
Constructing a RAG system simply bought a lot simpler. Google has launched File Search, a managed RAG function for the Gemini API that handles the heavy lifting of connecting LLMs to your knowledge. Overlook managing chunking, embeddings, or vector databases: File Search does all of it. This lets you skip the infrastructure complications and give attention to what issues: creating an incredible software. On this information, we’ll discover how File Search works and stroll via its implementation with sensible Python examples.
What File Search Does?
File Search allows Gemini to understand and reference data from proprietary knowledge sources like experiences, paperwork, and code recordsdata.
When a file is uploaded, the system separates the content material into smaller items, referred to as chunks. It then creates an embedding, a numeric illustration of that means for every chunk and saves them in a File Search Retailer.
When a consumer asks a query, Gemini searches via these saved embeddings to seek out and pull probably the most related sections for context. This course of permits Gemini to ship correct responses based mostly in your particular data, which is a core element of RAG.
Additionally Learn: Constructing an LLM Mannequin utilizing Google Gemini API
How File Search Works?
File Search is powered by semantic vector search. As a substitute of matching on phrases instantly, it should discover data based mostly on that means and context. Which means File Search can discover you related data even when the wording of the question is completely different.
Time wanted: 4 minutes
Right here’s the way it works step-by-step:
- Add a file
The file will probably be damaged up into smaller sections known as “chunks.”
- Embedding era
Every chunk can be remodeled right into a numerical vector that represents the that means of that chunk.
- Storage
The embeddings will probably be saved in a File Search Retailer, an embedded retailer designed particularly for retrieval.
- Question
When a consumer poses a query, File Search will remodel that query into an embedding.
- Retrieval
The retrieval step will evaluate the query embedding with the saved embeddings and discover which chunks are most related (if any).
- Grounding
Related chunks are added to the immediate to the Gemini mannequin in order that the reply is grounded within the factual knowledge from the paperwork.
This whole course of is dealt with underneath the Gemini API. The developer doesn’t should handle any extra infrastructure or databases.
Setup Necessities
To make the most of the File Search Software, builders will want just a few elementary elements. They might want to have Python 3.9 or newer, the google-genai shopper library, and a sound Gemini API key that has entry to both gemini-2.5-pro or gemini-2.5-flash.
Set up the shopper library by operating:
pip set up google-genai -U Then, set your setting variable for the API key:
export GOOGLE_API_KEY="your_api_key_here"Making a File Search Retailer
A File Search Retailer is the place Gemini saves and indexes embeddings created out of your uploaded recordsdata. The embeddings encapsulate the that means of your textual content, and so they proceed to be saved to the shop while you delete the unique file.
from google import genai from google.genai import varieties
shopper = genai.Consumer()
retailer = shopper.file_search_stores.create( config={'display_name': 'my_rag_store'} ) print("File Search Retailer created:", retailer.identify)
Every undertaking can have a complete of 10 shops, with the bottom tier having retailer limits of 1 GB, and better tier limits of 1 TB.
The shop is a persistent object your listed retain knowledge in.
Add a File
After the shop is loaded, you possibly can add a file. When a file is uploaded, the File Search Software will robotically chunk the file, generate embeddings and index for a quick retrieval course of.
# Add and import a file into the file search retailer, provide a singular file identify which will probably be seen in citations
operation = shopper.file_search_stores.upload_to_file_search_store(
file="/content material/Paper2Agent.pdf",
file_search_store_name=file_search_store.identify,
config={
'display_name' : 'my_rag_store',
}
)
# Wait till import is full
whereas not operation.achieved:
time.sleep(5)
operation = shopper.operations.get(operation)
print("File efficiently uploaded and listed.")
File Search helps PDF, DOCX, TXT, JSON, and programming recordsdata extending to .py and .js.
After the add step, your file is chunked, embedded, and prepared for retrieval.
Ask Questions Concerning the File
As soon as listed, Gemini can reply to inquiries based mostly in your doc. It finds the related sections from the File Search Retailer and makes use of these sections as context for the reply.
