 With FP8 Checkpoints")
Do you really need an enormous VLM when dense Qwen3-VL 4B/8B (Instruct/Considering) with FP8 runs in low VRAM but retains 256K→1M context and the complete functionality floor? Alibaba’s Qwen group has expanded its multimodal lineup with dense Qwen3-VL fashions at 4B and 8B scales, every transport in two activity profiles—Instruct and Considering—plus FP8-quantized checkpoints for low-VRAM deployment. The drop arrives as a smaller, edge-friendly complement to the beforehand launched 30B (MoE) and 235B (MoE) tiers and retains the identical functionality floor: picture/video understanding, OCR, spatial grounding, and GUI/agent management.
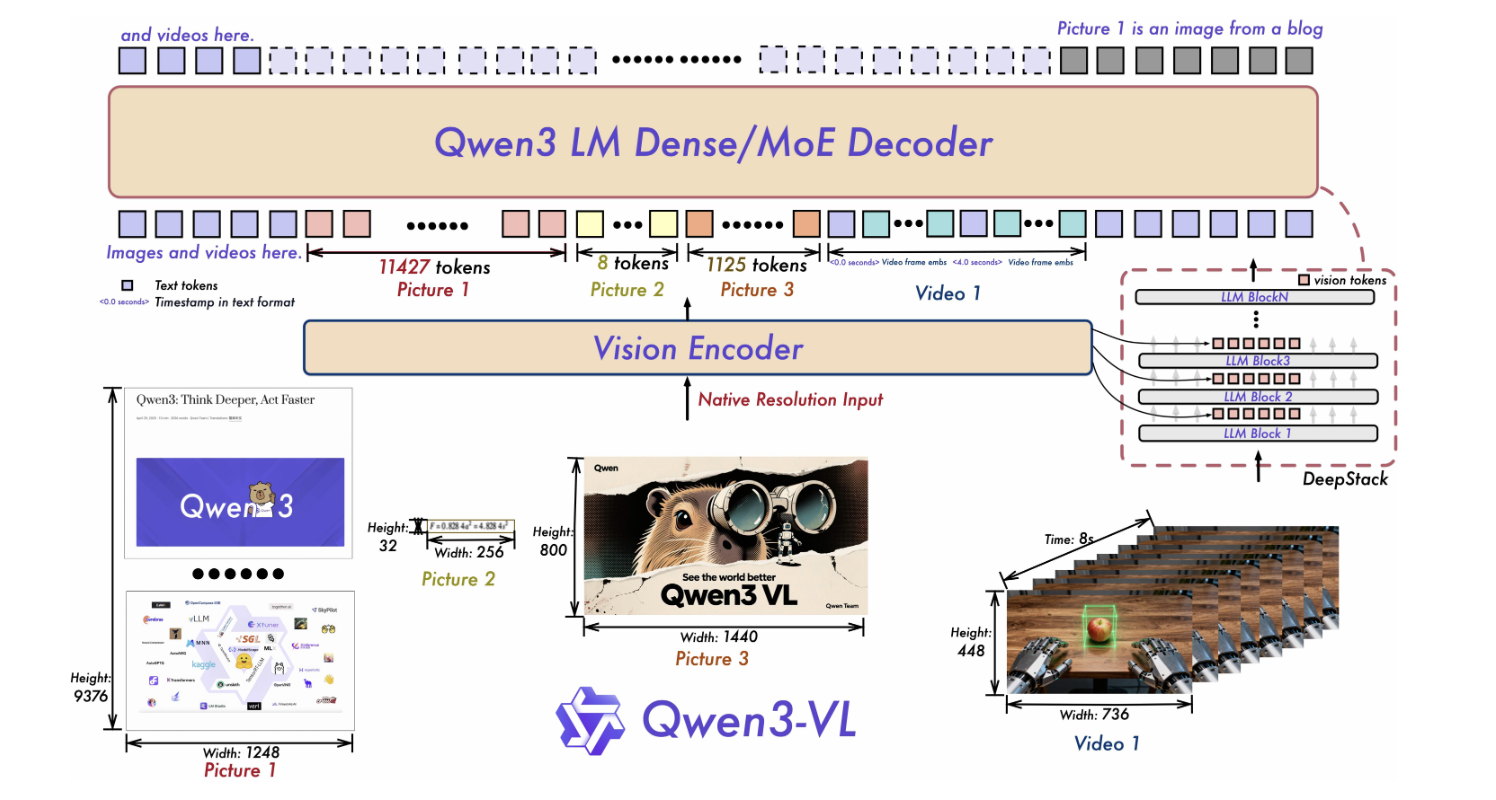
What’s within the launch?
