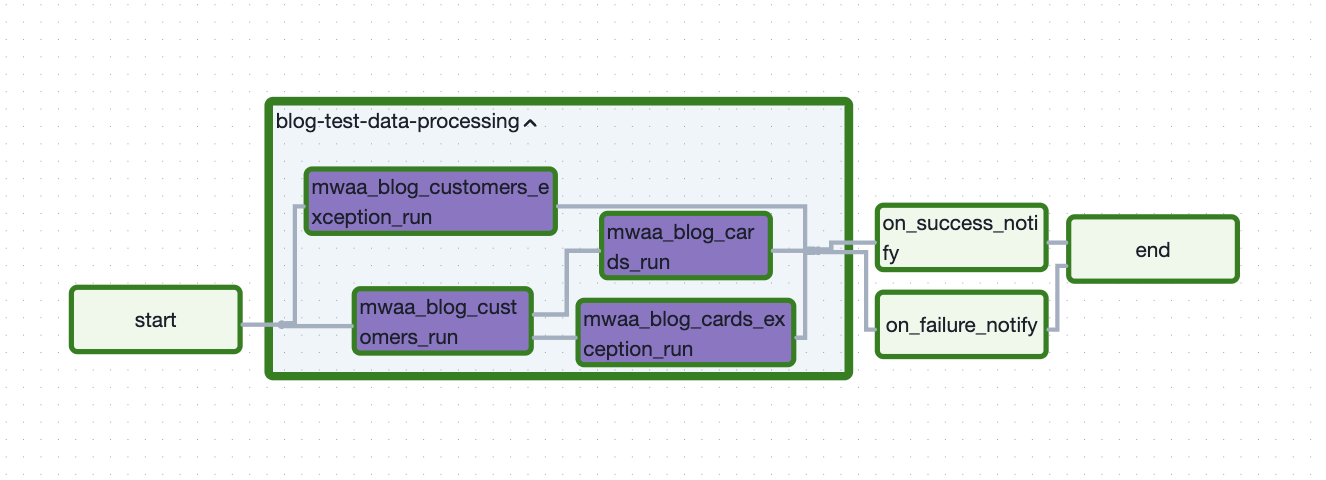
- The exception fashions places the failed data below exception prefix in S3:
Information that failed are present in an added column, tests_failed, the place all the information high quality checks that failed for that specific row are added, separated by a pipe (‘|’). (For the
mwaa_blog_customers_exceptiontwo exception data are discovered within the desk.) - The handed data are put below formatted prefix in S3.
- For every run, a run audit is captured within the audit desk with execution particulars like model_nm, process_nm, execution_start_date, execution_end_date, execution_status, execution_failure_reason, rows_affected.
Discover the information in S3 below the prefixbdb4834-formatted-bucket-- /audit_control/ - Monitor the execution till the DAG completes, which might take as much as 2-3 minutes. The execution standing of the DAG will be seen within the left panel after opening the DAG.

- As soon as the DAG has accomplished efficiently, open the AWS Glue console and choose Databases. Choose the
bdb4834_formatteddatabase, which ought to create three tables, as proven within the following picture.
Optionally, select Desk information to entry Athena for information evaluation.
