
At AWS re:Invent 2025, Amazon Internet Companies (AWS) introduced serverless storage for Amazon EMR Serverless, a brand new functionality that eliminates the necessity configure native disks for Apache Spark workloads. This reduces knowledge processing prices by as much as 20% whereas eliminating job failures from disk capability constraints.
With serverless storage, Amazon EMR Serverless routinely handles intermediate knowledge operations, corresponding to shuffle, in your behalf. You pay just for compute and reminiscence—no storage expenses. By decoupling storage from compute, Spark can launch idle staff instantly, lowering prices all through the job lifecycle. The next picture exhibits the serverless storage for EMR Serverless announcement from the AWS re:Invent 2025 keynote:

The problem: Sizing native disk storage
Operating Apache Spark workloads requires sizing native disk storage for shuffle operations—the place Spark redistributes knowledge throughout executors throughout joins, aggregations, and types. This requires analyzing job histories to estimate disk necessities, main to 2 widespread issues: overprovisioning wastes cash on unused capability, and below provisioning causes job failures when disk house runs out. Most clients overprovision native storage to make sure jobs full efficiently in manufacturing.
Knowledge skew compounds this additional. When one executor handles a disproportionately massive partition, that executor takes considerably longer to finish whereas different staff sit idle. If you happen to didn’t provision sufficient disk for that skewed executor, the job fails totally—making knowledge skew one of many prime causes of Spark job failures. Nonetheless, the issue extends past capability planning. As a result of shuffle knowledge {couples} tightly to native disks, Spark executors pin to employee nodes even when compute necessities drop between job levels. This prevents Spark from releasing staff and cutting down, inflating compute prices all through the job lifecycle. When a employee node fails, Spark should recompute the shuffle knowledge saved on that node, inflicting delays and inefficient useful resource utilization.
The way it works
Serverless storage for Amazon EMR Serverless addresses these challenges by offloading shuffle operations from particular person compute staff onto a separate, elastic storage layer. As an alternative of storing essential knowledge on native disks connected to Spark executors, serverless storage routinely provisions and scales high-performance distant storage as your job runs.
The structure offers a number of key advantages. First, compute and storage scale independently—Spark can purchase and launch staff as wanted throughout job levels with out worrying about preserving domestically saved knowledge. Second, shuffle knowledge is evenly distributed throughout the serverless storage layer, eliminating knowledge skew bottlenecks that happen when some executors deal with disproportionately massive shuffle partitions. Third, if a employee node fails, your job continues processing with out delays or reruns as a result of knowledge is reliably saved exterior particular person compute staff.
Serverless storage is offered at no extra cost, and it eliminates the price related to native storage. As an alternative of paying for mounted disk capability sized for max potential I/O load—capability that always sits idle throughout lighter workloads—you need to use serverless storage with out incurring storage prices. You may focus your price range on compute assets that straight course of your knowledge, not on managing and overprovisioning disk storage.
Technical innovation brings three breakthroughs
Serverless storage introduces three basic improvements that remedy Spark’s shuffle bottlenecks: multi-tier aggregation structure, purpose-built networking, and true storage-compute decoupling. Apache Spark’s shuffle mechanism has a core constraint: every mapper independently writes output as small information, and every reducer should fetch knowledge from probably hundreds of staff. In a large-scale job with 10,000 mappers and 1,000 reducers, this creates 10 million particular person knowledge exchanges. Serverless storage aggregates early and intelligently—mappers stream knowledge to an aggregation layer that consolidates shuffle knowledge in reminiscence earlier than committing to storage. Whereas particular person shuffle write and fetch operations may present barely larger latency as a result of community round-trips in comparison with native disk I/O, the general job efficiency improves by remodeling hundreds of thousands of tiny I/O operations right into a smaller variety of massive, sequential operations.
Conventional Spark shuffle creates a mesh community the place every employee maintains connections to probably a whole bunch of different staff, spending vital CPU on connection administration relatively than knowledge processing. We constructed a customized networking stack the place every mapper opens a single persistent distant process name (RPC) connection to our aggregator layer, eliminating the mesh complexity. Though particular person shuffle operations may present barely larger latency as a result of community spherical journeys in comparison with native disk I/O, general job efficiency improves by higher useful resource utilization and elastic scaling. Staff not run a shuffle service—they focus totally on processing your knowledge.
Conventional Amazon EMR Serverless jobs retailer shuffle knowledge on native disks, coupling knowledge lifecycle to employee lifecycle—idle staff can’t terminate with out shedding shuffle knowledge. Serverless storage decouples these totally by storing shuffle knowledge in AWS managed storage with opaque handles tracked by the driving force. Staff can terminate instantly after finishing duties with out knowledge loss, enabling elastic scaling. In funnel-shaped queries the place early levels require large parallelism that narrows as knowledge aggregates, we’re seeing as much as 80% compute value discount in benchmarks by releasing idle staff immediately. The next diagram illustrates instantaneous employee launch in funnel-shaped queries.
