
OpenAI has launched two open-source language fashions, GPT-Oss-120b and GPT-Oss-20b. These are OpenAI’s first overtly licensed LLMs since GPT-2. Aiming to create the most effective state-of-the-art reasoning and tool-use fashions out there. The fashions have been launched to appreciable fanfare within the AI neighborhood.
By open-sourcing GPT-Oss, OpenAI permits folks to freely use and adapt throughout the bounds of Apache 2.0. These two fashions definitely think about a democratic method for skilled personalization and customization of the expertise to native, contextual duties. On this article information, we’ll undergo how one can entry GPT-Oss-120b and GPT-Oss-20b, and when to make use of which mannequin.
What Makes GPT-Oss Particular?
OpenAI’s new open-weight fashions are probably the most sturdy public fashions since GPT-2. It makes use of the newest approaches from probably the most superior techniques and is constructed to essentially work and be straightforward to make use of and adapt.
- Open Apache 2.0 License: The GPT-Oss fashions are each totally open-weight fashions and are licensed beneath the permissive Apache 2.0 license. This implies there are not any copyleft restrictions and builders can use them for analysis or business merchandise with no licensing charges or source-code obligations.
- Configurable Reasoning Ranges: A singular characteristic is the benefit of configuring the mannequin’s reasoning effort: low, medium, or excessive. This can be a trade-off of pace vs. depth. A easy system message like “Use low reasoning” or “Use excessive reasoning” will make the mannequin assume much less or extra deeply earlier than it solutions.
- Full Chain-of-Thought Entry: Not like many closed fashions, GPT-Oss exhibits its inner reasoning. It has a default output of an evaluation, i.e, reasoning steps channel, adopted by a last reply channel. Customers and builders can examine or filter the portion to debug or belief the mannequin’s reasoning.
- Native Agentic Capabilities: These fashions are constructed on an agentic workflow. They’re constructed in the direction of instruction-following, and they’re constructed with native assist for utilizing instruments of their considering.
Mannequin Overview & Structure
Each GPT-Oss fashions are Transformer-based networks using a Combination-of-Specialists (MoE) design. In an MoE, solely a subset of the total parameters (“consultants”) is energetic for every enter token, lowering computation. When it comes to numbers:
- GPT-Oss-120b has 117 billion complete parameters (36 layers). It makes use of 128 knowledgeable sub-networks, with 4 consultants energetic per token. This leads to solely ~5.1 billion energetic parameters per token.
- GPT-Oss-20b has 21 billion complete parameters (24 layers) with 32 consultants (4 energetic), yielding ~3.6 billion energetic parameters per token.
The structure additionally contains a number of superior options: all consideration layers use Rotary Positional Embeddings (RoPE) to deal with very lengthy contexts (as much as 128,000 tokens). Consideration itself alternates between a full-global and a 128-token sliding window, just like GPT-3’s design.
These fashions use grouped multi-query consideration with a bunch measurement of 8 to avoid wasting reminiscence whereas sustaining quick inference. Activations are SwiGLU. Importantly, all knowledgeable weights are quantized to a 4-bit MXFP4 format, permitting the massive mannequin to slot in one 80GB GPU and the smaller mannequin in 16GB and not using a main accuracy loss.
The desk beneath summarizes the core specs:
| Mannequin | Layers | Whole Params | Lively Params/Token | Specialists (complete/energetic) | Context |
|---|---|---|---|---|---|
| GPT-Oss-120b | 36 | 117B | 5.1B | 128 / 4 | 128K |
| GPT-Oss-20b | 24 | 21B | 3.6B | 32 / 4 | 128K |
Technical Specs & Licensing
- {Hardware} Necessities: GPT-Oss-120b wants a high-end GPU (~80–100 GB VRAM) and runs on a single 80 GB A100/H100-class GPU or multi-GPU setups. GPT-Oss-20b is lighter, operating in ~16 GB VRAM even on laptops or Apple Silicon. Each fashions assist 128K token contexts, splendid for lengthy paperwork however compute-intensive.
- Quantization & Efficiency: Each fashions use 4-bit MXFP4 because the default, which helps in lowering reminiscence use and rushing up inference. Nonetheless, with out suitable {hardware}, they fall again to 16-bit and require roughly ~48 GB for GPT-Oss-20b. Velocity will be additional improved utilizing non-compulsory superior kernels like FlashAttention.
