
Many enterprises are adopting Apache Spark for scalable information processing duties comparable to extract, rework, and cargo (ETL), batch analytics, and information enrichment. As information pipelines evolve, the necessity for versatile and cost-efficient execution environments that assist automation, governance, and efficiency at scale additionally evolve in parallel. Amazon EMR gives a strong surroundings to run Spark workloads, and relying on workload traits and compliance necessities, groups can select between absolutely managed choices like Amazon EMR Serverless or extra customizable configurations utilizing Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2).
In use circumstances the place infrastructure management, information locality, or strict safety postures are important, comparable to in monetary companies, healthcare, or authorities, working transient EMR on EC2 clusters turns into a most popular selection. Nevertheless, orchestrating the complete lifecycle of those clusters, from provisioning to job submission and eventual teardown, can introduce operational overhead and threat if achieved manually.
To streamline this course of, the AWS Cloud affords built-in orchestration capabilities utilizing AWS Step Capabilities and Amazon EventBridge. Collectively, these companies make it easier to automate and schedule your entire EMR job lifecycle, lowering handbook intervention whereas optimizing price and compliance. Step Capabilities gives the workflow logic to handle cluster creation, Spark job execution, and cluster termination, and EventBridge schedules these workflows primarily based on enterprise or operational wants.
On this put up, we focus on tips on how to construct a totally automated, scheduled Spark processing pipeline utilizing Amazon EMR on EC2, orchestrated with Step Capabilities and triggered by EventBridge. We stroll by way of tips on how to deploy this resolution utilizing AWS CloudFormation, processes COVID-19 public dataset information in Amazon Easy Storage Service (Amazon S3), and retailer the aggregated ends in Amazon S3. This structure is right for periodic or scheduled batch processing eventualities the place infrastructure management, auditability, and cost-efficiency are important.
Resolution overview
This resolution makes use of the publicly accessible COVID-19 dataset as an instance tips on how to construct a modular, scheduled structure for scalable and cost-efficient batch processing for time-bound information workloads.The answer follows these steps:
- Uncooked COVID-19 information in CSV format is saved in an S3 enter bucket.
- A scheduled rule in EventBridge triggers a Step Capabilities workflow.
- The Step Capabilities workflow provisions a transient Amazon EMR cluster utilizing EC2 situations.
- A PySpark job is submitted to the cluster to calculate COVID-19 hospital utilization information to compute month-to-month state-level averages of inpatient and ICU mattress utilization, and COVID-19 affected person percentages.
- The processed outcomes are written again to an S3 output bucket.
- After profitable job completion, the EMR cluster is robotically deleted.
- Logs are endured to Amazon S3 for observability and troubleshooting.
By automating this workflow, you alleviate the necessity to manually handle EMR clusters whereas gaining cost-efficiency by working compute solely when wanted. This structure is right for periodic Spark jobs comparable to ETL pipelines, regulatory reporting, and batch analytics, particularly when management, compliance, and customization are required.The next diagram illustrates the structure for this use case.
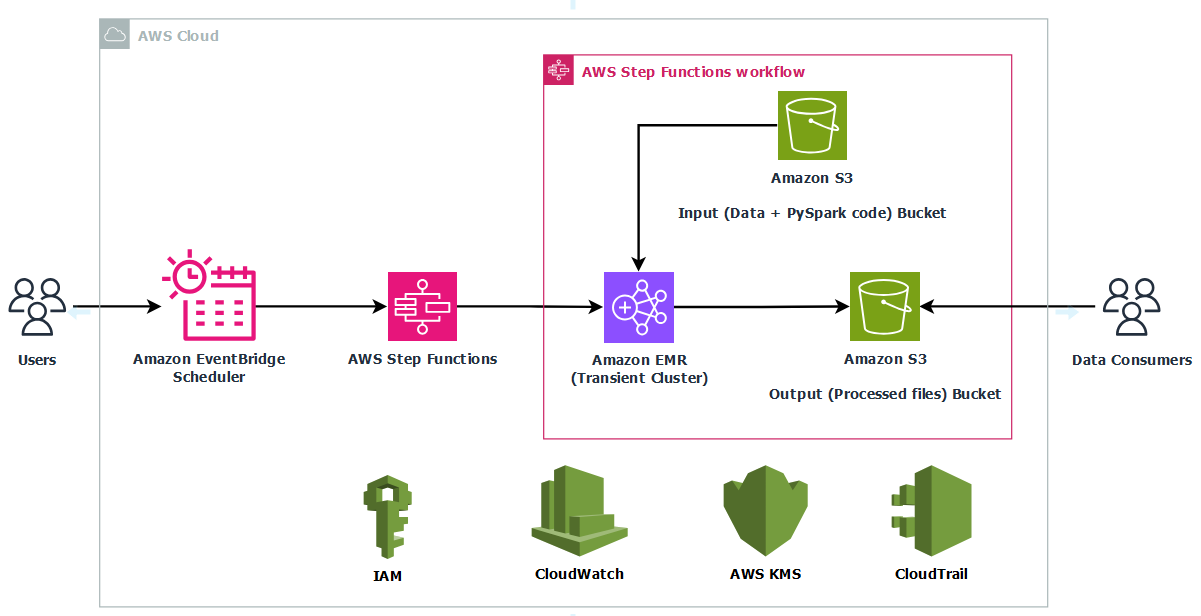
The infrastructure is deployed utilizing AWS CloudFormation to offer consistency and repeatability. AWS Id and Entry Administration (IAM) roles grant least‑privilege entry to Step Capabilities, Amazon EMR, EC2 situations, and S3 buckets, and non-compulsory AWS Key Administration Service (AWS KMS) encryption can safe information at relaxation in Amazon S3 and Amazon CloudWatch Logs. By combining a scheduled set off, stateful orchestration, and centralized logging, this resolution delivers a totally automated, price‑optimized, and safe solution to run transient Spark workloads in manufacturing.
