
You might need interacted with ChatGPT ultimately. Whether or not you’ve requested for assist in instructing a selected idea or an in depth guided step to resolve a posh downside.
In between, you must present a “immediate”(quick or lengthy) to speak with the LLM to provide the specified response. Nevertheless, the true essence of those fashions is not only of their structure, however in how intelligently we talk with them.
That is the place immediate engineering methods begin to occur. Proceed studying this weblog to study what immediate engineering is, its methods, key parts, and a hands-on sensible information on constructing an LLM utilizing immediate engineering.
What’s Immediate Engineering?
To grasp immediate engineering, let’s break down the time period. The “immediate” refers to a textual content or sentence that LLM intakes as NLP and generate output. The response could possibly be recursive, iterative, or incomplete.
Subsequently, immediate engineering comes into the image. It refers to crafting and optimising prompts to generate an iterative response. These responses fulfill the issue or generate output primarily based on the target desired, therefore controllable output technology.
With immediate engineering, you’re pushing an LLM right into a definitive path with an improved immediate to generate an efficient response.
Let’s perceive with an instance.
Immediate Engineering Instance
Think about your self as a tech information author. Your tasks embrace researching, crafting, and optimizing tech articles with a give attention to rating in search engines like google.
So, what’s a fundamental immediate you’ll give to an LLM? It could possibly be like this:
“Draft an Web optimization-focused weblog put up on this “title” together with a number of FAQs.“
It might generate a weblog put up on the given title with FAQs, however they lack factual, reader’s intent, and content material depth.
With immediate engineering, you possibly can sort out this example successfully. Under is an instance of a immediate engineering script:
Immediate: “You might be an professional Web optimization content material editor. Your process is to generate a completely structured, Web optimization-optimized weblog put up from a given title.
Title: “Point out matter right here”
Directions:
– Write a 1500+ phrase weblog put up with Web optimization finest practices.
– Embody meta title, meta description, introduction, structured headings (H2/H3), conclusion, and FAQs.
– Use clear, participating, fact-based writing.
– Naturally optimize for Web optimization with out key phrase stuffing.“
The distinction between these two prompts is the iterative response. The primary immediate might fail to generate an in-depth article, key phrase optimisation, structured readability content material, and so forth., whereas the second immediate intelligently fulfils all of the objectives.
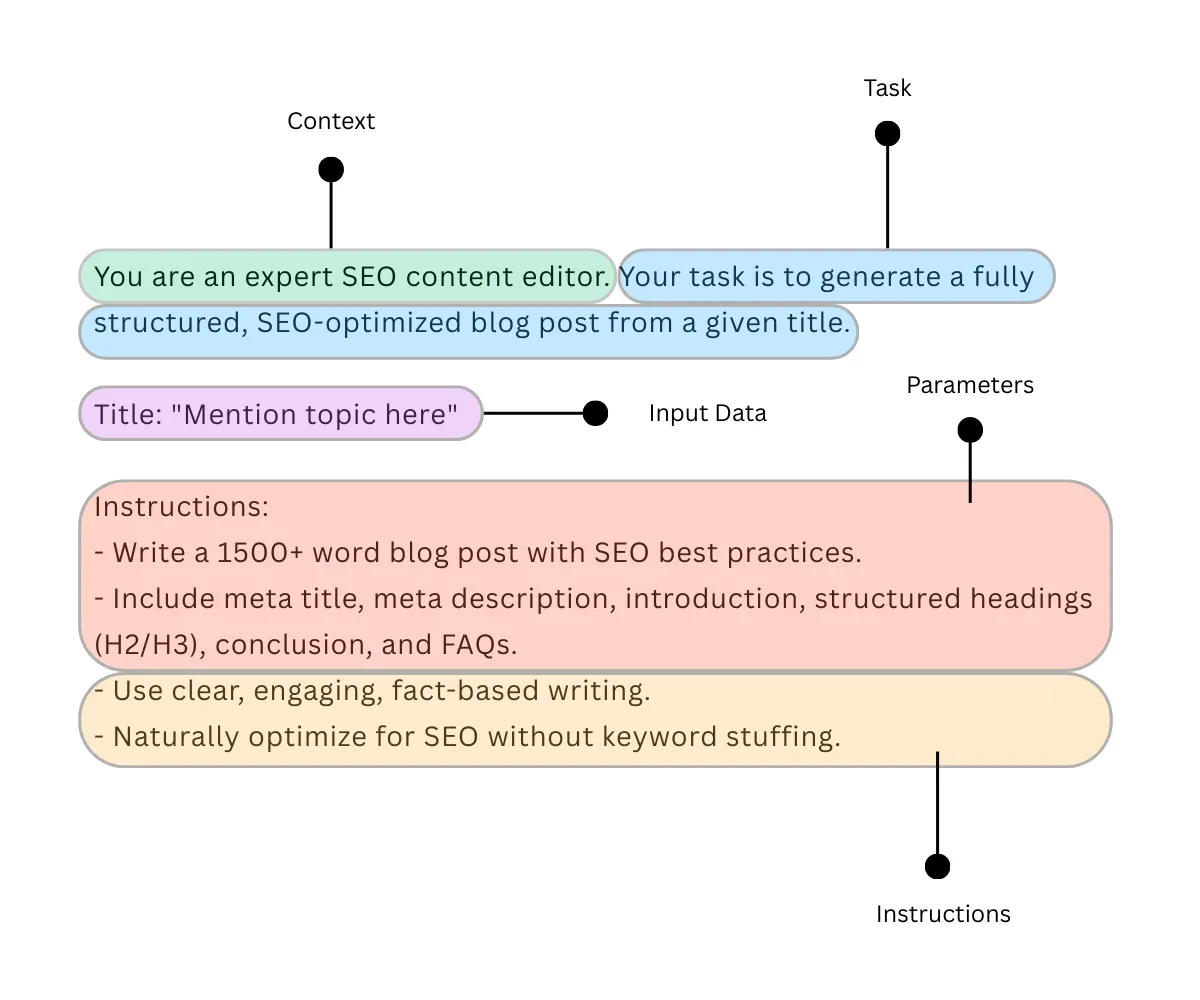
Parts Of Immediate Engineering
You might need noticed essential issues earlier. When optimising for immediate, we outline the duty, give directions, add context, and parameters to provide an LLM a directive strategy for output technology.
Important parts of immediate engineering are as follows:
- Process: In an announcement kind {that a} person particularly defines.
- Instruction: Present obligatory info to finish a process in a significant method.
- Context: Including an additional layer of data to acknowledge by LLM to generate a extra related response.
- Parameters: Imposing guidelines, codecs, or constraints for the response.
- Enter Knowledge: Present the textual content, picture, or different class of knowledge to course of.
The output generated by an LLM from a immediate engineering script can additional be optimised by varied methods. There are two classifications of immediate engineering methods: fundamental and superior.
For now, we’ll talk about solely fundamental immediate engineering methods for newcomers.
Immediate Engineering Strategies For Newcomers
I’ve defined seven immediate engineering methods in a tabular construction with examples.
