

Your most diligent accounts payable specialist is probably going spending the whole morning engaging in nothing of worth. They’re manually sorting a chaotic inbox, dragging lots of of attachments into folders to separate invoices from buy orders and vendor contracts. This is not only a minor inefficiency; it is a systemic failure to handle the unstructured knowledge that now dominates enterprise operations.
Here is a glimpse into why:
- 45% of employed People suppose their firm’s course of for organizing paperwork is caught in the dead of night ages.
- Professionals waste as much as 50% of their time trying to find info.
- Most SMBs spend 10% of their income on doc administration, however can’t say for certain the place that cash goes.
- Misclassified contracts may cause worth leakage, with unfulfilled provider obligations costing a big enterprise roughly 2% of its whole spend, a staggering $40 million per 12 months on a $2 billion spend base.
Conventional approaches have failed:
- Rule-based programs break when doc layouts change
- Template matching requires fixed upkeep
- Handbook sorting creates bottlenecks and errors
- Primary OCR options cannot deal with variations in format
- Siloed departmental programs create info obstacles
This information explains how trendy AI-powered doc classification addresses these challenges. We’ll look at confirmed approaches that main organizations use to:
- Mechanically establish and route paperwork to acceptable workflows
- Cut back processing time from minutes to seconds
- Keep accuracy above 90% throughout a number of doc sorts
- Scale operations with out proportional will increase in headcount
What’s doc classification?
Doc classification is the method of mechanically assigning a doc to a predefined class based mostly on its content material, structure, and metadata. Its function is to allow retrieval, routing, compliance monitoring, and downstream automation, forming the crucial first step within the doc processing workflow.
The core problem is that enterprise paperwork exist on a spectrum of complexity:
- Structured: These have a hard and fast structure the place knowledge fields are in predictable places. Consider authorities varieties like a U.S. W-2, a UK P60, or standardized passport purposes.
- Semi-structured: This is almost all of enterprise paperwork. The important thing knowledge is constant (e.g., an bill all the time has an bill quantity), however its location and format differ. Examples embrace invoices from totally different distributors, buy orders, and payments of lading.
- Unstructured: This class covers free-form textual content, the place that means is derived from the language and context, relatively than the structure. Examples embrace authorized contracts, emails, and enterprise stories.
A contemporary system performs classification throughout a number of dimensions to make an correct judgment:
- Textual content evaluation: Analyzing the textual content utilizing Pure Language Processing (NLP) to know what the doc is about. It identifies key fields and knowledge factors and acknowledges industry-specific terminology.
- Format evaluation: Mapping spatial relationships between parts. It identifies tables, headers, and sections and acknowledges logos and formatting patterns.
- Metadata evaluation: Utilizing attributes like creation date, supply system, language, or privateness markers. It seems at file supply and routing info, in addition to safety and entry necessities.
This multidimensional method permits a system to make distinctions essential for enterprise operations, akin to distinguishing between an bill and a purchase order order in finance, a lab report and a discharge abstract in healthcare, or an NDA and an employment contract in authorized. Early strategies relied on inflexible guidelines and templates, however the necessity to deal with semi-structured and unstructured knowledge at scale led to the introduction of extra AI-powered strategies that we use right this moment.
How trendy classification works: The entire expertise stack
A contemporary classification system would not depend on a single algorithm; it’s powered by an built-in engine that ingests, digitizes, and understands paperwork earlier than a last choice is ever made. This engine has a number of crucial layers, from foundational elements that course of uncooked information to superior algorithms that present deep contextual understanding.
Layer 1: Information ingestion
Earlier than any classification can occur, a doc have to be transformed right into a format the system can analyze.
Optical Character Recognition (OCR): For the thousands and thousands of scanned PDFs, smartphone footage, and handwritten notes that companies run on, OCR is the important first step. It converts an image of a doc into machine-readable textual content. It is a foundational expertise that’s already in use in most organizations right this moment.
