
Introduction: The Rise of GUI Brokers
Fashionable computing is dominated by graphical consumer interfaces throughout units—cell, desktop, and net. Automating duties in these environments has historically been restricted to scripted macros or brittle, hand-engineered guidelines. Current advances in vision-language fashions provide the tantalizing risk of brokers that may perceive screens, purpose about duties, and execute actions identical to people. Nonetheless, most approaches have both relied on closed-source, black-box fashions or have struggled with generalizability, reasoning constancy, and cross-platform robustness.
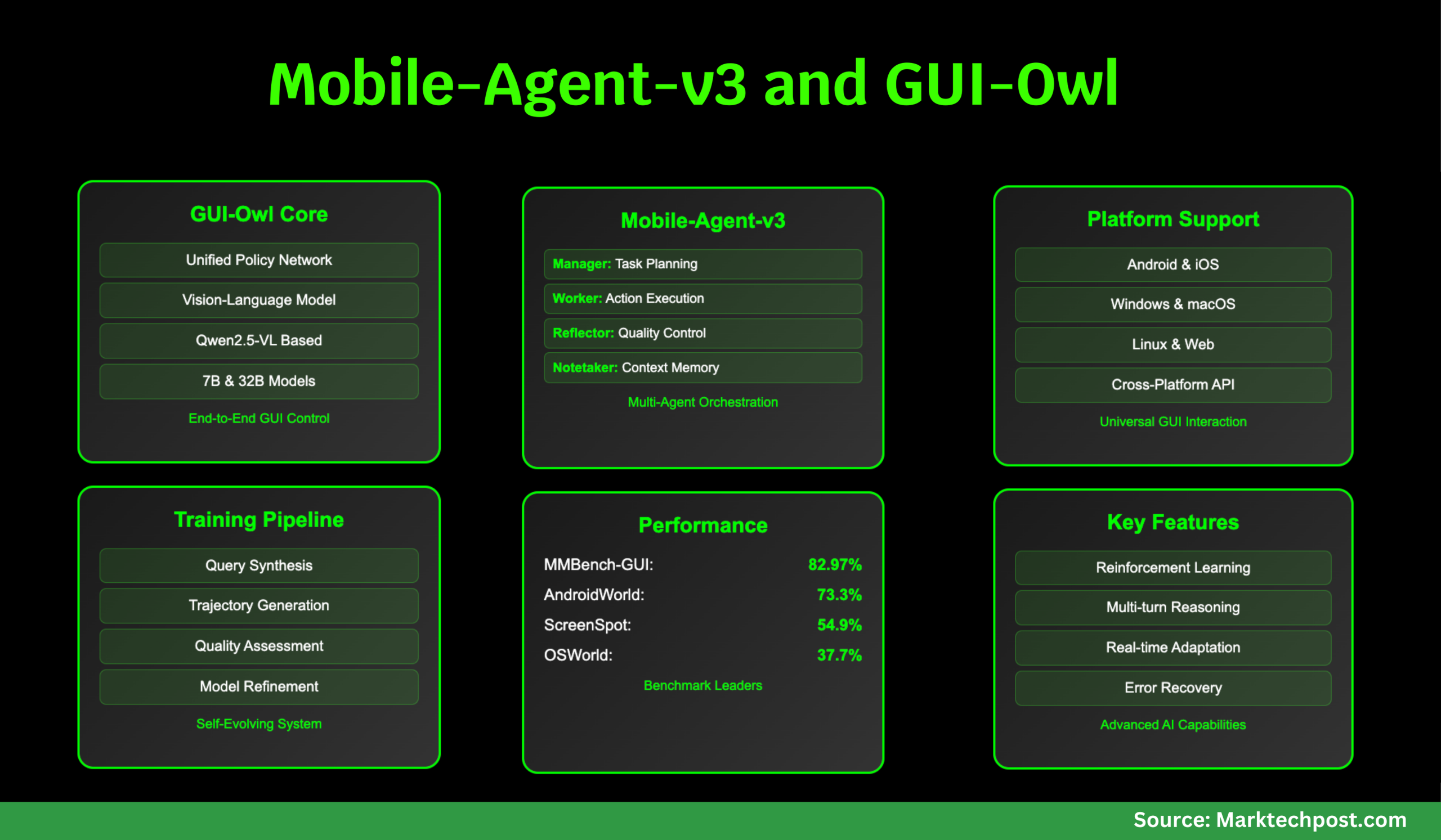
A staff of researchers from Alibaba Qwen introduce GUI-Owl and Cell-Agent-v3 that these challenges head-on. GUI-Owl is a local, end-to-end multimodal agent mannequin, constructed on Qwen2.5-VL and extensively post-trained on large-scale, numerous GUI interplay knowledge. It unifies notion, grounding, reasoning, planning, and motion execution inside a single coverage community, enabling strong cross-platform interplay and specific multi-turn reasoning. The Cell-Agent-v3 framework leverages GUI-Owl as a foundational module, orchestrating a number of specialised brokers (Supervisor, Employee, Reflector, Notetaker) to deal with complicated, long-horizon duties with dynamic planning, reflection, and reminiscence.