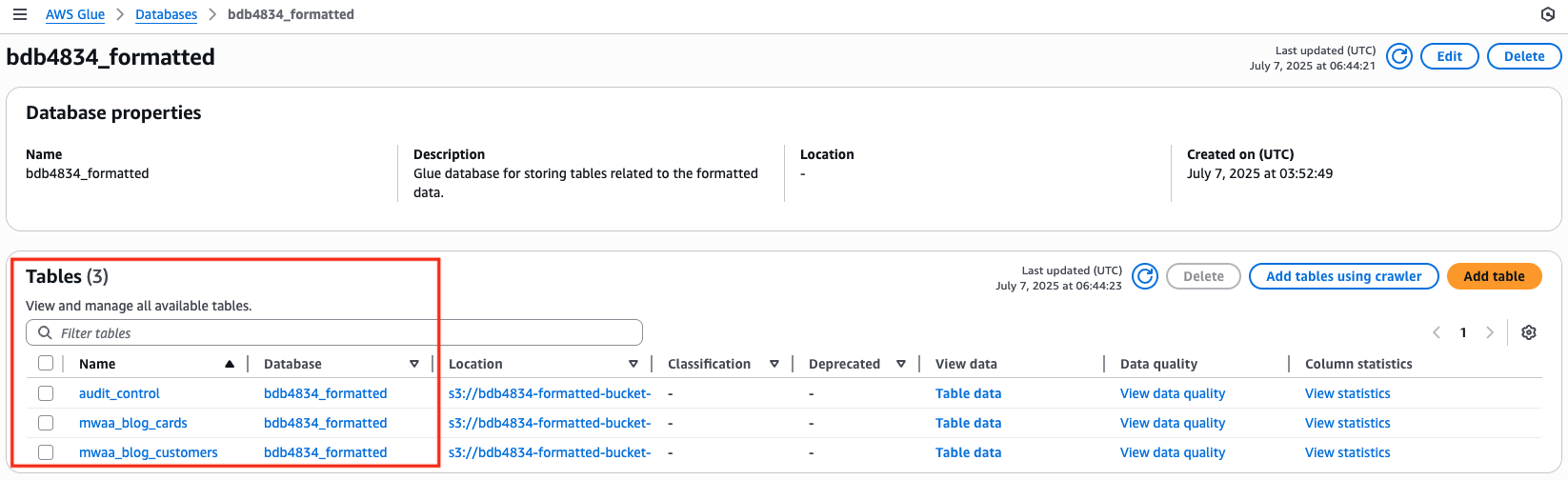
- Select
bdb4834_formatted_exceptiondatabase from below Databases in AWS Glue console, which ought to create two tables as proven within the following picture.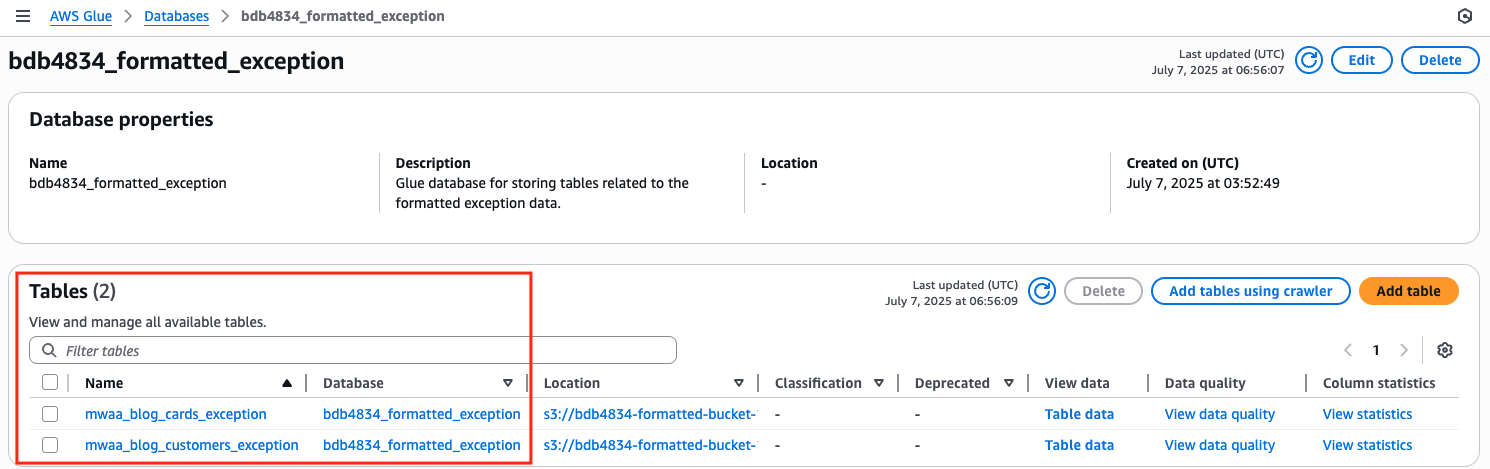
- Every mannequin is assigned LF tags via the config block of mannequin itself. Due to this fact, when the iceberg tables are created via dbt, LF tags are hooked up to the tables after the run completes.
