
Ever for the reason that launch of the unique GPT-2 fashions, OpenAI has not too long ago shared 2 open-source fashions with the open neighborhood. Extra not too long ago, the discharge of gpt-oss-20B and gpt-oss-120B marked an thrilling step ahead, receiving robust suggestions from the open-source ecosystem. These fashions launched a number of architectural improvements that make them notably environment friendly and succesful.
On the identical time, massive reasoning fashions like OpenAI’s o3 have proven how producing structured chains of thought can enhance response accuracy and high quality. Nonetheless, regardless of their strengths, present OSS fashions nonetheless face a notable disadvantage: they battle with deep reasoning, multi-step logic, and superior math.
Which is why fine-tuning and alignment are important. By leveraging reinforcement studying and curated datasets, we are able to form OSS fashions to purpose extra reliably and keep away from biased or unsafe outputs. On this weblog, we’ll discover the best way to fine-tune gpt-oss-20B utilizing a multilingual considering dataset from Hugging Face, enabling the mannequin to ship extra correct, logical, and reliable outcomes throughout numerous contexts.
Finetuning LLMs
Advantageous-tuning a massive language mannequin (LLM) might sound advanced, however the course of might be damaged down into 5 clear steps. On this weblog, we’ll stroll by these phases utilizing gpt-oss-20B and a multilingual considering dataset from Hugging Face to enhance reasoning efficiency and alignment.
1. Setup
Step one is to put in all the required libraries and dependencies. This consists of frameworks like Hugging Face Transformers, Speed up, PEFT (Parameter-Environment friendly Advantageous-Tuning), TRL, and different utilities that may assist us run coaching effectively on GPUs.
2. Put together the Dataset
Subsequent, we’ll obtain and preprocess the multilingual considering dataset from Hugging Face. The info must be formatted into an instruction-response type, making certain the mannequin learns step-by-step reasoning throughout completely different languages.
3. Put together the Mannequin
We’ll then load the bottom gpt-oss-20B mannequin and configure it for fine-tuning. As a substitute of updating all parameters (which might be extraordinarily resource-intensive), we’ll use LoRA (Low-Rank Adaptation). This memory-efficient method updates solely small adapter weights whereas maintaining the principle mannequin frozen.
4. Advantageous-Tuning
With every thing in place, we prepare the mannequin on our reasoning dataset. Throughout this part, reinforcement studying methods will also be utilized to align the mannequin’s habits, scale back biases, and encourage secure, logical outputs.
5. Inference
Lastly, we check the fine-tuned mannequin by producing reasoning responses in a number of languages. This permits us to guage how nicely the mannequin handles advanced, multi-step logic throughout numerous linguistic contexts.
The {Hardware}
The parameters (the weights the mannequin has learnt) are the first memory-consuming issue when fine-tuning a mannequin. Since every parameter is 4 bytes, a 20-billion-parameter mannequin already requires round 80 GB of reminiscence simply to retailer the weights in commonplace 32-bit precision. This quantity decreases to about 40 GB and even 10 GB only for the weights if we use smaller codecs, similar to 16-bit or 4-bit. Nonetheless, coaching additionally requires optimiser states, gradients, and non permanent buffers, which add much more on high of weights alone.
Novices discover that LoRA or QLoRA fine-tuning is a helpful answer. You prepare solely small adapter layers and freeze the unique weights somewhat than updating all 20B parameters. The adapters add little or no, and the frozen base mannequin might solely require about 10 GB with quantisation (4-bit). Operating on a single high-end GPU (similar to 48GB or 80GB playing cards) is possible as a result of this technique usually suits inside 30 to 50 GB of GPU reminiscence. LoRA/QLoRA is way more efficient and reasonable than full fine-tuning, which is why most individuals working with 20B+ fashions use it.
So as to perceive the whole strategy of fine-tuning the GPT OSS 20 B mannequin, we are going to fastidiously go over every of those steps.