Whereas older OCR struggled with messy paperwork, trendy, AI-enhanced variations excel. For instance, the open-source DocStrange mannequin can natively establish and digitize advanced buildings, akin to tables, signatures, and handwritten notes, offering wealthy, structured textual content for the subsequent layer of study.
Metadata Evaluation: Usually neglected, a doc’s metadata supplies highly effective clues that exist outdoors the content material itself. Attributes just like the supply system, writer, creation date, and nation of origin are ingested alongside the doc’s content material. That is crucial for compliance. A doc from a German consumer might be mechanically flagged for GDPR dealing with based mostly solely on its metadata.
Layer 2: Semantic understanding
As soon as the textual content is digitized, Pure Language Processing (NLP) supplies the understanding. It permits the system to research language for semantic that means, discerning the intent and context which might be essential for correct classification.
That is what strikes a system from merely matching key phrases to really comprehending a doc’s function. For instance, a purchase order order and a gross sales contract would possibly each comprise related phrases, however an NLP mannequin can analyze the verbs and entities to distinguish them accurately. This functionality is crucial for dealing with unstructured paperwork, akin to contracts. A latest McKinsey proof-of-concept demonstrated this energy: a Gen AI software analyzed 190 advanced contracts in 4 totally different languages in simply three weeks, figuring out thousands and thousands in potential financial savings. This job would have taken a human group months.
Layer 3: Built-in AI
The true breakthrough in trendy classification is combining these layers right into a single, holistic evaluation.
Multimodal AI: That is the present normal. It fuses OCR with NLP. As a substitute of a sequential course of, multimodal fashions analyze a doc’s visible structure and its textual content material concurrently. The mannequin acknowledges the visible construction of an bill—the brand placement, the desk format—and combines that with its textual understanding to make a assured choice. This method is so efficient that analysis has proven it permits even easy image-based classifiers to attain 91.14% accuracy on advanced doc benchmarks.
Graph Convolutional Networks (GCNs): For the best degree of understanding, state-of-the-art fashions use GCNs to create a “relationship map” of the whole doc set. This supplies the mannequin with a world context, enabling it to know that an “bill” from one vendor is expounded to a “buy order” from one other. For very lengthy paperwork, Graph-Tree Fusion fashions mix this international context with sentence-level evaluation to beat the enter size limits that constrain older fashions.
Layer 4: The effectivity structure
This highly effective engine have to be deployed effectively to be sensible at an enterprise scale. The brute-force method of making use of one large AI mannequin to each doc is sluggish and costly. Trendy programs are constructed in a different way.
The clever workflow begins with a light-weight, speedy mannequin that classifies paperwork based mostly on easy options, such because the filename. Analysis exhibits that this preliminary step might be as much as 400 instances sooner than a whole deep-learning evaluation, accurately dealing with as much as 90% of clearly named paperwork with an accuracy of over 96%. Solely ambiguous information (e.g., scan_082925.pdf) are routed for deeper, multimodal evaluation.
For lengthy paperwork that require deeper evaluation, the system would not course of each single phrase. As a substitute, it makes use of relevance rating to create a “semantic abstract” containing solely essentially the most informative sentences. This system has been confirmed to cut back inference time by as much as 35% with no loss in classification accuracy, analyzing lengthy contracts and stories lastly sensible at scale.
Every of those evolutions solved limitations of the prior stage, however success now is dependent upon the standard of knowledge seize (OCR) and the depth of semantic understanding (NLP).
Coaching doc classification fashions: Actual-world challenges and options
Coaching an efficient doc classification mannequin is the place the guarantees of AI meet the messy actuality of enterprise operations. Whereas distributors typically showcase “out-of-the-box” options, a profitable real-world implementation requires a practical method to knowledge high quality, quantity, and ongoing upkeep. The core problem is {that a} staggering 77% of organizations report that their knowledge high quality is common, poor, or very poor, making it unsuitable for AI with no clear technique.