Validate the LF tags hooked up to the tables by visiting the AWS Lake Formation console. Within the left navigation pane, select Tables and search for
mwaa_blog_customersormwaa_blog_cardsdesk belowbdb4834_formatteddatabase. Choose any desk among the many two and below Actions, select Edit LF tags and the tags are hooked up, as proven within the following display shot.
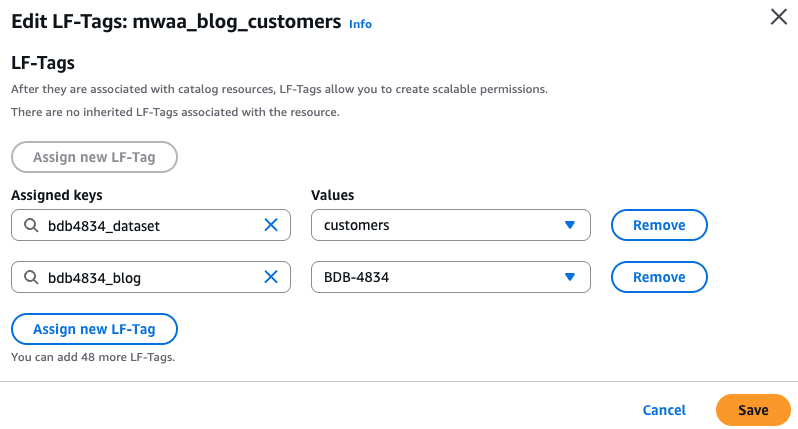
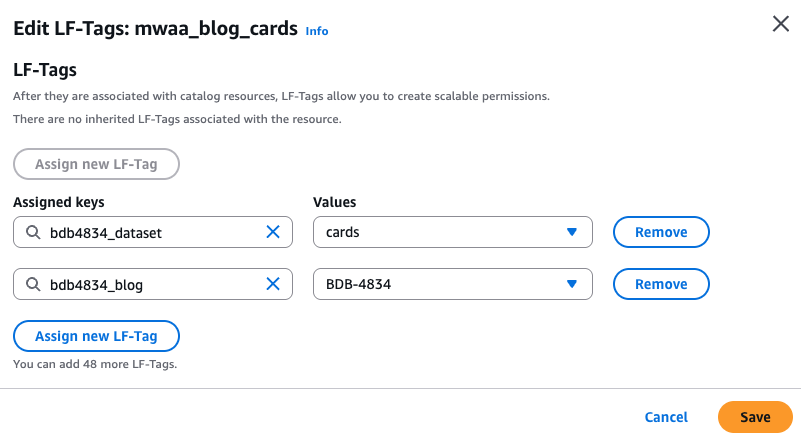
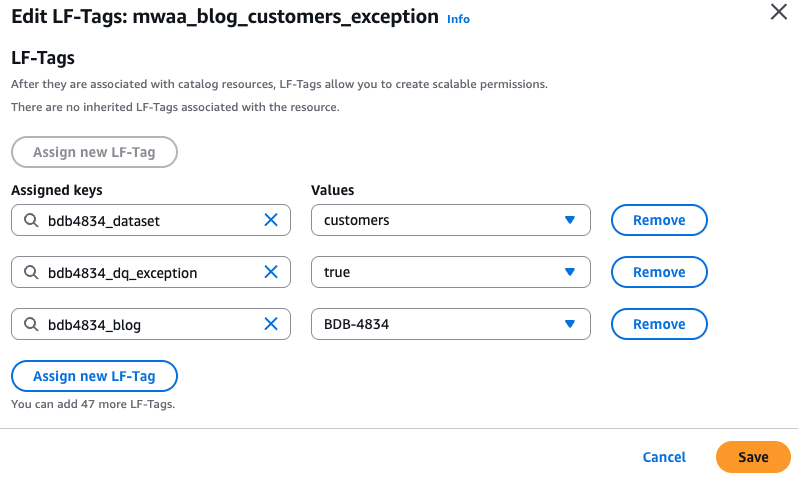
- Equally, for the
bdb4834_formatted_exceptiondatabase, choose any one of many exception tables below thebdb4834_formatted_exceptiondatabase and the LF tags are hooked up.
