
Andrej Karpathy has open-sourced nanochat, a compact, dependency-light codebase that implements a full ChatGPT-style stack—from tokenizer coaching to net UI inference—geared toward reproducible, hackable LLM coaching on a single multi-GPU node.
The repo gives a single-script “speedrun” that executes the total loop: tokenization, base pretraining, mid-training on chat/multiple-choice/tool-use knowledge, Supervised Finetuning (SFT), optionally available RL on GSM8K, analysis, and serving (CLI + ChatGPT-like net UI). The really helpful setup is an 8×H100 node; at ~$24/hour, the 4-hour speedrun lands close to $100. A post-run report.md summarizes metrics (CORE, ARC-E/C, MMLU, GSM8K, HumanEval, ChatCORE).
Tokenizer and knowledge path
- Tokenizer: customized Rust BPE (constructed by way of Maturin), with a 65,536-token vocab; coaching makes use of FineWeb-EDU shards (re-packaged/shuffled for easy entry). The walkthrough reviews ~4.8 characters/token compression and compares towards GPT-2/4 tokenizers.
- Eval bundle: a curated set for CORE (22 autocompletion datasets like HellaSwag, ARC, BoolQ, and so forth.), downloaded into
~/.cache/nanochat/eval_bundle.
Mannequin, scaling, and “speedrun” goal
The speedrun config trains a depth-20 Transformer (≈560M params with 1280 hidden channels, 10 consideration heads of dim 128) for ~11.2B tokens in step with Chinchilla-style scaling (params × ~20 tokens). The creator estimates this run as a ~4e19 FLOPs functionality mannequin. Coaching makes use of Muon for matmul parameters and AdamW for embeddings/unembeddings; loss is reported in bits-per-byte (bpb) to be tokenizer-invariant.
Mid-training, SFT, and gear use
After pretraining, mid-training adapts the bottom mannequin to conversations (SmolTalk) and explicitly teaches multiple-choice conduct (100K MMLU auxiliary-train questions) and device use by inserting … blocks; a small GSM8K slice is included to seed calculator-style utilization. The default combination: SmolTalk (460K), MMLU aux-train (100K), GSM8K foremost (8K), totaling 568K rows.
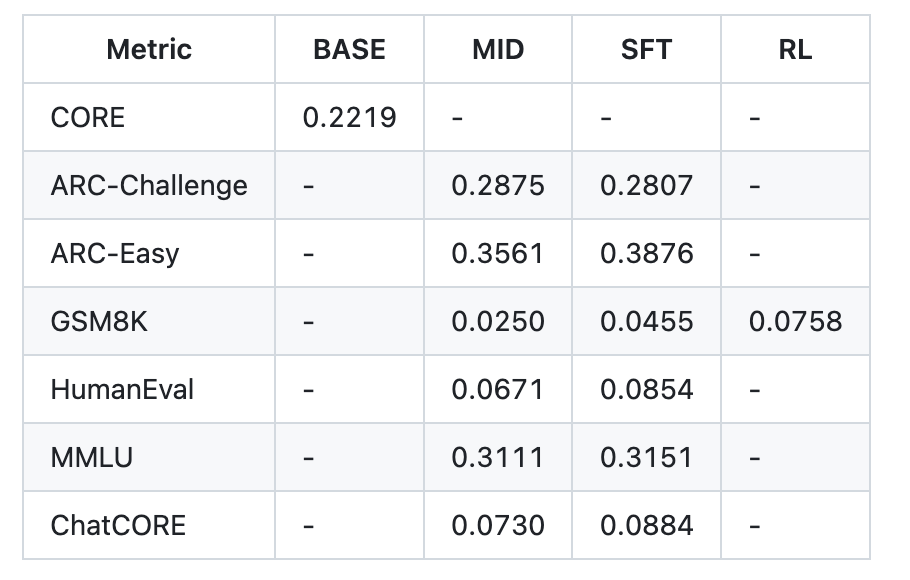
SFT then fine-tunes on higher-quality conversations whereas matching test-time formatting (padded, non-concatenated rows) to scale back prepare/inference mismatch. The repo’s instance post-SFT metrics (speedrun tier) report ARC-Simple 0.3876, ARC-Problem 0.2807, MMLU 0.3151, GSM8K 0.0455, HumanEval 0.0854, ChatCORE 0.0884.
Device use is wired end-to-end: the customized Engine implements KV cache, prefill/decode inference, and a easy Python interpreter sandbox for tool-augmented runs—utilized in each coaching and analysis flows.
Non-obligatory RL on GSM8K by way of a simplified GRPO loop
The ultimate (optionally available) stage applies reinforcement studying on GSM8K with a simplified GRPO routine. The walkthrough clarifies what’s omitted relative to canonical PPO-style RLHF: no belief area by way of a reference mannequin, no KL penalties, on-policy updates (discard PPO ratios/clip), token-level GAPO-style normalization, and mean-shift benefit. Virtually, it behaves near REINFORCE whereas retaining the group-relative benefit calculation. Scripts scripts.chat_rl and scripts.chat_eval -i rl -a GSM8K display the loop.
Price/high quality scaling and greater fashions
The README sketches two bigger targets past the ~$100 speedrun:
- ~$300 tier: d=26 (~12 hours), barely surpasses GPT-2 CORE; requires extra pretraining shards and batch-size changes.
- ~$1,000 tier: ~41.6 hours, with materially improved coherence and primary reasoning/coding capacity.
The repo additionally word prior experimental runs the place a d=30 mannequin educated for ~24 hours reached 40s on MMLU, 70s on ARC-Simple, 20s on GSM8K.
Analysis snapshot (speedrun tier)
An instance report.md desk for the ~$100/≈4-hour run exhibits: CORE 0.2219 (base); after mid-training/SFT, ARC-E 0.3561→0.3876, ARC-C ~0.2875→0.2807, MMLU 0.3111→0.3151, GSM8K 0.0250→0.0455, HumanEval 0.0671→0.0854, ChatCORE 0.0730→0.0884; wall-clock 3h51m.
Key Takeaways
- nanochat is a minimal, end-to-end ChatGPT-style stack (~8K LOC) that runs by way of a single
speedrun.shon one 8×H100 node (~4h ≈ $100). - The pipeline covers tokenizer (Rust BPE), base pretraining, mid-training, SFT, optionally available RL on GSM8K (simplified GRPO), analysis, and serving (CLI + Internet UI).
- Speedrun metrics (instance
report.md): CORE 0.2219 base; after SFT—ARC-Simple 0.3876, ARC-Problem 0.2807, MMLU 0.3151, GSM8K 0.0455, HumanEval 0.0854. - Scaling tiers are outlined: ~$300 (d=26, ~12h) “barely outperforms GPT-2 CORE”; ~$1,000 (~41.6h) for materially higher coherence/reasoning.
Karpathy’s nanochat lands in a helpful center floor: a single, clear, dependency-light repository that stitches tokenizer coaching (Rust BPE), pretraining on FineWeb-EDU, mid-training (SmolTalk/MMLU aux/GSM8K with device use tags), SFT, optionally available simplified GRPO on GSM8K, and a skinny Engine (KV cache, prefill/decode, Python interpreter) right into a reproducible speedrun on an 8×H100 node, producing a traceable report.md with CORE/ARC/MMLU/GSM8K/HumanEval and a minimal Internet UI.
Try the Technical particulars and Codes. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}