Let’s break down the real-world challenges of coaching a mannequin and the trendy options that make it sensible.
a. The chilly begin problem: The way to start with little to no knowledge
Essentially the most vital hurdle for any group is the “chilly begin” downside: how do you practice a mannequin when you do not have an enormous, pre-labeled dataset? Conventional approaches that demanded 1000’s of manually labeled paperwork have been impractical for many companies. Trendy platforms clear up this with three distinct, sensible approaches.
1. Zero-shot studying
What it’s: The flexibility to start out classifying paperwork utilizing solely a class identify and a transparent, plain-English description of what to search for.
The way it works: As a substitute of studying from labeled examples, these fashions leverage strategies like Confidence-Pushed Contrastive Studying to know the semantic that means of the class itself. The mannequin matches the content material of an incoming doc to your description with none preliminary coaching paperwork.
Greatest for: That is preferrred for distinct doc classes the place a transparent description can successfully separate one from one other. This precept is the expertise behind our Zero-Shot mannequin. You outline a brand new doc kind not by importing a big dataset, however by offering a transparent description. The AI makes use of its present intelligence to start out classifying instantly.
2. Few-shot studying
What it’s: The flexibility to coach a mannequin with a really small variety of samples, usually between 10 and 50 per class.
The way it works: The mannequin is architected to generalize successfully from restricted examples, making it preferrred for rapidly adapting to new or specialised doc sorts while not having a large-scale knowledge assortment undertaking.
Greatest for: That is preferrred for extremely specialised or uncommon doc sorts the place amassing a big dataset just isn’t possible.
3. Pre-trained fashions
What it’s: Utilizing a mannequin that has already been pre-trained on thousands and thousands of paperwork for a typical use case (like invoices or receipts) after which fine-tuning it to your particular wants.
The way it works: This method considerably reduces preliminary coaching necessities and permits organizations to attain excessive accuracy from the beginning by constructing on a robust, pre-existing basis.
Greatest for: Widespread enterprise paperwork like invoices, receipts, and buy orders, the place a pre-trained mannequin supplies a direct head begin.
b. The information high quality downside: Good knowledge in, good outcomes out
The standard of your coaching knowledge has a direct affect on classification accuracy. This can be a main level of failure; the AIIM report discovered that solely 23% of organizations have established processes for knowledge high quality monitoring and preparation for AI, which is a significant reason for implementation failure.
Key high quality necessities embrace:
- Decision: A minimal of 1000×1000 pixel decision for photos and 300 DPI for scanned paperwork is beneficial to make sure textual content is obvious.
- Readability: Textual content have to be readable and free from extreme blur or distortion.
- Annotation consistency: It’s crucial to comply with the identical conference when annotating knowledge. For instance, when you annotate the date and time in a receipt below the label date, it’s essential to comply with the identical follow in all receipts.
- Completeness: Don’t partially annotate paperwork. If a picture has 10 fields to be labeled, guarantee all 10 are annotated.
c. The stagnation downside: Making certain steady enchancment
Classification fashions usually are not static; they’re designed to enhance over time by studying from their surroundings.
1. Instantaneous Studying:
What it’s: The mannequin is architected to study from each single human correction in real-time. When a consumer within the loop approves a corrected doc or reclassifies a file, that suggestions is straight away included into the mannequin’s logic.
Profit: This eliminates the necessity for guide, periodic retraining tasks and ensures the mannequin mechanically adapts to new doc variations as they seem.
2. Efficiency Monitoring:
AI Confidence Rating: Trendy platforms present a dynamic “AI Confidence” rating for every prediction. This metric quantifies the mannequin’s capacity to course of a file with out human intervention and is essential for setting automation thresholds. It’s a dynamic measure of how succesful the AI mannequin is of processing your information with out human intervention.
Enterprise and technical KPIs: Repeatedly observe technical metrics like accuracy and straight-through-processing (STP) charges, alongside enterprise metrics like processing time and error charges, to establish areas for enchancment and flag systematic errors.