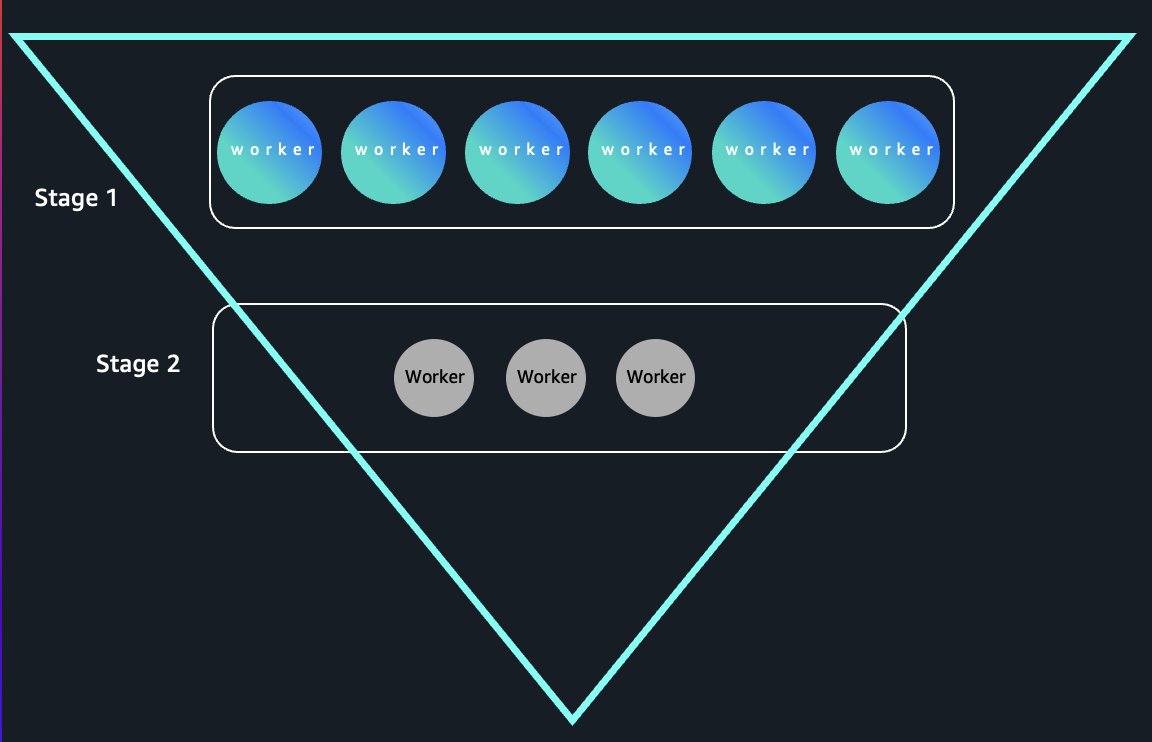
Our aggregator layer integrates straight with AWS Identification and Entry Administration (IAM), AWS Lake Formation, and fine-grained entry management techniques, offering job-level knowledge isolation with entry controls that match supply knowledge permissions.
Getting began
Serverless storage is out there in a number of AWS Areas. For the present listing of supported Areas, seek advice from the Amazon EMR Person Information.
New functions
Serverless storage could be enabled for brand spanking new functions beginning with Amazon EMR launch 7.12. Observe these steps:
- Create an Amazon EMR Serverless software with Amazon EMR 7.12 or later:
- Submit your Spark job:
Current functions
You may allow serverless storage for current functions on Amazon EMR 7.12 or later by updating your software settings.
To allow serverless storage utilizing AWS Command Line Interface (AWS CLI), enter the next command:
To allow serverless storage utilizing Amazon EMR Studio UI, navigate to your software in Amazon EMR Studio, go to Configuration, and add the Spark property spark.aws.serverlessStorage.enabled=true within the spark-defaults classification.
Job-level configuration
You can even allow serverless storage for particular jobs, even when it’s not enabled on the software degree:
(Optionally available) Disabling serverless storage
If you happen to desire to proceed utilizing native disks, you possibly can disable serverless storage by omitting the spark.aws.serverlessStorage.enabled configuration or setting it to false at both the appliance or job degree:
spark.aws.serverlessStorage.enabled=falseTo make use of conventional native disk provisioning, configure the suitable disk sort and measurement on your software staff.
Monitoring and price monitoring
You may monitor elastic shuffle utilization by normal Spark UI metrics and observe prices on the software degree in AWS Value Explorer and AWS Value and Utilization Stories. The service routinely handles efficiency optimization and scaling, so that you don’t have to tune configuration parameters.
When to make use of serverless storage
Serverless storage delivers probably the most worth for workloads with substantial shuffle operations—sometimes jobs that shuffle greater than 10 GB of information (and fewer than 200 G per job, the limitation as of this writing). These embody:
- Massive-scale knowledge processing with heavy aggregations and joins
- Kind-heavy analytics workloads
- Iterative algorithms that repeatedly entry the identical datasets
Jobs with unpredictable shuffle sizes profit notably nicely as a result of serverless storage routinely scales capability up and down based mostly on real-time demand. For workloads with minimal shuffle exercise or very brief length (below 2–3 minutes), the advantages could be restricted. In these circumstances, the overhead of distant storage entry may outweigh some great benefits of elastic scaling.
Safety and knowledge lifecycle
Your knowledge is saved in serverless storage solely whereas your job is working and is routinely deleted when your job is accomplished. As a result of Amazon EMR Serverless batch jobs can run for as much as 24 hours, your knowledge will probably be saved for not than this most length. Serverless storage encrypts your knowledge each in transit between your Amazon EMR Serverless software and the serverless storage layer and at relaxation whereas quickly saved, utilizing AWS managed encryption keys. The service makes use of an IAM based mostly safety mannequin with job-level knowledge isolation, which signifies that one job can’t entry the shuffle knowledge of one other job. Serverless storage maintains the identical safety requirements as Amazon EMR Serverless, with enterprise-grade safety controls all through the processing lifecycle.
Conclusion
Serverless storage represents a basic shift in how we method knowledge processing infrastructure, eliminating handbook configuration, aligning prices to precise utilization, and bettering reliability for I/O intensive workloads. By offloading shuffle operations to a managed service, knowledge engineers can give attention to constructing analytics relatively than managing storage infrastructure.
To study extra about serverless storage and get began, go to the Amazon EMR Serverless documentation.
In regards to the authors

{kind=link}