So, Runpod, a GPU provider, shall be used for the {hardware} configuration. You possibly can entry RunPod from the next hyperlink: https://console.runpod.io/
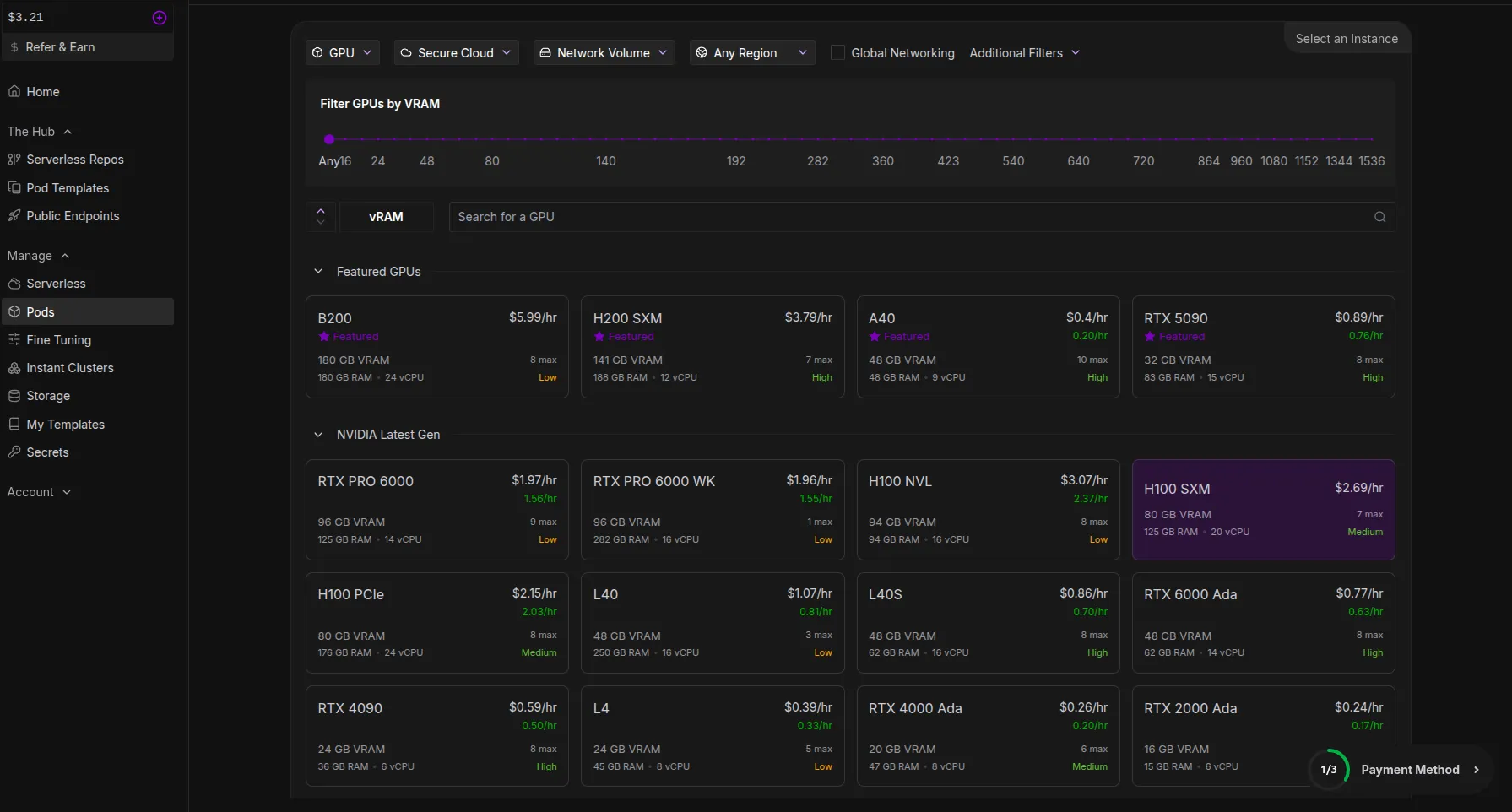
We’ll be utilizing the H100 SXM GPU mannequin, which has 80 GB of VRAM.
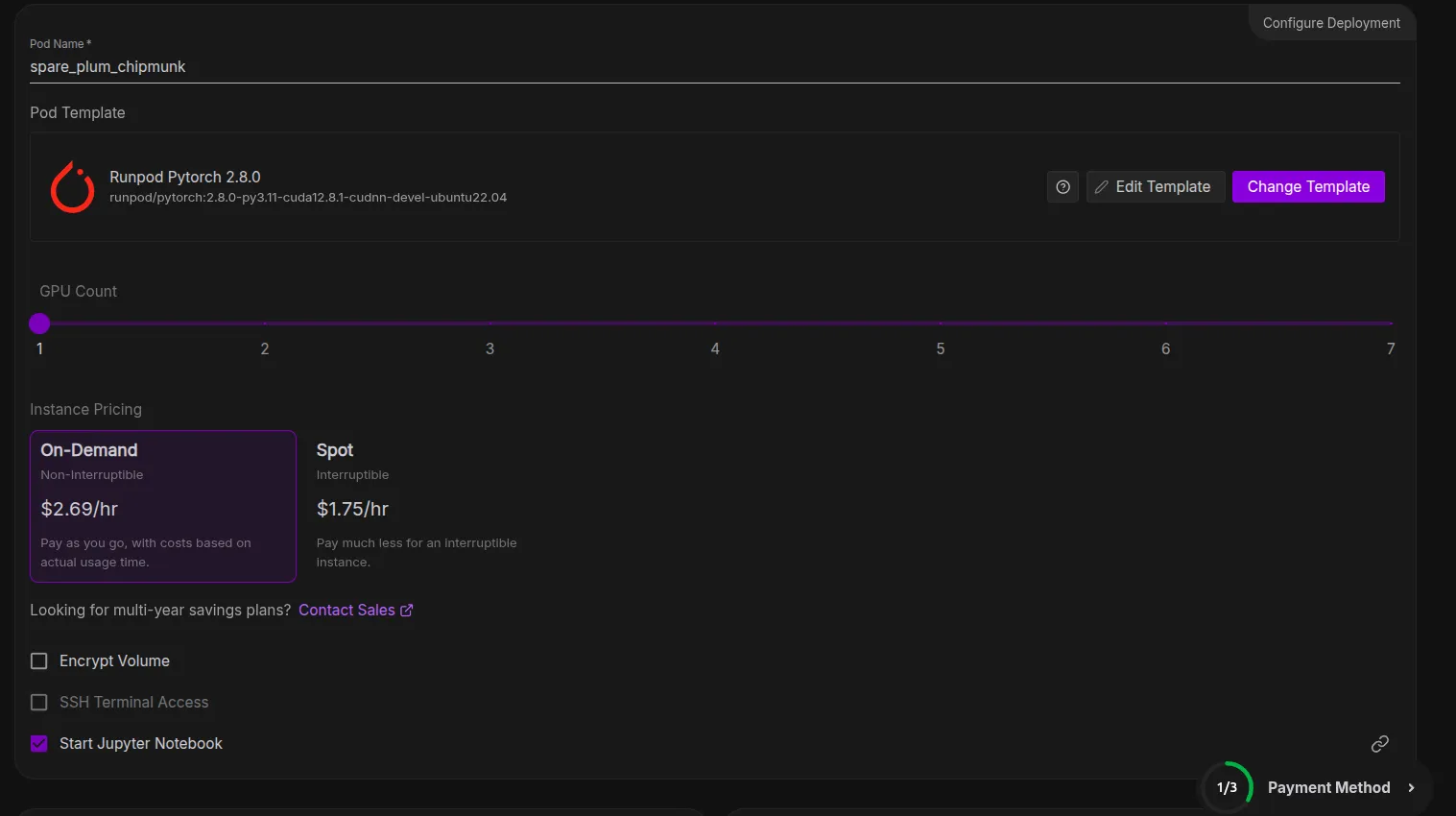
To be secure for our pod setting, we will even improve the scale of the Container Disc and Quantity Disc to 200 GB within the template.
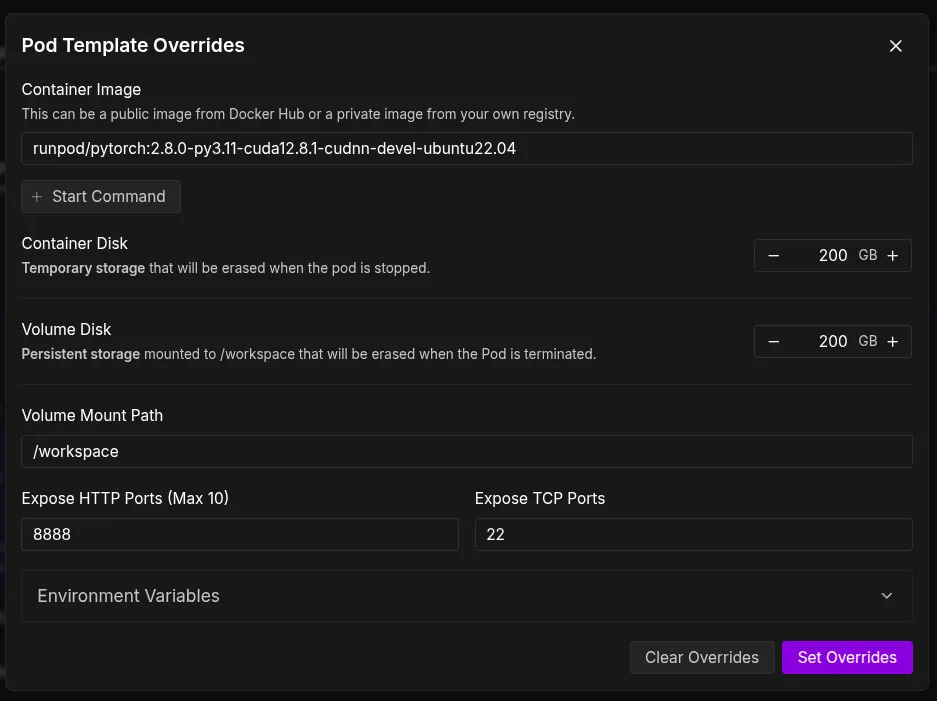
