

Predictive algorithms can now detect good dwelling failures earlier than they occur. Most methods at present solely spot points after they happen, which makes prevention not possible. The outdated reactive method is turning into outdated quicker.
Predictive upkeep machine studying offers a greater resolution than ready for units to fail. Householders can spot future issues with outstanding accuracy by analyzing patterns in historic knowledge, statistical algorithms, and machine studying strategies. Uncooked knowledge from sensors, vitality utilization metrics, and system info turns into helpful insights that assist make choices, lower dangers, and optimize efficiency.
A number of machine studying strategies excel at predicting {hardware} failures early. Classification, clustering, and prediction algorithms have proven nice outcomes. The LSTM (Lengthy Quick-Time period Reminiscence) mannequin stands above the remainder as a result of it excels at dealing with knowledge sequences and retains info longer. Sensible dwelling methods can forestall many points by recognizing patterns via these predictive upkeep algorithms.
This piece guides rookies via constructing a predictive algorithm for dwelling failures. You’ll study every little thing from understanding the core drawback to launching a working system.
Step 1: Perceive the Downside of Residence Failures
Sensible properties want predictive algorithms that may spot issues earlier than they occur. These algorithms should perceive what sometimes breaks down and why present upkeep strategies don’t catch these points early sufficient.
Widespread causes of good dwelling failures
Sensible dwelling methods can break down resulting from a number of distinct issues:
- Connectivity Points: Sensible dwelling house owners report unreliable Wi-Fi connections as their commonest drawback. Units typically present up as “offline,” take too lengthy to reply, or work inconsistently. Different units utilizing the identical frequency (2.4GHz or 5GHz) can considerably weaken alerts. Bodily objects like partitions and enormous furnishings additionally block these transmissions.
- Compatibility Challenges: Gadget connections typically create complications for householders. Sensible dwelling units use totally different protocols like Zigbee, Z-Wave, WiFi, and Bluetooth to speak. Units with totally different protocols can’t speak to one another. Producers’ proprietary requirements additionally make their units incompatible with different manufacturers.
- Energy Issues: Sensible units don’t work nicely with energy source-drain points. Safety cameras and different power-hungry home equipment use plenty of vitality. Too many units on one energy supply can overload it. Battery-powered units drain shortly with common use.
- Safety Vulnerabilities: Sensible dwelling units observe plenty of person knowledge, together with how individuals use them, their priorities, and recordings. Poor safety measures and weak passwords make it straightforward for others to manage these units. Attackers can intercept system communications if encryption isn’t robust sufficient.
- Automation Failures: Community issues, interference, or congestion can cease automated routines from working. Fallacious settings, system setup points, and poor timing can break automation triggers.
Why conventional methods fall quick
Conventional dwelling upkeep has an enormous flaw – it solely fixes issues after they break. This reactive method creates a number of issues:
Analysis exhibits that 89% of kit failures occur randomly and aren’t associated to age. This truth contradicts how schedule-based upkeep works, which assumes machines fail primarily based on their age. These pointless repairs find yourself costing extra money.
Producers lose about 800 hours every year due to downtime. Conventional upkeep can’t predict sudden failures, which results in this productiveness loss. Common upkeep schedules use previous knowledge to guess when repairs is likely to be wanted. This technique typically leads to an excessive amount of or too little upkeep since most breakdowns occur unexpectedly.
Cash turns into one other concern. Housing specialists counsel setting apart 1% of property worth yearly for repairs. But, a survey of three,000 UK householders confirmed they fall quick by 719.49 on common. Financial challenges make this worse. About 23% of UK householders skip necessary upkeep like yearly boiler checks. This results in void warranties, security dangers, and larger restore payments.
Conventional upkeep additionally misses alternatives to make use of good dwelling knowledge. With out correct evaluation, these methods can’t spot patterns that predict failures, discover small modifications in how units work, or inform regular variations from warning indicators.
Predictive upkeep algorithms remedy these issues by checking system circumstances on a regular basis. They analyze sensor knowledge about temperature, vibration, vitality use, and utilization patterns. This helps repair present points and predict future issues.
Step 2: Acquire and Arrange Sensible Residence Information
The muse of any predictive upkeep system begins with gathering acceptable knowledge after figuring out dwelling failures. Sensible dwelling environments want various, high-quality knowledge from a number of sources to create algorithms that may predict failures.
