
Enhancing Apache Hive learn and write efficiency on Amazon EMR is essential for organizations coping with large-scale knowledge analytics and processing. When queries execute sooner, companies could make data-driven choices extra shortly, cut back time-to-insight, and optimize their operational prices. In at this time’s aggressive panorama, the place real-time analytics and interactive querying have gotten customary necessities, each millisecond of latency discount can considerably impression enterprise outcomes.
The Amazon EMR runtime for Apache Hive is a performance-optimized runtime that’s 100% API appropriate with open supply Apache Hive. It affords sooner out-of-the-box efficiency than Apache Hive by way of improved question plans, sooner queries, and tuned defaults. Amazon EMR on Amazon EC2 and Amazon EMR Serverless use this optimized runtime, which is 1.5 instances sooner for learn queries than EMR 7.0 based mostly on an business customary benchmark derived from TPC-DS at 3 TB scale and three instances sooner for write queries.
Apache Hive on Amazon EMR added over 10 options from Amazon EMR 7.0 to Amazon EMR 7.10 releases and persevering with. These enhancements are turned on by default and are 100% API appropriate with Apache Hive. A few of the enhancements embrace:
- Default EMR enhanced S3A file system implementation for Apache Hive on Amazon EMR
- Amazon EMR enhanced S3A zero-rename characteristic with 3-times improved write efficiency
- Learn question efficiency parity with EMR File System (EMRFS)
- AWS Lake Formation help with Amazon EMR enhanced S3A
- Fantastic-tuned file itemizing course of for file codecs together with Parquet, Textual content, CSV, and so forth
- Async document reader initialization
- Enhancements to Tez process preemption
- Fantastic-tuned locality throughout container reuse
- Improved Tez relaxed locality
- Enhancements with cut up computation for ORC file codecs
Transitioning from EMRFS to Amazon EMR enhanced S3A
The storage interface of Amazon EMR has advanced by way of two implementations: EMRFS and S3A. EMRFS, a proprietary Amazon Easy Storage Service (Amazon S3) connector developed by Amazon, has been the default filesystem for Amazon EMR since its early days, providing AWS-specific optimizations similar to Constant View for dealing with eventual consistency in Amazon S3, specialised efficiency tuning for the AWS setting, and seamless integration with AWS companies by way of AWS Identification and Entry Administration (IAM) roles. Then again, S3A emerged from the Apache Hadoop open supply neighborhood as a regular S3 connector and has advanced considerably by way of steady enhancements, efficiency optimizations, and enhanced S3 characteristic help. Whereas EMRFS was designed particularly for optimum S3 entry inside Amazon EMR, S3A’s community-driven improvement has closed the efficiency hole with proprietary implementations.
Benefits of utilizing enhanced S3A in Apache Hive on Amazon EMR
The transition from EMRFS to Amazon EMR enhanced S3A because the default filesystem in Amazon EMR 7.10 marks a strategic shift towards open supply standardization whereas sustaining efficiency parity and including advantages like improved portability and neighborhood help.
Primarily based on the Amazon EMR HBase on Amazon S3 transitioning to EMR S3A with comparable EMRFS efficiency weblog put up, S3A in Amazon EMR Hive affords vital benefits over EMRFS, utilizing fashionable AWS applied sciences and superior storage capabilities.
- The combination of AWS SDK v2 brings improved efficiency by way of non-blocking I/O, async purchasers, and higher credential administration.
- S3A gives complete help for Amazon S3 Glacier (Amazon S3 Glacier)and Amazon S3 Glacier Deep Archive, enabling cost-effective knowledge lifecycle administration and environment friendly dealing with of archival knowledge for analytics.
- It affords enhanced infrastructure flexibility with AWS Outposts help for on-premises deployments and customized endpoint help for Amazon S3-compatible storage methods, facilitating hybrid and multi-cloud architectures.
- Efficiency is considerably boosted with Amazon S3 Specific One Zone help, offering single-digit millisecond entry for latency-sensitive analytics and interactive knowledge exploration.
- S3A introduces vector reads, permitting environment friendly entry to columnar knowledge codecs by batching a number of non-contiguous byte ranges right into a single S3
GETrequest, lowering I/O overhead and enhancing question efficiency. - The prefetching characteristic in S3A optimizes sequential learn efficiency by proactively fetching knowledge, enhancing throughput and lowering latency for large-scale knowledge processing duties.
