
TL;DR
LLM-as-a-Choose methods may be fooled by confident-sounding however mistaken solutions, giving groups false confidence of their fashions. We constructed a human-labeled dataset and used our open-source framework syftr to systematically check decide configurations. The outcomes? They’re within the full publish. However right here’s the takeaway: don’t simply belief your decide — check it.
After we shifted to self-hosted open-source fashions for our agentic retrieval-augmented technology (RAG) framework, we have been thrilled by the preliminary outcomes. On robust benchmarks like FinanceBench, our methods appeared to ship breakthrough accuracy.
That pleasure lasted proper up till we regarded nearer at how our LLM-as-a-Choose system was grading the solutions.
The reality: our new judges have been being fooled.
A RAG system, unable to search out knowledge to compute a monetary metric, would merely clarify that it couldn’t discover the knowledge.
The decide would reward this plausible-sounding clarification with full credit score, concluding the system had accurately recognized the absence of information. That single flaw was skewing outcomes by 10–20% — sufficient to make a mediocre system look state-of-the-art.
Which raised a important query: should you can’t belief the decide, how are you going to belief the outcomes?
Your LLM decide may be mendacity to you, and also you gained’t know except you rigorously check it. One of the best decide isn’t all the time the most important or most costly.
With the proper knowledge and instruments, nonetheless, you may construct one which’s cheaper, extra correct, and extra reliable than gpt-4o-mini. On this analysis deep dive, we present you the way.
Why LLM judges fail
The problem we uncovered went far past a easy bug. Evaluating generated content material is inherently nuanced, and LLM judges are susceptible to refined however consequential failures.
Our preliminary difficulty was a textbook case of a decide being swayed by confident-sounding reasoning. For instance, in a single analysis a couple of household tree, the decide concluded:
“The generated reply is related and accurately identifies that there’s inadequate data to find out the precise cousin… Whereas the reference reply lists names, the generated reply’s conclusion aligns with the reasoning that the query lacks crucial knowledge.”
In actuality, the knowledge was out there — the RAG system simply didn’t retrieve it. The decide was fooled by the authoritative tone of the response.
Digging deeper, we discovered different challenges:
- Numerical ambiguity: Is a solution of three.9% “shut sufficient” to three.8%? Judges usually lack the context to resolve.
- Semantic equivalence: Is “APAC” an appropriate substitute for “Asia-Pacific: India, Japan, Malaysia, Philippines, Australia”?
- Defective references: Generally the “floor fact” reply itself is mistaken, leaving the decide in a paradox.
These failures underscore a key lesson: merely selecting a strong LLM and asking it to grade isn’t sufficient. Good settlement between judges, human or machine, is unattainable and not using a extra rigorous strategy.
Constructing a framework for belief
To deal with these challenges, we would have liked a strategy to consider the evaluators. That meant two issues:
- A high-quality, human-labeled dataset of judgments.
- A system to methodically check totally different decide configurations.
First, we created our personal dataset, now out there on HuggingFace. We generated a whole bunch of question-answer-response triplets utilizing a variety of RAG methods.
Then, our group hand-labeled all 807 examples.
Each edge case was debated, and we established clear, constant grading guidelines.
The method itself was eye-opening, displaying simply how subjective analysis may be. Ultimately, our labeled dataset mirrored a distribution of 37.6% failing and 62.4% passing responses.

Subsequent, we would have liked an engine for experimentation. That’s the place our open-source framework, syftr, got here in.
We prolonged it with a brand new JudgeFlow class and a configurable search house to range LLM selection, temperature, and immediate design. This made it doable to systematically discover — and establish — the decide configurations most aligned with human judgment.
Placing the judges to the check
With our framework in place, we started experimenting.
Our first check targeted on the Grasp-RM mannequin, particularly tuned to keep away from “reward hacking” by prioritizing content material over reasoning phrases.
