
Builders and entrepreneurs are being advised so as to add llms.txt information to their websites to assist massive language fashions (LLMs) “perceive” their content material.
However what precisely is llms.txt, who’s utilizing it, and—extra importantly—must you care?
llms.txt is a proposed normal for serving to LLMs entry and interpret structured content material from web sites. You’ll be able to learn the complete proposal on llmstext.org.
In a nutshell, it’s a textual content file designed to inform LLMs the place to seek out the great things: API documentation, return insurance policies, product taxonomies, and different context-rich sources. The aim is to take away ambiguity by giving language fashions a curated map of high-value content material, in order that they don’t need to guess what issues.
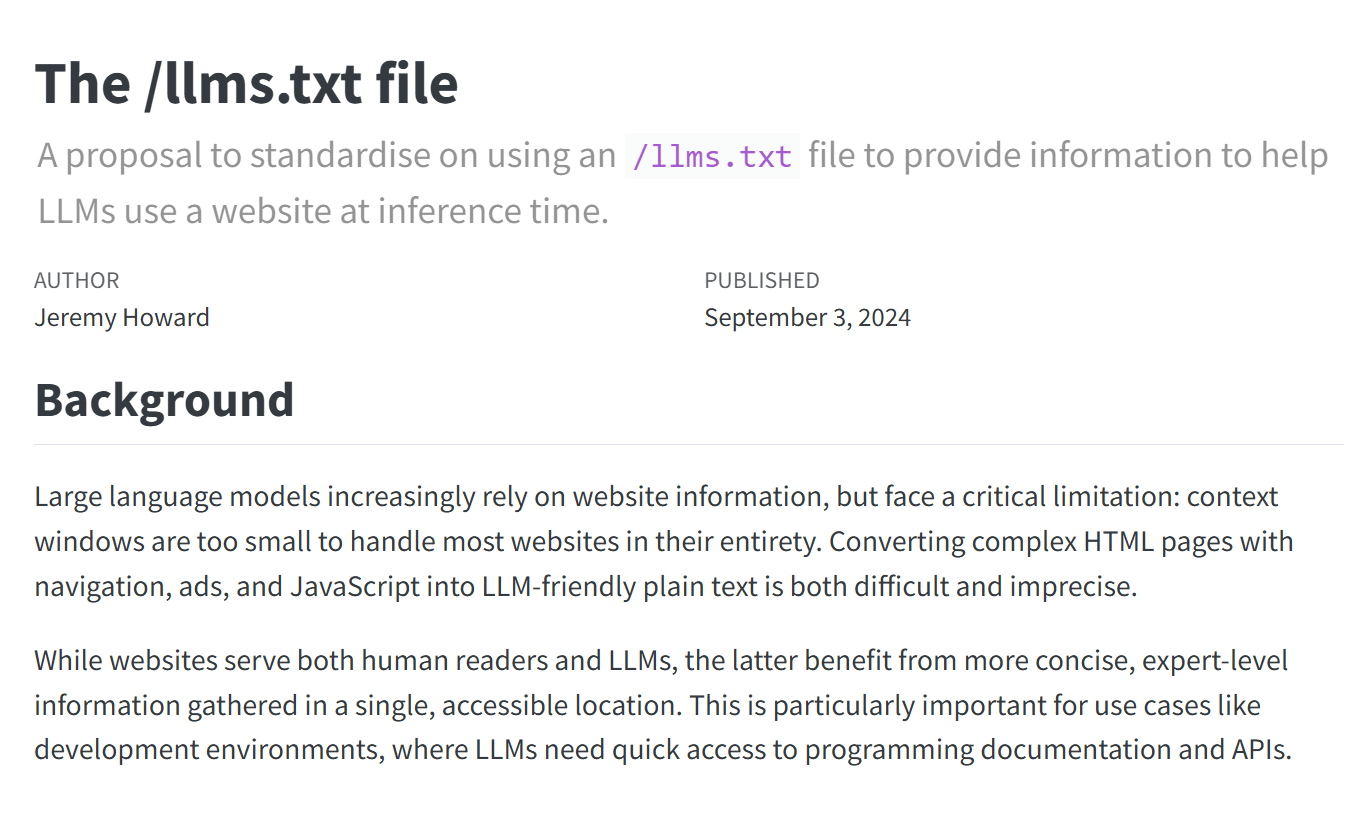
A screenshot from the proposed normal over on https://llmstxt.org/.
In idea, this seems like a good suggestion. We already use information like robots.txt and sitemap.xml to assist search engines like google and yahoo perceive what’s on a web site and the place to look. Why not apply the identical logic to LLMs?