- S3A’s enhanced delegation token help, a results of AWS SDK v2 integration, gives versatile authentication mechanisms together with help for internet identification tokens and federated identification methods.
These superior options make S3A a extra versatile, environment friendly, and performance-oriented alternative for organizations utilizing Hive on Amazon EMR, significantly these requiring subtle knowledge administration and analytics capabilities throughout numerous infrastructure environments.
Learn queries efficiency comparability
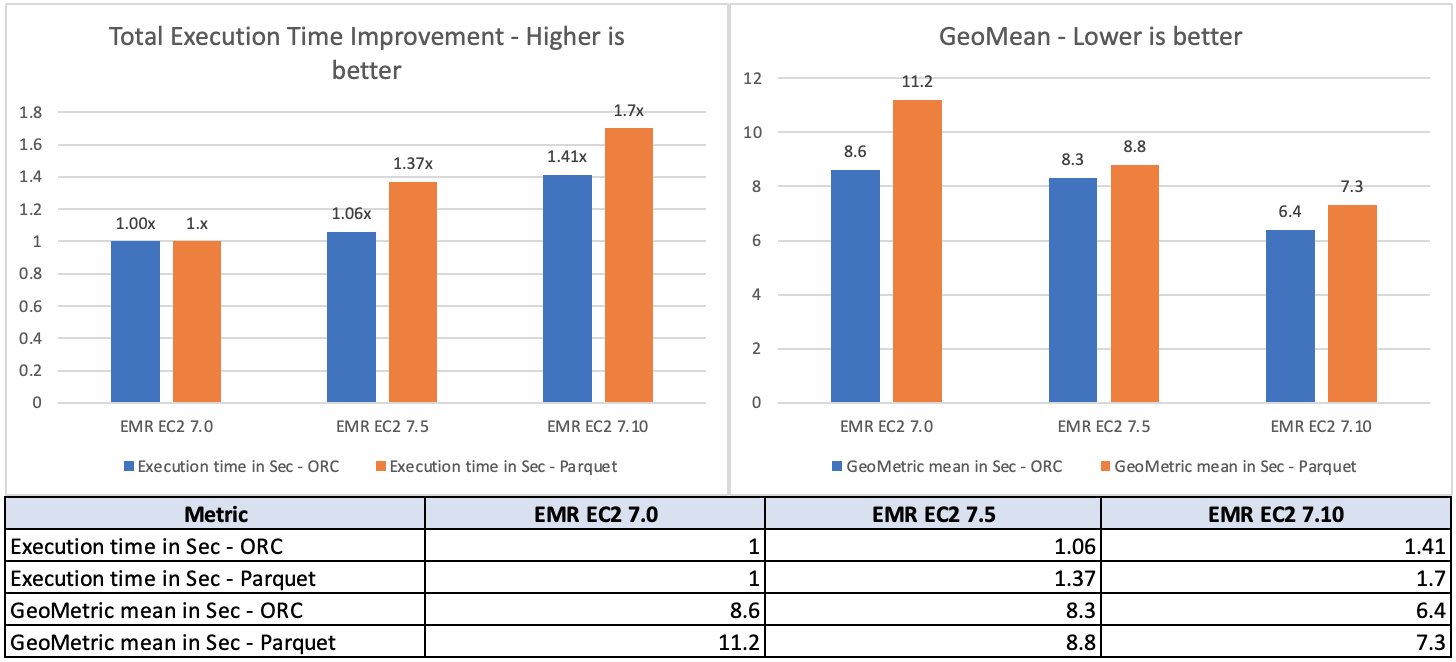
To guage the Amazon EMR Hive engine efficiency, we ran benchmark exams with the three TB TPC-DS datasets. We used Amazon EMR Hive clusters for benchmark exams on Amazon EMR and put in Apache Hive 3.1.3 on Amazon Elastic Compute Cloud (Amazon EC2) clusters designated for open supply software program (OSS) benchmark runs. We ran exams on separate EC2 clusters comprised of 16 m5.8xlarge cases for every of Apache Hive 3.1.3, Amazon EMR 7.0.0, Amazon EMR 7.5.0 and Amazon EMR 7.10.0. The first node has 32 vCPU and 128 GB reminiscence, and 16 employee nodes have a complete of 512 vCPU and 2048 GB reminiscence. We examined with Amazon EMR defaults to focus on the out-of-the-box expertise and tuned Apache Hive with the minimal settings wanted to offer a good comparability.
