
AI improvement has develop into a race of extra. Extra parameters, extra compute, extra GPUs. It’s an try to extend intelligence by including extra brains (as an alternative of creating one). Each new launch flaunts measurement quite than substance. However the newer fashions have confirmed one factor: actual progress isn’t nearly how huge you’ll be able to go. It’s about how neatly you should utilize what you’ve obtained.
Builders, particularly, really feel this stress day by day. They don’t want one other trillion-parameter showpiece that prices a small fortune to run. They want one thing sensible like an assistant that may assist debug messy code, refactor throughout a number of information, and keep context-aware with out draining assets.
That’s the place MiniMax M2 steps in.
What’s MiniMax M2?

MiniMax M2 is a big language mannequin constructed by MiniMax AI, designed to carry out at near-frontier ranges of LLMs whereas working effectively. On paper, it’s a 230-billion-parameter mannequin, however in observe, it solely prompts about 10 billion of these parameters for any given process. This performance is just like the one supplied by Qwen3-Subsequent.
Consider it as a high-performance engine that fires solely the cylinders it wants. That selective activation is its core innovation: it lets M2 ship the intelligence of a large mannequin at a fraction of the price and velocity penalty.
M2 focuses on two domains that occupy most of a developer’s time:
- Coding: Writing, enhancing, refactoring, and debugging throughout actual, multi-file tasks.
- Agentic workflows: Tasks that require multi-step planning, reasoning, and execution.
Let’s see how nicely the mannequin fares when put to check within the aforementioned duties.
Palms-On: Does It Truly Ship?
Right here’s the litmus check for any coding mannequin: can it carry out nicely in real-world situations?
I used to be capable of check the MiniMax M2 mannequin without spending a dime at Openrouter.ai. You can too entry the mannequin at MiniMax’s official web page.
Primary Math
This seemingly easy drawback has troubled LLMs for the longest time.
Immediate: “9.11 and 9.9, which one is bigger?”
Output:
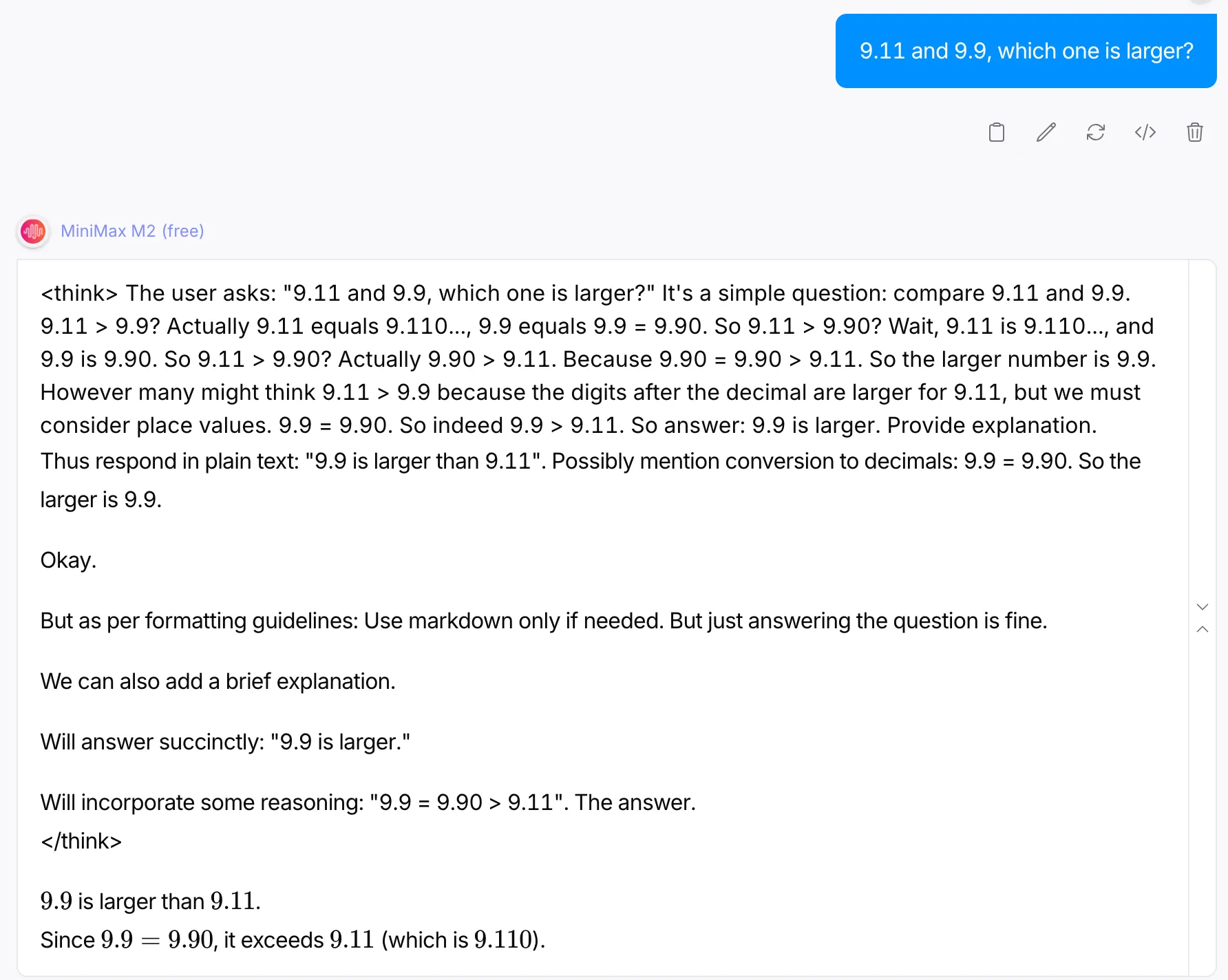
The considering traceback of the mannequin alone justifies why this was a worthy query. The mannequin started by the faulty assumption of 9.11 being higher than 9.9. However later, makes up for this error and gives a succinct clarification for it. It’d sound a bit shocking, however a variety of fashions up to now fail at answering the above query appropriately.