Kinds of knowledge wanted (sensor, system, utilization)
Three foremost classes of information energy profitable predictive upkeep algorithms:
Person-based options are important parts that present human actions and behaviors. These options observe when actions begin and finish, how lengthy they final, the place they occur, and which components of the house individuals use. The system learns regular utilization patterns by monitoring every day routines like showering, sleeping, breakfast, leaving, toileting, dinner and different actions.
Equipment options make up the second important knowledge class. These options observe system IDs, utilization patterns (begin/finish occasions and period), vitality consumption metrics, and associated vitality prices. The system spots potential failures by expecting uncommon equipment conduct. Analysis exhibits that detailed utilization metrics assist detect indicators of damage and tear months earlier than units truly fail.
Environmental knowledge makes up the third important class and covers circumstances inside and outdoors that have an effect on how units work and final. The primary environmental components embody:
- Temperature readings (ambient and device-specific)
- Humidity ranges all through the house
- Air high quality measurements
- Illumination ranges
These environmental parts enormously have an effect on how nicely units work and the way dependable they’re. Duke Power’s knowledge analytics system processes over 85 billion knowledge factors yearly from their grid sensors to schedule upkeep on the proper time.
IoT-enabled units collect operational knowledge together with machine speeds and steps. This knowledge helps classify several types of stops or failures after processing. Sensors like present sensors (ACS712), voltage sensors (ZMPT101B), temperature sensors (DS18B20), and light-dependent resistors (LDR) present rapid operational insights via their readings.
Establishing knowledge pipelines from IoT units
A structured method helps deal with the fixed circulation of data from a number of units when constructing robust knowledge pipelines.
IoT sensors act because the system’s eyes and ears and generate terabytes of information that want environment friendly processing. Excessive-throughput knowledge pipelines depend on centralized message brokers like Apache Kafka or Apache Pulsar. These brokers can deal with tens of millions of occasions per second from IoT sensors and machines.
The system cleans, normalizes, and standardizes collected knowledge via preprocessing phases. This course of fixes lacking values, removes outliers, and converts every little thing to constant codecs. Most methods break up their dataset into coaching and testing units – often 80-20 – to test how nicely the mannequin works with new knowledge.
Azure Time Collection Insights provides nice options for rapid evaluation of time-series knowledge. This platform makes use of multi-layered storage with each heat storage (latest knowledge as much as 31 days) and chilly storage (long-term archives) that works nicely with time-series IoT-scale knowledge.
A whole knowledge pipeline structure wants:
- Information ingestion layer with IoT sensors and communication protocols
- Message dealer for dependable knowledge transmission (Kafka/Pulsar)
- Information processing part for standardization and enrichment
- Storage options optimized for time-series knowledge
- Analytics platforms for rapid monitoring and prediction
The system combines IoT sensor knowledge with operational knowledge like system info and utilization historical past to create full datasets for predictive evaluation. Effectively-structured knowledge pipelines assist monitor crucial parameters in real-time whereas constructing historic datasets wanted to coach predictive fashions.
Step 3: Put together the Information for Machine Studying
Sensible dwelling knowledge wants correct preparation to construct predictive algorithms that may forecast dwelling failures. Uncooked knowledge has errors and inconsistencies. Machine studying fashions want structured knowledge to seek out significant patterns.
Cleansing and formatting the info
IoT knowledge typically comprises anomalies that may have an effect on how nicely fashions work. Temperature sensors generally document implausible spikes of 1000’s of levels. These readings would counsel the home burned down in the event that they have been actual. Energy fluctuations trigger these spikes when analog voltage outputs briefly present unrealistic excessive values.
A well-laid-out template standardizes knowledge. This offers consistency in knowledge sources, no matter parts run in background methods. The standardized knowledge will get enriched with lacking particulars, transformed to particular codecs, or tailored as wanted.
Gadget specs and bodily limits assist set affordable thresholds. Values past these thresholds want marking as outliers. Whereas automation helps, human checks guarantee accuracy.
Dealing with lacking or inconsistent values
IoT environments face an enormous problem with lacking knowledge. The explanations range:
- Unstable community communications
- Synchronization issues
- Unreliable sensor units
- Environmental components
- Gadget malfunctions
These gaps harm reliability and fast choices. Healthcare, industrial settings, and good cities really feel these results essentially the most.
