")
Introduction
Imaginative and prescient Language Fashions (VLMs) permit each textual content inputs and visible understanding. Nevertheless, picture decision is essential for VLM efficiency for processing textual content and chart-rich information. Rising picture decision creates important challenges. First, pretrained imaginative and prescient encoders usually wrestle with high-resolution pictures on account of inefficient pretraining necessities. Working inference on high-resolution pictures will increase computational prices and latency throughout visible token technology, whether or not by way of single high-resolution processing or a number of lower-resolution tile methods. Second, high-resolution pictures produce extra tokens, which results in a rise in LLM prefilling time and time-to-first-token (TTFT), which is the sum of the imaginative and prescient encoder latency and the LLM prefilling time.
Present VLM Architectures
Giant multimodal fashions similar to Frozen and Florence used cross-attention to mix picture and textual content embeddings inside the intermediate LLM layers. Auto-regressive architectures like LLaVA, mPLUG-Owl, MiniGPT-4, and Cambrian-1 are efficient. For environment friendly picture encoding, CLIP-pretrained imaginative and prescient transformers stay broadly adopted, with variants like SigLIP, EVA-CLIP, InternViT, and DFNCLIP. Strategies like LLaVA-PruMerge and Matryoshka-based token sampling try dynamic token pruning, whereas hierarchical backbones similar to ConvNeXT and FastViT cut back token rely by way of progressive downsampling. Not too long ago, ConvLLaVA was launched, which makes use of a pure-convolutional imaginative and prescient encoder to encode pictures for a VLM.
Apple’s FastVLM
Researchers from Apple have proposed FastVLM, a mannequin that achieves an optimized tradeoff between decision, latency, and accuracy by analyzing how picture high quality, processing time, variety of tokens, and LLM measurement have an effect on one another. It makes use of FastViTHD, a hybrid imaginative and prescient encoder designed to output fewer tokens and cut back encoding time for high-resolution pictures. FastVLM achieves an optimum steadiness between visible token rely and picture decision solely by scaling the enter picture. It reveals a 3.2 occasions enchancment in TTFT within the LLaVA1.5 setup and achieves superior efficiency on key benchmarks utilizing the identical 0.5B LLM when in comparison with LLaVA-OneVision at most decision. It delivers 85 occasions sooner TTFT whereas utilizing a 3.4 occasions smaller imaginative and prescient encoder.
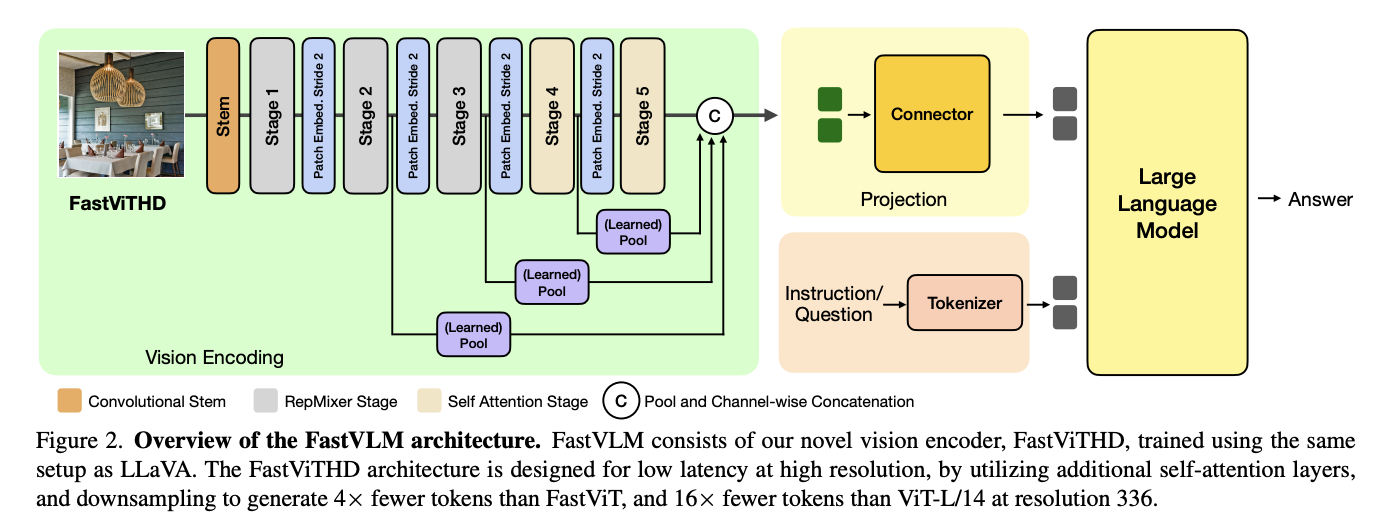
All FastVLM fashions are skilled on a single node with 8 occasions NVIDIA H100-80GB GPUs, the place stage 1 coaching of VLM is quick, taking round half-hour to coach with a Qwen2-7B decoder. Additional, FastViTHD enhances the bottom FastViT structure by introducing a further stage with a downsampling layer. This ensures self-attention operates on tensors downsampled by an element of 32 reasonably than 16, decreasing picture encoding latency whereas producing 4 occasions fewer tokens for the LLM decoder. The FastViTHD structure comprises 5 levels: the primary three levels make the most of RepMixer blocks for environment friendly processing, whereas the ultimate two levels make use of multi-headed self-attention blocks, creating an optimum steadiness between computational effectivity and high-resolution picture understanding.
Benchmark Comparisons
When put next with ConvLLaVA utilizing the identical LLM and comparable coaching information, FastVLM achieves 8.4% higher efficiency on TextVQA and 12.5% enchancment on DocVQA whereas working 22% sooner. The efficiency benefit will increase at greater resolutions, the place FastVLM maintains 2× sooner processing speeds than ConvLLaVA throughout varied benchmarks. FastVLM matches or surpasses MM1 efficiency throughout various benchmarks through the use of intermediate pretraining with 15M samples for decision scaling, whereas producing 5 occasions fewer visible tokens. Furthermore, FastVLM not solely outperforms Cambrian-1 but additionally runs 7.9 occasions sooner. With scaled instruction tuning, it delivers higher outcomes whereas utilizing 2.3 occasions fewer visible tokens.

Conclusion
In conclusion, researchers launched FastVLM, an development in VLM by using the FastViTHD imaginative and prescient spine for environment friendly high-resolution picture encoding. The hybrid structure, pretrained on strengthened image-text information, reduces visible token output whereas sustaining minimal accuracy sacrifice in comparison with current approaches. FastVLM achieves aggressive efficiency throughout VLM benchmarks whereas delivering notable effectivity enhancements in each TTFT and imaginative and prescient spine parameter rely. Rigorous benchmarking on M1 MacBook Professional {hardware} reveals that FastVLM affords a state-of-the-art resolution-latency-accuracy trade-off superior to the present strategies.
Try the Paper and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this venture. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.

{kind=link}