- Run SQL queries on the tables created by opening the Athena console and working Analytical queries on the tables created above.Pattern SQL queries:


- The exception fashions places the failed data below exception prefix in S3:
Governance utilizing Lake Formation
On this part, we present how assigning Lake Formation permissions and creating LF tags is automated utilizing the metadata file.Under is a metadata file construction, which is required for reference when importing the metadata file for Lake Formation in Airflow S3 bucket, contained in the Lake Formation prefix.
Elements of the metadata file
role_arn: The IAM function that the Lambda perform assumes to carry out operations.access_type: Specifies whether or not the motion is to grant or revoke permissions (GRANT, REVOKE).lf_tags: Tags used for tag-based entry management (TBAC) in Lake Formation.named_data_catalog: A listing of databases and tables on which Lake Formation permissions or tags are utilized to.table_permissions: Lake Formation-specific permissions (e.g., SELECT, DESCRIBE, ALTER, and so forth.).
Lambda perform bdb4834-lf-tags-automation parses this JSON and grants the required LF tags to the function with given desk permissions.
- To replace the metadata file, obtain it from the MWAA bucket (lakeformation prefix)
- Add a JSON object with the metadata construction outlined above, mentioning the IAM function ARN and the tags and tables to which entry must be granted.
Instance:Let’s assume under is how the metadata file initially seems to be like:Under is the json object that must be added within the above metadata file:
So now, the ultimate metadata file ought to seem like:
- Upon importing this file on the similar location (
bdb4834-mwaa-bucket->->/lakeformation/) in S3, thelf_tags_automationlambda is triggered to create LF tags in the event that they don’t exist after which it assigns these tags to the IAM function ARN and likewise grants permission to the IAM function ARN utilizingnamed_data_catalogas outlined.To confirm the permissions, go to the Lake Formation console and select Tables below Information Catalog and seek for the desk title.

To test LF-Tags, select the desk title and below the LF tags part, all of the tags are discovered hooked up to this desk.
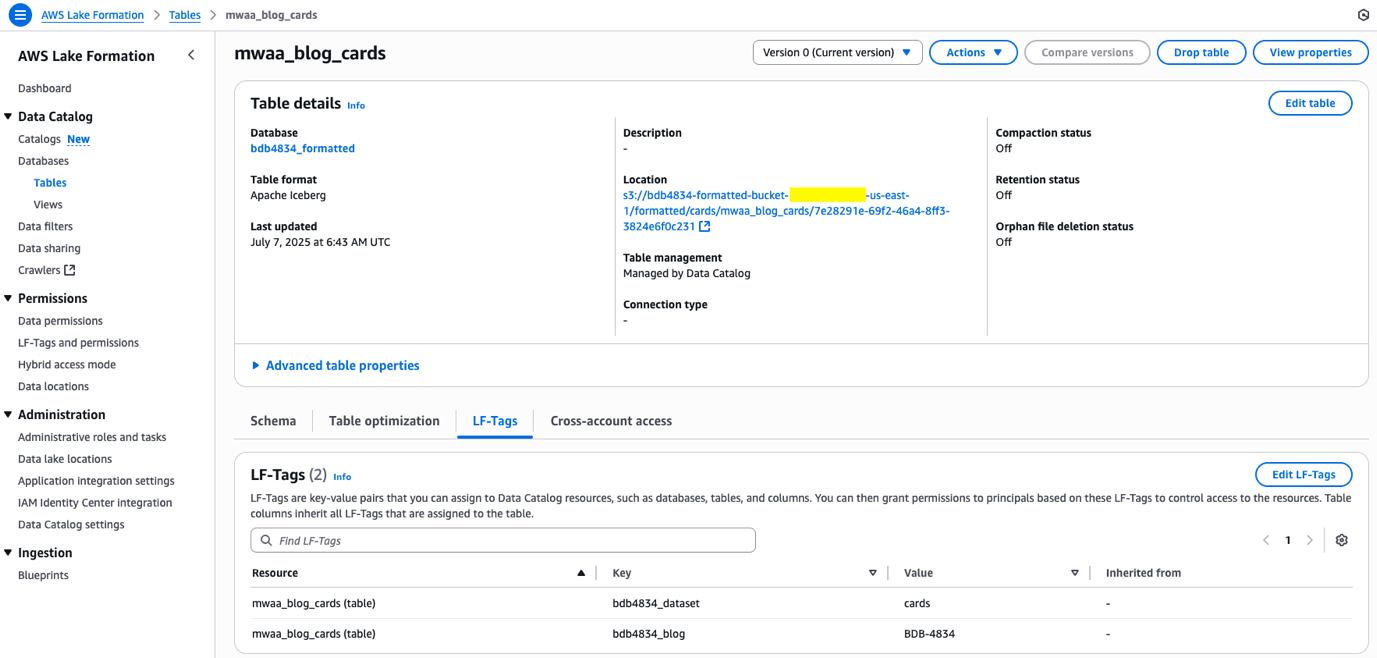
This metadata file used as a structured enter to an AWS Lambda perform automates the next to carry out automated, constant, and scalable information entry governance throughout the AWS Lake Formation environments:
- Granting AWS Lake Formation (LF) permissions on Glue Information Catalog assets (like databases and tables).