For the supply knowledge, we selected the three TB scale issue, which comprises 17.7 billion data, roughly 924 GB of compressed knowledge in Parquet file format and ORC file format. The very fact tables are partitioned by the date column, which consists of partitions starting from 200–2,100. No statistics have been pre-calculated for these tables. A complete of 104 Hive SQL queries have been run in 5 iterations sequentially and a mean of every question’s runtime in these 5 iterations was used for comparability. The typical of the 5 iterations’ runtime on Amazon EMR 7.10 was roughly 1.5 instances sooner than Amazon EMR 7.0. The next determine illustrates the whole runtimes in seconds.
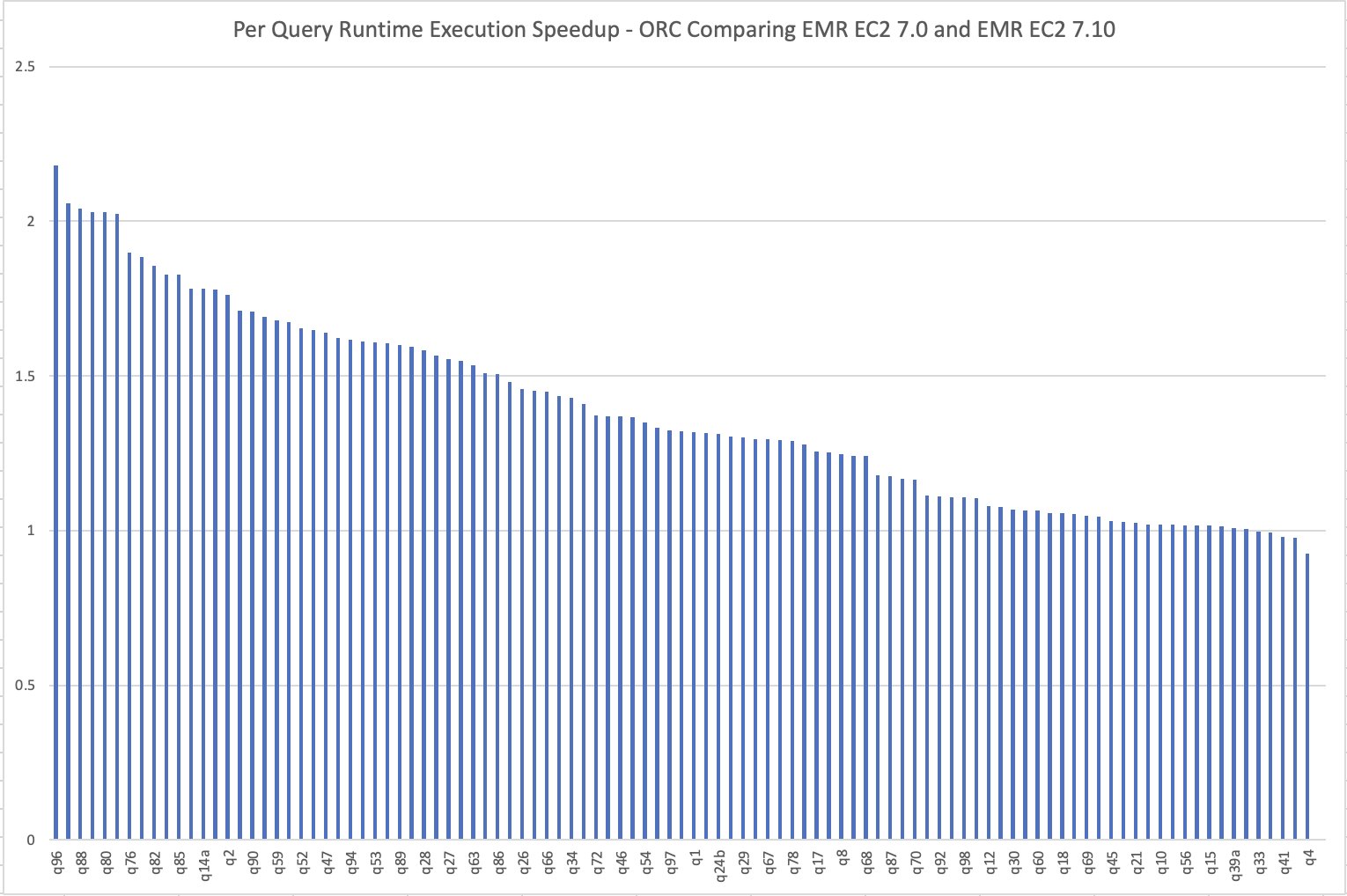
The per-query speedup on Amazon EMR 7.10 when in comparison with Amazon EMR 7.0 is illustrated within the following chart. The horizontal axis represents queries within the TPC-DS 3 TB benchmark ordered by the Amazon EMR speedup descending and the vertical axis reveals the speedup of queries because of the Amazon EMR runtime.