However importantly, no main LLM supplier at present helps llms.txt. Not OpenAI. Not Anthropic. Not Google.
As I mentioned within the intro, llms.txt is a proposed normal. I might additionally suggest an ordinary (let’s name it please-send-me-traffic-robot-overlords.txt), however except the main LLM suppliers agree to make use of it, it’s fairly meaningless.
That’s the place we’re at with llms.txt: it’s a speculative thought with no official adoption.
Don’t sleep on robots.txt
llms.txt won’t impression your visibility on-line, however robots.txt positively does.
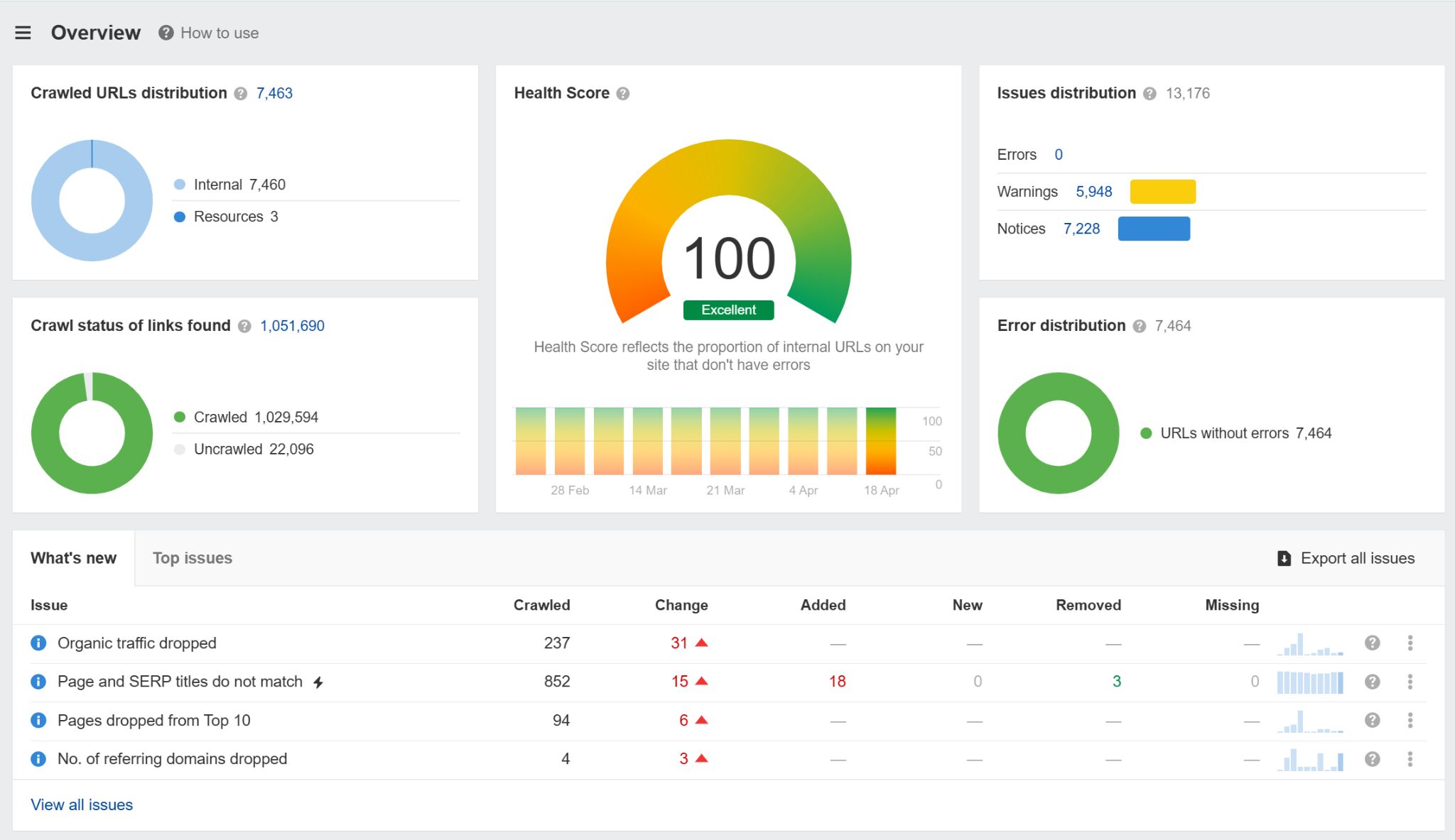
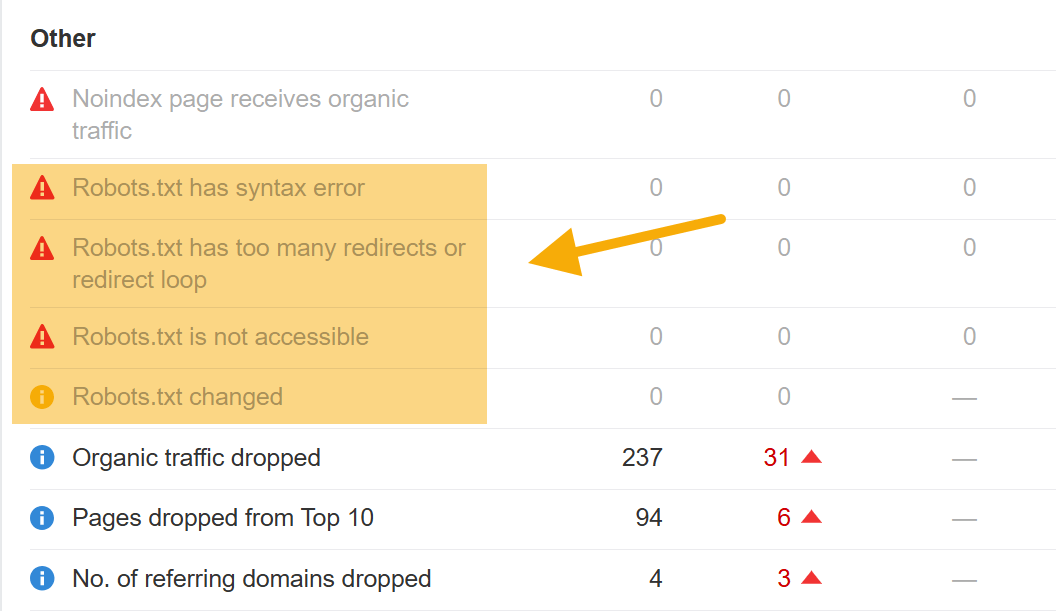
You should use Ahrefs’ Website Audit to observe a whole bunch of frequent technical search engine marketing points, together with issues together with your robots.txt file that may significantly hamper your visibility (and even cease your web site from being crawled).
Right here’s what an llms.txt file appears like in follow. This can be a screenshot of Anthropic’s precise llms.txt file:
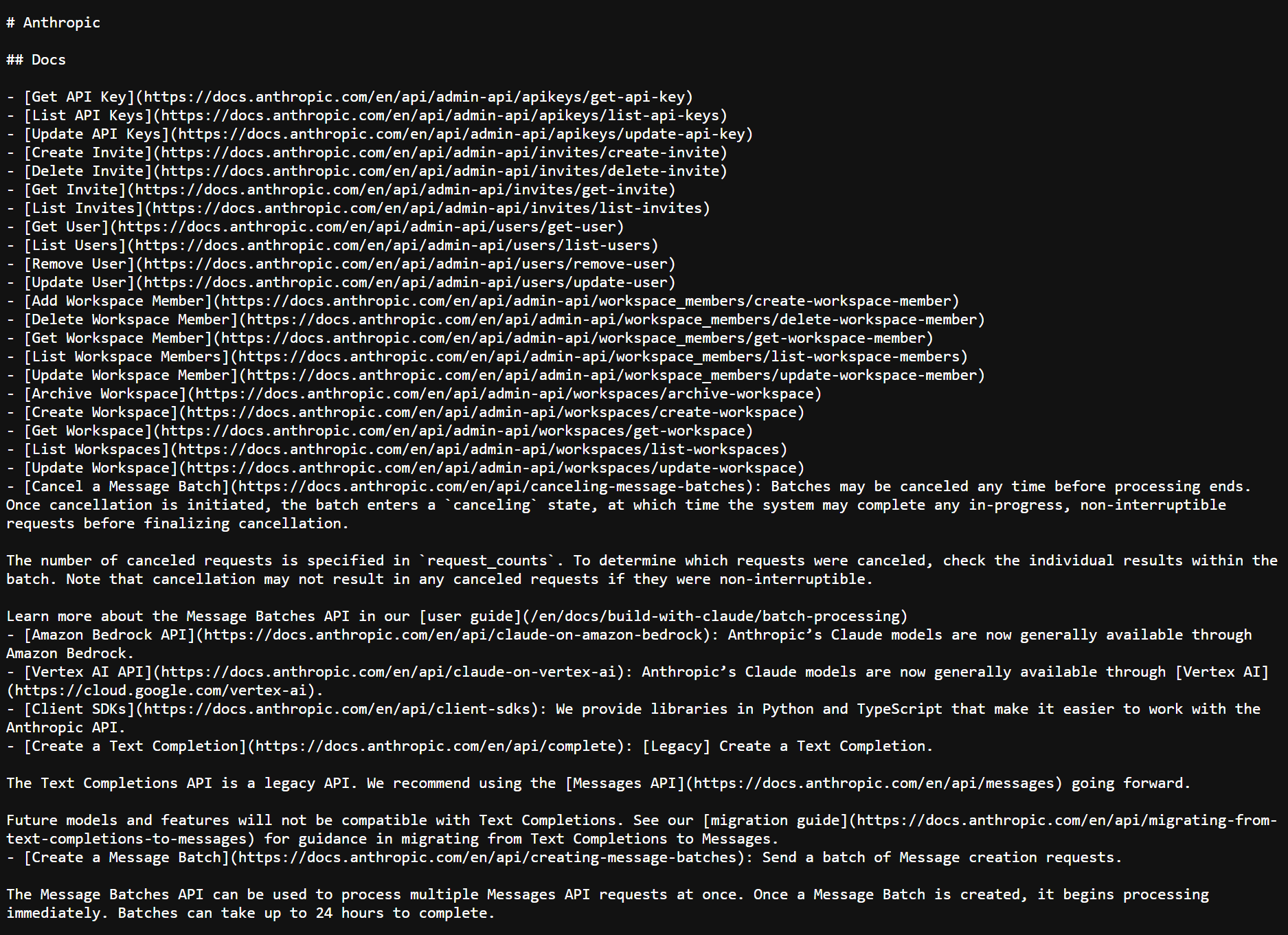
At its core, llms.txt is a Markdown doc (a type of specifically formatted textual content file). It makes use of H2 headers to prepare hyperlinks to key sources. Right here’s a pattern construction you can use:
