Organizations should typically take care of an unlimited array of knowledge codecs and sources of their knowledge analytics workloads. This vary of knowledge sorts, corresponding to structured relational knowledge, semi-structured codecs like JSON and XML and even binary codecs like Protobuf and Avro, has introduced new challenges for firms seeking to extract helpful insights.
Protocol Buffers (protobuf) has gained important traction in industries that require environment friendly knowledge serialization and transmission, significantly in streaming knowledge situations. Protobuf’s compact binary illustration, language-agnostic nature, and powerful typing make it a sexy selection for firms in sectors corresponding to finance, gaming, telecommunications, and ecommerce, the place high-throughput and low-latency knowledge processing is essential.
Though protobuf affords benefits in environment friendly knowledge serialization and transmission, its binary nature poses challenges in relation to analytics use circumstances. In contrast to codecs like JSON or XML, which will be straight queried and analyzed, protobuf knowledge requires a further deserialization step to transform it from its compact binary format right into a construction appropriate for processing and evaluation. This additional conversion step introduces complexity into knowledge analytics pipelines and instruments. It could actually probably decelerate knowledge exploration and evaluation, particularly in situations the place close to real-time insights are essential.
On this submit, we discover an end-to-end analytics workload for streaming protobuf knowledge, by showcasing easy methods to deal with these knowledge streams with Amazon Redshift Streaming Ingestion, deserializing and processing them utilizing AWS Lambda capabilities, in order that the incoming streams are instantly obtainable for querying and analytical processing on Amazon Redshift.
The answer supplies a stable basis for dealing with protobuf knowledge in Amazon Redshift. You’ll be able to additional improve the structure to assist schema evolution by incorporating AWS Glue Schema Registry. By integrating the AWS Glue Schema Registry, you can also make positive your Lambda perform makes use of the most recent schema model for deserialization, whilst your knowledge construction adjustments over time. Nonetheless, for the aim of this submit and to keep up simplicity, we deal with demonstrating easy methods to invoke Lambda from Amazon Redshift to transform protobuf messages to JSON format, which serves as a stable basis for dealing with binary knowledge in close to real-time analytics situations.
Answer overview
The next structure diagram describes the AWS companies and options wanted to arrange a totally useful protobuf streaming ingestion pipeline for close to real-time analytics.
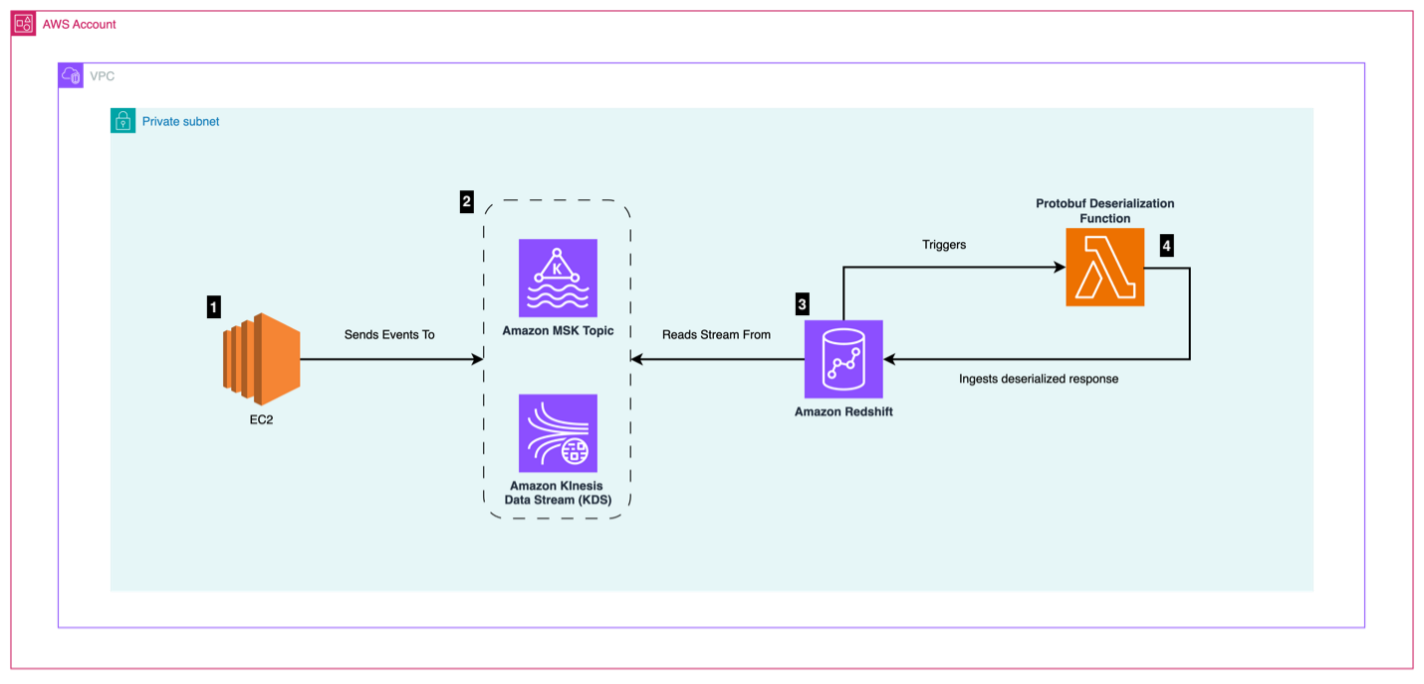
The workflow consists of the next steps:
- An Amazon Elastic Compute Cloud (Amazon EC2) occasion producer generates occasions and forwards them to a message queue. The occasions are created and serialized utilizing protobuf.