Lacking knowledge is available in three sorts:
- Lacking Fully at Random (MCAR) – No connection exists between lacking values and dataset
- Lacking at Random (MAR) – Lacking values hyperlink to noticed knowledge however not lacking knowledge
- Lacking Not at Random (MNAR) – Lacking values instantly relate to what’s lacking
Completely different imputation strategies repair these points. Analysis exhibits BFMVI (Bayesian Framework for A number of Variable Imputation) works higher than outdated strategies. It achieved an RMSE of simply 0.011758 at 10% lacking price whereas KNN scored 0.941595.
Different dependable strategies embody:
- Imply/median imputation for MCAR knowledge
- Regression imputation for structured relationships
- Random Forest strategies for complicated datasets
- Ok-Nearest Neighbors for characteristic similarities
Characteristic engineering for time-series knowledge
Characteristic engineering turns uncooked time sequence knowledge into helpful inputs. These inputs seize complicated patterns and relationships that make predictions extra correct. Conventional strategies like ARIMA can battle with outliers. Characteristic engineering provides higher flexibility and reliability.
Sensible dwelling knowledge advantages from time-based options extracted from timestamps. Hour of day, day of week, and vacation indicators assist fashions spot patterns in dwelling utilization and circumstances.
Three key strategies form time-series characteristic engineering:
Lag options use previous values to foretell higher. They work nice for short-term patterns and cycles in system conduct.
Rolling window statistics like transferring averages clean out noise and present traits. These stats adapt to altering patterns and catch uncommon conduct by sliding home windows of information.
Fourier transforms break down time sequence into frequency components. This reveals patterns which may disguise in common time views. Residence system utilization patterns change into clearer.
Actual examples present how nicely these preparation strategies work. Resorts, very similar to properties, present robust hyperlinks between CO2 and room energy use (correlation coefficient: 0.430153). Humidity (0.380577) and advantageous mud (0.321560) additionally present notable connections.
Step 4: Select the Proper Predictive Algorithm
The life-blood of any good dwelling failure prediction system lies in choosing the right predictive algorithms. When you’ve ready your knowledge, you could select algorithms that match your upkeep challenges.
Overview of predictive upkeep algorithms
Predictive upkeep algorithms search for patterns in previous knowledge to forecast gear failures. These algorithms make it easier to take motion primarily based on precise system circumstances as a substitute of mounted schedules, not like reactive or scheduled upkeep approaches.
These algorithms purpose to hyperlink collected knowledge with attainable failures with out utilizing degradation fashions. This technique has change into extra well-liked as a result of it really works nicely with complicated good dwelling methods and gear.
Most predictive upkeep algorithms match into three classes:
- Statistical strategies – Conventional approaches like regression evaluation that discover linear relationships between variables
- Machine studying strategies – Superior algorithms that discover complicated patterns and adapt to new knowledge
- Deep studying fashions – Refined neural networks that work finest with sequential or time-series knowledge from good units
Analysis exhibits that XGBoost, Synthetic Neural Networks, and Deep Neural Networks have proven the perfect leads to fault diagnostics and system optimization amongst machine studying strategies.
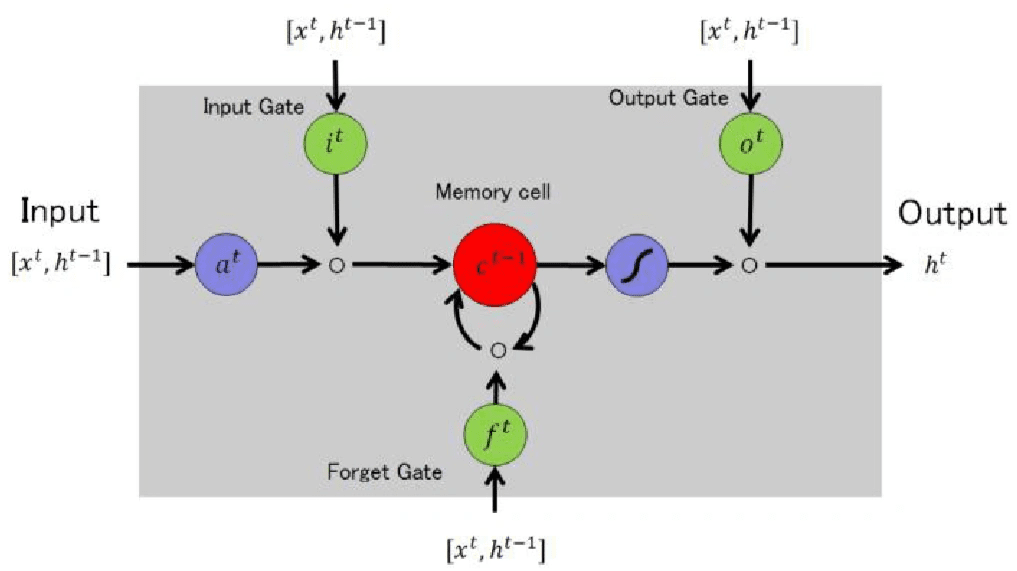
Why LSTM is efficient for time-based predictions
Lengthy Quick-Time period Reminiscence (LSTM) networks stand out at predicting dwelling failures. These specialised recurrent neural networks excel at recognizing long-term patterns in sequential knowledge, making them excellent for good dwelling sensor knowledge evaluation.