We will now deploy our pod after overriding these settings, which may take as much as two minutes to arrange. Subsequent, we are able to choose the Jupyter Pocket book choice, which is able to take us to a brand new tab with a Jupyter pocket book setting that’s similar to those we work on domestically.
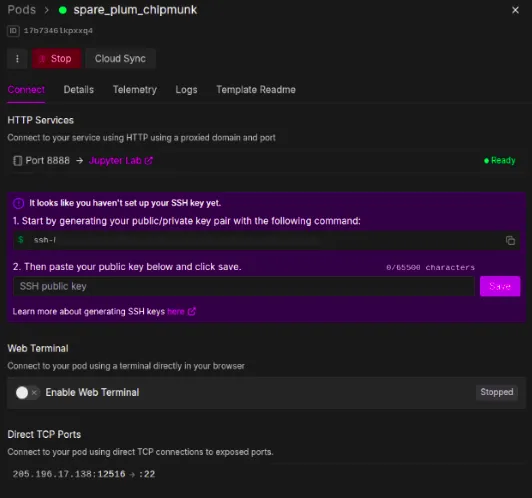
Arrange for Advantageous-Tuning
The Jupyter Pocket book setting could be very simple to make use of, the place we are able to open ipynb, py, and different varieties of recordsdata together with the terminal.