- A message queue utilizing Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis accepts the protobuf messages despatched by the occasion producer. For this submit, we use Amazon MSK Serverless.
- A Redshift cluster (provisioned or serverless), wherein a materialized view with an exterior schema is configured, factors to the message queue. For this submit, we use Amazon Redshift Serverless.
- A Lambda protobuf deserialization perform is triggered by Amazon Redshift throughout ingestion and deserializes protobuf knowledge into JSON knowledge.
Schema
To showcase protobuf’s deserialization performance, we use a pattern protobuf schema that represents a monetary commerce transaction. This schema might be used throughout the AWS companies talked about on this submit.
// commerce.proto
syntax = "proto3";
message Commerce{
int32 userId = 1;
string userName = 2;
int32 quantity = 3;
int32 pair = 4;
int32 motion = 5;
string TimeStamp = 6;
}
Amazon Redshift materialized view
To ensure that Amazon Redshift to ingest streaming knowledge from Amazon MSK or Kinesis, an applicable function must be assigned to Amazon Redshift and a materialized view must be correctly outlined. For detailed directions on easy methods to accomplish this, seek advice from Streaming ingestion to a materialized view or Simplify knowledge streaming ingestion for analytics utilizing Amazon MSK and Amazon Redshift.
On this part, we deal with the materialized view definition that makes it doable to deserialize protobuf knowledge. Our instance focuses on streaming ingestion from Amazon MSK. Usually, the materialized view ingests the Kafka metadata fields and the precise knowledge (kafka_value) like within the following instance:
CREATE MATERIALIZED VIEW trade_events AUTO REFRESH YES AS
SELECT
kafka_partition,
kafka_offset,
kafka_timestamp_type,
kafka_timestamp,
kafka_key,
JSON_PARSE(kafka_value) as Information,
kafka_headers
FROM
"dev"."msk_external_schema"."entity"
WHERE
CAN_JSON_PARSE(kafka_value)
When the incoming kafka_value is of sort JSON, you’ll be able to apply the built-in JSON_PARSE perform and create a column of sort SUPER so you’ll be able to straight question the information.
Amazon Redshift Lambda user-defined perform
In our case, accepting protobuf encoded knowledge requires some further steps. Step one is to create an Amazon Redshift Lambda user-defined perform (UDF). This Amazon Redshift perform is the hyperlink to a Lambda perform that executes the precise deserialization. This fashion, when knowledge is ingested, Amazon Redshift calls the Lambda perform for deserialization.
Creating or updating our Amazon Redshift Lambda UDF is simple, as illustrated within the following code. Extra examples can be found within the GitHub repo.
CREATE OR REPLACE EXTERNAL FUNCTION f_deserialize_protobuf(VARCHAR(MAX))
RETURNS VARCHAR(MAX) IMMUTABLE
LAMBDA 'f-redshift-deserialize-protobuf' IAM_ROLE ':RedshiftRole';
As a result of Lambda capabilities don’t (on the time of writing) settle for binary knowledge as enter, you could first convert incoming binary knowledge to its hex illustration, previous to calling the perform. You are able to do this through the use of the TO_HEX Amazon Redshift perform.
Contemplating the hex dialog and with the Lambda UDF obtainable, now you can use it in your materialized view definition:
CREATE MATERIALIZED VIEW trade_events AUTO REFRESH YES AS
SELECT
kafka_partition,
kafka_offset,
kafka_timestamp_type,
kafka_timestamp,
kafka_key,
kafka_value,
kafka_headers,
JSON_PARSE(f_deserialize_protobuf(to_hex(kafka_value)))::tremendous as json_data
FROM
"dev"."msk_external_schema"."entity";
Lambda layer
Lambda capabilities require entry to applicable protobuf libraries, in order that deserialization can happen. You’ll be able to implement this by a Lambda layer. The layer is offered as a zipper file, respecting the next folder construction, and accommodates the protobuf library, its dependencies, and user-provided code contained in the customized folder, which incorporates the protobuf generated lessons:
python
customized
google
Protobuf-4.25.2.dist-info
As a result of we carried out the Lambda capabilities in Python, the foundation folder of the zip file is the python folder. For extra languages, seek advice from the documentation on easy methods to correctly construction your folder construction.