# Ask a query in regards to the file
response = shopper.fashions.generate_content(
mannequin="gemini-2.5-flash",
contents="""Summarize what's there within the analysis paper""",
config=varieties.GenerateContentConfig(
instruments=[
types.Tool(file_search=types.FileSearch(
file_search_store_names=[file_search_store.name]
))
]
)
)
print("Mannequin Response:n")
print(response.textual content)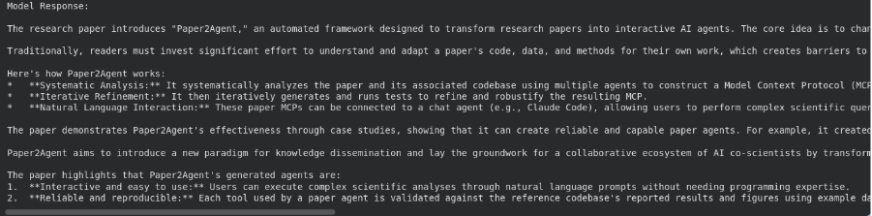
Right here, File Search is being utilized as a software inside generate_content(). The mannequin first searches your saved embeddings, pulls probably the most related sections, after which generates a solution based mostly on that context.
Customise Chunking
By default, File Search decides the best way to break up recordsdata into chunks, however you possibly can management this conduct for higher search precision.
operation = shopper.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.identify,
file="path/to/your/file.txt",
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
) This configuration units every chunk to 200 tokens with 20 overlapping tokens for smoother context continuity. Shorter chunks give finer search outcomes, whereas bigger ones retain extra general that means helpful for analysis papers and code recordsdata.
Handle Your File Search Shops
You may simply listing, view, and delete file search shops utilizing the API.
print("n Obtainable File Search Shops:")
for s in shopper.file_search_stores.listing():
print(" -", s.identify)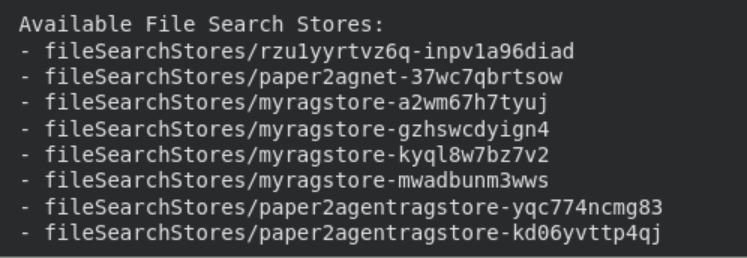
# Get detailed data
particulars = shopper.file_search_stores.get(identify=file_search_store.identify)
print("n Retailer Particulars:n", particulars
# Delete the shop (non-obligatory cleanup)
shopper.file_search_stores.delete(identify=file_search_store.identify, config={'pressure': True})
print("File Search Retailer deleted.")
These administration choices assist hold your setting organized. Listed knowledge stays saved till manually deleted, whereas recordsdata uploaded via the momentary Information API are robotically eliminated after 48 hours.
Additionally Learn: 12 Issues You Can Do with the Free Gemini API
Pricing and Limits
The File Search Software is meant to be easy and inexpensive for each developer. Every uploaded file may be as massive as 100 MB, and you may make as much as 10 file search shops per undertaking. The free tier permits for 1 GB of complete storage in file search shops, whereas the upper tiers enable for 10 GB, 100 GB, and 1 TB for Tier 1, Tier 2, and Tier 3, respectfully.
Indexing embeddings prices $0.15 per a million tokens processed, however each storage embeddings and embedding queries that index knowledge at run-time are free. Retrieved doc tokens are billed as common context tokens if utilized in era. Storage makes use of roughly 3 occasions your file measurement, for the reason that embeddings are taking on further area.
The File Search Software was constructed for low-latency response occasions, and it’ll get again queries fast and reliably even when you’ve got a big set of paperwork. This can guarantee a clean responsive expertise to your retrievals and generative duties.
Supported Fashions
File Search is on the market on each the Gemini 2.5 Professional and Gemini 2.5 Flash fashions. Each assist grounding, metadata filtering, and citations. This implies it might level to the exact sections of the paperwork utilized to formulate solutions, including accuracy and verification to responses.
Additionally Learn: The best way to Entry and Use the Gemini API?
Conclusion
The Gemini File Search Software is designed to make RAG simpler for everybody. It takes care of the sophisticated points, corresponding to chunking, embedding, and looking instantly inside the Gemini API. Builders don’t should create retrieval pipelines by themselves or work with an exterior database. After you will have uploaded a file, every thing is completed robotically.
With free storage, built-in citations, and fast response occasions, File Search helps you create grounded, reliable, and data-aware AI programs. It alleviates builders from anxious and meticulous constructing to save lots of time whereas retaining agency management, accuracy, and integrity.
You may start establishing File Search now at Google AI Studio, or from the Gemini API. It’s a very easy, fast, and protected technique to construct robustly clever purposes that make the most of precise knowledge responsibly.
Hello, I’m Janvi, a passionate knowledge science fanatic presently working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we are able to extract significant insights from complicated datasets.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}