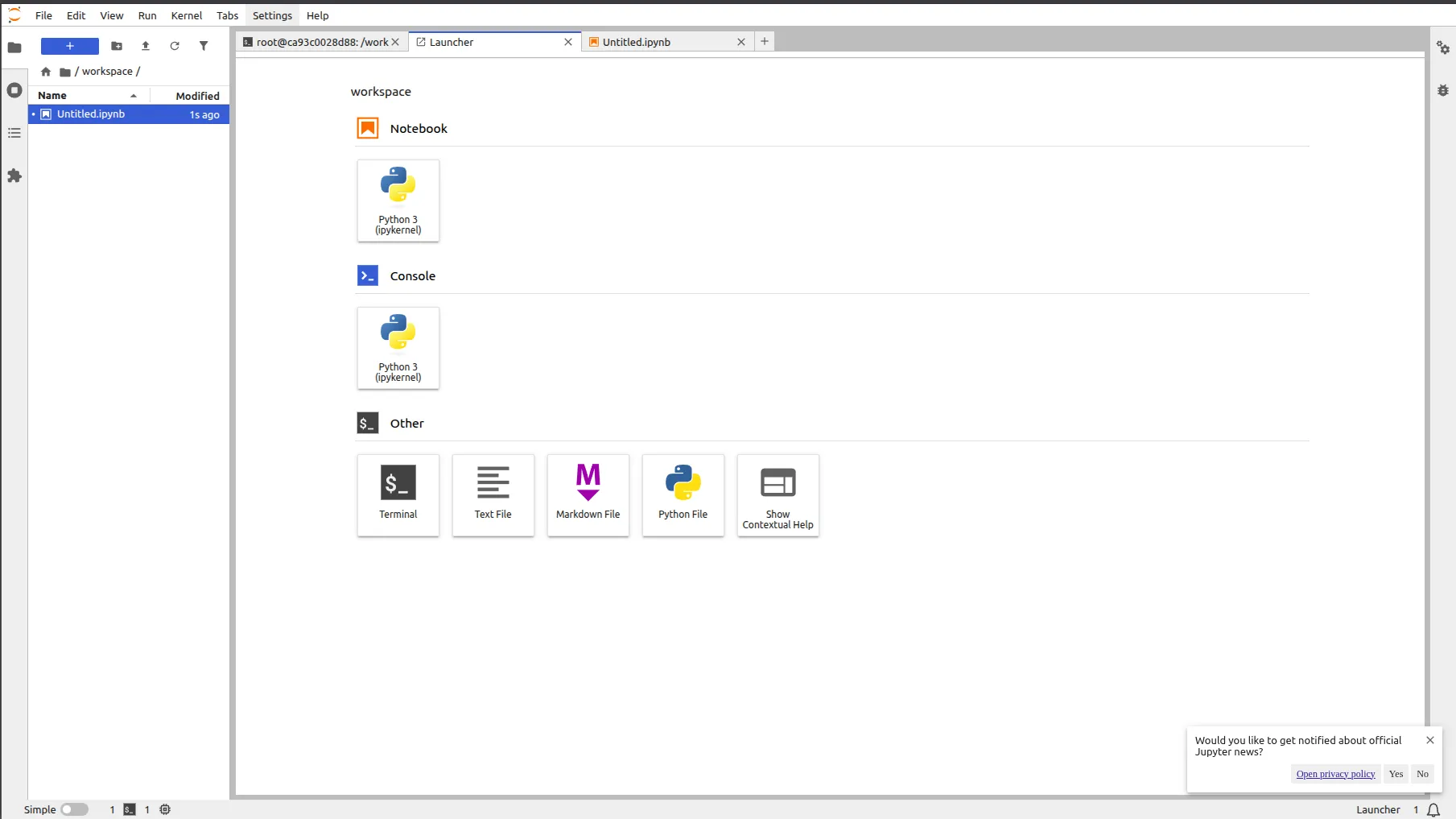
Step 1: Setup
Earlier than diving into fine-tuning, let’s arrange a clear setting to keep away from dependency points. We’ll use uv, a contemporary Python package deal supervisor that makes it simple to deal with digital environments and installations.