- License & Utilization: Launched beneath Apache 2.0, each fashions can be utilized, modified, and distributed freely, even for business use, with no royalties or code-sharing necessities. No API charges or license restrictions apply.
| Specification | GPT-Oss-120b | GPT-Oss-20b |
|---|---|---|
| Whole Parameters | 117 billion | 21 billion |
| Lively Parameters per Token | 5.1 billion | 3.6 billion |
| Structure | Combination-of-Specialists with 128 consultants (4 energetic/token) | Combination-of-Specialists with 32 consultants (4 energetic/token) |
| Transformer Blocks | 36 layers | 24 layers |
| Context Window | 128,000 tokens | 128,000 tokens |
| Reminiscence Necessities | 80 GB (matches on a single H100 GPU) | 16 GB |
Set up and Setup Course of
Listed here are the methods to get began with GPT-Oss:
1. Hugging Face Transformers: Set up the newest libraries and cargo the mannequin straight. The next command installs the required conditions:
pip set up --upgrade speed up transformersThe code beneath downloads the required mannequin from the Hugging Face hub.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
mannequin = AutoModelForCausalLM.from_pretrained(
"openai/gpt-oss-20b", device_map="auto", torch_dtype="auto")As soon as the mannequin has been downloaded, you may try it out utilizing:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain why the sky is blue."}
]
inputs = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(mannequin.system)
outputs = mannequin.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))This setup was documented in OpenAI’s information and runs on any GPU. (For greatest pace on NVIDIA A100/H100 playing cards, set up triton kernels to make use of MXFP4; in any other case the mannequin will use 16-bit internally).
2. vLLM: For top-throughput or multi-GPU serving, you need to use the vLLM library. OpenAI notes that on 2x H100s. You possibly can set up vLLM utilizing:
pip set up vllmOne can begin a server with:
vllm serve openai/gpt-oss-120b --tensor-parallel-size 2Or in Python:
from vllm import LLM
llm = LLM("openai/gpt-oss-120b", tensor_parallel_size=2)
output = llm.generate("San Francisco is a")
print(output)This makes use of optimized consideration kernels on Hopper GPUs.
3. Ollama (Native on Mac/Home windows): Ollama is a turnkey native chat server. After putting in Ollama, merely run:
ollama pull gpt-oss:20b
ollama run gpt-oss:20bThis can obtain the mannequin (quantized) and launch a chat UI. Ollama auto-applies a chat template (the “concord” format) by default. You too can name it through API. For instance, utilizing Python and the OpenAI SDK pointed at Ollama’s endpoint:
from openai import OpenAI
consumer = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = consumer.chat.completions.create(
mannequin="gpt-oss:20b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain what MXFP4 quantization is."}
]
)
print(response.decisions[0].message.content material)This sends the immediate to the native GPT-Oss mannequin, identical to the official API.
4. Llama.cpp (CPU/ARM): Pre-built GGUF variations of the fashions can be found (e.g, ggml-org/GPT-Oss-120b-GGUF on Hugging Face). After putting in llama.cpp, you may serve the mannequin domestically:
# macOS:
brew set up llama.cpp
# Begin a neighborhood HTTP server for inference:
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 -fa --jinja --reasoning-format noneThen ship chat messages to http://localhost:8080 in the identical format. This selection permits operating even on a CPU or GPU-agnostic atmosphere with JIT or Vulkan assist.
General, GPT-Oss fashions can be utilized with most typical frameworks. The above strategies (Transformers, vLLM, Ollama, llama.cpp) cowl desktop and server setups. You possibly can combine and match – as an illustration, run one setup for quick inference (vLLM on GPU) and one other for on-device testing (Ollama or llama.cpp).
Arms-On Demo Part
Activity 1: Reasoning Activity
Immediate: “”” Choose the choice that’s associated to the third time period in the identical means because the second time period is expounded to the primary time period.
IVORY : ZWSPJ :: CREAM : ?
A. NFDQB
B. SNFDB
C. DSFCN
D. BQDZL
”””
import os
os.environ['HF_TOKEN'] = 'HF_TOKEN'
from openai import OpenAI
consumer = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = consumer.chat.completions.create(
mannequin="openai/GPT-Oss-20b", # openai/GPT-Oss-120b Change to make use of 120b mannequin
messages=[
{
"role": "user",
"content": """Select the option that is related to the third term in the same way as the second term is related to the first term.
IVORY : ZWSPJ :: CREAM : ?