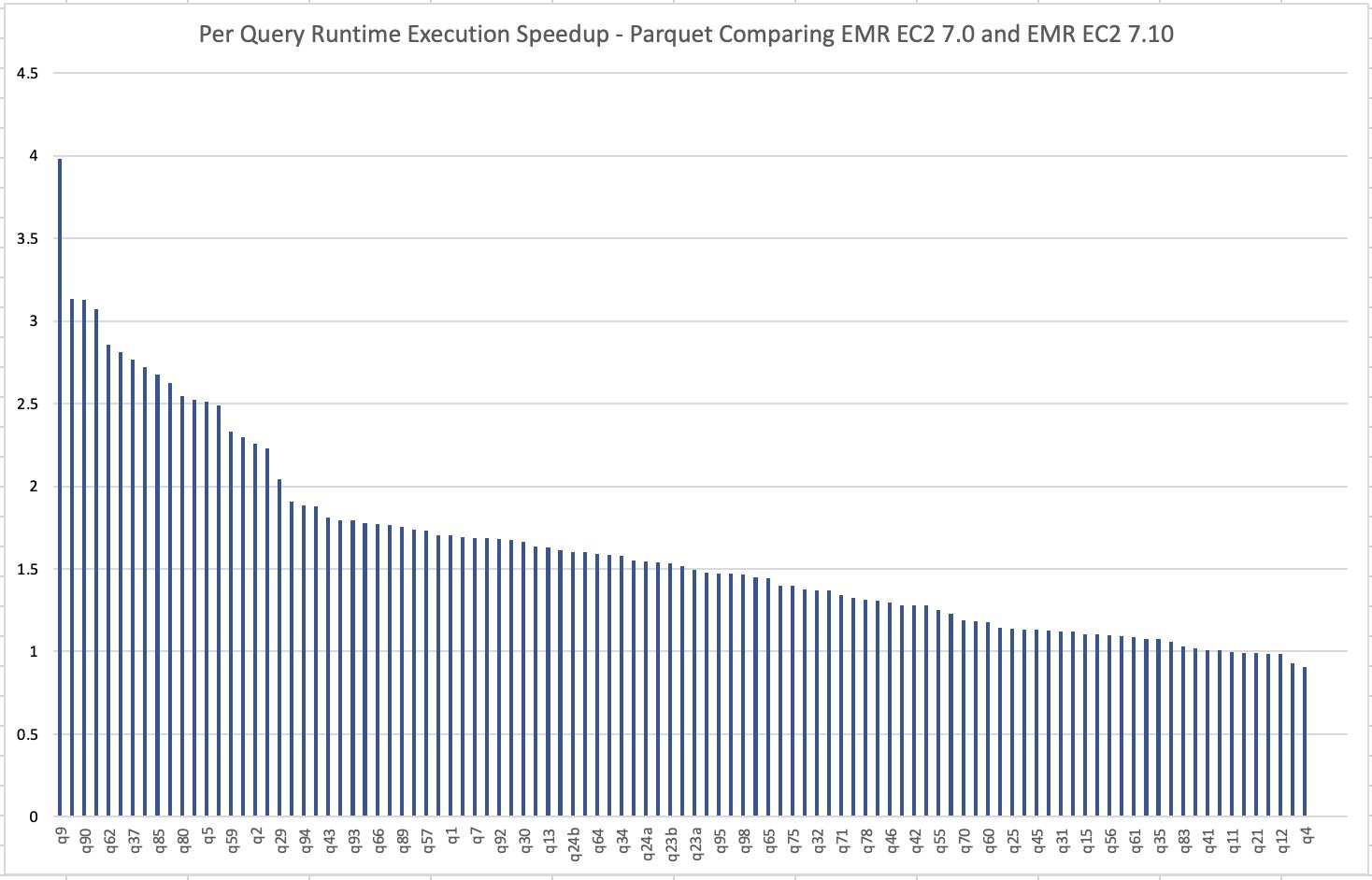
The beneath picture illustrates the per-query speedup on Amazon EMR 7.10 when in comparison with Amazon EMR 7.0 for Parquet information.