Create a Digital Setting
Open your terminal and run the next instructions:
# Set up uv if not already put in
pip set up uv
# Create a digital setting
uv venv
# Activate the setting
supply .venv/bin/activateMoreover, if wanted, you’ll be able to run these instructions too
apt-get replace && apt-get improve -y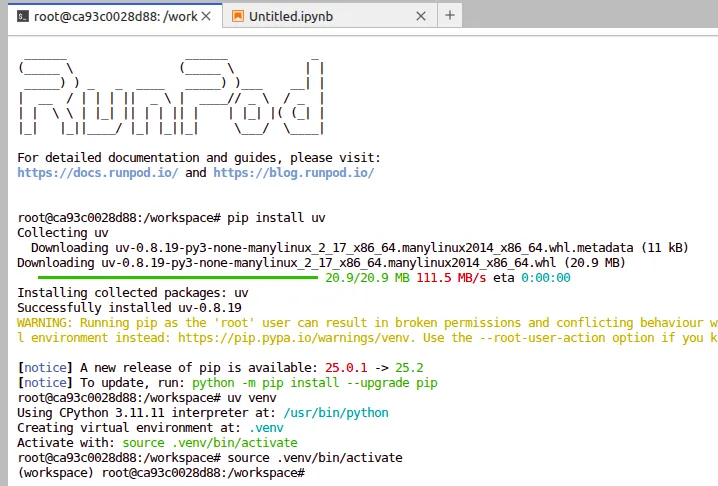
Set up the Dependencies
With the digital setting activated, the subsequent step is to put in all of the required libraries. These will give us the instruments to load the mannequin, apply parameter-efficient fine-tuning, and prepare successfully on GPUs.
Run the next instructions inside your terminal:
# Set up PyTorch with CUDA 12.8 assist
%pip set up torch --index-url https://obtain.pytorch.org/whl/cu128
# Set up Hugging Face libraries and different instruments
%pip set up "trl>=0.20.0" "peft>=0.17.0" "transformers>=4.55.0" trackioRight here’s what every of those does:
- torch -> The deep studying framework powering our coaching.
- trl -> Hugging Face’s library for coaching with reinforcement studying (nice for alignment duties).
- peft -> Parameter-Environment friendly Advantageous-Tuning, enabling methods like LoRA.
- transformers -> Core library for working with LLMs.
- trackio -> Light-weight experiment monitoring to watch coaching progress.
As soon as these are put in, we’re prepared to maneuver on to dataset preparation.
We will even be logging into our Hugging Face utilizing the entry tokens, which we are able to get from our Profile Settings.
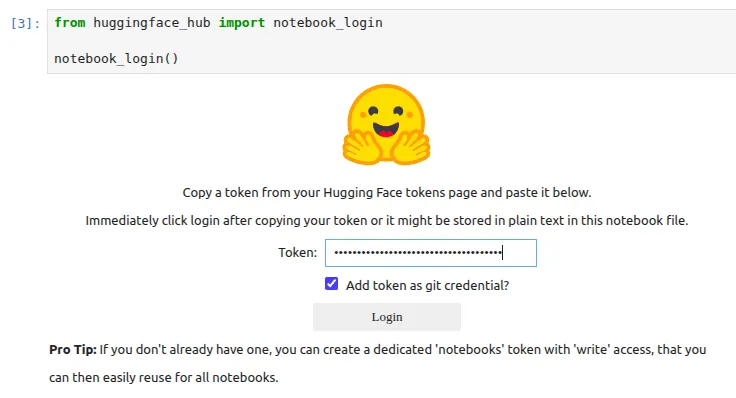
For those who get any points with respect to git, then you’ll be able to run this command
!git config –world credential.helper retailerStep 2: Put together the Dataset
Earlier, we mentioned how the gpt-oss fashions, regardless of their effectivity, usually are not notably robust in deep reasoning and multi-step logic. To deal with this, we’ll fine-tune gpt-oss-20B on a specialised dataset that strengthens its reasoning capacity.
For this, we’ll use the Multilingual Considering Dataset out there on Hugging Face. This dataset is designed to check and prepare reasoning abilities throughout a number of languages, making it a really perfect alternative for bettering each logical accuracy and cross-lingual generalization.
Downloading the Dataset
We shall be utilizing Multilingual-Considering, which is a reasoning dataset the place the chain-of-thought has been translated into a number of languages, similar to French, Spanish, and German. By fine-tuning openai/gpt-oss-20b on this dataset, it’ll be taught to generate reasoning steps in these languages, and thus its reasoning course of might be interpreted by customers who communicate these languages.
We shall be utilizing solely the messages column of this dataset for our coaching.
Observe:- You can also make a dataset by yourself, which ought to be much like this format and enclosed inside a dictionary that has key-value pairs, which might permit the mannequin to grasp what the query is and the suitable reply to this query.
We will fetch the dataset instantly utilizing the Hugging Face datasets library:
https://huggingface.co/datasets/HuggingFaceH4/Multilingual-Considering
from datasets import load_dataset
dataset = load_dataset("HuggingFaceH4/Multilingual-Considering", cut up="prepare")
datasetThis can be a small dataset of 1,000 examples, however that is normally greater than ample for fashions like openai/gpt-oss-20b, which have undergone intensive post-training.