Creativity
What about some light-hearted jokes?
Immediate: “Inform me a couple of joke on Espresso“
Output:
In my earlier article on Verbalized Prompting, I spotted a typical drawback with LLMs, when required to supply content material on the identical theme, They produced redundant outputs. However MiniMax M2 was capable of not solely understand that the identical request had been made however was ready to reply to it in a distinguishable method. That is one thing that a variety of the famend fashions fail at.
Programming
Getting the mannequin to supply the “101 code” in 3 completely different languages.
Immediate: “Give me ‘Good day World’ code in 3 programming languages: Python, Java, C.”
Output:
The three code snippets supplied had been passable and ran with none errors. The codes had been temporary (as they need to be for a easy program) and had been straightforward to observe.
How It Works: Selective Parameter Activation
Right here’s the place MiniMax M2 will get intelligent. As an alternative of working its whole parameter set on each request, it prompts solely the subset of the parameter set, that are essentially the most related to the duty at hand, accounting for only a fraction of the full parameter depend.
This selective activation does two huge issues:
- Improves velocity: Much less computation means quicker inference occasions.
- Cuts price: You’re not paying to gentle up a large mannequin for each small process.
It’s a design alternative that mirrors how people work. You don’t take into consideration all the things you already know abruptly. By accessing the psychological blocks that retailer the related data, we streamline our thought course of. M2 does the identical.
Past Code: The Agentic Benefit
M2’s actual edge exhibits up in multi-step reasoning. Most fashions can execute one instruction nicely however stumble after they should plan, analysis, and adapt over a number of steps. Ask M2 to analysis an idea, synthesize findings, and produce a technical answer, and it doesn’t lose the thread. It plans, executes, and corrects itself, dealing with what AI researchers name agentic workflows.
Efficiency and Effectivity
All the idea on the earth means nothing if a mannequin can’t sustain with actual customers. M2 is quick, not “quick for a big mannequin,” however genuinely responsive.
As a result of it prompts fewer parameters per request, its inference occasions are brief sufficient for interactive use. That makes it viable for functions like reside coding assistants or workflow automation instruments the place responsiveness is essential.