Lambda perform
A Lambda perform converts incoming protobuf data to JSON data. As a primary step, you could import your customized lessons from the lambda Layer customized folder:
# Import generated protobuf lessons
from customized import trade_pb2
Now you can deserialize incoming hex encoded binary knowledge to things. That is carried out in a two-step course of. Step one is to decode the hex encoded binary knowledge:
# convert incoming hex knowledge to binary
binary_data = bytes.fromhex(document)
Subsequent, you instantiate the protobuf outlined lessons and execute the precise deserialization course of utilizing the protobuf library technique ParseFromString:
# Instantiate class
trade_event = trade_pb2.Commerce()
# Deserialize into class
trade_event.ParseFromString(binary_data)
After you run deserialization and instantiate your objects, you’ll be able to convert to different codecs. In our case, we serialize into JSON format, in order that Amazon Redshift ingests the JSON content material in a single discipline of sort SUPER:
# Serialize into json
elems = trade_event.ListFields()
fields = {}
for elem in elems:
fields[elem[0].title] = elem[1]
json_elem = json.dumps(fields)
Combining these steps collectively, the Lambda perform ought to look as follows:
import json
# Import the generated protobuf lessons
from customized import trade_pb2
def lambda_handler(occasion, context):
outcomes = []
recordSets = occasion['arguments']
for recordSet in recordSets:
for document in recordSet:
# convert incoming hex knowledge to binary knowledge
binary_data = bytes.fromhex(document)
# Instantiate class
trade_event = trade_pb2.Commerce()
# Deserialize into class
trade_event.ParseFromString(binary_data)
# Serialize into json
elems = trade_event.ListFields()
fields = {}
for elem in elems:
fields[elem[0].title] = elem[1]
json_elem = json.dumps(fields)
# Append to outcomes
outcomes.append(json_elem)
print('OK')
return json.dumps({"success": True,"num_records": len(outcomes),"outcomes": outcomes})
Batch mode
Within the previous code pattern, Amazon Redshift is looking our perform in batch mode, that means that a variety of data are despatched throughout a single Lambda perform name. Extra particularly, Amazon Redshift is batching data into the arguments property of the request. Subsequently, you could loop by the incoming array of knowledge and apply your deserialization logic per document. On the time of writing, this conduct is inner to Amazon Redshift and might’t be configured or managed by a configuration possibility. An Amazon Redshift streaming client consumer will learn new data on the message queue for the reason that final time it learn. The next is a pattern of the payload the Lambda handler perform receives:
"consumer": "IAMR:Admin",
"cluster": "arn:aws:redshift:*********************************",
"database": "dev",
"external_function": "fn_lambda_protobuf_to_json",
"query_id": 5583858,
"request_id": "17955ee8-4637-42e6-897c-5f4881db1df5",
"arguments": [
[
"088a1112087374723a3231383618c806200128093217323032342d30332d32302031303a34363a33382e363932" ], [ "08a74312087374723a3836313518f83c200728093217323032342d30332d32302031303a34363a33382e393031" ], [ "08b01e12087374723a3338383818f73d20f8ffffffffffffffff0128053217323032342d30332d32302031303a34363a33392e303134"
]
],
"num_records":3
}
Insights from ingested knowledge
Along with your knowledge saved in Amazon Redshift after the deserialization course of, now you can execute queries in opposition to your streaming knowledge and straight acquire insights. On this part, we current some pattern queries as an instance performance and conduct.
Look at lag question
To look at the distinction between the newest timestamp worth of our streaming supply vs. the present date/time (wall clock), we calculate the newest time limit at which we ingested knowledge. As a result of streaming knowledge is predicted to movement into the system constantly, this metric additionally reveals the ingestion lag between our streaming supply and Amazon Redshift.
choose high 1
(GETDATE() - kafka_timestamp) as ingestion_lag
from
trade_events
order by
kafka_timestamp desc
Look at content material question: Fraud detection on an incoming stream
By making use of the question performance obtainable in Amazon Redshift, we will uncover conduct hidden in our knowledge in actual time. With the next question, we attempt to match reverse commerce volumes performed by completely different customers over the past 5 minutes that lead to a zero sum sport and will assist a possible fraud detection idea:
choose
json_data.quantity,
LISTAGG(json_data.userid::int, ', ') as customers,
LISTAGG(json_data.pair::int, ', ') as pairs
from
trade_events
the place
trade_events.kafka_timestamp >= DATEADD(minute, -5, GETDATE())
group by
json_data.quantity
having
sum(json_data.pair) = 0
and min(abs(json_data.pair)) = max(abs(json_data.pair))
and depend(json_data.pair) > 1
This question is a rudimentary instance of how we will use stay knowledge to guard methods from fraudsters.
