
AWS just lately introduced the final availability of auto-optimize for the Amazon OpenSearch Service vector engine. This characteristic streamlines vector index optimization by routinely evaluating configuration trade-offs throughout search high quality, velocity, and price financial savings. You possibly can then run a vector ingestion pipeline to construct an optimized index in your desired assortment or area. Beforehand, optimizing index configurations—together with algorithm, compression, and engine settings—required consultants and weeks of testing. This course of have to be repeated as a result of optimizations are distinctive to particular information traits and necessities. Now you can auto-optimize vector databases in below an hour with out managing infrastructure and buying experience in index tuning.
On this submit, we talk about how the auto-optimize characteristic works, its advantages, and share examples of auto-optimized outcomes.
Overview of vector search and vector indexes
Vector search is a way that improves search high quality and is a cornerstone of generative AI purposes. It entails utilizing a sort of AI mannequin to transform content material into numerical encodings (vectors), enabling content material matching by semantic similarity as a substitute of simply key phrases. You construct vector databases by ingesting vectors into OpenSearch to construct indexes that allow searches throughout billions of vectors in milliseconds.
Advantages of optimizing vector indexes and the way it works
The OpenSearch vector engine offers a wide range of index configurations that provide help to make favorable trade-offs between search high quality (recall), velocity (latency), and price (RAM necessities). There isn’t a universally optimum configuration. Consultants should consider combos of index settings resembling Hierarchal Navigable Small Worlds (HNSW) algorithm parameters (resembling m or ef_construction), quantization methods (resembling scalar, binary, or product), and engine parameters (resembling memory-optimized, disk-optimized, or warm-cold storage). The distinction between configurations could possibly be a ten% or extra distinction in search high quality, a whole lot of milliseconds in search latency, or as much as 3 times in price financial savings. For big-scale deployments, cost-optimizations could make or break your finances.