LSTM provides three key benefits over conventional algorithms:
LSTM networks have reminiscence cells that retailer info for lengthy durations. These cells can “bear in mind” important occasions or patterns from a lot earlier in a sequence. This characteristic turns into important whenever you analyze system efficiency over weeks or months.
The fashions course of knowledge in sequence and protect time relationships between observations. This makes them glorious at dealing with time-series knowledge from good properties, the place occasion timing typically holds priceless predictive clues.
Particular gates in LSTMs management info circulation. They will select what to recollect or overlook, which helps them give attention to related patterns whereas filtering noise. This selective reminiscence makes them splendid for dealing with complicated, noisy good dwelling knowledge.
Different predictive algorithms examples
A number of different algorithms work nicely for predicting good dwelling failures:
XGBoost boosts prediction accuracy by discovering hidden knowledge correlations. It achieved 98% accuracy in predicting system failures when used with Zigbee-enabled good dwelling networks. Research present XGBoost performs higher than many different algorithms for IoT-based good dwelling community fault detection.
Random Forest creates a number of choice bushes throughout coaching and averages their forecasts. This group method reduces equipment downtime by grouping units into well being states primarily based on utilization hours, temperature, and energy consumption patterns.
Help Vector Machines (SVM) excel at recognizing variations between working home equipment and people needing upkeep. SVM handles complicated, high-dimensional knowledge with non-linear characteristic correlations nicely.
Convolutional Neural Networks (CNN) extract options from enter sequences successfully. Groups typically mix CNNs with LSTM to spice up sample recognition in system efficiency knowledge.
ARIMA works nicely with time-dependent knowledge to foretell equipment breakdowns or upkeep wants. It spots traits, seasonal patterns, and weird conduct in equipment utilization and vitality consumption.
Analysis exhibits combining a number of algorithms typically provides higher outcomes. To call only one instance, mixing XGBoost with Firefly Optimization helps create fault identification algorithms that present fast, correct forecasts. This mixture helps repair points quicker and retains good dwelling gear operating easily.
Step 5: Practice and Consider Your Mannequin
The crucial bridge between uncooked knowledge evaluation and a practical system lies in coaching and evaluating your predictive algorithm. You have to practice your algorithms to identify patterns that may predict dwelling system failures after you choose them.
Splitting knowledge into coaching and take a look at units
The correct dataset division helps keep away from deceptive efficiency assessments. Information scientists sometimes break up their knowledge into two or three distinct units. Most implementations use an 80-20 break up, with 80% going to coaching and 20% to testing. All the identical, you may wish to suppose over a three-way break up to get a full image:
- Coaching set: 60-80% of information used to coach the mannequin
- Validation set: Used to tune hyperparameters and run preliminary assessments
- Take a look at set: 20-40% saved solely to judge the ultimate mannequin
This setup protects your analysis’s integrity by retaining take a look at knowledge untouched all through growth. Cross-validation offers an alternate technique that divides coaching knowledge into a number of “folds” which change between coaching and validation roles. This method works finest particularly when you will have smaller datasets as a result of it makes essentially the most of accessible knowledge.