Stipulations
Earlier than you get began, be sure you have the next stipulations:
Arrange assets with AWS CloudFormation
To provision the required assets utilizing a single CloudFormation template, full the next steps:
- Register to the AWS Administration Console as an admin person.
- Clone the pattern repository to your native machine or AWS CloudShell and navigate into the venture listing.
- Set an surroundings variable for the AWS Area the place you propose to deploy the assets. Change the placeholder together with your Area code, for instance,
us-east-1. - Deploy the stack utilizing the next command. Replace the stack title if wanted. On this instance, the stack is created with the title
covid19-analysis.
You’ll be able to monitor the stack creation progress on the AWS CloudFormation console on the Occasions tab. The deployment sometimes completes in below 5 minutes.
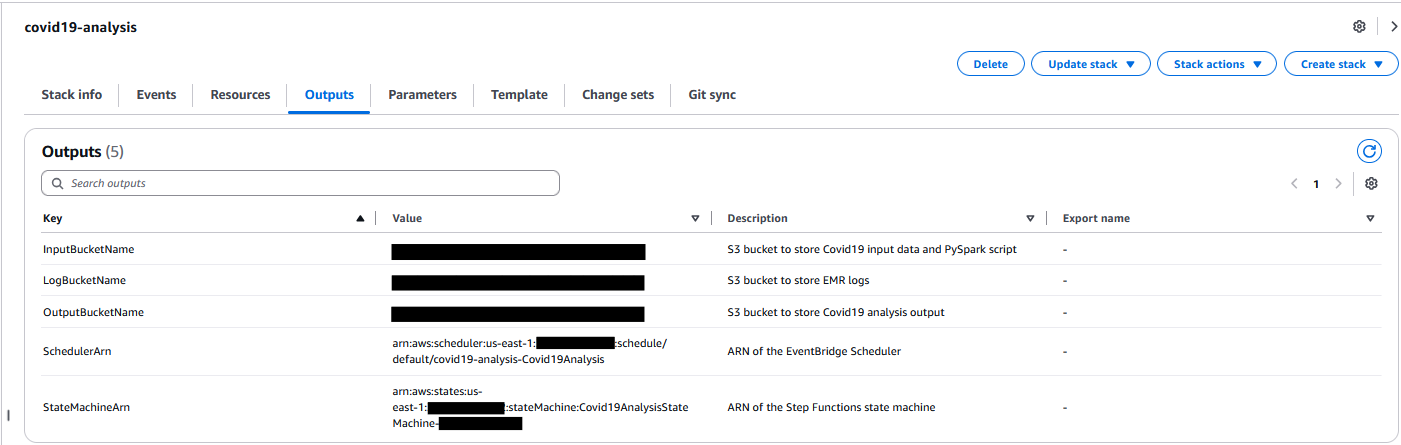
After the stack is efficiently created, go to the Outputs tab on the AWS CloudFormation console and observe the next values to be used in later steps:
- InputBucketName
- OutputBucketName
- LogBucketName
Arrange the COVID-19 dataset
Together with your infrastructure in place, full the next steps to arrange the enter information:
- Obtain the COVID-19 information CSV file from HealthData.gov to your native machine.
- Rename the downloaded file to covid19-dataset.csv.
- Add the renamed file to your S3 enter bucket below the uncooked/ folder path.