SKUs and variants: The brand new additions comprise 4 dense fashions—Qwen3-VL-4B and Qwen3-VL-8B, every in Instruct and Considering editions—alongside FP8 variations of the 4B/8B Instruct and Considering checkpoints. The official announcement explicitly frames these as “compact, dense” fashions with decrease VRAM utilization and full Qwen3-VL capabilities retained.
Context size and functionality floor: The mannequin playing cards record native 256K context with expandability to 1M, and doc the complete characteristic set: long-document and video comprehension, 32-language OCR, 2D/3D spatial grounding, visible coding, and agentic GUI management on desktop and cellular. These attributes carry over to the brand new 4B/8B SKUs.
Structure notes: Qwen3-VL highlights three core updates: Interleaved-MRoPE for sturdy positional encoding over time/width/peak (long-horizon video), DeepStack for fusing multi-level ViT options and sharpening picture–textual content alignment, and Textual content–Timestamp Alignment past T-RoPE for occasion localization in video. These design particulars seem within the new playing cards as properly, signaling architectural continuity throughout sizes.
Mission timeline: The Qwen3-VL GitHub “Information” part data the publication of Qwen3-VL-4B (Instruct/Considering) and Qwen3-VL-8B (Instruct/Considering) on Oct 15, 2025, following earlier releases of the 30B MoE tier and organization-wide FP8 availability.
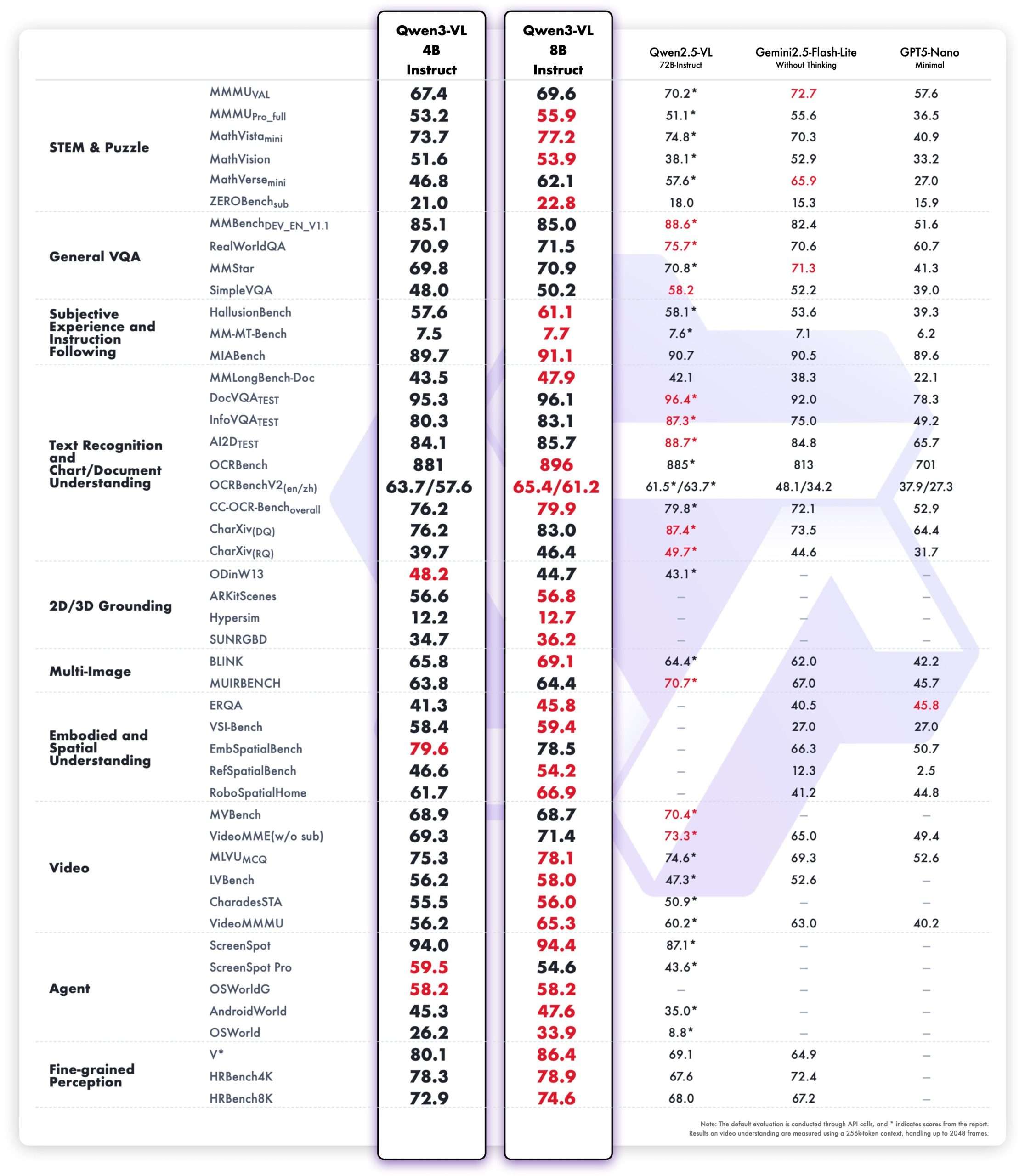
FP8: deployment-relevant particulars
Numerics and parity declare: The FP8 repositories state fine-grained FP8 quantization with block dimension 128, with efficiency metrics almost equivalent to the unique BF16 checkpoints. For groups evaluating precision trade-offs on multimodal stacks (imaginative and prescient encoders, cross-modal fusion, long-context consideration), having vendor-produced FP8 weights reduces re-quantization and re-validation burden.