We pitted it in opposition to its base mannequin utilizing 4 prompts:
- The “default” LlamaIndex CorrectnessEvaluator immediate, asking for a 1–5 score
- The identical CorrectnessEvaluator immediate, asking for a 1–10 score
- A extra detailed model of the CorrectnessEvaluator immediate with extra specific standards.
- A easy immediate: “Return YES if the Generated Reply is appropriate relative to the Reference Reply, or NO if it isn’t.”
The syftr optimization outcomes are proven beneath within the cost-versus-accuracy plot. Accuracy is the straightforward % settlement between the decide and human evaluators, and price is estimated based mostly on the per-token pricing of Collectively.ai‘s internet hosting providers.
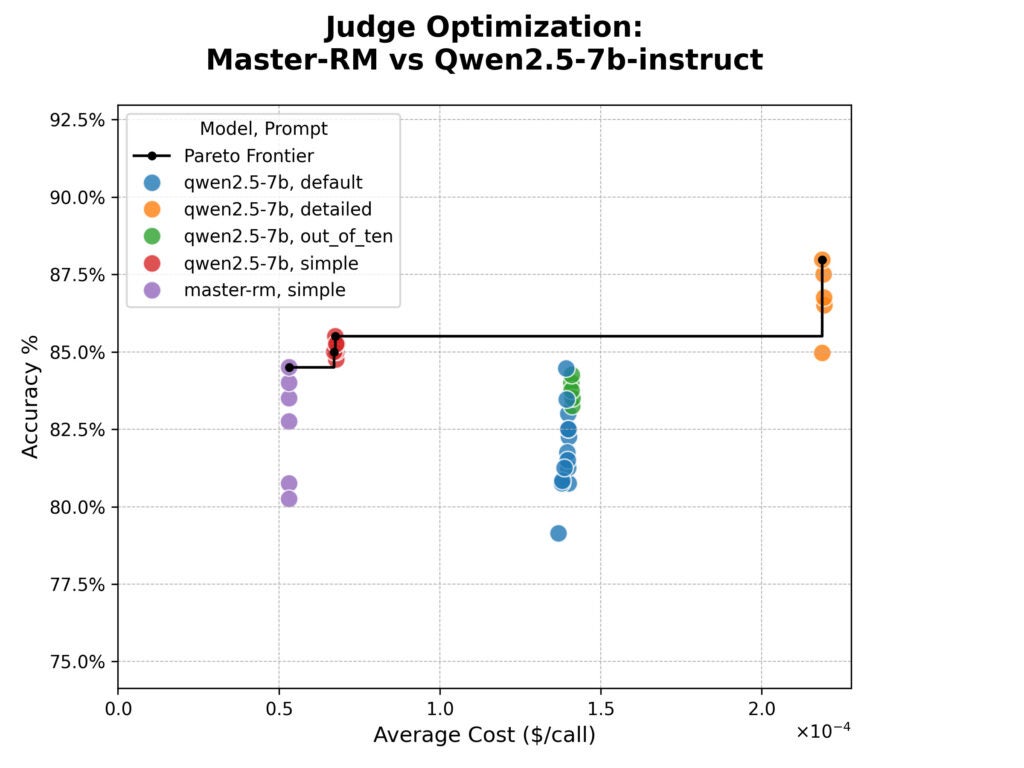
The outcomes have been stunning.
Grasp-RM was no extra correct than its base mannequin and struggled with producing something past the “easy” immediate response format resulting from its targeted coaching.
Whereas the mannequin’s specialised coaching was efficient in combating the results of particular reasoning phrases, it didn’t enhance general alignment to the human judgements in our dataset.
We additionally noticed a transparent trade-off. The “detailed” immediate was essentially the most correct, however practically 4 occasions as costly in tokens.
Subsequent, we scaled up, evaluating a cluster of huge open-weight fashions (from Qwen, DeepSeek, Google, and NVIDIA) and testing new decide methods:
- Random: Choosing a decide at random from a pool for every analysis.
- Consensus: Polling 3 or 5 fashions and taking the bulk vote.