Arrange the PySpark Script
Full the next steps to arrange the PySpark script:
- Open AWS CloudShell from the console.
- Verify that you’re working contained in the sample-emr-transient-cluster-step-functions-eventbridge listing earlier than working the subsequent command.
- Copy the PySpark script wanted for this walkthrough into your enter bucket:
This script processes COVID-19 hospital utilization information saved as CSV recordsdata in your S3 enter bucket. When working the job, present the next command-line arguments:
--input– The S3 path to the enter CSV recordsdata--output– The S3 path to retailer the processed outcomes
The script reads the uncooked dataset, standardizes numerous date codecs, and filters out information with invalid or lacking dates. It then extracts key utilization metrics comparable to inpatient mattress utilization, ICU mattress utilization, and the share of beds occupied by COVID-19 sufferers and calculates month-to-month averages grouped by state. The aggregated output is saved as timestamped CSV recordsdata within the specified S3 location.
This instance demonstrates how you should use PySpark to effectively clear, rework, and analyze large-scale healthcare information to realize actionable insights on hospital capability tendencies through the pandemic.
Configure a schedule in EventBridge
The Step Capabilities state machine is by default scheduled to run on December 31, 2025, as a one-time execution. You’ll be able to replace the schedule for recurring or one-time execution as wanted. Full the next steps:
- On the EventBridge console, select Schedules below Scheduler within the navigation pane.
- Choose the schedule named
-covid19-analysis and select Edit. - Set your most popular schedule sample.
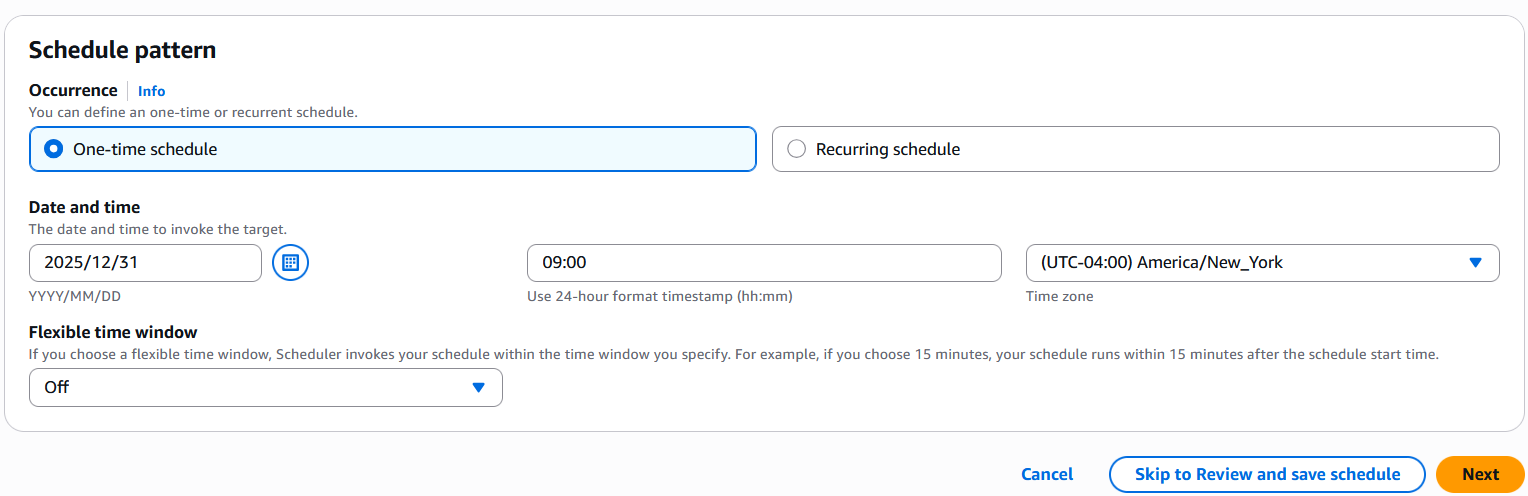
- If you wish to run the schedule one time, choose One-time schedule for Incidence and enter a date and time.