The next determine is a conceptual illustration of trade-offs between index configurations.
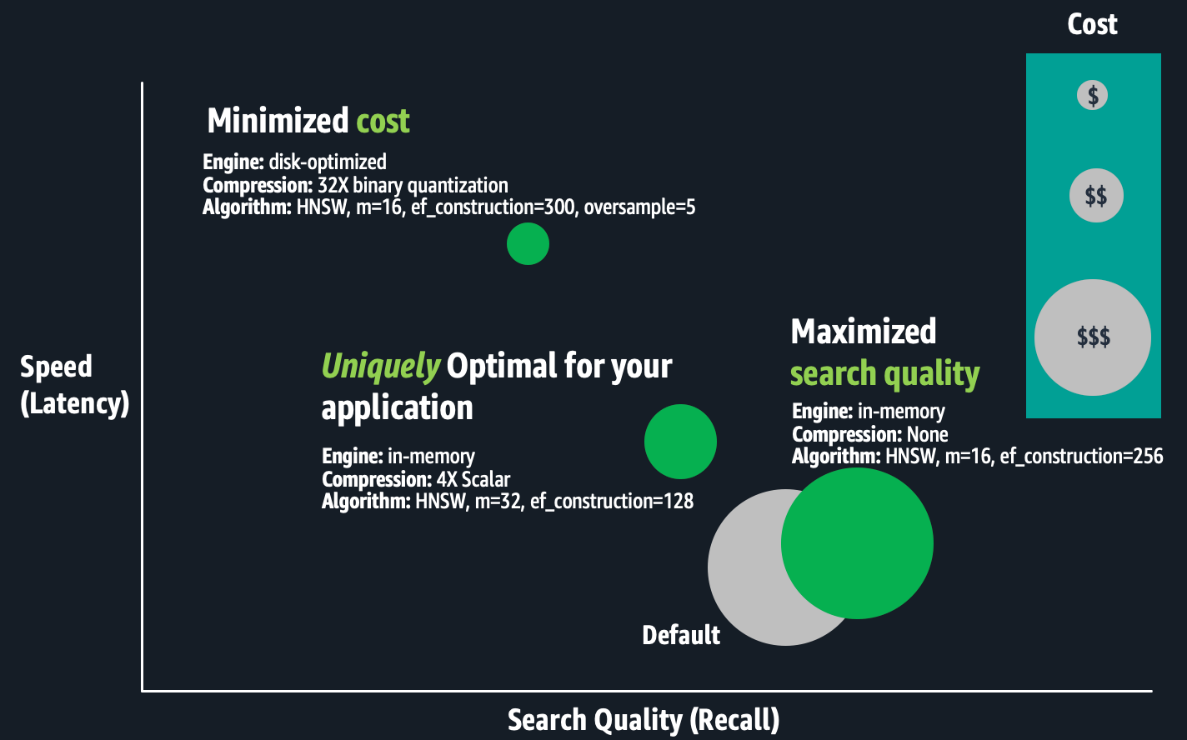
Optimizing vector indexes is time-consuming. Consultants should construct an index; consider its velocity, high quality, and price; and make applicable configuration changes earlier than repeating this course of. Operating these experiments at scale can take weeks as a result of constructing and evaluating large-scale index requires substantial compute energy, leading to hours to days of processing for only one index. Optimizations are distinctive to particular enterprise necessities and every dataset, and trade-off choices are subjective. The perfect trade-offs rely upon the use case, resembling seek for an inside wiki or an e-commerce website. Due to this fact, this course of have to be repeated for every index. Lastly, in case your utility information adjustments constantly, your vector search high quality may degrade, requiring you to rebuild and re-optimize your vector indexes commonly.
Answer overview
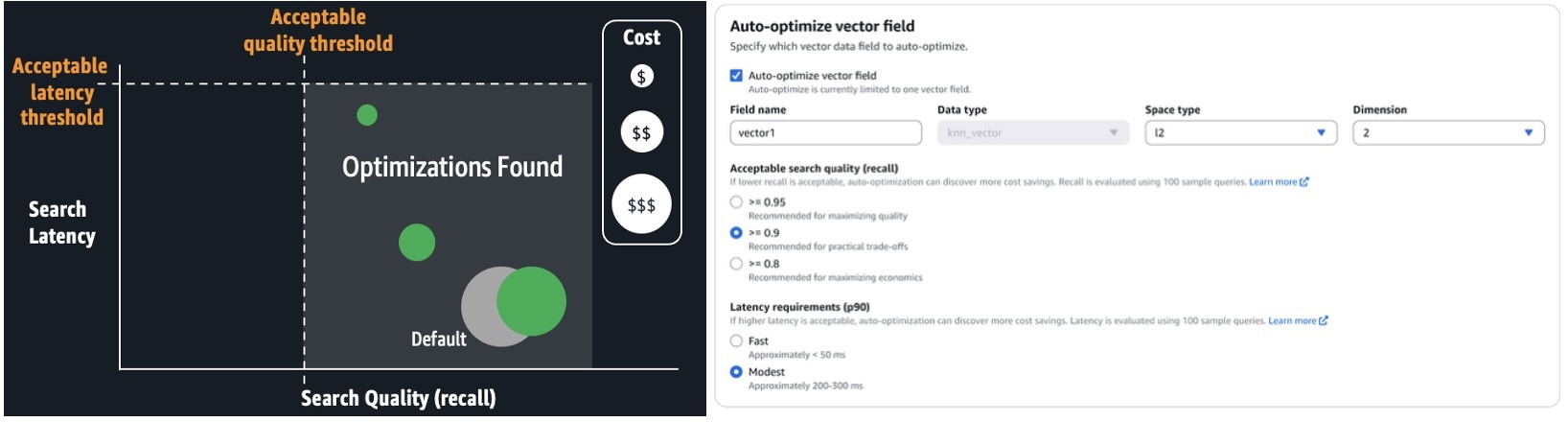
With auto-optimize, you possibly can run jobs to provide optimization suggestions, consisting of studies that element efficiency measurements and explanations of the really helpful configurations. You possibly can configure auto-optimize jobs by merely offering your utility’s acceptable search latency and high quality necessities. Experience in k-NN algorithms, quantization methods, and engine settings aren’t required. It avoids the one-size-fits-all limitations of options primarily based on a number of pre-configured deployment sorts, providing a tailor-made match in your workloads. It automates the guide labor beforehand described. You merely run serverless, auto-optimize jobs at a flat price per job. These jobs don’t eat your assortment or area assets. OpenSearch Service manages a separate multi-tenant heat pool of servers, and parallelizes index evaluations throughout safe, single-tenant staff to ship outcomes shortly. Auto-optimize can be built-in with vector ingestion pipelines, so you possibly can shortly construct an optimized vector index on a group or area from an Amazon Easy Storage Service (Amazon S3) information supply.