| Strategies | Rationalization | Immediate Instance |
|---|---|---|
| Zero-Shot Prompting | Producing output by LLM with none examples given. | Translate the next from English to Hindi. “Tomorrow’s match will probably be wonderful.” |
| Few-Shot Prompting | Producing output by an LLM by studying from a number of units of instance ingestion. | Translate the next from English to Hindi. “Tomorrow’s match will probably be wonderful.” For instance: Hiya → नमस्ते All good → सब अच्छा Nice Recommendation → बढ़िया सलाह |
| One-Shot Prompting | Producing output by an LLM studying from a one-example reference. | Translate the next from English to Hindi.“Tomorrow’s match will probably be wonderful.” For instance: Hiya → नमस्ते |
| Chain-of-thought (CoT) Prompting | Directing LLM to interrupt down reasoning into steps to enhance advanced process efficiency. | Resolve: 12 + 3 * (4 — 2). First, calculate 4 — 2. Then, multiply the outcome by 3. Lastly, add 12. |
| Tree-of-thought (ToT) Prompting | Structuring the mannequin’s thought course of as a tree to know the processing conduct. | Think about three economists making an attempt to reply the query: What would be the value of gasoline tomorrow? Every economist writes down one step of their reasoning at a time, then proceeds to the following. If at any stage one realizes their reasoning is flawed, they exit the method. |
| Meta Prompting | Guiding a mannequin to create a immediate to execute completely different duties. | Write a immediate that helps generate a abstract of any information article. |
| Reflexion | Prompting to instruct the mannequin to have a look at previous responses and enhance responses sooner or later. | Replicate on the errors made within the earlier rationalization and enhance the following one. |
Now that you’ve discovered immediate engineering methods, let’s follow constructing an LLM software.
Constructing LLM Purposes Utilizing Immediate Engineering
I’ve demonstrated the way to construct a customized LLM software utilizing immediate engineering. There are numerous methods to perform this. However I saved the method easy and beginner-friendly.
Stipulations:
- An working system with a minimal of 8GB VRAM
- Obtain Python 3.13 in your system
- Obtain and set up Ollama
Goal: Creating “Web optimization Weblog Generator LLM” the place the mannequin takes a title and produces an Web optimization-optimized weblog draft.
Step 1 – Putting in The Llama 3:8B Mannequin
After confirming that you’ve glad the conditions, head to the command line interface and set up the Llama3 8b mannequin, as that is our foundational mannequin for communication.
ollama run llama3:8b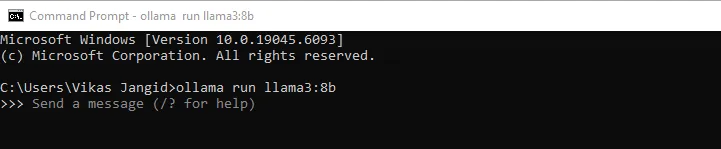
The dimensions of the LLM is roughly 4.3 Gigabytes, so it’d take a couple of minutes to obtain. You’ll see successful message after obtain completion.
Step 2 – Making ready Our Mission Information
We would require a mixture of information for speaking with the LLM. It features a Python script and some necessities information.
Create a folder and identify it “seo-blog-llm” and create a necessities.txt file with the next and put it aside.
ollama>=0.3.0
python-slugify>=8.0.4Now, head to the command line interface and on the challenge supply path, run the next command.
pip set up -r necessities.txt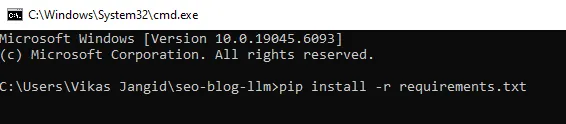
Step 3 – Creating Immediate File
In chic editor or any code-based editor, save the next code logic with the file identify prompts.py. This logic guides the LLM in the way to reply and produce output. That is the place immediate engineering shines.
SYSTEM_PROMPT = """You might be an professional Web optimization content material editor. You write fact-aware, reader-first articles that rank.
Observe these guidelines strictly:
- Output ONLY Markdown for the ultimate article; no explanations or preambles.
- Embody on the high a YAML entrance matter block with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target.
- Preserve meta_title ≤ 60 chars; meta_description ≤ 160 chars.
- Use H2/H3 construction, quick paragraphs, bullets, and numbered lists the place helpful.
- Preserve key phrase utilization pure (no stuffing).
- Finish with a conclusion and a 4–6 query FAQ.
- For those who insert any statistic or declare, mark it with [citation needed] (because you’re offline).
"""
USER_TEMPLATE = """Title: "{title}"
Write a {word_count}-word Web optimization weblog for the above title.