Learn price comparability
Our benchmark outputs the whole runtime and geometric imply figures to measure the Hive runtime efficiency by simulating a real-world complicated choice help use case. The fee metric can present us with extra insights. Price estimates are computed utilizing the next formulation. They think about Amazon EC2, Amazon Elastic Block Retailer (Amazon EBS), and Amazon EMR prices, however don’t embrace Amazon S3 GET and PUT prices.
- Amazon EC2 price (together with SSD price) = variety of cases * m5.8xlarge hourly charge * job runtime in hours
- 8xlarge hourly charge = $1.536 per hour
- Root Amazon EBS price = variety of cases * Amazon EBS per GB-hourly charge * root EBS quantity dimension * job runtime in hours
- Amazon EMR price = variety of cases * m5.8xlarge Amazon EMR price * job runtime in hours
- 8xlarge Amazon EMR price = $0.27 per hour
- Complete price = Amazon EC2 price + root Amazon EBS price + Amazon EMR price
Primarily based on the calculation, the Amazon EMR 7.10 benchmark end result demonstrates a 33% enchancment in job price in comparison with Amazon EMR 7.0.
| Metric | Amazon EMR 7.0.0 | Amazon EMR 7.10.0 |
| Runtime in hours | 2.86 | |
| Variety of EC2 cases | 17 | 17 |
| Amazon EBS Dimension | 20gb | 20gb |
| Amazon EC2 price | $78.34 | $52.22 |
| Amazon EBS price | $0.01 | $0.01 |
| Amazon EMR price | $14.58 | $9.72 |
| Complete price | $92.93 | $61.96 |
| Price Financial savings | Baseline | Amazon EMR 7.10.0 is 33% higher than Amazon EMR 7.0.0 |
Hive write committers efficiency comparability
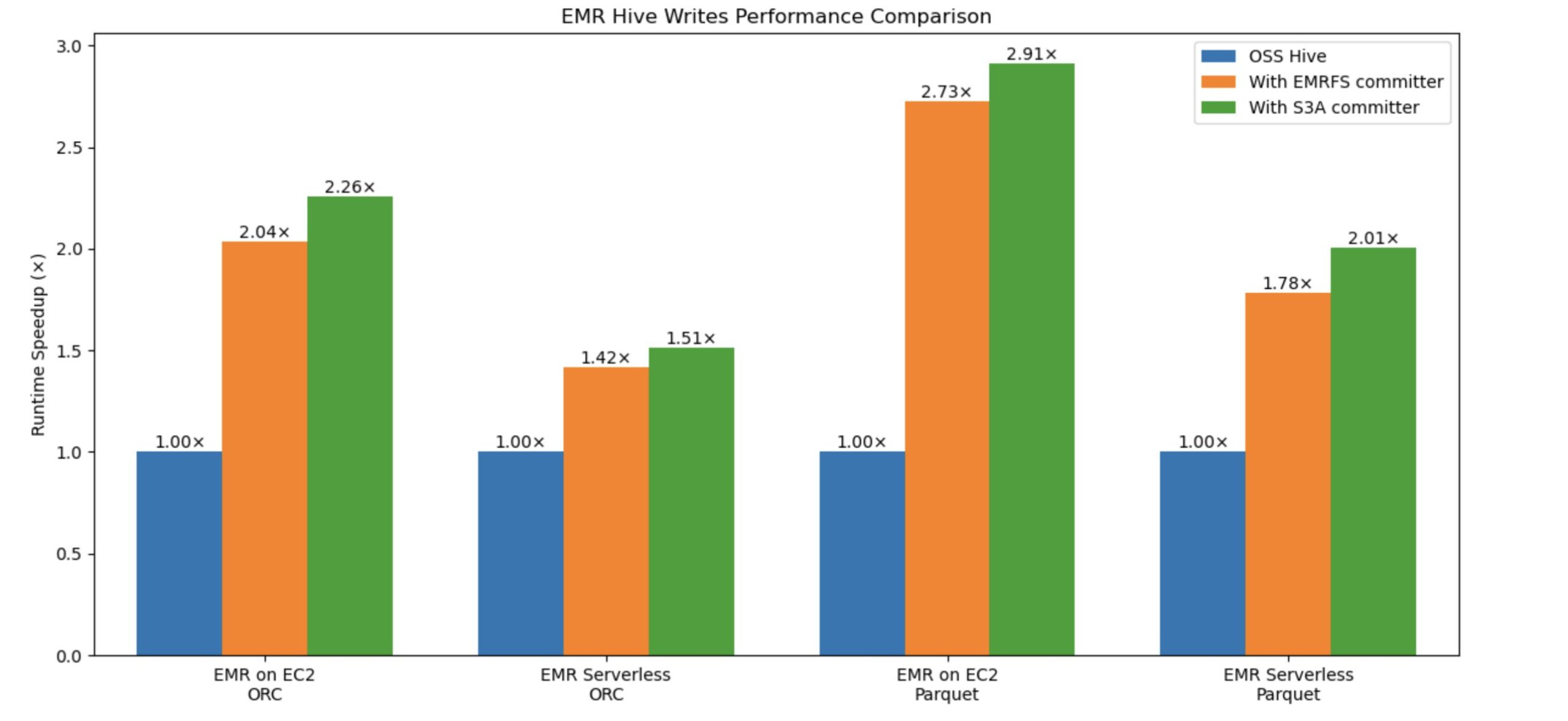