A. NFDQB
B. SNFDB
C. DSFCN
D. BQDZL
"""
}
],
)
# Examine if there's content material in the primary content material discipline
if completion.decisions[0].message.content material:
print("Content material:", completion.decisions[0].message.content material)
else:
# If content material is None, test reasoning_content
print("Reasoning Content material:", completion.decisions[0].message.reasoning_content)
# For Markdown show in Jupyter
from IPython.show import show, Markdown
# Show the precise content material that exists
content_to_display = (completion.decisions[0].message.content material or
completion.decisions[0].message.reasoning_content or
"No content material out there")GPT-Oss-120b Response:
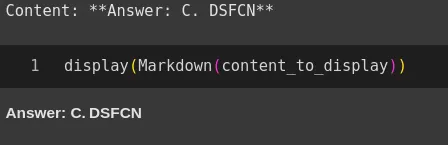
GPT-Oss-20b Response:

Comparative Evaluation
GPT-Oss-120B accurately identifies the related sample within the analogy and selects choice C with deliberate reasoning. Because it methodically interprets the character transformation between phrase pairs to acquire the right mapping. Alternatively, GPT-Oss-20B fails to yield any outcome on this job, doubtless because of the limits of the output tokens.
This would possibly counsel difficulties with output size, in addition to computational inefficiencies. General, GPT-Oss-120B is best capable of handle symbolic reasoning with way more management and accuracy; subsequently, it’s extra dependable than GPT-Oss-20B for this reasoning job involving verbal analogy.
Activity 2: Code Era
Immediate: “”” Given two sorted arrays nums1 and nums2 of measurement m and n respectively, return the median of the 2 sorted arrays.
The general run time complexity ought to be O(log (m+n)) in C++.
Instance 1:
Enter: nums1 = [1,3], nums2 = [2]
Output: 2.00000
Rationalization: merged array = [1,2,3] and median is 2.
Instance 2:
Enter: nums1 = [1,2], nums2 = [3,4]
Output: 2.50000
Rationalization: merged array = [1,2,3,4] and median is (2 + 3) / 2 = 2.5.
Constraints:
nums1.size == m
nums2.size == n
0
0
1
-106
”””
import os
from openai import OpenAI
consumer = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = consumer.chat.completions.create(
mannequin="openai/GPT-Oss-120b", # openai/GPT-Oss-20b change to make use of 20b mannequin
messages=[
{
"role": "user",
"content": """Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays.
The overall run time complexity should be O(log (m+n)) in C++.
Example 1:
Input: nums1 = [1,3], nums2 = [2]
Output: 2.00000
Rationalization: merged array = [1,2,3] and median is 2.
Instance 2:
Enter: nums1 = [1,2], nums2 = [3,4]
Output: 2.50000
Rationalization: merged array = [1,2,3,4] and median is (2 + 3) / 2 = 2.5.
Constraints:
nums1.size == m
nums2.size == n
0 GPT-Oss-120b Response
embody
utilizing namespace std;
class Answer {
public:
double findMedianSortedArrays(const vector& nums1,
const vector& nums2) {
// Let A be the shorter array.
const vector* A = &nums1;
const vector* B = &nums2;
if (A->measurement() > B->measurement()) swap(A, B); // now |A| ≤ |B|
int m = A->measurement();
int n = B->measurement();
int complete = m + n;
int half = (complete + 1) / 2; // measurement of left half
int low = 0, excessive = m; // we search over variety of components taken from A
whereas (low b_right) { // i too giant
excessive = i - 1;
} else if (b_left > a_right) { // i too small
low = i + 1;
} else { // right cut up
int max_left = max(a_left, b_left);
if (complete % 2 == 1) // odd
return static_cast(max_left);
int min_right = min(a_right, b_right);
return (max_left + min_right) / 2.0;
}
}
// The code by no means reaches right here as a result of the constraints assure at the least one aspect.