- Creating Lake Formation Tags and Making use of Lake Formation tags (LF-Tags) for tag-based entry management (TBAC).
Discover extra on dbt
Now that the deployment features a bdb4834-printed S3 bucket and a printed Catalog database, sturdy dbt fashions will be constructed for information transformation and curation.
Right here’s learn how to implement a whole dbt workflow:
- Begin by growing fashions that observe this sample:
- Learn from the formatted tables within the staging space
- Apply enterprise logic, joins, and aggregations
- Write clear, analysis-ready information to the printed schema
- Tagging for automation: Use constant dbt tags to allow automated DAG technology. These tags set off MWAA orchestration to robotically embrace new fashions within the execution pipeline.
- Including new fashions: When working with new datasets, confer with present fashions for steerage. Apply acceptable LF tags for information entry management. The brand new LF tags may also now be used for permissions.
- Allow DAG execution: For brand spanking new datasets, replace the MWAA metadata file to incorporate a new JSON entry. This step is critical to generate a DAG that executes the brand new dbt fashions.
This strategy ensures the dbt implementation scales systematically whereas sustaining automated orchestration and correct information governance.
Clear up
1. Open the S3 console and delete all objects from under buckets:
- bdb4834-raw-bucket-
– - bdb4834-formatted -bucket-
– - bdb4834-mwaa-bucket-
– - bdb4834-published-bucket-
–
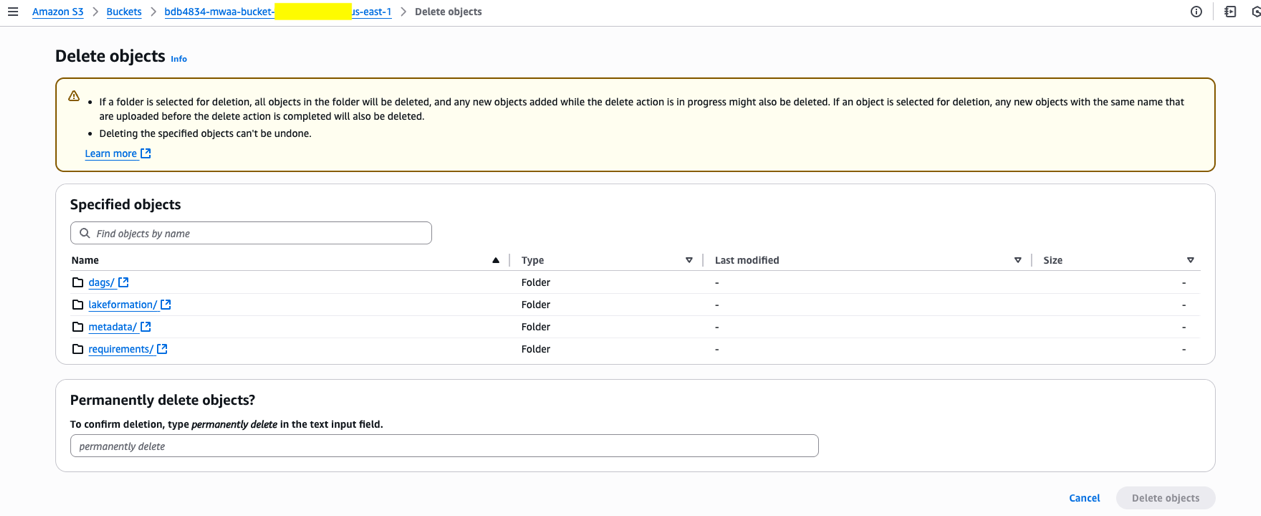
To delete all objects, select the bucket title, choose all objects and select Delete.