Constraints:
- Target market: {viewers}
- Tone: easy, informative, participating (as if explaining to a 20-year-old)
- Geography: {geo}
- Major key phrase: {primary_kw}
- 5–8 secondary key phrases: {secondary_kws}
Format:
1) YAML entrance matter with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target
2) Intro (50–120 phrases)
3) Physique with clear H2/H3s together with the first key phrase naturally in a minimum of one H2
4) Sensible suggestions, checklists, and examples
5) Conclusion
6) FAQ (4–6 Q&As)
Guidelines:
- Don't embrace “Define” or “Draft” sections.
- Don't present your reasoning or chain-of-thought.
- Preserve meta fields inside limits. If wanted, shorten.
"""Step 4 – Setting Up Python Script
That is our grasp file, which acts as a mini software for speaking with the LLM. In chic editor or any code-based editor, save the next code logic with the file identify generator.py.
import re
import os
from datetime import datetime
from slugify import slugify
import ollama # pip set up ollama
from prompts import SYSTEM_PROMPT, USER_TEMPLATE
MODEL_NAME = "llama3:8b" # alter in the event you pulled a unique tag
OUT_DIR = "output"
os.makedirs(OUT_DIR, exist_ok=True)
def build_user_prompt(
title: str,
word_count: int = 1500,
viewers: str = "newbie bloggers and content material entrepreneurs",
geo: str = "international",
primary_kw: str = None,
secondary_kws: listing[str] = None,
):
if primary_kw is None:
primary_kw = title.decrease()
if secondary_kws is None:
secondary_kws = []
secondary_str = ", ".be a part of(secondary_kws) if secondary_kws else "n/a"
return USER_TEMPLATE.format(
title=title,
word_count=word_count,
viewers=viewers,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_str
)
def call_llm(system_prompt: str, user_prompt: str, temperature=0.4, num_ctx=8192):
# Chat-style name for higher instruction-following
resp = ollama.chat(
mannequin=MODEL_NAME,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
choices={
"temperature": temperature,
"num_ctx": num_ctx,
"top_p": 0.9,
"repeat_penalty": 1.1,
},
stream=False,
)
return resp["message"]["content"]
def validate_front_matter(md: str):
"""
Primary YAML entrance matter extraction and checks for meta size.
"""
fm = re.search(r"^---s*(.*?)s*---", md, re.DOTALL | re.MULTILINE)
points = []
meta = {}
if not fm:
points.append("Lacking YAML entrance matter block ('---').")
return meta, points
block = fm.group(1)
# naive parse (hold easy for no dependencies)
for line in block.splitlines():
if ":" in line:
ok, v = line.cut up(":", 1)
meta[k.strip()] = v.strip().strip('"').strip("'")
# checks
mt = meta.get("meta_title", "")
mdsc = meta.get("meta_description", "")
if len(mt) > 60:
points.append(f"meta_title too lengthy ({len(mt)} chars).")
if len(mdsc) > 160:
points.append(f"meta_description too lengthy ({len(mdsc)} chars).")
if "slug" not in meta or not meta["slug"]:
# fall again to title-based slug if wanted
title_match = re.search(r'Title:s*"([^"]+)"', md)
fallback = slugify(title_match.group(1)) if title_match else f"post-{datetime.now().strftime('%YpercentmpercentdpercentHpercentM')}"
meta["slug"] = fallback
points.append("Lacking slug; auto-generated.")
return meta, points
def ensure_headers(md: str):
if "## " not in md:
return ["No H2 headers found."]