Tooling standing: The 4B-Instruct-FP8 card notes that Transformers doesn’t but load these FP8 weights straight, and recommends vLLM or SGLang for serving; the cardboard contains working launch snippets. Individually, the vLLM recipes information recommends FP8 checkpoints for H100 reminiscence effectivity. Collectively, these level to instant, supported paths for low-VRAM inference.
Key Takeaways
- Qwen launched dense Qwen3-VL 4B and 8B fashions, every in Instruct and Considering variants, with FP8 checkpoints.
- FP8 makes use of fine-grained FP8 (block dimension 128) with near-BF16 metrics; Transformers loading shouldn’t be but supported—use vLLM/SGLang.
- Functionality floor is preserved: 256K→1M context, 32-language OCR, spatial grounding, video reasoning, and GUI/agent management.
- Mannequin Card-reported sizes: Qwen3-VL-4B ≈ 4.83B params; Qwen3-VL-8B-Instruct ≈ 8.77B params.
Qwen’s choice to ship dense Qwen3-VL 4B/8B in each Instruct and Considering types with FP8 checkpoints is the sensible a part of the story: lower-VRAM, deployment-ready weights (fine-grained FP8, block dimension 128) and specific serving steerage (vLLM/SGLang) makes it simply deployable. The aptitude floor—256K context expandable to 1M, 32-language OCR, spatial grounding, video understanding, and agent management—stays intact at these smaller scales, which issues greater than leaderboard rhetoric for groups concentrating on single-GPU or edge budgets.
Try the Mannequin on Hugging Face and GitHub Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}