Amazon EMR launched a brand new committer to boost Hive write efficiency on Amazon S3 as much as 2.91 instances sooner. The present Hive EMRFS S3-optimized committer, eliminates rename operations by writing knowledge on to the output location and solely commits information at job completion to assist implement failure resilience. It implements a modified file naming conference that features a question ID suffix. The brand new, Hive S3A-optimized committer, was developed to carry comparable zero-rename capabilities to Hive on S3A, which beforehand lacked this characteristic. Constructed on OSS Hadoop’s Magic Committer, it eliminates pointless file actions throughout commit phases utilizing S3 multipart add (MPU) operations. This newer committer not solely matches however exceeds EMRFS efficiency, delivering sooner Hive write question execution whereas lowering S3 API calls, leading to improved effectivity and price financial savings for patrons. Each committers successfully tackle the efficiency bottleneck attributable to rename operations in Hive, with the S3A-optimized committer rising because the superior resolution.
Constructing on our earlier weblog put up in regards to the Amazon EMR Hive Zero Rename characteristic features 15-fold write efficiency with EMRFS-optimized committer, we’ve achieved extra efficiency enhancements in Hive write operations utilizing the S3A optimized committer. We ran the comparability exams with and with out the brand new committer and evaluated the write efficiency enchancment. The benchmark used an insert overwrite question that joins two tables from a 3 TB TPC-DS ORC and Parquet dataset.
The next graph compares Hive write question whole runtime speedup in opposition to ORC and Parquet codecs. The y-axis denotes the speedup (whole time taken with rename / whole time taken by question with committer), and the x-axis denotes file codecs and EMR deployment fashions. With the brand new S3A committer, the runtime speedup is healthier.