Utilizing metrics like accuracy and F1-score
Binary classification issues (functioning vs. failing units) want a number of metrics to offer significant analysis:
Accuracy alone will be misleading. A dataset with simply 1% failure circumstances would let a mannequin that all the time predicts “no failure” attain 99% accuracy. These metrics give a greater image:
- Sensitivity/Recall: Proportion of precise failures appropriately recognized
- Precision: Proportion of predicted failures that have been precise failures
- F1-score: Harmonic imply between precision and recall, splendid for imbalanced datasets
Regression duties that predict time-to-failure use totally different metrics:
- MAE: Absolute distinction between predictions and precise values
- RMSE: Sq. root of common squared errors, penalizing bigger errors
- R-squared: Exhibits how a lot variance the mannequin explains
Avoiding overfitting and underfitting
Fashions must work nicely past their coaching knowledge. Overfitting occurs when fashions excel with coaching knowledge however battle with new examples. Right here’s the right way to forestall this:
- Use regularization strategies to restrict mannequin complexity
- Add dropout layers that randomly ignore neurons throughout coaching to stop over-dependence on particular options
- Apply early stopping by watching validation loss and saving the mannequin earlier than efficiency drops
Batch normalization makes coaching extra secure and quicker by normalizing layer outputs. Dropout layers forestall fashions from relying too closely on particular neurons. A sensible resolution entails monitoring the validation accuracy curve till it ranges off or begins to say no.
Switch studying offers one other resolution that’s nice for inadequate failure knowledge. Analysis exhibits that data from one kind of failure can enhance prediction efficiency by so much for different failure sorts with restricted knowledge.
Step 6: Deploy and Monitor the Prediction System
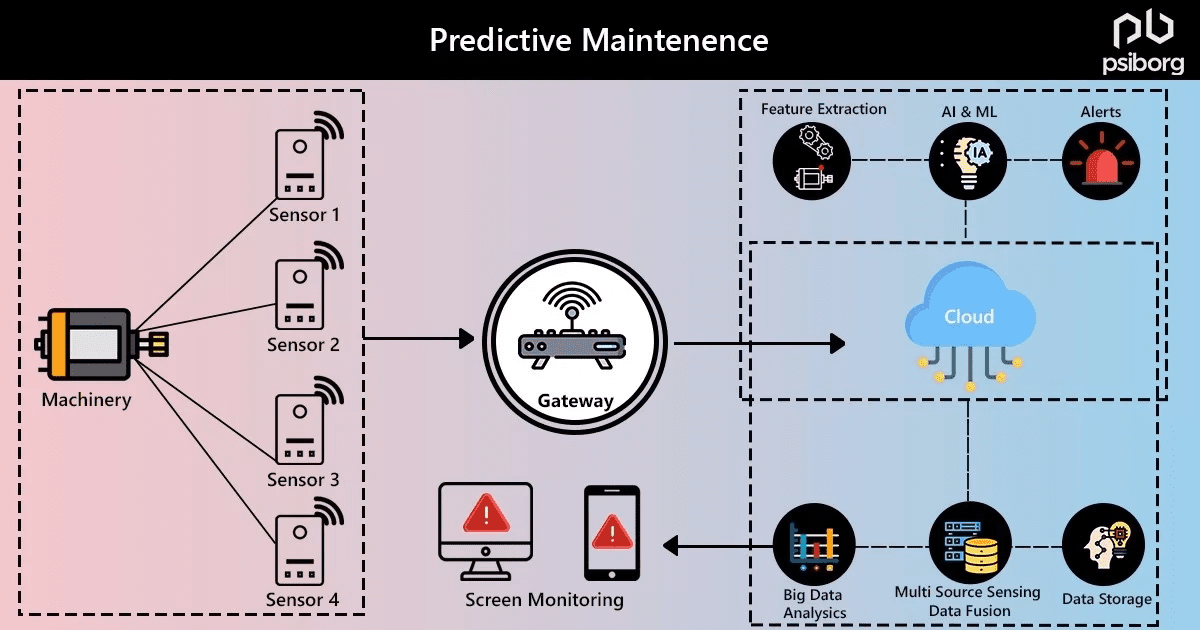
Picture Supply: CRMatrix
Your predictive upkeep work reaches its peak whenever you deploy the skilled mannequin right into a system that householders can use. This last step turns theoretical algorithms into sensible instruments that forestall dwelling system failures.