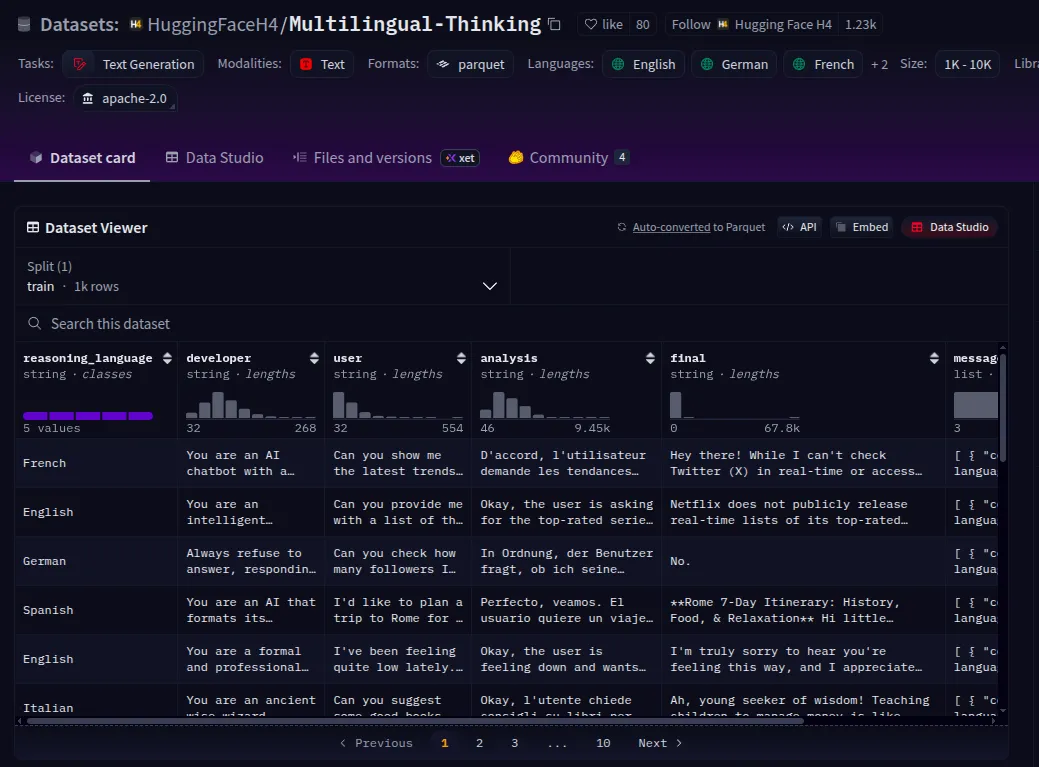
Step 3: Tokenize and Format the Dataset
Earlier than coaching, we have to course of the dataset right into a format the mannequin understands. Since gpt-oss-20B is a chat-style mannequin, we’ll use its chat template to transform the dataset into conversational textual content that may be tokenized.
Load the Tokenizer
We begin by loading the tokenizer of the gpt-oss-20B mannequin:
from transformers import AutoTokenizer
# Load the tokenizer for GPT-OSS-20B
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")Apply Chat Template
Every instance within the multilingual reasoning dataset comprises structured messages. We will use the tokenizer’s chat template to transform these right into a plain-text dialog that the mannequin can prepare on:
# Take the primary instance from the dataset
messages = dataset[0]["messages"]
# Convert structured messages into plain-text dialog
dialog = tokenizer.apply_chat_template(messages, tokenize=False)
print(dialog)The gpt-oss fashions have been educated on the Concord response format for outlining dialog constructions, producing reasoning output, and structuring perform calls.
Step 4: Put together the Mannequin
Now that our dataset is prepared, let’s put together the gpt-oss-20B mannequin for fine-tuning. Since coaching a 20B parameter mannequin instantly could be very resource-intensive, we’ll make use of two key methods:
- Quantization – reduces reminiscence utilization and hastens inference by storing weights in decrease precision (right here we use MXFP4 quantization, which is utilized loads for OpenAI fashions).
- LoRA (Low-Rank Adaptation) – allows parameter-efficient fine-tuning by coaching solely small adapter layers whereas maintaining many of the mannequin frozen.
Learn extra: Finetuning LLMs with Llora
Load the Base Mannequin with Quantization
What’s MXFP4?
- MXFP4 (Combined 4-bit Floating Level) is a quantization format developed to cut back reminiscence utilization and enhance inference velocity in large-scale autoregressive fashions like gpt-oss-20B.
- Not like easy integer quantization (like INT8/INT4), MXFP4 makes use of a discovered combined floating-point illustration, which preserves extra of the unique mannequin’s numerical precision.
Why GPT fashions particularly?
- GPT-style fashions (decoder-only transformers) are extraordinarily weight-heavy, particularly in consideration and feed-forward layers.
- MXFP4 is optimized for these architectures by specializing in linear layers + consideration projections, which dominate the reminiscence footprint.
Benefits
- Reminiscence Environment friendly: Reduces VRAM necessities massively (20B parameter fashions match on fewer GPUs).
- Velocity: Allows sooner inference by decreasing precision with out shedding a lot high quality.