Structure and Core Capabilities
GUI-Owl: The Foundational Mannequin
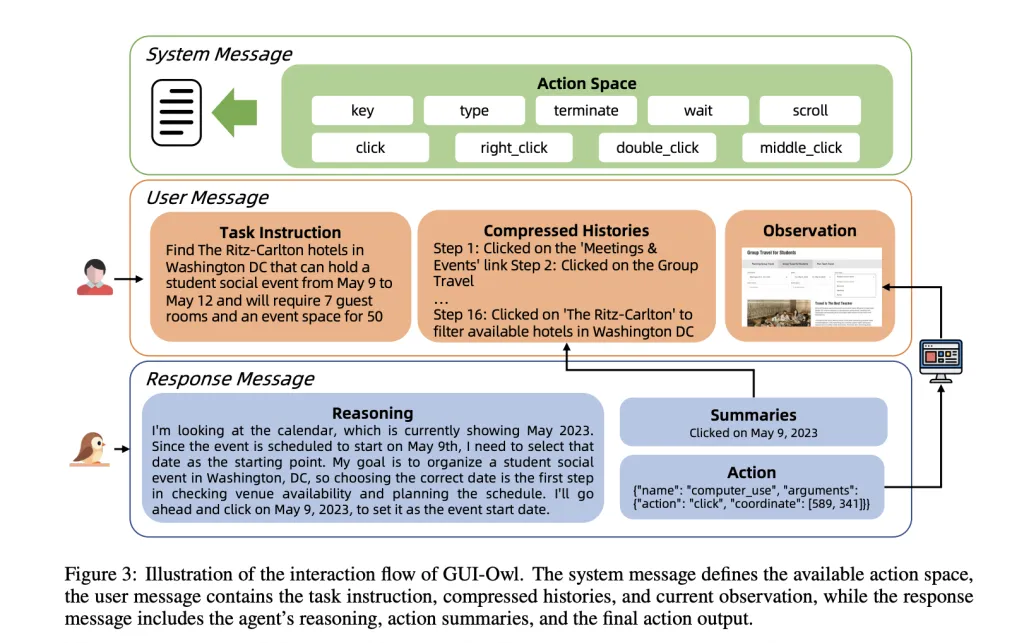
GUI-Owl is designed from the bottom as much as deal with the heterogeneity and dynamism of real-world GUI environments. It’s initialized from Qwen2.5-VL, a state-of-the-art vision-language mannequin, however undergoes intensive extra coaching on specialised GUI datasets. This contains grounding (finding UI components from pure language queries), activity planning (breaking down complicated directions into actionable steps), and motion semantics (understanding how actions have an effect on the GUI state). The mannequin is fine-tuned through a mixture of supervised studying and reinforcement studying (RL), with a concentrate on aligning its selections with real-world activity success.
Key Improvements in GUI-Owl:
- Unified Coverage Community: Not like prior analysis that separates notion, planning, and execution into disjoint modules, GUI-Owl integrates these capabilities right into a single neural community. This enables for seamless multi-turn decision-making and specific intermediate reasoning—essential for dealing with the paradox and variability of actual GUIs.