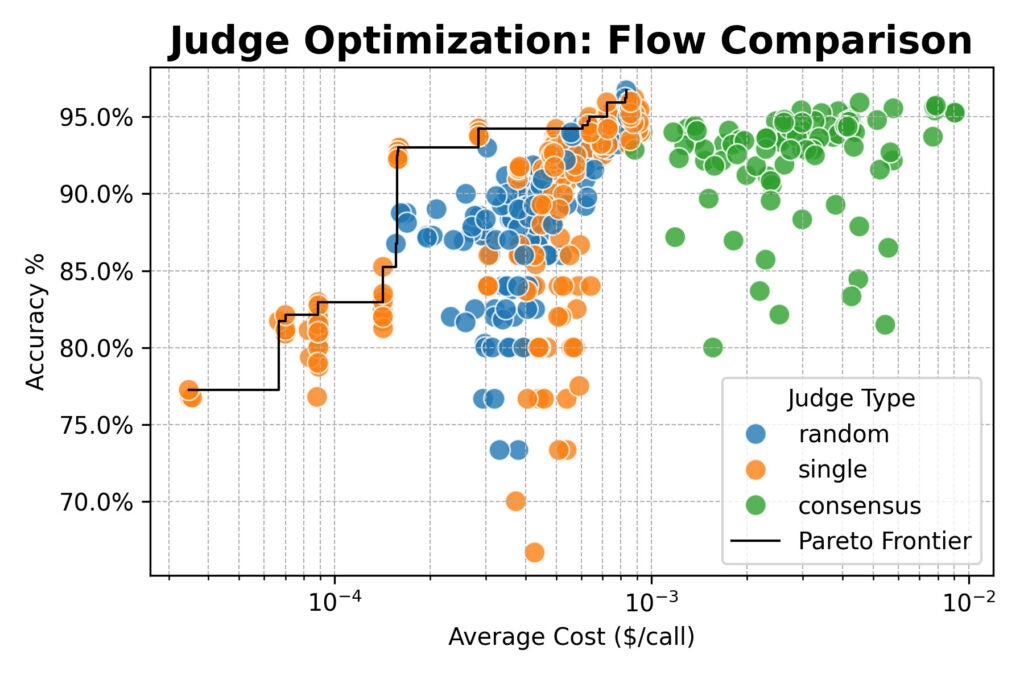
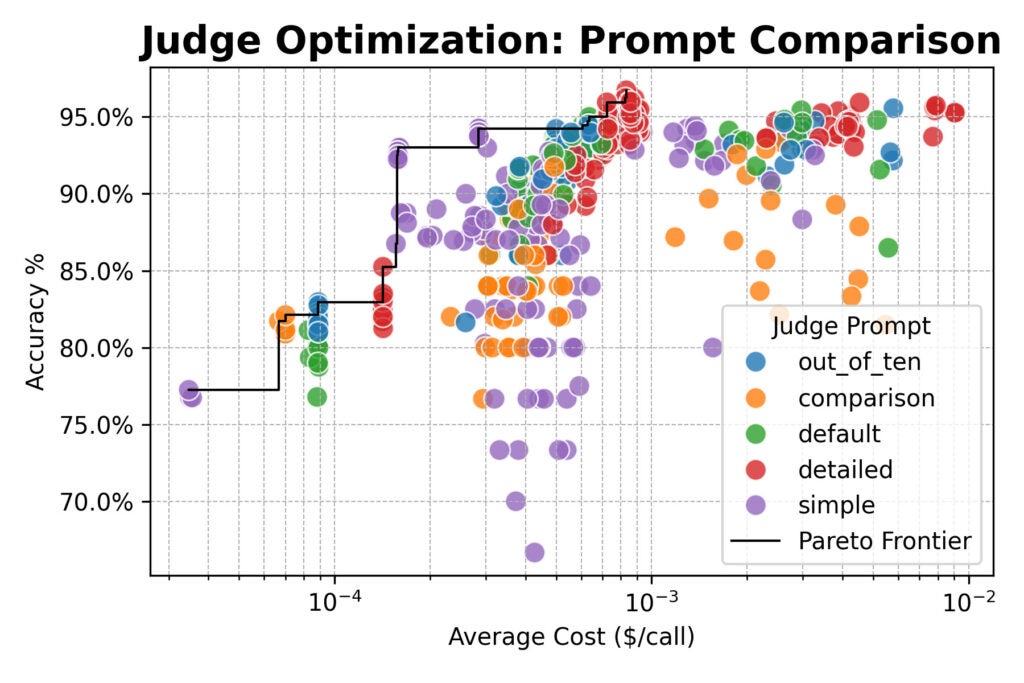
Right here the outcomes converged: consensus-based judges supplied no accuracy benefit over single or random judges.