Understanding efficiency impression with totally different knowledge sizes and variety of information
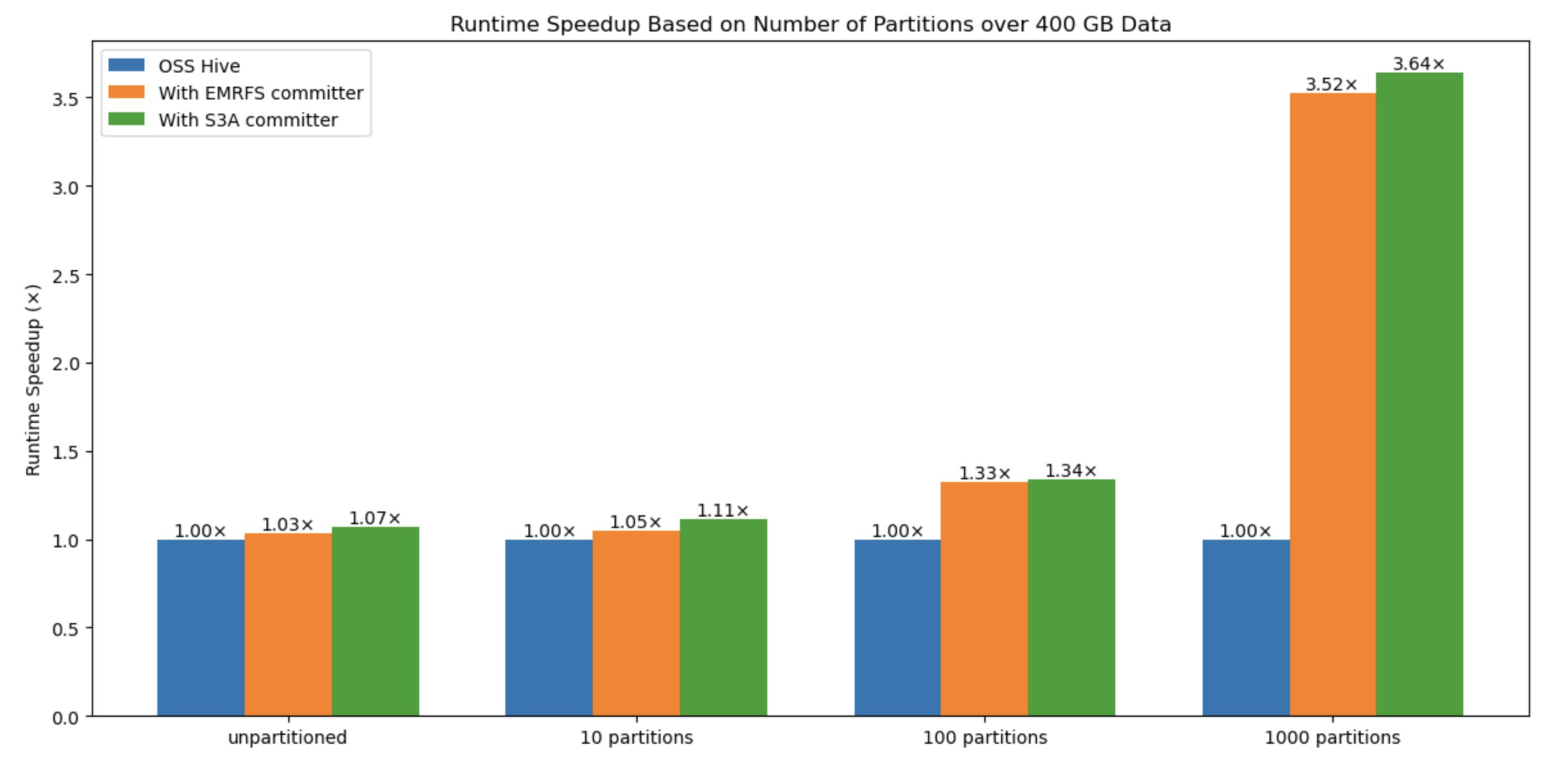
To benchmark the efficiency impression with variable knowledge sizes and variety of information, we additionally evaluated the answer with numerous varieties, similar to dimension of knowledge (10 information –unpartitioned, 10 partitions, 100 partitions, 1000 partitions), variety of information, and variety of partitions: The outcomes present that the variety of information written is the crucial issue for efficiency enchancment when utilizing this new committer compared to the default Hive commit logic and EMRFS committer.
Within the following graph, the y-axis denotes the runtime speedup (whole time taken with rename / whole time taken by question with committer), and the x-axis denotes the variety of partitions. We noticed that because the variety of partitions will increase, the committer performs higher due to avoiding a number of costly rename operations in Amazon S3.