With a transparent path to coaching an correct and constantly enhancing mannequin, the dialog shifts from technical feasibility to tangible enterprise outcomes.
We will now transfer from the mechanics of coaching to essentially the most crucial query for any enterprise chief: What’s the measurable affect these programs have on a company’s backside line?
The proof: Quantified ROI and real-world outcomes
The advantages of transferring from guide sorting to clever classification usually are not theoretical. They’re measured in saved hours, direct value reductions, and mitigated operational dangers. Whereas the enterprise case is exclusive for each firm, a transparent benchmark for fulfillment has been established within the {industry}.
Enterprise purposes throughout industries
| Trade | Widespread Paperwork | Automated Workflow | Enterprise Worth |
| Finance & Accounting | Invoices, Buy Orders, Receipts, Tax Kinds, Financial institution Statements | Classify incoming paperwork to set off 3-way matching, route high-value invoices for particular approval, and export validated knowledge to an ERP like SAP or NetSuite. | Quicker AP/AR cycles, diminished reconciliation errors, and proactive prevention of duplicate funds and fraud. |
| Healthcare | Affected person Data, Lab Reviews, Insurance coverage Claims (e.g., HCFA-1500 varieties), Vendor Compliance Recordsdata | Type affected person information for EHR programs, classify vendor paperwork for compliance checks, and mechanically route claims to the right adjudication group. | Quicker document retrieval, improved interoperability, strong HIPAA compliance, and a major discount in vendor onboarding time. |
| Authorized & Compliance | Contracts, NDAs, Litigation Filings, Discovery Paperwork, Compliance Reviews | Triage new contracts by kind (e.g., NDA vs. MSA), flag particular clauses for knowledgeable assessment, and mechanically monitor for compliance deviations in opposition to transactional knowledge. | Quicker due diligence, a major discount in guide authorized assessment hours, and proactive danger mitigation earlier than contracts are executed. |
| Logistics & Provide Chain | Payments of Lading, Buy Orders, Supply Notes, Customs Kinds, Transport Receipts | Mechanically break up multi-document transport packets, classify every doc, and route them to customs, warehouse, and finance programs concurrently. | Quicker customs clearance, fewer transport delays, improved provide chain visibility, and extra correct stock administration. |
| Human Assets | Resumes, Worker Contracts, Onboarding Kinds (e.g., I-9s, P45s), Efficiency Critiques, Expense Reviews | Classify applicant resumes to route them to the right hiring supervisor, and mechanically set up all onboarding paperwork into digital worker information. | Quicker hiring cycles, streamlined worker onboarding, simpler compliance with labor legal guidelines, and extra environment friendly inner audits. |
The benchmark: What separates one of the best from the remainder
Based on a complete 2024 examine by Ardent Companions, the efficiency hole between a mean Accounts Payable division and a “Greatest-in-Class” one is outlined nearly totally by the extent of automation. The examine discovered that Greatest-in-Class AP groups obtain bill processing instances which might be 82% sooner and at a 78% decrease value than all different teams.
Reaching this degree of efficiency just isn’t a thriller; it’s the direct results of making use of the applied sciences mentioned on this information. Let’s look at how particular companies have achieved this.
| Metric | Handbook Processing | Automated Processing |
| Time per doc | 5-10 minutes | |
| Price per doc | ~$9.40 (Trade Avg.) | ~$2.78 (Greatest-in-Class) |
| Error fee | 5-10% (guide entry) |
Instance 1: Taming complexity in manufacturing
Asian Paints, a world producer, confronted a posh problem: processing paperwork from 22,000 distributors each day. Every transaction required a number of doc sorts, buy orders, supply notes, and import summaries, all flowing right into a single inbox.