The next screenshot illustrates easy methods to configure an auto-optimize job on the OpenSearch Service console.
When the job is full (usually, inside 30–60 minutes for million-plus-size datasets), you possibly can evaluate the suggestions and studies, as proven within the following screenshot.
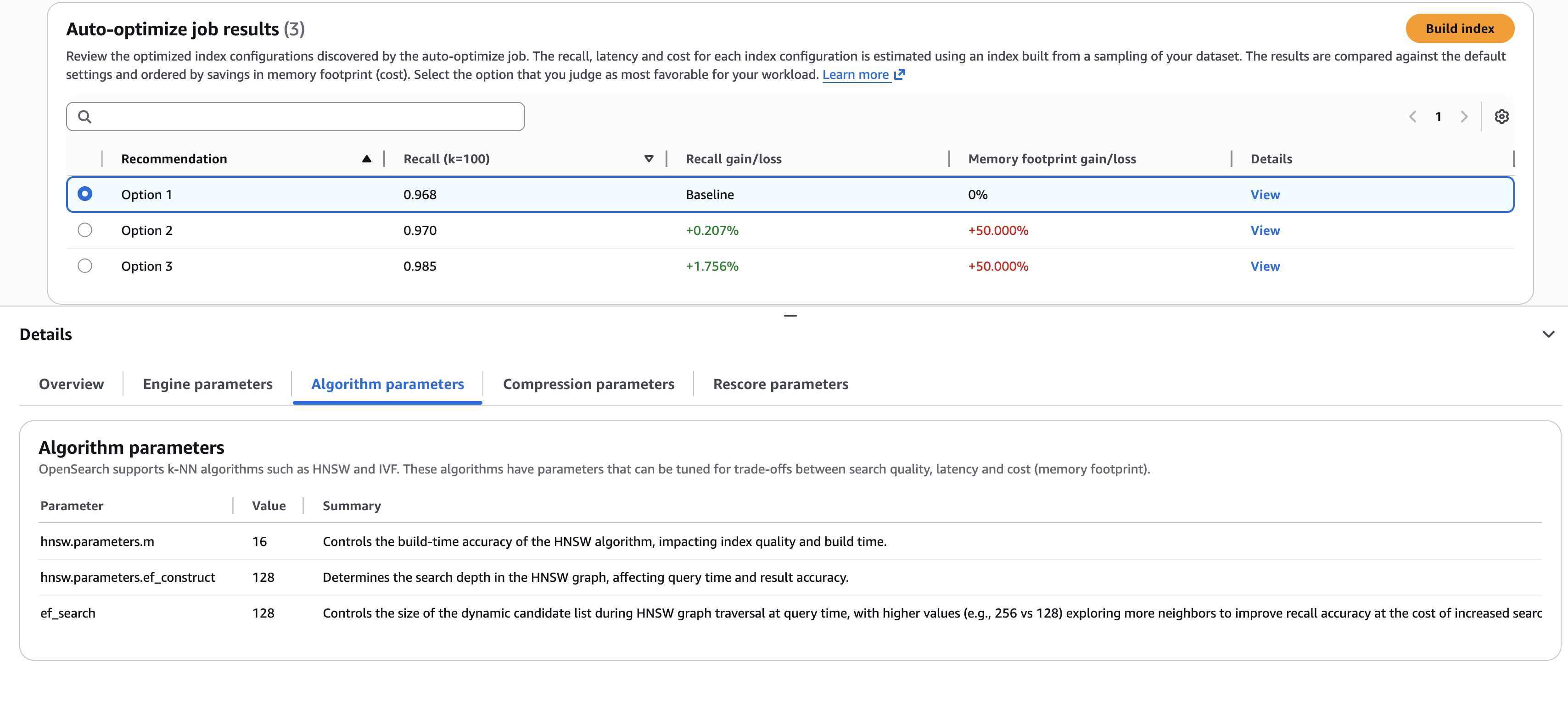
The screenshot illustrates an instance the place it’s good to select one of the best trade-offs. Do you choose the primary choice, which delivers the very best price financial savings (via decrease reminiscence necessities)? Or do you choose the third choice, which delivers a 1.76% search high quality enchancment, however at greater price? If you wish to perceive the main points of the configurations used to ship these outcomes, you possibly can view the sub-tabs on the Particulars pane, such because the Algorithm parameters tab proven within the previous screenshot.