return 0.0;
}
};
/* Instance utilization
int primary() {
Answer s;
vector a = {1, 3};
vector b = {2};
cout GPT-Oss-20b Response
# Reference Implementation (C++17)
embody
utilizing namespace std;
class Answer {
public:
double findMedianSortedArrays(vector& nums1,
vector& nums2) {
// Guarantee nums1 is the shorter array
if (nums1.measurement() > nums2.measurement())
return findMedianSortedArrays(nums2, nums1);
int m = nums1.measurement();
int n = nums2.measurement();
int low = 0, excessive = m;
int halfLen = (m + n + 1) / 2; // measurement of left half
whereas (low nums1[i])
low = i + 1;
// i too huge - should transfer left
else if (i > 0 && nums1[i-1] > nums2[j])
excessive = i - 1;
else {
// right partition discovered
int maxLeft;
if (i == 0)
maxLeft = nums2[j-1];
else if (j == 0)
maxLeft = nums1[i-1];
else
maxLeft = max(nums1[i-1], nums2[j-1]);
// odd complete, median is maxLeft
if ((m + n) % 2 == 1)
return static_cast(maxLeft);
// even complete, want minRight as effectively
int minRight;
if (i == m)
minRight = nums2[j];
else if (j == n)
minRight = nums1[i];
else
minRight = min(nums1[i], nums2[j]);
return (maxLeft + minRight) / 2.0;
}
}
// Ought to by no means attain right here for legitimate enter
return 0.0;
}
};
/* Instance utilization:
int primary() {
Answer s;
vector a = {1, 3};
vector b = {2};
cout Comparative Evaluation
GPT-Oss-120B completes the analogy precisely, choosing choice C, and exhibits sturdy rationale by efficiently figuring out the letter substitution sample. The mannequin exhibits good reasoning by way of dealing with shifts within the letters’ oscillatory and conserving monitor of relationships between issues. Alternatively, GPT-Oss-20B is unable to even full the duty! The mannequin exceeded the output token restrict and didn’t return a solution. This means GPT-Oss-20B is inefficient in both its useful resource utilization or its dealing with of the immediate. General, GPT-Oss-120B demonstrates significantly better efficiency in structured reasoning duties, making it a significantly better alternative than GPT-Oss-20B for duties associated to symbolic analogies.
Mannequin Choice Information
Selecting between the 120B and 20B fashions is determined by the wants of 1’s mission or the duty on which we’re working:
- gpt-oss-120b: That is the high-power mannequin. Use it for the toughest reasoning duties, complicated code era, math downside fixing, or domain-specific Q&A. It performs near OpenAI’s o4-mini mannequin. Due to this fact, it wants a big GPU with roughly 80GB+ VRAM to run it and excels on benchmarks and long-form duties the place step-by-step reasoning is essential.
- gpt-oss-20b: This can be a “workhorse” mannequin optimized for effectivity. It matches the standard of OpenAI’s o3-mini on many benchmarks, however can run on a single 16GB VRAM. Select 20B if you want a quick on-device assistant, low-latency chatbot, or instruments that use net search/Python calls. It’s splendid for proof-of-concepts, cell/edge purposes, or when {hardware} is constrained. In lots of circumstances, the 20B mannequin solutions effectively sufficient. For instance, it scored ~96% on a troublesome math contest job, practically matching 120B.
Efficiency Benchmarks and Comparisons
On customary benchmarks, OpenAI’s gpt-oss shares outcomes. The 120B mannequin works its means upward, scoring greater than the 20B mannequin on robust reasoning and data duties, each nonetheless having wonderful performances.
| Benchmark | gpt-oss-120b | gpt-oss-20b | OpenAI o3 | OpenAI o4-mini |
|---|---|---|---|---|
| MMLU | 90.0 | 85.3 | 93.4 | 93.0 |
| GPQA Diamond | 80.1 | 71.5 | 83.3 | 81.4 |
| Humanity’s Final Examination | 19.0 | 17.3 | 24.9 | 17.7 |
| AIME 2024 | 96.6 | 96.0 | 95.2 | 98.7 |
| AIME 2025 | 97.9 | 98.7 | 98.4 | 99.5 |
Use Instances and Purposes
Listed here are some purposes for GPT-Oss:
- Content material Era and Rewriting: Generate or rewrite articles, tales, or advertising and marketing copy. These fashions can describe their thought course of earlier than writing and help writers and journalists in growing higher content material.
- Tutoring and Training: can exhibit alternative ways to explain an idea, stroll by means of issues step-by-step, and supply suggestions to academic apps or tutoring instruments, and medication.
- Code Era: can generate code, debug code, or clarify code very effectively. Fashions may internally execute instruments, permitting them to be useful with associated growth duties or as coding assistants.
- Analysis Help: can summarize paperwork, reply to domain-specific questions, and analyze information. The bigger fashions will also be fine-tuned for particular fields of research, akin to regulation, medication, or science.
- Autonomous Brokers: Allows actions that use instruments to construct bots with autonomous brokers that may browse the online, name APIs, or run code. Integrates simply with agent frameworks to construct extra complicated step-based workflows.
Conclusion
The 120B mannequin clearly outperforms throughout the board: producing sharper content material, fixing more durable issues, writing higher code, and adapting quicker in analysis and autonomous duties. Its solely actual tradeoff is useful resource depth, which makes native deployment a problem. However when you’ve acquired the infrastructure, there’s no contest. This isn’t simply an improve! It’s a complete new tier of functionality.
Hiya! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my abilities in a collaborative atmosphere whereas persevering with to study and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}