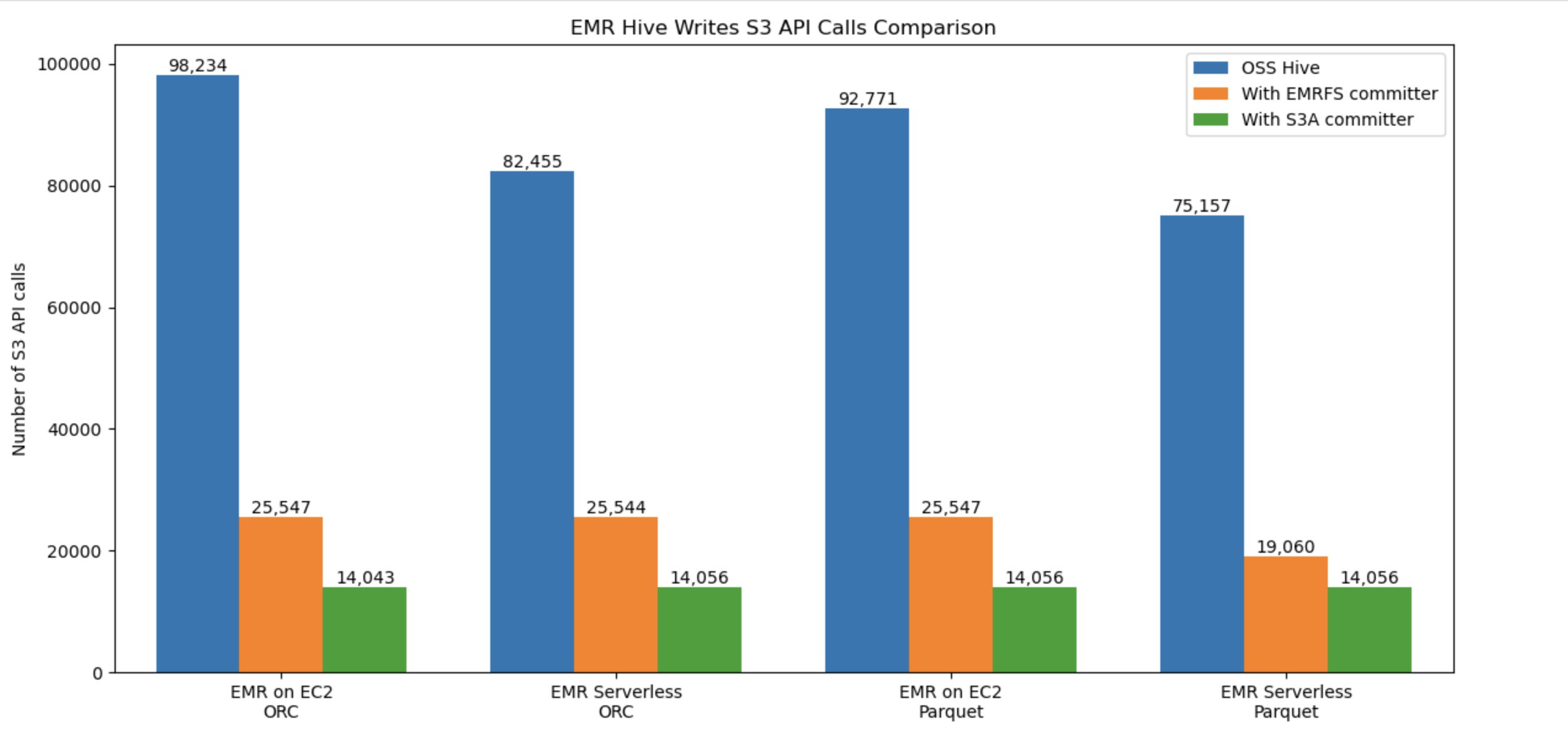
Write price comparability
The next graph compares the variety of general Amazon S3 API requires Hive write workflow in opposition to ORC and Parquet codecs. The benchmark used an insert overwrite question that joins two tables from a 3 TB TPC-DS ORC, Parquet datasets on each Amazon EMR EC2 and Amazon EMR Serverless. With the brand new committer, the S3 utilization price is healthier(decrease).
Limitations with Hive S3A zero-rename characteristic
This committer won’t be used, and default Hive commit logic will likely be utilized within the following situations:
- When merge small information (
hive.merge.tezfiles) is enabled. - When utilizing Hive ACID tables.
- When partitions are distributed throughout file methods similar to HDFS and Amazon S3.
Abstract
Amazon EMR continues to enhance the Amazon EMR runtime for Apache Hive, resulting in a efficiency enchancment year-over-year and extra options for large knowledge clients to run their analytics workload in price efficient method. Extra importantly, the transition to S3A brings extra advantages similar to improved standardization, higher portability, and stronger neighborhood help, whereas sustaining the sturdy efficiency ranges established by EMRFS. We suggest that you simply keep updated with the most recent Amazon EMR launch to make the most of the most recent efficiency and have advantages.
To maintain updated, subscribe to the Large Information Weblog RSS feed to study extra about Amazon EMR runtime for Apache Hive, configuration finest practices, and tuning recommendation.
Concerning the authors

{kind=link}