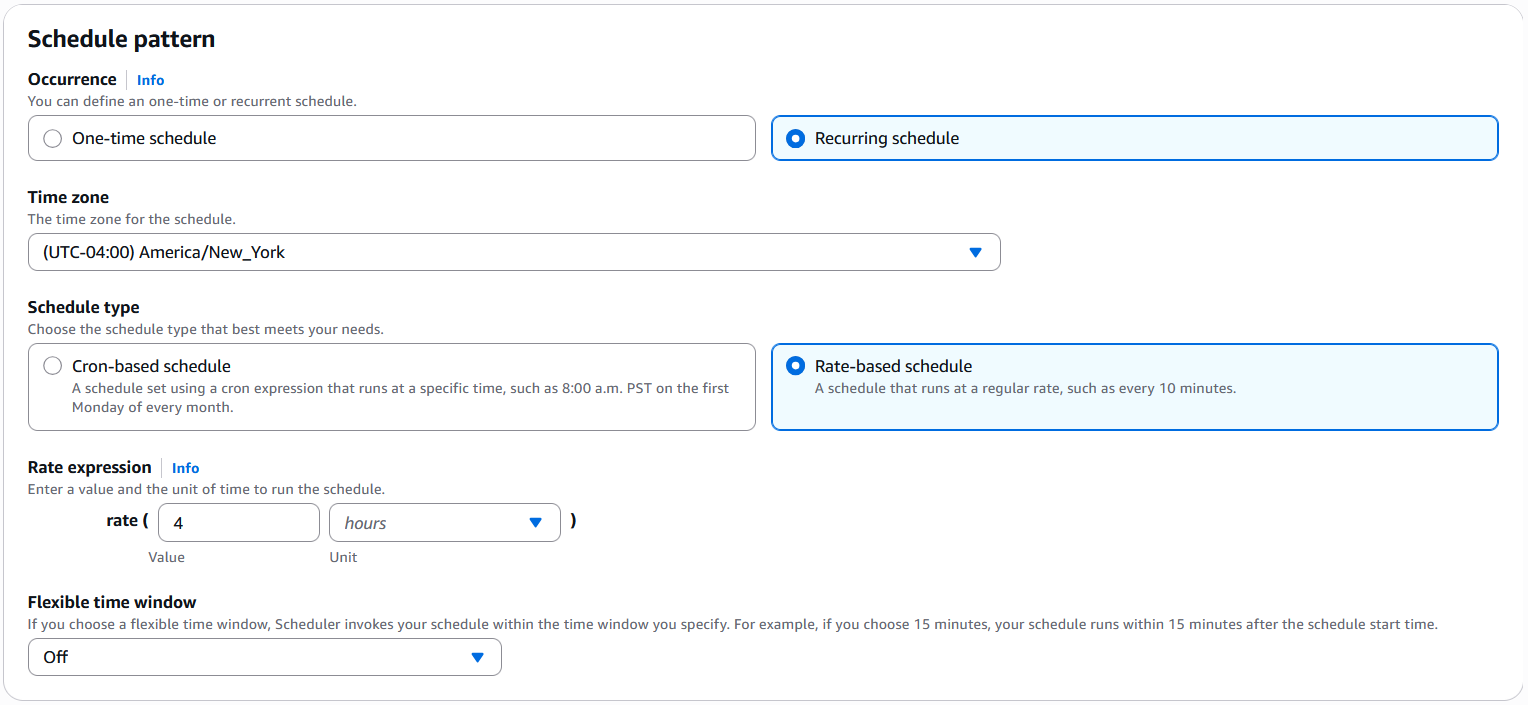
- If you wish to run this on a recurring foundation, choose Recurring schedule. Specify the schedule sort as both Cron-based schedule or Charge-based schedule as wanted.
- If you wish to run the schedule one time, choose One-time schedule for Incidence and enter a date and time.
- Select Subsequent twice and select Save schedule.
Begin the workflow in Step Capabilities
Based mostly in your EventBridge schedule, the Step Capabilities workflow will run robotically. For this walkthrough, full the next steps to set off it manually:
- On the Step Capabilities console, select State machines within the navigation pane.
- Select the state machine that begins with Covid19AnalysisStateMachine-*.
- Select Begin execution.