Integrating the mannequin into a sensible dwelling dashboard
Platforms like JHipster construct full internet purposes with Java backends, Spring frameworks, and interactive interfaces that collect predictions from fashions of all kinds. Visible dashboards act as command facilities the place householders test system standing, observe predictions, and do the work wanted. Good dashboards present a number of views – from detailed system knowledge to complete overviews of linked methods and their failure possibilities. These interfaces ought to present explainable AI interpretations to assist customers grasp why predictions occur, which results in higher choices.
Stay prediction and alerting
The deployed system watches incoming knowledge from dwelling units and flags points immediately. Alerts exit as push notifications, texts, or emails to smartphones when the system spots particular occasions. Customers get prompt updates about their dwelling’s standing and may reply quick – calling authorities, triggering alarms, or utilizing two-way audio methods. Trendy safety methods mix easily with different good units and may set off automated responses, similar to turning on lights when cameras detect movement.
Updating fashions with new knowledge
Prediction fashions want updates to remain correct. You may select from 4 methods: hold the unique mannequin, retrain with out altering hyperparameters, do a full retrain, or make incremental updates. Finest practices counsel updating fashions after main modifications: when efficiency drops, knowledge grows by about 30%, after massive buyer modifications, or each six months. Gadget danger scores may change after updates because the mannequin learns new patterns.
Conclusion
Predictive algorithms for dwelling failures mark a significant step ahead in comparison with old-school upkeep strategies. This piece explores how good dwelling methods can spot potential system failures earlier than they occur and save householders cash, time, and trouble.
The six-step course of turns newcomers into succesful builders of dwelling predictive upkeep methods. A strong grasp of frequent failure mechanisms and reactive upkeep limitations builds a powerful basis for higher options. Information assortment and preparation create the core of any prediction system that works, regardless of their challenges. Good characteristic engineering makes time-series knowledge patterns simpler for algorithms to acknowledge.
Selecting the best algorithm stands as essentially the most essential growth choice. LSTM networks work notably nicely with time-based dwelling knowledge due to their reminiscence capabilities and sequential processing strengths. XGBoost, Random Forest, and hybrid approaches are nice options that match particular wants.
Coaching and analysis want cautious consideration to catch actual system conduct patterns with out overfitting. These methods study from new knowledge after deployment and change into extra correct as time passes.
Householders who use predictive upkeep algorithms have clear benefits over conventional strategies. They face fewer shock breakdowns and repair interruptions. On high of that, upkeep prices drop when issues are mounted earlier than main harm happens. The system helps units last more via well timed fixes primarily based on actual circumstances as a substitute of mounted schedules.
Sensible dwelling know-how modifications quicker every day, which makes predictive upkeep out there to extra customers. Future methods will spot complicated failure patterns throughout linked dwelling units even higher. Householders who undertake these applied sciences now will no doubt get pleasure from safer, extra dependable, and environment friendly properties over the following a number of years.
FAQs
1. What are the important thing steps in growing a predictive algorithm for dwelling failures?
The important thing steps embody understanding the issue, gathering and organizing good dwelling knowledge, making ready the info for machine studying, selecting the best predictive algorithm, coaching and evaluating the mannequin, and at last deploying and monitoring the prediction system.
2. Which kinds of knowledge are important for predicting dwelling failures?
Important knowledge sorts embody user-based options (like exercise patterns), equipment options (similar to utilization and vitality consumption), and environmental knowledge (together with temperature, humidity, and air high quality measurements).
3. Why is LSTM notably efficient for predicting dwelling failures?
LSTM (Lengthy Quick-Time period Reminiscence) networks are efficient as a result of they’ll seize long-term dependencies in sequential knowledge, course of info sequentially, and selectively bear in mind or overlook info. This makes them splendid for analyzing time-series knowledge from good dwelling sensors.
4. How can overfitting be prevented when coaching a predictive mannequin?
Overfitting will be prevented by utilizing strategies similar to regularization, implementing dropout layers, making use of early stopping, and utilizing batch normalization. Monitoring the validation accuracy curve and stopping coaching when it plateaus or declines can also be an efficient method.
5. What are the advantages of implementing a predictive upkeep system for good properties?
Implementing a predictive upkeep system for good properties can result in fewer surprising breakdowns, diminished upkeep prices, prolonged system lifespans, and general improved effectivity and reliability of dwelling methods. It permits for well timed interventions primarily based on precise system circumstances reasonably than arbitrary schedules.

{kind=link}