- Accuracy Retention: Performs higher than naïve INT4 quantization, particularly on long-context reasoning duties, the place precision issues extra.
import torch
from transformers import AutoModelForCausalLM, Mxfp4Config
# Configure MXFP4 quantization
quantization_config = Mxfp4Config(dequantize=True)
# Mannequin kwargs for environment friendly coaching
model_kwargs = dict(
attn_implementation="keen",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
# Load GPT-OSS-20B with quantization
mannequin = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs)Fast Check: Producing a Response
Earlier than fine-tuning, let’s make sure that the mannequin is working:
messages = [
{"role": "user", "content": "¿Cuál es la capital de Australia?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(mannequin.system)
output_ids = mannequin.generate(input_ids, max_new_tokens=512)
response = tokenizer.batch_decode(output_ids)[0]
print(response)At this stage, the mannequin ought to return a response in Spanish (ans: Canberra).
Add LoRA Adapters
Now we combine LoRA adapters to allow parameter-efficient fine-tuning.
from peft import LoraConfig, get_peft_model
# LoRA configuration
peft_config = LoraConfig(
r=8, # rank
lora_alpha=16,
target_modules="all-linear",
target_parameters=[ # Specific layers we want to adapt - you can edit with any other layers too
"7.mlp.experts.gate_up_proj",
"7.mlp.experts.down_proj",
"15.mlp.experts.gate_up_proj",
"15.mlp.experts.down_proj",
"23.mlp.experts.gate_up_proj",
"23.mlp.experts.down_proj",
],
)
# Apply LoRA to the mannequin
peft_model = get_peft_model(mannequin, peft_config)
# Print trainable parameters
peft_model.print_trainable_parameters()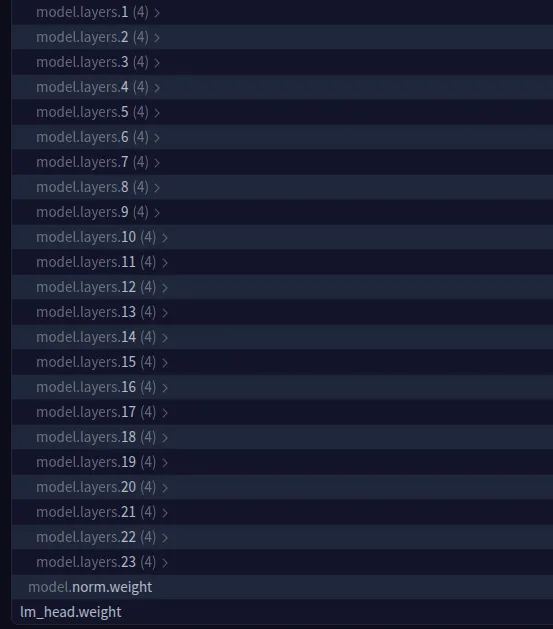
We will choose different mannequin layers additionally. You possibly can take a look at the mannequin parameters data by way of this hyperlink – https://huggingface.co/openai/gpt-oss-20b/blob/fundamental/mannequin.safetensors.index.json
This setup ensures that solely a small fraction of the mannequin’s parameters shall be up to date throughout coaching, maintaining GPU reminiscence necessities manageable whereas nonetheless permitting the mannequin to be taught reasoning abilities.
Step 5: Advantageous-Tuning
With the mannequin ready and LoRA adapters utilized, we’re able to fine-tune gpt-oss-20B on the Multilingual Reasoning Dataset. For this, we’ll use Hugging Face’s TRL (Transformers Reinforcement Studying) library, which supplies a easy SFTTrainer class for supervised fine-tuning.
Outline Coaching Configuration
We’ll configure the coaching with a studying fee, batch measurement, logging frequency, and scheduler.
from trl import SFTConfig
# Coaching arguments
training_args = SFTConfig(
learning_rate=2e-4,
gradient_checkpointing=True,
num_train_epochs=1,
logging_steps=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_length=2048, # if you would like make it extra mild weight you'll be able to scale back this quantity
warmup_ratio=0.03,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr_rate": 0.1},
output_dir="gpt-oss-20b-multilingual-reasoner",
report_to="trackio", # Logs coaching metrics
push_to_hub=True, # Push outcomes to Hugging Face Hub
)
If you want to trace the logs of the mannequin coaching, you can too go for WandB.
Initialize Coach
from trl import SFTTrainer
# Create coach
coach = SFTTrainer(
mannequin=peft_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
# Begin fine-tuning
coach.prepare()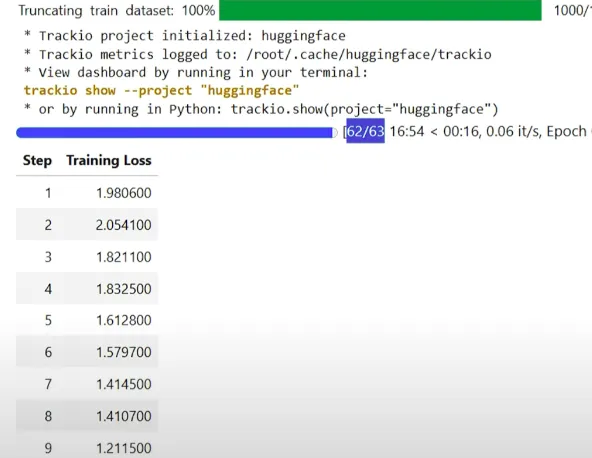
Monitor Logs
You possibly can monitor your coaching progress with Trackio:
!trackio present --project "gpt-oss-20b-multilingual-reasoner"or in Python:
import trackio
trackio.present(mission="gpt-oss-20b-multilingual-reasoner")Coaching Time
On a single H100 GPU, coaching takes about 17 to 18 minutes. On much less highly effective {hardware}, the time could also be longer relying on GPU reminiscence and compute velocity.