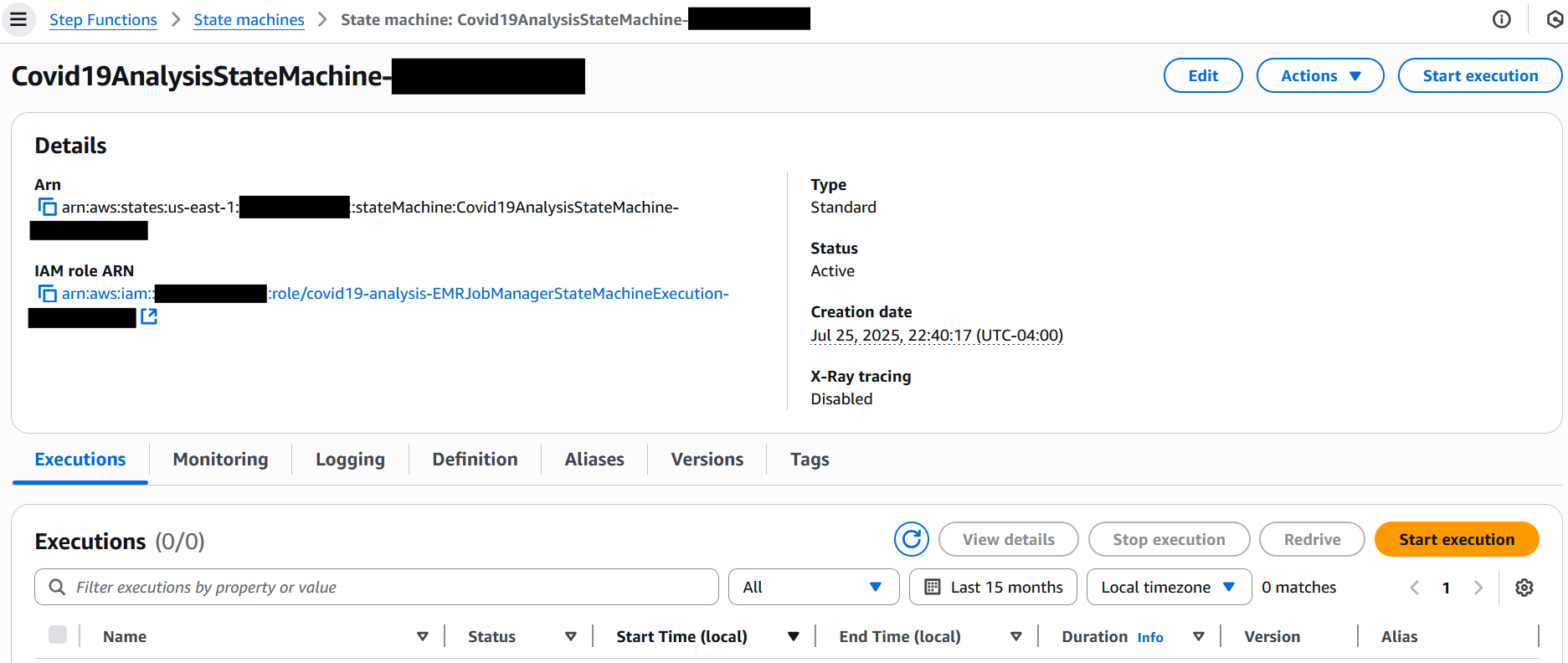
- Within the Enter part, present the next JSON (present the log bucket and output bucket names with the suitable values captured earlier):
- Select Begin execution to provoke the workflow.
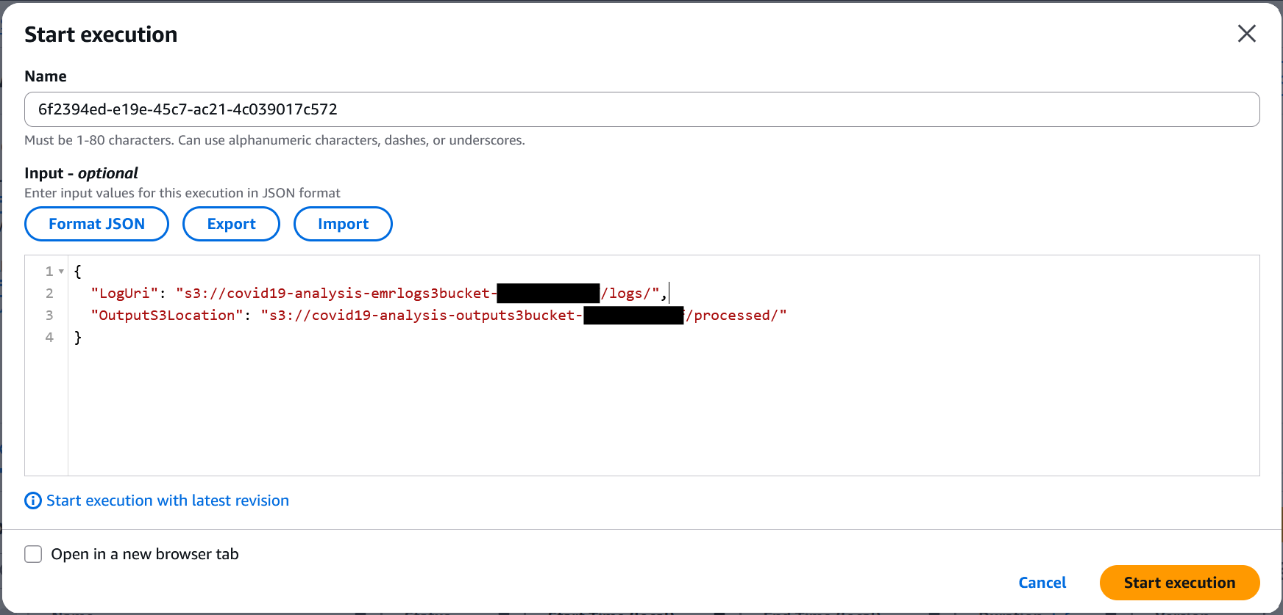
Monitor the EMR job and workflow execution
After you begin the workflow, you may observe each the Step Capabilities state transitions and the EMR job progress in actual time on the console.