For a extra complete instance, see Close to-real-time fraud detection utilizing Amazon Redshift Streaming Ingestion with Amazon Kinesis Information Streams and Amazon Redshift ML. On this use case, an Amazon Redshift ML mannequin for anomaly detection is skilled utilizing the incoming Amazon Kinesis Information Streams knowledge that’s streamed into Amazon Redshift. After enough coaching (for instance, 90% accuracy for the mannequin is achieved), the skilled mannequin is put into inference mode for inferencing choices on the identical incoming bank card knowledge.
Look at content material question: Be a part of with non-streaming knowledge
Having our protobuf data streaming in Amazon Redshift makes it doable to hitch streaming with non-streaming knowledge. A typical instance is combining incoming trades with consumer info knowledge already recorded within the system. Within the following question, we be a part of the incoming stream of trades with consumer info, like electronic mail, to get a listing of doable alerts targets:
choose
user_info.electronic mail
from
trade_events
inside be a part of
user_info
on user_info.userId = trade_events.json_data.userid
the place
trade_events.json_data.quantity > 1000
and trade_events.kafka_timestamp >= DATEADD(minute, -5, GETDATE())
Conclusion
The flexibility to successfully analyze and derive insights from knowledge streams, no matter their format, is essential for knowledge analytics. Though protobuf affords compelling benefits for environment friendly knowledge serialization and transmission, its binary nature can pose challenges and maybe influence efficiency in relation to analytics workloads. The answer outlined on this submit supplies a sturdy and scalable framework for organizations in search of to achieve helpful insights, detect anomalies, and make data-driven choices with agility, even in situations the place high-throughput and low-latency processing is essential. By utilizing Amazon Redshift Streaming Ingestion together with Lambda capabilities, organizations can seamlessly ingest, deserialize, and question protobuf knowledge streams, enabling close to real-time evaluation and insights.
For extra details about Amazon Redshift Streaming Ingestion, seek advice from Streaming ingestion to a materialized view.
Concerning the authors
 Konstantinos Tzouvanas is a Senior Enterprise Architect on AWS, specializing in knowledge science and AI/ML. He has intensive expertise in optimizing real-time decision-making in Excessive-Frequency Buying and selling (HFT) and making use of machine studying to genomics analysis. Recognized for leveraging generative AI and superior analytics, he delivers sensible, impactful options throughout industries.
Konstantinos Tzouvanas is a Senior Enterprise Architect on AWS, specializing in knowledge science and AI/ML. He has intensive expertise in optimizing real-time decision-making in Excessive-Frequency Buying and selling (HFT) and making use of machine studying to genomics analysis. Recognized for leveraging generative AI and superior analytics, he delivers sensible, impactful options throughout industries.
 Marios Parthenios is a Senior Options Architect working with Small and Medium Companies throughout Central and Japanese Europe. He empowers organizations to construct and scale their cloud options with a selected deal with Information Analytics and Generative AI workloads. He permits companies to harness the facility of knowledge and synthetic intelligence to drive innovation and digital transformation.
Marios Parthenios is a Senior Options Architect working with Small and Medium Companies throughout Central and Japanese Europe. He empowers organizations to construct and scale their cloud options with a selected deal with Information Analytics and Generative AI workloads. He permits companies to harness the facility of knowledge and synthetic intelligence to drive innovation and digital transformation.
 Pavlos Kaimakis is a Senior Options Architect at AWS who helps prospects design and implement business-critical options. With intensive expertise in product improvement and buyer assist, he focuses on delivering scalable architectures that drive enterprise worth. Exterior of labor, Pavlos is an avid traveler who enjoys exploring new locations and cultures.
Pavlos Kaimakis is a Senior Options Architect at AWS who helps prospects design and implement business-critical options. With intensive expertise in product improvement and buyer assist, he focuses on delivering scalable architectures that drive enterprise worth. Exterior of labor, Pavlos is an avid traveler who enjoys exploring new locations and cultures.
 John Mousa is a Senior Options Architect at AWS. He helps energy and utilities and healthcare and life sciences prospects as a part of the regulated industries workforce in Germany. John has curiosity within the areas of service integration, microservices architectures, in addition to analytics and knowledge lakes. Exterior of labor, he likes to spend time along with his household and play video video games.
John Mousa is a Senior Options Architect at AWS. He helps energy and utilities and healthcare and life sciences prospects as a part of the regulated industries workforce in Germany. John has curiosity within the areas of service integration, microservices architectures, in addition to analytics and knowledge lakes. Exterior of labor, he likes to spend time along with his household and play video video games.


{kind=link}