Their implementation method:
- Automated classification to establish doc sorts
- Direct routing of invoices to SAP
- Separate workflow for supply notes and POs
- Automated matching of associated paperwork
Outcomes:
- Processing time: 5 minutes → 30 seconds per doc
- Time saved: 192 person-hours month-to-month
- Scope: Efficiently dealing with 22,000+ vendor paperwork day by day
- Error discount: Automated duplicate detection caught $47,000 in vendor overcharges
Instance 2: Making certain compliance and scale in healthcare
SafeRide Well being wanted to confirm and classify 16 totally different doc sorts for every transportation vendor, from automobile registrations to driver certifications. Handbook processing created bottlenecks in vendor onboarding.
Implementation technique:
- Classification mannequin educated for every doc kind
- Computerized routing to validation workflows
- Integration with Salesforce for vendor administration
- Actual-time standing monitoring
Outcomes:
- Handbook workload diminished by 80%
- Crew effectivity elevated by 500%
- Automated validation of compliance paperwork
- Quicker vendor onboarding course of
Instance 3: Scaling AP operations
Augeo, an accounting agency processing 3,000 vendor invoices month-to-month, wanted to streamline their doc dealing with inside Salesforce. Their group spent 4 hours day by day on guide knowledge entry.
Resolution structure:
- Automated doc classification
- Direct integration with Accounting Seed
- Automated knowledge extraction and add
- Exception dealing with workflow
Outcomes:
- Processing time: 4 hours → half-hour day by day
- Capability: Efficiently dealing with 3,000+ month-to-month invoices
- Improved service supply to present purchasers
- Added capability for brand spanking new purchasers with out headcount improve
Implementation plan: Your path from guide sorting to automated workflows
This isn’t a six-month IT overhaul. For a targeted scope, you’ll be able to go from a chaotic inbox to your first automated classification workflow in only a week or two. This blueprint is designed to ship a tangible win rapidly, constructing momentum for broader adoption.
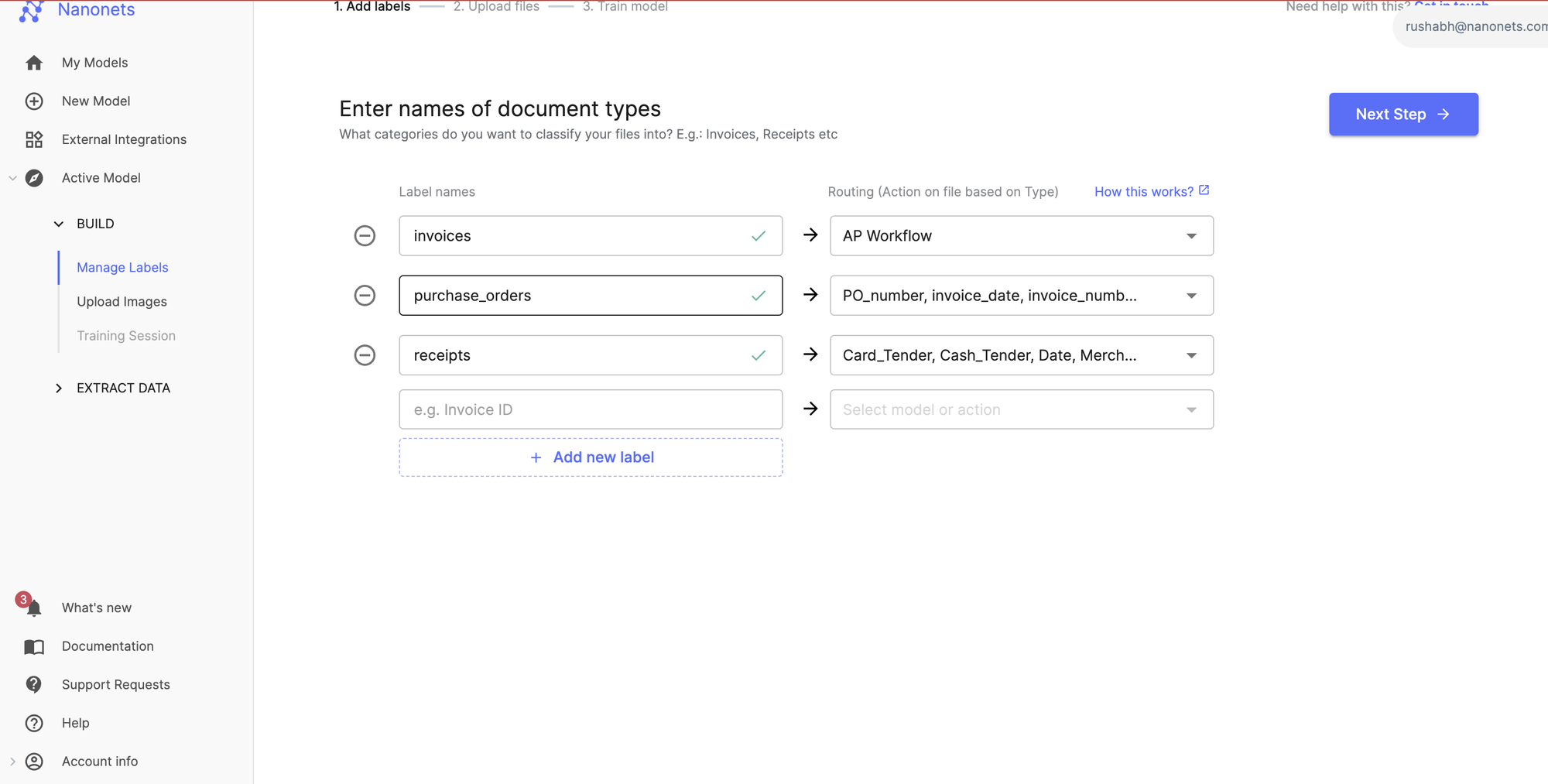
Step 1: Outline & ingest
The aim is to ascertain the scope of your preliminary undertaking and arrange the information pipeline.
- Establish the goal: Select 2-3 of your highest-volume, most problematic doc sorts. A standard place to begin for finance groups is separating Invoices, Buy Orders, and Credit score Notes.