Monitor the Step Capabilities state machine
Full the next steps to observe the Step Capabilities state machine:
- On the Step Capabilities console, select State machines within the navigation pane.
- Select the state machine that begins with Covid19AnalysisStateMachine-*.
- Select the working execution to view the visible workflow.
Every state node will replace because it progresses—inexperienced for achievement, purple for failure.
- To discover a step, select its node and examine the enter, output, and error particulars within the facet pane.
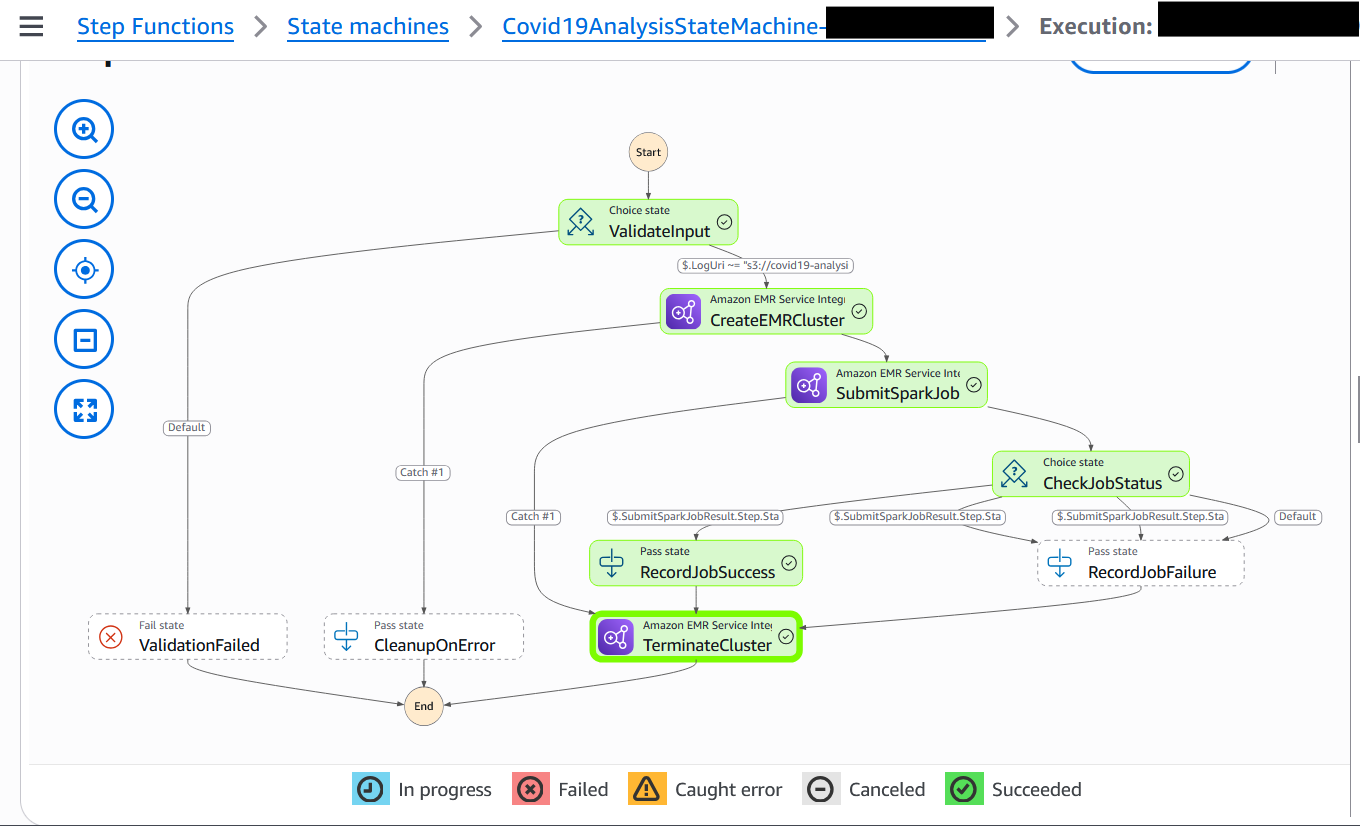
The next screenshot reveals an instance of a efficiently executed workflow.