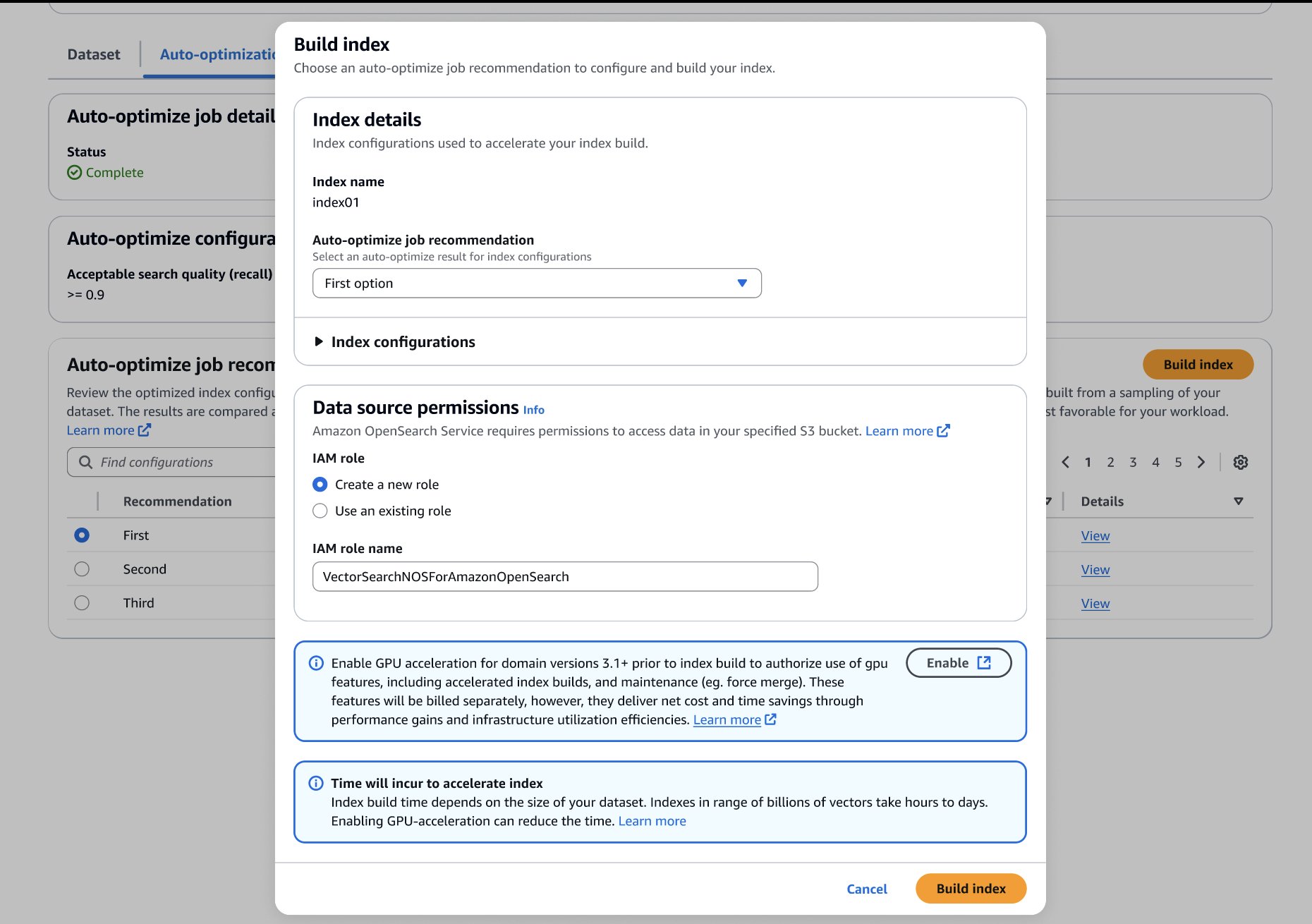
After you’ve made your alternative, you possibly can construct your optimized index in your goal OpenSearch Service area or assortment, as proven within the following screenshot. In the event you’re constructing the index on a group or a site working OpenSearch 3.1+, you possibly can allow GPU-acceleration to extend the construct velocity as much as 10 instances quicker at 1 / 4 of the indexing price.
Auto-optimize outcomes
The next desk presents a number of examples of auto-optimize outcomes. To quantify the worth of working auto-optimize, we current positive factors in comparison with default settings. The estimated RAM necessities are primarily based on commonplace area sizing estimates:
Required RAM = 1.1 x (bytes per dimension x dimensions + hnsw.parameters.m x 8) x vector depend
We estimate price financial savings by evaluating the minimal infrastructure (has simply sufficient RAM) to host an index with the default in comparison with optimized settings.
| Dataset | Auto-Optimize Job Configurations | Really useful Adjustments to Defaults |
Required RAM) (% lowered) |
Estimated Value Financial savings (Required information nodes for default configuration vs. optimized) |
Recall (% achieve) |
| msmarco-distilbert-base-tas-b: 10M 384D vectors generated from MSMARCO v1 | Acceptable recall >= 0.95 Modest latency (Roughly 200-300 ms) | Extra supporting indexing and search reminiscence (ef_search=256, ef_constructon=128)Use Lucene engineDisk optimized mode with 5X oversampling4X compression (4-bit binary quantization) |