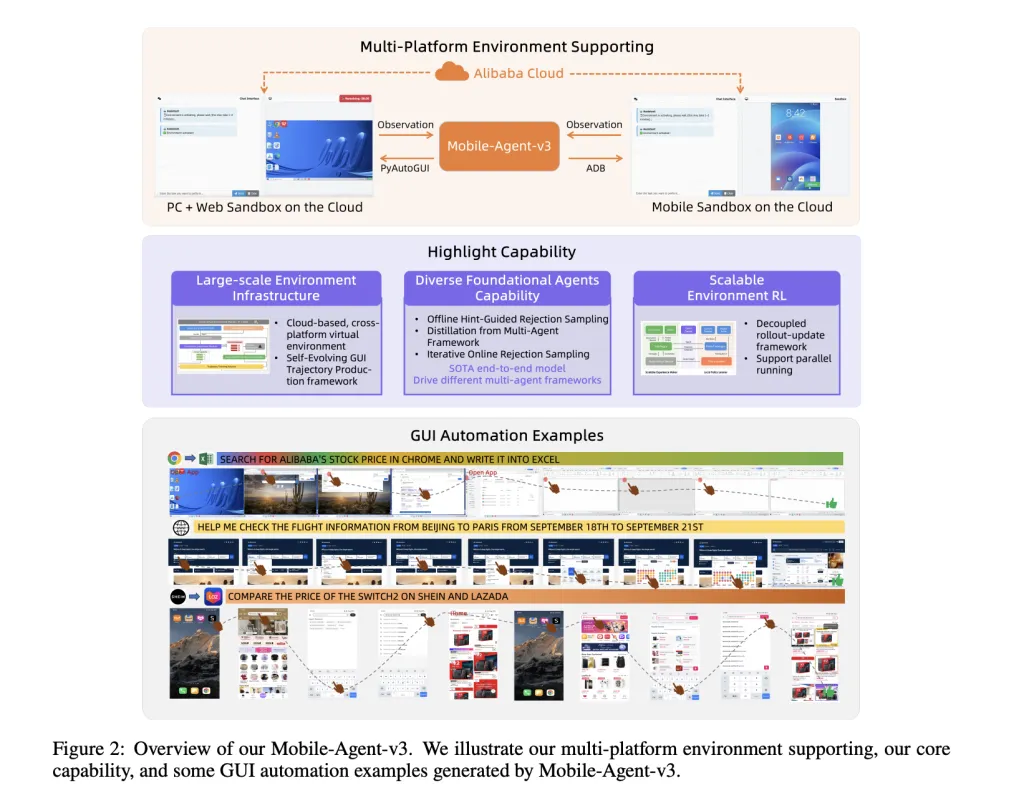
- Scalable Coaching Infrastructure: The staff constructed a cloud-based digital atmosphere spanning Android, Ubuntu, macOS, and Home windows. This “Self-Evolving GUI Trajectory Manufacturing” pipeline generates high-quality interplay knowledge by having GUI-Owl and Cell-Agent-v3 work together with digital units, then rigorously judging the correctness of trajectories. Profitable trajectories are used for additional coaching, making a virtuous cycle of enchancment.
- Various Information Synthesis: To show the mannequin strong grounding and reasoning, the analysis staff make use of a wide range of knowledge synthesis methods: synthesizing UI aspect grounding duties from accessibility bushes and crawled screenshots, distilling activity planning information from each historic trajectories and huge pretrained LLMs, and producing motion semantics knowledge by having the mannequin predict the impact of actions given before-and-after screenshots.
- Reinforcement Studying Alignment: GUI-Owl is additional refined through a scalable RL framework that helps totally asynchronous coaching and a novel “Trajectory-aware Relative Coverage Optimization” (TRPO). TRPO assigns credit score throughout lengthy, variable-length motion sequences—a important advance for GUI duties the place rewards are sparse and solely accessible upon activity completion.