- Collect samples: Gather at the least 10-15 numerous examples of every doc kind. This can be a crucial step; utilizing solely clear, easy examples is a typical mistake that results in poor real-world efficiency.
- Arrange your mannequin: Inside the Nanonets platform, create a brand new Doc Classification Mannequin. For every doc kind, create a corresponding label (e.g., Bill-EU, Buy-Order).
- Join your supply: Within the Workflow tab, arrange an automatic import channel. Join your [email protected] inbox or a delegated cloud folder (OneDrive, Google Drive, and many others.). Nanonets checks for brand spanking new information each 5 minutes.
Step 2: Practice and take a look at
Subsequent, you could give attention to coaching the preliminary AI mannequin and establishing a efficiency baseline.
- Practice the mannequin: Add your pattern paperwork to their corresponding labels.
- Course of a validation set: Feed a separate batch of 20-30 combined paperwork (not utilized in coaching) via the system to get your first take a look at the mannequin’s efficiency and a baseline accuracy rating.
- Analyze Confidence Scores: For every doc, the mannequin will return a classification and a confidence rating (e.g., 97%). Reviewing these scores is essential for setting your preliminary threshold for straight-through processing.
Step 3: Configure guidelines & human-in-the-loop
With a baseline mannequin working, subsequent you could embed your particular enterprise guidelines into the workflow.
- Outline routing logic: Map out the place every categorized doc ought to go. Within the Nanonets Workflow builder, this can be a visible, drag-and-drop course of to attach your classification mannequin to different modules, akin to a specialised knowledge extraction mannequin for invoices or an approval queue.
- Arrange the Human-in-the-Loop (HITL) Workflow: No mannequin is ideal initially. Configure the system to route any paperwork that fall under your confidence threshold (e.g.,
Step 4: Connecting to your programs
The ultimate step is about connecting the automated workflow to your present enterprise programs.
- Join your outputs: Configure the export step of your workflow. This may very well be a direct API integration into your ERP (like SAP or NetSuite), accounting software program (like QuickBooks or Xero), or a shared database.