After that, sort ‘completely delete’ within the textual content field and select Delete Objects.
Do that for all three buckets talked about above.
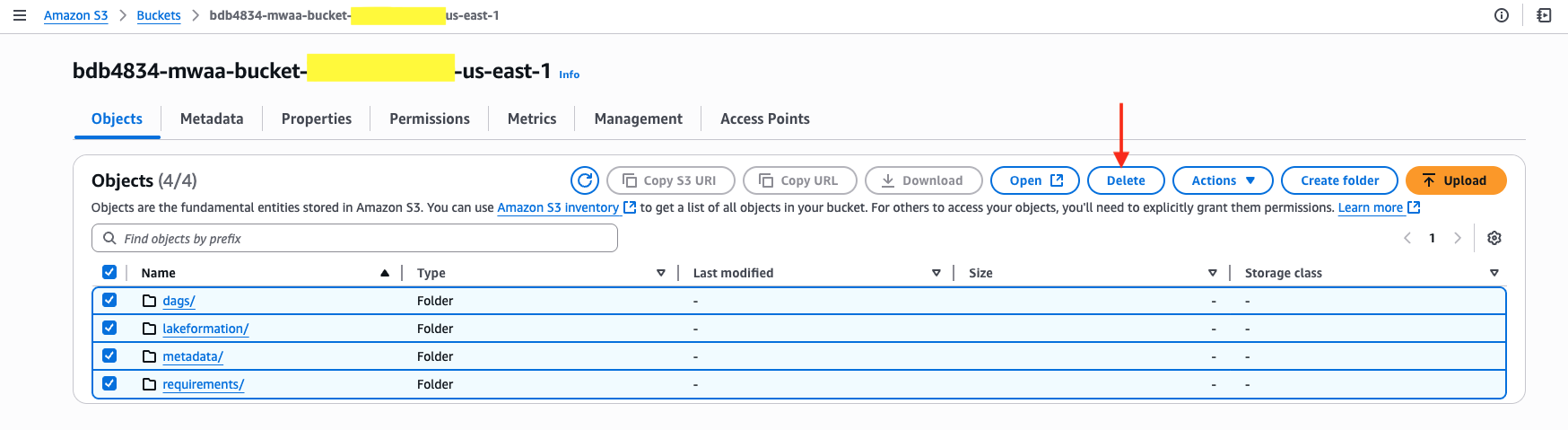
2. Go to the AWS Cloudformation console, select you’re the stack title and choose Delete. It could take roughly 40 minutes for the deletion to finish.
Suggestions
When utilizing dbt with MWAA, some typical challenges embrace employee useful resource exhaustion, dependency administration points, and in some uncommon instances, points like DAGs disappearing and re-appearing when there are numerous dynamic DAGs being created from a single python script.
To mitigate these points, observe these greatest practices:
1. Scale the MWAA setting appropriately by upgrading the setting class as required.
2. Use customized necessities.txt and correct dbt adapter configuration to make sure constant environments.
3. Set airflow configuration parameters to tune the efficiency of MWAA.
Conclusion
On this submit, we explored the end-to-end setup of a ruled information lake utilizing MWAA and dbt which improved information high quality, safety, and compliance, main to higher decision-making and elevated operational effectivity. We additionally lined learn how to construct customized dbt frameworks for auditing and information high quality, automate Lake Formation entry management, and dynamically generate MWAA DAGs based mostly on dbt tags. These capabilities allow a scalable, safe, and automatic information lake structure, streamlining information governance and orchestration.
For additional exploring, confer with From information lakes to insights: dbt adapter for Amazon Athena now supported in dbt Cloud
In regards to the authors

{kind=link}