Monitor the EMR cluster and EMR step
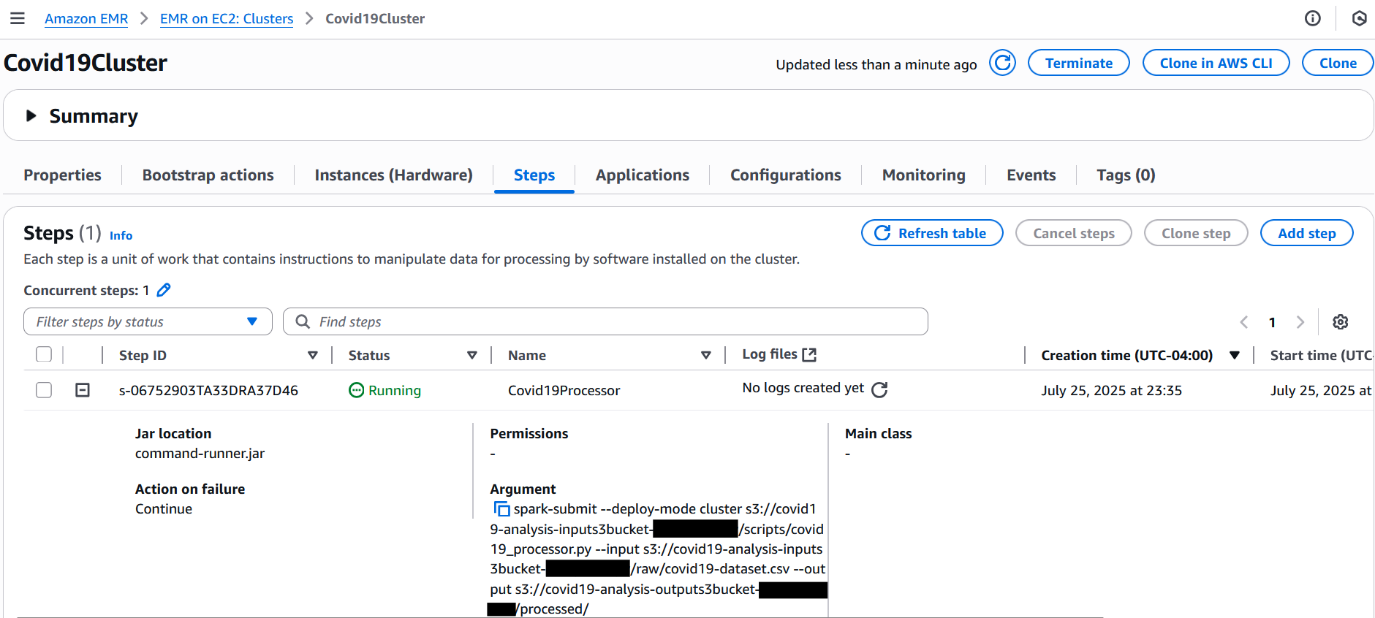
Full the next steps to observe the EMR cluster and EMR step standing:
- Whereas the cluster is lively, open the Amazon EMR console and select Clusters within the navigation pane.
- Find the Covid19Cluster transient EMR cluster.
Initially, it is going to be in Beginning standing.
On the Steps tab, you may see your Spark submit step listed. Because the job progresses, the step standing modifications from Pending to Working to lastly Accomplished or Failed.
- Select the Purposes tab to view the applying UIs, in which you’ll entry the Spark Historical past Server and YARN Timeline Server for monitoring and troubleshooting.
Monitor CloudWatch logs
To allow CloudWatch logging and enhanced monitoring on your EMR on EC2 cluster, confer with Amazon EMR on EC2 – Enhanced Monitoring with CloudWatch utilizing customized metrics and logs. This information explains tips on how to set up and configure the CloudWatch agent utilizing a bootstrap motion, so you may stream system-level metrics (comparable to CPU, reminiscence, and disk utilization) and utility logs from EMR nodes on to CloudWatch. With this setup, you may acquire real-time visibility into cluster well being and efficiency, simplify troubleshooting, and retain important logs even after the cluster is terminated.
For this walkthrough, examine the logs within the S3 log output location.
Verify cluster deletion
When the Spark step is full, Step Capabilities will robotically delete the Amazon EMR cluster. Refresh the Clusters web page on the Amazon EMR console. You need to see your cluster standing change from Terminating to Terminated inside a minute.