- Go stay: Activate the workflow. All incoming paperwork to your chosen course of will now be mechanically categorized, routed, and processed, with human oversight just for the exceptions.
💡
Metrics to trace: Straight-By means of Processing (STP) Price (%), Classification Accuracy (%), Common Processing Time per Doc (seconds), Discount in Handbook Labor (hours/week), Price Financial savings per Doc, and Discount in Error Price (%).
- Widespread errors to keep away from:
- Coaching with non-representative knowledge: Utilizing solely clear examples as a substitute of the messy, real-world paperwork your group truly handles.
- Setting automation thresholds too excessive: Demanding 99% confidence from day one will route every part for guide assessment. Begin at a decrease worth (e.g., 85%) and improve it because the mannequin learns.
- Ignoring the consumer expertise: Make sure the software program vendor you choose has an HITL interface that’s quick and intuitive; in any other case, your group will see it as one other bottleneck.
Future-proofing your operations: The strategic outlook
Adopting doc classification is greater than an effectivity improve; it’s a strategic crucial that prepares your group for the way forward for work, compliance, and automation.
The AI-augmented workforce: rise of the AI brokers
The PwC 2025 AI Enterprise Predictions report states that your data workforce might successfully double, not via hiring, however via the combination of AI brokers—digital staff that may autonomously carry out advanced, multi-step duties.
Doc classification is the foundational ability for these brokers. An AI agent should first establish the kind of a doc earlier than it will possibly take the subsequent step, whether or not that entails drafting a response, updating a CRM, or initiating a cost workflow. Organizations that grasp classification right this moment are constructing the important infrastructure for the AI-augmented workforce of tomorrow.
Wrapping up: Classification is the gateway to full automation
Doc classification is step one to end-to-end doc automation. As soon as a doc is precisely categorized, a series of automated actions might be triggered. An “bill” might be routed for extraction and cost; a “contract” might be despatched for authorized assessment and signature; a “buyer criticism” might be routed to the suitable help tier.
That is the core precept behind a contemporary workflow automation platform. Nanonets allows you to go manner past easy sorting; you get full, end-to-end automation your small business truly wants — from e-mail import to ERP export.
FAQs
Can the system deal with paperwork in a number of languages concurrently?
Doc classification programs help a number of languages and scripts with out requiring separate fashions. The expertise combines: Language-agnostic visible evaluation for structure and construction, Multilingual OCR capabilities for textual content extraction, and Cross-language semantic understanding.
This implies organizations can course of paperwork in numerous languages via the identical workflow, sustaining constant accuracy throughout languages. The system mechanically detects the doc language and applies acceptable processing guidelines.
How does the system keep knowledge privateness and safety throughout classification?
Doc classification platforms implement a number of safety layers:
Finish-to-end encryption for all paperwork in transit and at relaxation
Function-based entry management for doc viewing and processing
Audit trails monitoring all system interactions and doc dealing with
Configurable knowledge retention insurance policies
Compliance with main requirements (SOC 2, GDPR, HIPAA)
Organizations also can deploy non-public cloud or on-premises options for enhanced safety necessities.
How does the system adapt to new doc sorts or modifications in present codecs?
Trendy classification programs use adaptive studying to deal with modifications:
- Steady studying from consumer corrections and suggestions
- Computerized adaptation to minor format modifications
- Straightforward addition of latest doc sorts with out full retraining
- Efficiency monitoring to detect accuracy modifications
- Swish dealing with of doc variations and updates
What degree of technical experience is required to keep up the system after implementation
Day-to-day system upkeep requires minimal technical experience:
- Visible interface for workflow changes
- No-code configuration for most typical modifications
- Constructed-in monitoring and alerting
- Automated mannequin updates and enhancements
- Normal integrations managed via UI
Technical groups could also be wanted for:
- Customized integration improvement
- Superior workflow modifications
- Efficiency optimization
- Safety configuration updates
- Customized characteristic improvement

{kind=link}