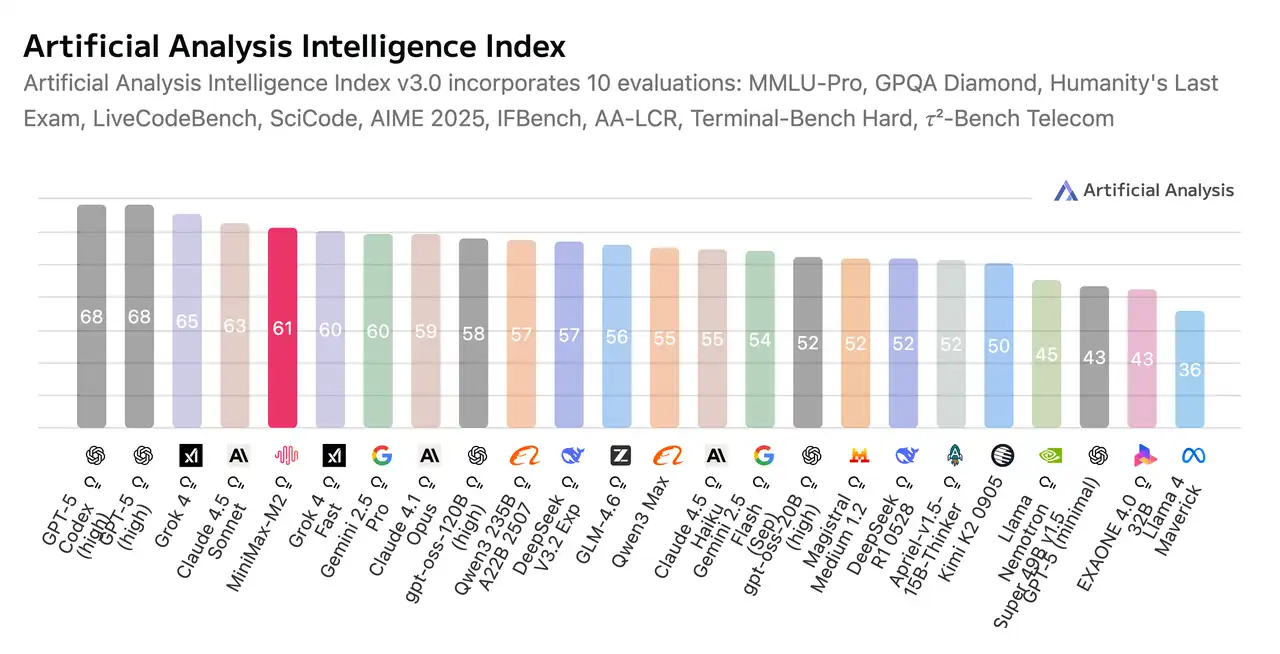
On the price aspect, the mathematics is simply as engaging. Fewer lively parameters imply decrease power and infrastructure prices, which makes large-scale deployment make sense. For enterprises, that’s a direct discount in working prices; for startups, it’s the distinction between experimenting freely and rationing API calls.
Which means for builders, no extra feeding the mannequin the identical context repeatedly. For groups, it means consistency: the mannequin remembers choices, naming conventions, and architectural logic throughout classes.
| Class | MiniMax-M2 | In comparison with Common | Notes |
|---|---|---|---|
| Intelligence | Synthetic Evaluation Intelligence Index: 61 | Greater | Signifies higher reasoning or output high quality. |
| Worth | $0.53 per 1M tokens (blended 3:1) Enter: $0.30 Output: $1.20 |
Cheaper | Robust price effectivity for large-scale use. |
| Pace | 84.8 tokens/sec | Slower | Might have an effect on real-time or streaming duties. |
| Latency (TTFT) | 1.13 seconds | Decrease (quicker first token) | Higher for interactive responses. |
| Context Window | 200k tokens | Smaller | Limits multi-document or long-context use circumstances. |
The Takeaway
We’ve seen what MiniMax M2 is, the way it works, and why it’s completely different. It’s a mannequin that thinks like a developer, plans like an agent, and scales like a enterprise device. Its selective activation structure challenges the business’s “extra is best” mindset, exhibiting that the way forward for AI won’t depend upon including parameters however on optimizing them.
For builders, it’s a coding companion that understands codebases. For groups, it’s an economical basis for AI-powered merchandise. And for the business at massive, it’s a touch that the following wave of breakthroughs received’t come from bigness, however from precision and clever design.
Learn extra: Minimax M1
Incessantly Requested Questions
A. It makes use of selective parameter activation, solely 10B of its 230B parameters run per process, providing excessive efficiency with decrease price and latency.
A. Exceptionally nicely. It understands multi-file dependencies, performs compile–run–repair loops, and achieves robust outcomes on benchmarks like SWE-Bench Verified.
A. Sure. Its effectivity, velocity, and stability make it appropriate for production-scale deployment throughout each startup and enterprise environments.
I specialise in reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}