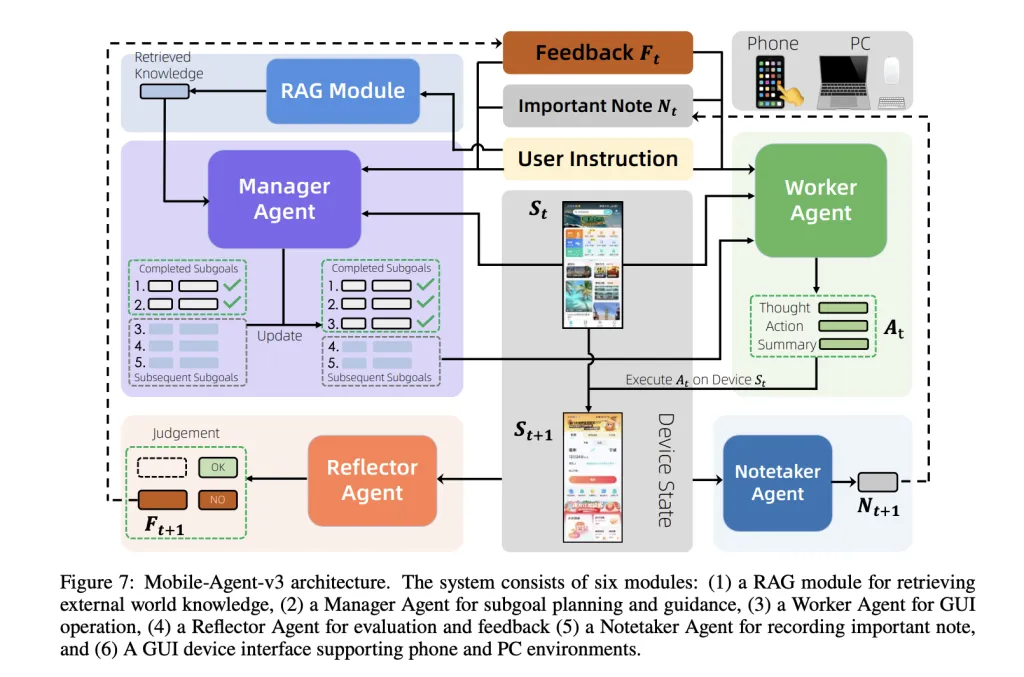
Cell-Agent-v3: Multi-Agent Coordination
Cell-Agent-v3 is a general-purpose agentic framework designed to sort out complicated, multi-step, and cross-application workflows. It breaks duties into subgoals, dynamically updates plans primarily based on execution suggestions, and maintains persistent contextual reminiscence. The framework coordinates 4 specialised brokers:
- Supervisor Agent: Decomposes high-level directions into subgoals, dynamically updating the plan primarily based on outcomes and suggestions.
- Employee Agent: Executes probably the most related actionable subgoal given the present GUI state, prior suggestions, and amassed notes.
- Reflector Agent: Evaluates the result of every motion, evaluating meant and precise state transitions to generate diagnostic suggestions.
- Notetaker Agent: Persists important data (e.g., codes, credentials) throughout software boundaries, enabling long-horizon duties.
Coaching and Information Pipeline
A serious bottleneck in GUI agent improvement is the shortage of high-quality, scalable coaching knowledge. Conventional approaches depend on costly handbook annotation, which doesn’t scale to the variety and dynamism of actual GUIs. The GUI-Owl staff addresses this with a self-evolving knowledge manufacturing pipeline:
- Question Technology: For cell apps, a human-annotated directed acyclic graph (DAG) fashions sensible navigation flows and slot-value pairs for consumer inputs. LLMs synthesize pure directions from these paths, that are additional refined and validated towards actual app interfaces.
- Trajectory Technology: Given a question, GUI-Owl or Cell-Agent-v3 interacts with a digital atmosphere to provide a trajectory—a sequence of actions and state transitions.
- Trajectory Correctness Judgment: A two-level critic system evaluates every step (did the motion have the meant impact?) and the general trajectory (did the duty succeed?). This makes use of each textual and multimodal reasoning, with consensus-based last judgments.
- Steering Synthesis: For difficult queries, the system synthesizes step-by-step steerage from profitable (human or mannequin) trajectories, serving to the agent study from constructive examples.
- Iterative Coaching: Newly generated profitable trajectories are added to the coaching set, and the mannequin is retrained, closing the loop on self-improvement.