All three strategies topped out round 96% settlement with human labels. Throughout the board, the best-performing configurations used the detailed immediate.
However there was an essential exception: the straightforward immediate paired with a strong open-weight mannequin like Qwen/Qwen2.5-72B-Instruct was practically 20× cheaper than detailed prompts, whereas solely giving up a couple of proportion factors of accuracy.
What makes this answer totally different?
For a very long time, our rule of thumb was: “Simply use gpt-4o-mini.” It’s a standard shortcut for groups in search of a dependable, off-the-shelf decide. And whereas gpt-4o-mini did carry out nicely (round 93% accuracy with the default immediate), our experiments revealed its limits. It’s only one level on a much wider trade-off curve.
A scientific strategy provides you a menu of optimized choices as an alternative of a single default:
- Prime accuracy, regardless of the fee. A consensus stream with the detailed immediate and fashions like Qwen3-32B, DeepSeek-R1-Distill, and Nemotron-Tremendous-49B achieved 96% human alignment.
- Funds-friendly, fast testing. A single mannequin with the straightforward immediate hit ~93% accuracy at one-fifth the price of the gpt-4o-mini baseline.
By optimizing throughout accuracy, value, and latency, you can also make knowledgeable selections tailor-made to the wants of every venture — as an alternative of betting the whole lot on a one-size-fits-all decide.
Constructing dependable judges: Key takeaways
Whether or not you employ our framework or not, our findings may also help you construct extra dependable analysis methods:
- Prompting is the most important lever. For the very best human alignment, use detailed prompts that spell out your analysis standards. Don’t assume the mannequin is aware of what “good” means to your activity.
- Easy works when pace issues. If value or latency is important, a easy immediate (e.g., “Return YES if the Generated Reply is appropriate relative to the Reference Reply, or NO if it isn’t.”) paired with a succesful mannequin delivers glorious worth with solely a minor accuracy trade-off.
- Committees convey stability. For important evaluations the place accuracy is non-negotiable, polling 3–5 numerous, highly effective fashions and taking the bulk vote reduces bias and noise. In our examine, the top-accuracy consensus stream mixed Qwen/Qwen3-32B, DeepSeek-R1-Distill-Llama-70B, and NVIDIA’s Nemotron-Tremendous-49B.
- Larger, smarter fashions assist. Bigger LLMs persistently outperformed smaller ones. For instance, upgrading from microsoft/Phi-4-multimodal-instruct (5.5B) with an in depth immediate to gemma3-27B-it with a easy immediate delivered an 8% increase in accuracy — at a negligible distinction in value.
From uncertainty to confidence
Our journey started with a troubling discovery: as an alternative of following the rubric, our LLM judges have been being swayed by lengthy, plausible-sounding refusals.
By treating analysis as a rigorous engineering downside, we moved from doubt to confidence. We gained a transparent, data-driven view of the trade-offs between accuracy, value, and pace in LLM-as-a-Choose methods.
Extra knowledge means higher selections.
We hope our work and our open-source dataset encourage you to take a better have a look at your personal analysis pipelines. The “finest” configuration will all the time rely in your particular wants, however you now not need to guess.
Able to construct extra reliable evaluations? Discover our work in syftr and begin judging your judges.

{kind=link}