By following these steps, you acquire full end-to-end visibility into your workflow from the second the Step Capabilities state machine is triggered to the automated shutdown of the EMR cluster. You’ll be able to monitor execution progress, troubleshoot points, verify job success, and constantly optimize your transient Spark workloads.
Confirm job output in Amazon S3
When the job is full, full the next steps to examine the processed ends in the S3 output bucket:
- On the Amazon S3 console, select Buckets within the navigation pane.
- Open the output S3 bucket you famous earlier.
- Open the processed folder.
- Navigate into the timestamped subfolder to view the CSV output file.
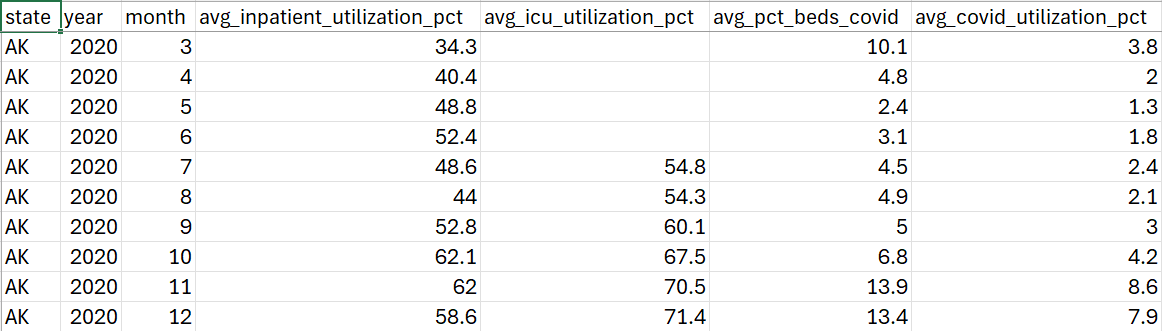
- Obtain the CSV file to view the processed outcomes, as proven within the following screenshot.
Monitoring and troubleshooting
To observe the progress of your Spark job working on a transient EMR on EC2 cluster, use the Step Capabilities console. It gives real-time visibility into every state transition in your workflow, from cluster creation and job submission to cluster deletion. This makes it simple to trace execution circulate and establish the place points would possibly happen.Throughout job execution, you should use the Amazon EMR console to entry cluster-level monitoring. This contains YARN utility statuses, step-level logs, and total cluster well being. If CloudWatch logging is enabled in your job configuration, driver and executor logs stream in close to actual time, so you may rapidly detect and diagnose errors, useful resource constraints, or information skew inside your Spark utility.
After the workflow is full, no matter whether or not it succeeds or fails, you may carry out an in depth post-execution evaluation by reviewing the logs saved within the S3 bucket specified within the LogUri parameter. This log listing contains customary output and error logs, together with Spark historical past recordsdata, providing insights into execution conduct and efficiency metrics.
For continued entry to the Spark UI throughout job execution, you should use persistent utility UIs on the EMR console. These hyperlinks stay accessible even after the cluster is stopped, enabling deeper root-cause evaluation and efficiency tuning for future runs.
This visibility into each workflow orchestration and job execution may help groups optimize their Spark workloads, cut back troubleshooting time, and construct confidence of their EMR automation pipelines.
Clear up
To keep away from incurring ongoing costs, clear up the assets provisioned throughout this walkthrough:
- Empty the S3 buckets:
- On the Amazon S3 console, select Buckets within the navigation pane.
- Choose the enter, output, and log buckets used on this tutorial.
- Select Empty to take away all objects earlier than deleting the buckets (non-compulsory).
- Delete the CloudFormation stack:
- On the AWS CloudFormation console, select Stacks within the navigation pane.
- Choose the stack you created for this resolution and select Delete.
- Verify the deletion to take away related assets.
Conclusion
On this put up, we confirmed tips on how to construct a totally automated and cost-effective Spark processing pipeline utilizing Step Capabilities, EventBridge, and Amazon EMR on EC2. The workflow provisions a transient EMR cluster, runs a Spark job to course of information, and stops the cluster after the job completes. This method helps cut back prices whereas providing you with full management over the method. This resolution is right for scheduled information processing duties comparable to ETL jobs, log analytics, or batch reporting, particularly whenever you want detailed management over infrastructure, safety, and compliance settings.
To get began, deploy the answer in your surroundings utilizing the CloudFormation stack offered and alter it to suit your information processing wants. Try the Step Capabilities Developer Information and Amazon EMR Administration Information to discover additional.
Share your suggestions and concepts within the feedback or join together with your AWS Options Architect to fine-tune this sample on your use case.
Concerning the authors

{kind=link}