# llms.txt ## Docs - /api.md A abstract of API strategies, authentication, price limits, and instance requests. - /quickstart.md A setup information to assist builders begin utilizing the platform rapidly. ## Insurance policies - /phrases.md Authorized phrases outlining service utilization. - /returns.md Details about return eligibility and processing. ## Merchandise - /catalog.md A structured index of product classes, SKUs, and metadata. - /sizing-guide.md A reference information for product sizing throughout classes.
You can also make your personal llms.txt in minutes:
- Begin with a fundamental Markdown file.
- Use H2s to group sources by sort.
- Hyperlink to structured, markdown-friendly content material.
- Maintain it up to date.
- Host it at your root area: https://yourdomain.com/llms.txt
You’ll be able to create it your self or use a free llms.txt generator (like this one) to make it for you.
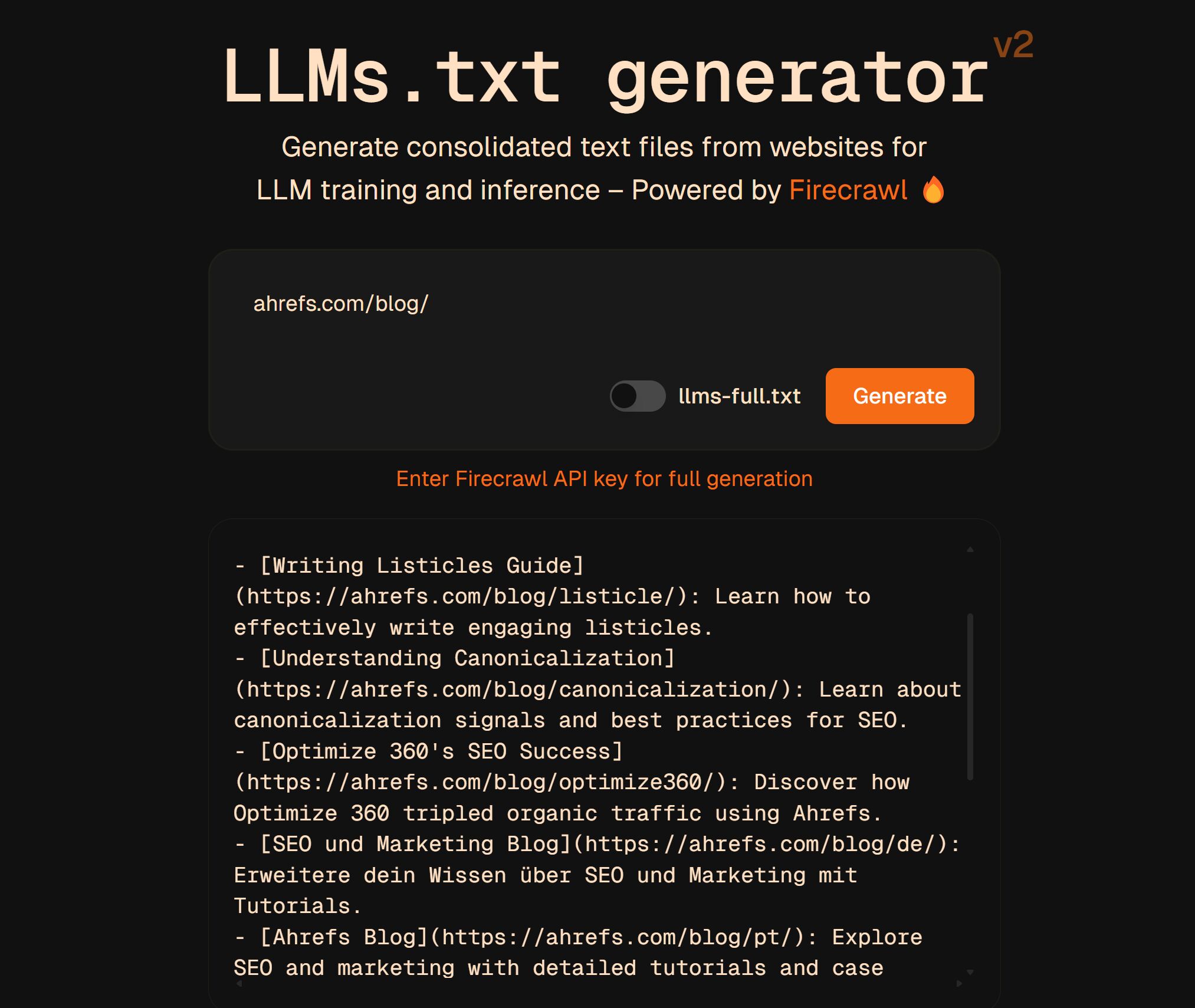
I’ve examine some builders additionally experimenting with LLM-specific metadata of their llms.txt information, like token budgets or most well-liked file codecs (however there’s no proof that that is revered by crawlers or LLM fashions).
You’ll be able to see a listing of corporations utilizing llms.txt at listing.llmstxt.cloud—a community-maintained index of public llms.txt information.
Listed below are a number of examples:
- Mintlify: Developer documentation platform.
- Tinybird: Actual-time knowledge APIs.
- Cloudflare: Lists efficiency and safety docs.
- Anthropic: Publishes a full Markdown map of its API docs.
However what concerning the large gamers?
Thus far, no main LLM supplier has formally adopted llms.txt as a part of their crawler protocol:
- OpenAI (GPTBot): Honors robots.txt however doesn’t formally use llms.txt.
- Anthropic (Claude): Publishes its personal llms.txt, however doesn’t state that its crawlers use the usual.
- Google (Gemini/Bard): Makes use of robots.txt (by way of Person-agent: Google-Prolonged) to handle AI crawl conduct, with no point out of llms.txt assist.
- Meta (LLaMA): No public crawler or steering, and no indication of llms.txt utilization.
This highlights an vital level: creating an llms.txt just isn’t the identical as implementing it in crawler conduct. Proper now, most LLM distributors deal with llms.txt as an fascinating thought, and never one thing that they’ve agreed to prioritize and comply with.
For my part, no, not but.
There’s no proof that llms.txt improves AI retrieval, boosts visitors, or enhances mannequin accuracy. And no supplier has dedicated to parsing it.
But it surely’s additionally very simple to arrange. If you have already got structured content material like product pages or developer docs, compiling an llms.txt is trivial. It’s a Markdown file, hosted by yourself web site. There is perhaps no noticed profit, however there’s additionally no danger. If LLMs do ultimately comply with it as an ordinary, there is perhaps some small benefit to being early adopters.
I believe llms.txt is gaining traction as a result of all of us wish to affect LLM visibility, however we lack the instruments to do it. So we latch onto concepts that really feel like management.
However in my private view, llms.txt is an answer searching for an issue. Engines like google already crawl and perceive your content material utilizing current requirements like robots.txt and sitemap.xml. LLMs use a lot of the identical infrastructure.
As Google’s John Mueller put it in a Reddit submit just lately:
AFAIK not one of the AI companies have mentioned they’re utilizing LLMs.TXT (and you may inform while you have a look at your server logs that they don’t even verify for it). To me, it’s corresponding to the key phrases meta tag – that is what a site-owner claims their web site is about … (Is the positioning actually like that? nicely, you’ll be able to verify it. At that time, why not simply verify the positioning instantly?)

Disagree with me, or wish to share an instance on the contrary? Message me on LinkedIn or X.

{kind=link}