5.6 GB (-69.4%) |
Much less 75% (3 x r8g.mediumsearch vs. 3 x r8g.xlarge.search) |
0.995(+2.6%) |
| all-mpnet-base-v2: 1M 768D vectors generated from MSMARCO v2.1 | Acceptable recall >= 0.95 Modest latency (Roughly 200–300 ms) | Denser HNSW Graph (m=32)Extra supporting indexing and search reminiscence (ef_search=256, ef_constructon=128)Disk optimized mode with 3X oversampling8X compression (4-bit binary quantization) |
0.7GB (-80.9%) |
Much less 50.7% (t3.small.search vs. t3.medium.search) |
0.999 (+0.9%) |
| Cohere Embed V3: 113M 1024D vectors generated from MSMARCO v2.1 | Acceptable recall >= 0.95 Quick latency (Roughly | Denser HNSW Graph (m=32)Extra supporting indexing and search reminiscence (ef_search=256, ef_constructon=128)Use Lucene engine4X compression (uint8-scalar quantization) |
159GB (-69.7%) |
Much less 50.7% (6 x r8g.4xlarge.search vs. 6 x r8g.8xlarge.search) |
0.997 (+8.4%) |
Conclusion
You can begin constructing auto-optimized vector databases on the Vector ingestion web page of the OpenSearch Service console. Use this characteristic with GPU-accelerated vector indexes to construct optimized, billion-scale vector databases inside hours.
Auto-optimize is out there for OpenSearch Service vector collections and OpenSearch 2.17+ domains within the US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Mumbai, Singapore, Sydney, Tokyo), and Europe (Frankfurt, Eire, Stockholm) AWS Areas.
In regards to the authors

{kind=link}