Benchmarking and Efficiency
GUI-Owl and Cell-Agent-v3 are rigorously evaluated throughout a set of GUI automation benchmarks, overlaying grounding, single-step decision-making, query answering, and end-to-end activity completion.
Grounding and UI Understanding
On grounding duties—finding UI components from pure language queries—GUI-Owl-7B outperforms all open-source fashions of comparable dimension, and GUI-Owl-32B surpasses even proprietary fashions like GPT-4o and Claude 3.7. For instance, on the MMBench-GUI L2 benchmark (overlaying Home windows, macOS, Linux, iOS, Android, and Internet), GUI-Owl-7B scores 80.49, whereas GUI-Owl-32B achieves 82.97, each nicely forward of the competitors. On ScreenSpot Professional, which focuses on high-resolution, complicated interfaces, GUI-Owl-7B scores 54.9, considerably outperforming UI-TARS-72B and Qwen2.5-VL-72B. These outcomes show that GUI-Owl’s grounding capabilities are each broad and deep, dealing with every part from easy button clicks to fine-grained textual content localization.
Complete GUI Understanding and Single-Step Resolution Making
MMBench-GUI L1 evaluates UI understanding and single-step decision-making by means of question-answering. Right here, GUI-Owl-7B scores 84.5 (straightforward), 86.9 (medium), and 90.9 (laborious), far outpacing all present fashions. This means not simply correct notion, however strong reasoning about interface states and actions. On Android Management, which focuses on single-step selections in pre-annotated contexts, GUI-Owl-7B achieves 72.8, the very best amongst 7B fashions, whereas GUI-Owl-32B reaches 76.6, surpassing even the most important open and proprietary fashions.
Finish-to-Finish and Multi-Agent Capabilities
The true check of a GUI agent is its skill to finish actual, multi-step duties in interactive environments. AndroidWorld and OSWorld are two such benchmarks, the place brokers should autonomously navigate apps and working programs to perform consumer directions. GUI-Owl-7B scores 66.4 on AndroidWorld and 34.9 on OSWorld, whereas Cell-Agent-v3 (with GUI-Owl as its core) achieves 73.3 and 37.7, respectively—a brand new state-of-the-art for open-source frameworks. The multi-agent design proves particularly efficient on long-horizon, error-prone duties, because the Reflector and Supervisor brokers allow dynamic replanning and restoration from errors.
Actual-World Integration
The analysis staff additionally evaluated GUI-Owl’s efficiency because the “mind” inside established agentic frameworks like Cell-Agent-E (Android) and Agent-S2 (desktop). Right here, GUI-Owl-32B achieves 62.1% success on AndroidWorld and 48.4% on a difficult subset of OSWorld, considerably outperforming all baselines. This underscores GUI-Owl’s sensible worth as a plug-and-play module for numerous agent programs.
Actual-World Deployment
GUI-Owl helps a wealthy, platform-specific motion house. On cell, this contains clicks, lengthy presses, swipes, textual content entry, system buttons (again, house, and so forth.), and software launching. On desktop, actions embody mouse strikes, clicks, drags, scrolls, keyboard enter, and application-specific instructions. Actions are translated into low-level system instructions (ADB for Android, pyautogui for desktop), making the framework readily deployable in actual environments.
The agent’s reasoning and determination course of is clear: for every step, it observes the display screen, recollects compressed historical past, causes in regards to the subsequent motion, summarizes its intent, and executes. This specific intermediate reasoning not solely improves robustness but additionally permits integration into bigger multi-agent programs, the place totally different “roles” (e.g., planner, executor, critic) can specialize and collaborate.
Conclusion: Towards Basic-Objective GUI Brokers
GUI-Owl and Cell-Agent-v3 characterize a serious leap towards general-purpose, autonomous GUI brokers. By unifying notion, grounding, reasoning, and motion right into a single mannequin, and by constructing a scalable, self-improving coaching pipeline, the analysis staff have achieved state-of-the-art efficiency throughout each cell and desktop environments, surpassing even the most important proprietary fashions in key benchmarks.
Try the PAPER and GITHUB PAGE. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}