return []
def save_article(md: str, slug: str | None = None):
if not slug:
slug = slugify("article-" + datetime.now().strftime("%YpercentmpercentdpercentHpercentMpercentS"))
path = os.path.be a part of(OUT_DIR, f"{slug}.md")
with open(path, "w", encoding="utf-8") as f:
f.write(md)
return path
def generate_blog(
title: str,
word_count: int = 1500,
viewers: str = "newbie bloggers and content material entrepreneurs",
geo: str = "international",
primary_kw: str | None = None,
secondary_kws: listing[str] | None = None,
):
user_prompt = build_user_prompt(
title=title,
word_count=word_count,
viewers=viewers,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_kws or [],
)
md = call_llm(SYSTEM_PROMPT, user_prompt)
meta, fm_issues = validate_front_matter(md)
hdr_issues = ensure_headers(md)
points = fm_issues + hdr_issues
path = save_article(md, meta.get("slug"))
return {
"path": path,
"meta": meta,
"points": points
}
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate Web optimization weblog from title")
parser.add_argument("--title", required=True, assist="Weblog title")
parser.add_argument("--words", sort=int, default=1500, assist="Goal phrase rely")
args = parser.parse_args()
outcome = generate_blog(
title=args.title,
word_count=args.phrases,
primary_kw=args.title.decrease(), # easy default key phrase
secondary_kws=[],
)
print("Saved:", outcome["path"])
if outcome["issues"]:
print("Validation notes:")
for i in outcome["issues"]:
print("-", i)Simply to make sure you’re doing proper. Your challenge folder ought to have the next information. Observe that the output folder and the _pycache_ folder will probably be created explicitly.
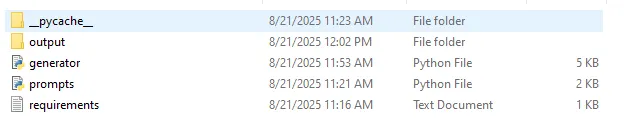
Step 5 – Run It
You might be nearly achieved. Within the command line interface, run the next command to get the output. An output will robotically get saved within the output folder of your challenge supply within the (.md) format file.
python generator.py --title "Luxurious Inside Design Concepts for Villas & Resorts" --words 1800And you’ll see one thing like this within the command line:

To open the generated output markdown (.md) file. Both use VS Code or drag-and-drop to any browser. Right here, I’ve used the Chrome browser to open the file, and the output appears to be like acceptable:
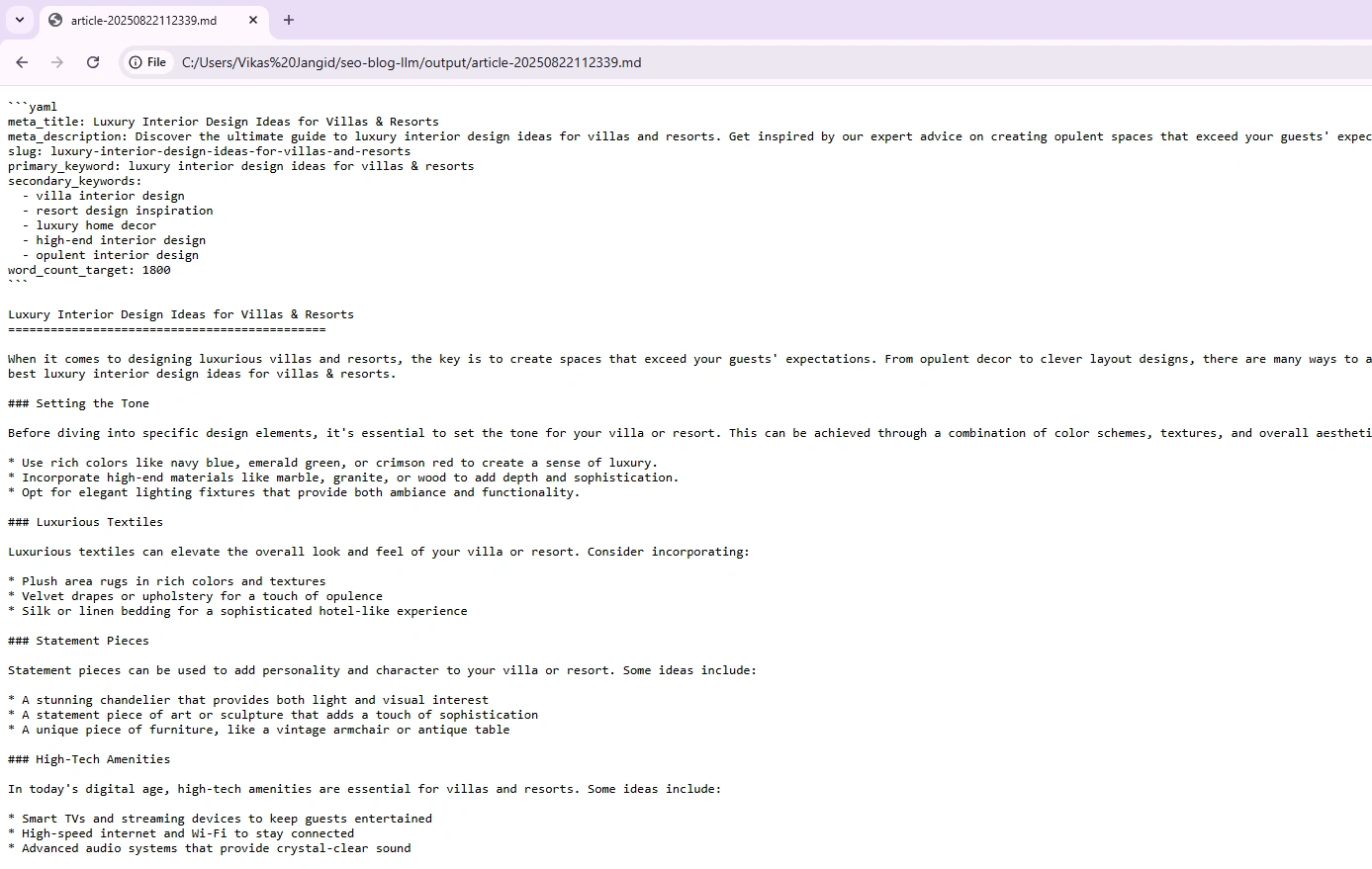
Issues to remember
Right here are some things to remember whereas utilizing the above code:
- Operating the setup with solely 8 GB RAM led to gradual responses. For a smoother expertise, I like to recommend 12–16 GB RAM when working LLaMA 3 regionally.
- The mannequin LLama3:8B usually returned fewer than the requested phrases. The generated output is fewer than 800 phrases.
- Add passing parameters like
geo,tone, andtarget marketwithin the run command to generate extra specified output.
Key Takeaway
You’ve simply constructed a customized LLM-powered software by yourself machine. What we did was use the uncooked LLaMa 3 and formed its conduct with immediate engineering.
Right here’s a fast recap:
- Put in Ollama that allows you to run LLaMA 3 regionally.
- Pulled the LLaMA 3 8B mannequin so that you don’t depend on exterior APIs.
- Wrote immediate.py that defines the way to instruct the mannequin.
- Wrote generator.py that acts as your mini app.
In the long run, you’ve discovered immediate engineering idea with its methods and hands-on follow growing an LLM-powered software.
Learn extra:
Continuously Requested Questions
A. LLMs can not generate output explicitly and due to this fact require a immediate that guides them to grasp what process or info to provide.
A. Immediate engineering instructs LLM to behave logically and successfully earlier than producing the output. It means crafting particular and well-defined directions to information the LLM in producing the specified output.
A. The 4 pillars of immediate engineering are Simplicity (clear and straightforward), Specificity (concise and particular), Construction (logical format), and Sensitivity (honest and unbiased).
A. Sure, immediate engineering is a ability and in vogue. It requires thorough considering in crafting efficient prompts that information LLMs in direction of desired outcomes.
A. Immediate engineers are expert professionals in understanding the enter (prompts) and excel in creating dependable and sturdy prompts, particularly for giant language fashions, to optimize their efficiency and guarantee they generate extremely correct and inventive outputs.
I’m Bharat Kumar, a content material editor at The Subsequent Tech with 3+ years of expertise in writing and modifying know-how content material. Presently, exploring Generative AI (GenAI) by Analytics Vidhya and sharing my learnings by writing participating, story-driven articles on Synthetic Intelligence, Generative Engines, and Machine Studying.
Login to proceed studying and revel in expert-curated content material.

{kind=link}