Save and Push Mannequin
As soon as coaching completes, save the fine-tuned mannequin domestically and push it to the Hugging Face Hub:
# Save mannequin domestically
coach.save_model(training_args.output_dir)
# Push to Hugging Face Hub
coach.push_to_hub(dataset_name="skhamzah123/GPT-OSS-20B_FT")Now your mannequin is reside and shareable, prepared for reasoning duties in a number of languages.
Step 6: Inference
After fine-tuning, we are able to now generate reasoning responses in a number of languages utilizing our gpt-oss-20B multilingual mannequin. We first load the bottom gpt-oss-20B mannequin, merge it with our fine-tuned LoRA adapters, after which generate responses utilizing a structured chat template.
I’d counsel you restart your kernel earlier than operating these cells, since an excessive amount of reminiscence is already saved in your RAM, and it’d trigger your kernel to crash.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
# Load the bottom mannequin
model_kwargs = dict(attn_implementation="keen", torch_dtype="auto", use_cache=True, device_map="auto")
base_model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs).cuda()
# Merge fine-tuned weights with base mannequin
peft_model_id = "skhamzah123/gpt-oss-20b-multilingual-reasoner"
mannequin = PeftModel.from_pretrained(base_model, peft_model_id)
mannequin = mannequin.merge_and_unload()
# Outline language and immediate
REASONING_LANGUAGE = "Hindi" # edit this to every other language
SYSTEM_PROMPT = f"reasoning language: {REASONING_LANGUAGE}"
USER_PROMPT = "¿Cuál es el capital de Australia?"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(mannequin.system)
gen_kwargs = {"max_new_tokens": 512, "do_sample": True, "temperature": 0.6}
output_ids = mannequin.generate(input_ids, **gen_kwargs)
response = tokenizer.batch_decode(output_ids)[0]
print(response)We use Keen Consideration/Flash Consideration to make inference light-weight and quick, decreasing reminiscence utilization whereas nonetheless dealing with lengthy sequences effectively. The merge_and_unload() step combines the LoRA adapters with the bottom mannequin in order that inference runs with out additional adapter overhead. By specifying the reasoning language within the system immediate, the mannequin can generate step-by-step reasoning in a number of languages, demonstrating the effectiveness of multilingual fine-tuning.
Conclusion
Advantageous-tuning gpt-oss-20B demonstrates how open-source massive language fashions might be tailored to carry out advanced reasoning throughout a number of languages whereas remaining reminiscence and compute environment friendly. By leveraging methods like LoRA for parameter-efficient fine-tuning and MXFP4 quantization, we have been in a position to improve reasoning capabilities with out requiring huge GPU assets.
Utilizing the Multilingual Considering Dataset allowed the mannequin to be taught step-by-step logic in several languages, making it extra versatile and aligned for real-world purposes. With cautious dataset preparation, mannequin configuration, and inference optimization (Keen/Flash Consideration), OSS fashions might be secure, correct, and performant, bridging the hole between open-source flexibility and sensible utility.
This workflow not solely highlights the energy of open-source LLMs but in addition supplies a sensible blueprint for anybody trying to fine-tune massive fashions for reasoning, alignment, and multilingual capabilities.
Loads of the assets on this article have been taken from the OpenAI cookbook. Please seek advice from it for extra particulars.
Continuously Requested Questions
A. With LoRA or QLoRA, you’ll be able to fine-tune it on a single 80GB GPU (like an H100). Full fine-tuning, nonetheless, requires 300GB+ of GPU reminiscence and multi-GPU setups.
A. MXFP4 preserves higher numerical precision, particularly for long-context reasoning, whereas nonetheless decreasing reminiscence and rushing up inference in comparison with commonplace INT4 quantization.
A. Sure. Simply format your dataset in an instruction-response type (as dictionaries with “query” and “reply” pairs) so the mannequin can be taught structured reasoning from it.
Knowledge Scientist @ Analytics Vidhya | CSE AI and ML @ VIT Chennai
Obsessed with AI and machine studying, I am wanting to dive into roles as an AI/ML Engineer or Knowledge Scientist the place I could make an actual influence. With a knack for fast studying and a love for teamwork, I am excited to carry revolutionary options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout numerous fields and take the initiative to delve into knowledge engineering, making certain I keep forward and ship impactful initiatives.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}