
Yesterday DeepSeek neighborhood launched its newest and most superior text-2-visual modal often known as: Deepseek-OCR and it’s altering the best way we used to extract textual content from pictures. Until now we’re depending on the standard OCR fashions that battle with accuracy and format understanding whereas extracting textual content from PDF’s, pictures or messy hand written notes.
However, DeepSeek-OCR utterly modifications the story.
It expertly reads, understands and converts visible textual content to digital textual content with extraordinary precision. DeepSeek-OCR isn’t simply one other OCR software, it’s an clever visible textual content system constructed on the highest of DeepSeek‑VL2 Imaginative and prescient-Language Mannequin(VLM) identified for its pace and accuracy. It will probably simply establish visible textual content, in a number of languages, by its superior imaginative and prescient algorithms even in handwritten format. On this article, we’re going to take a look at DeepSeek-OCR’s structure, and check out its capabilities on a couple of pictures of the textual content.
What’s DeepSeek OCR?
DeepSeek-OCR is a multimodal system that compresses textual content by translating it to a visible illustration. It additionally works on the encoder and decoder type structure. First, it encodes entire paperwork in picture kind and makes use of a vision-language mannequin to recuperate the textual content. In observe, this implies a web page of textual content often with hundreds of tokens finally ends up represented by just a few hundred imaginative and prescient tokens. And DeepSeek calls this strategy context optical compression.
Context Optical Compression
Right here after extracting the textual content out of the picture by way of the encoder. DeepSeek doesn’t ship all of the phrases into the mannequin however merely exhibits the textual content as a picture. For instance, for a web page the picture may solely want 200-400 tokens whereas for the web page filled with textual content may want 2000-5000 textual content tokens.
Imaginative and prescient tokens can seize all the important data comparable to format, spacing, phrase shapes rather more densely. The imaginative and prescient encoder learns to compress the picture in order that the decoder could reconstruct the unique textual content, which implies: every visible token can encode data equal to many textual content tokens.
Imaginative and prescient-Language OCR Mannequin
As, the imaginative and prescient token simply captures the format and phrase shapes due to this fact, collectively, they kind an end-to-end image-to-text pipeline for vision-language fashions just like imaginative and prescient transformers basically. Nevertheless, as a result of the imaginative and prescient tokens seize data extra densely, we’re in a position to scale back the tokens wanted general and maximize the mannequin’s consideration to the visible construction of the textual content.
DeepSeek OCR Structure
DeepSeek-OCR follows a two-stage encoder-decoder structure that works as follows: the DeepEncoder (≈380M parameters) encodes the picture to supply imaginative and prescient tokens, and the DeepSeek-3B-MoE (≈570M energetic parameters) expands the tokens again out to textual content.
DeepEncoder (Imaginative and prescient Encoder)
The DeepEncoder consists of two imaginative and prescient transformers linked in collection. The primary is a SAM-base block which has 80M params, and makes use of windowed consideration to encode native element. The second is a CLIP-large block with 300M params, and makes use of international consideration to encode the general format.
In between the 2 imaginative and prescient transformers, there’s a convolutions block that reduces the variety of imaginative and prescient tokens from 16× by an element of 16. For instance, a 1024×1024 picture is parsed into 4096 patches, after which decreased to solely 256 tokens.
- SAM-base (80M): Makes use of windowed self-attention to scan advantageous picture particulars.
- CLIP-large (300M): Applies dense consideration to encode international context.
- 16× convolution: Reduces the depend of imaginative and prescient tokens from the preliminary patch depend (e.g. 4096→256 for 1024²).
DeepSeek-3B-MoE Decoder
The decoder module is a language transformer with a Combination-of-Specialists structure. The mannequin has 64 specialists, though solely 6 are energetic per token(on common), and is used to develop imaginative and prescient tokens again to textual content. The small decoder was skilled on wealthy doc information as an OCR-style activity like textual content, math equations, charts, chemical diagrams, and mixed-languages. So it’d develop a normal vary of fabric in every token.
- Combination-of-Specialists: 64 whole specialists, six energetic specialists every step
- Imaginative and prescient-to-text coaching: skilled on OCR-style information from normal paperwork,preserving the format setting from a various vary of textual sources.
Multi-Decision Enter Modes
DeepSeek-OCR is designed with help for a number of enter resolutions, permitting the consumer to decide on a stability of particulars versus compression. It presents 4 native modes, together with a particular Gundam (tiling) mode:
| Mode | Decision | Approx. Imaginative and prescient Tokens | Description |
| Tiny | 512×512 | ~64 | Extremely-lightweight mode for fast scans and easy paperwork |
| Small | 640×640 | ~100 | Balanced mode with good speed-accuracy tradeoff; default mode |
| Base | 1024×1024 | ~256 | Excessive-quality OCR for detailed doc evaluation |
| Massive | 1280×1280 | ~400 | Excessive-precision mode for advanced paperwork with dense layouts |
| Gundam (Dynamic) | A number of tiles: n×640×640 + 1×1024×1024 | Variable, usually n×100 + 256 tokens | Dynamic decision that splits very high-res pages into a number of tiles for very advanced paperwork |
This flexibility permits DeepSeek to compress in a separate method, relying on the complexity of the web page.
How one can Entry DeepSeek OCR?
Putting in the mandatory libraries
!pip set up torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://obtain.pytorch.org/whl/cu118
!pip set up flash-attn
!pip set up transformers==4.46.3
!pip set up speed up==1.1.1
!pip set up safetensors==0.4.5
!pip set up addictAfter putting in these, transfer to step 2.
Loading the mannequin
from transformers import AutoModel, AutoTokenizer
import torch
model_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
mannequin = AutoModel.from_pretrained(model_name, trust_remote_code=True, use_safetensors=True)
mannequin = mannequin.eval().cuda().to(torch.bfloat16)Let’s Strive DeepSeek OCR
Now that we all know entry DeepSeek OCR, we can be testing it out for two examples:
Primary Doc Conversion
This instance processes a PNG doc picture, extracts all textual content content material utilizing DeepSeek’s imaginative and prescient tokens, and converts it into clear markdown format whereas testing the compression capabilities of the mannequin.
immediate = "nConvert the doc to markdown. "
image_file="/content material/img_1.png"
output_path="/content material/out_1"
res = mannequin.infer(tokenizer, immediate=immediate, image_file=image_file,
output_path=output_path, base_size=1024, image_size=640,
crop_mode=True, save_results=True, test_compress=True) This may load the DeepSeek-OCR on the GPU. Within the offered instance immediate, it’s instructed to transform the doc to Markdown. In output_path, we’ll save the acknowledged textual content after working infer().
Enter picture:
Response from DeepSeek OCR:
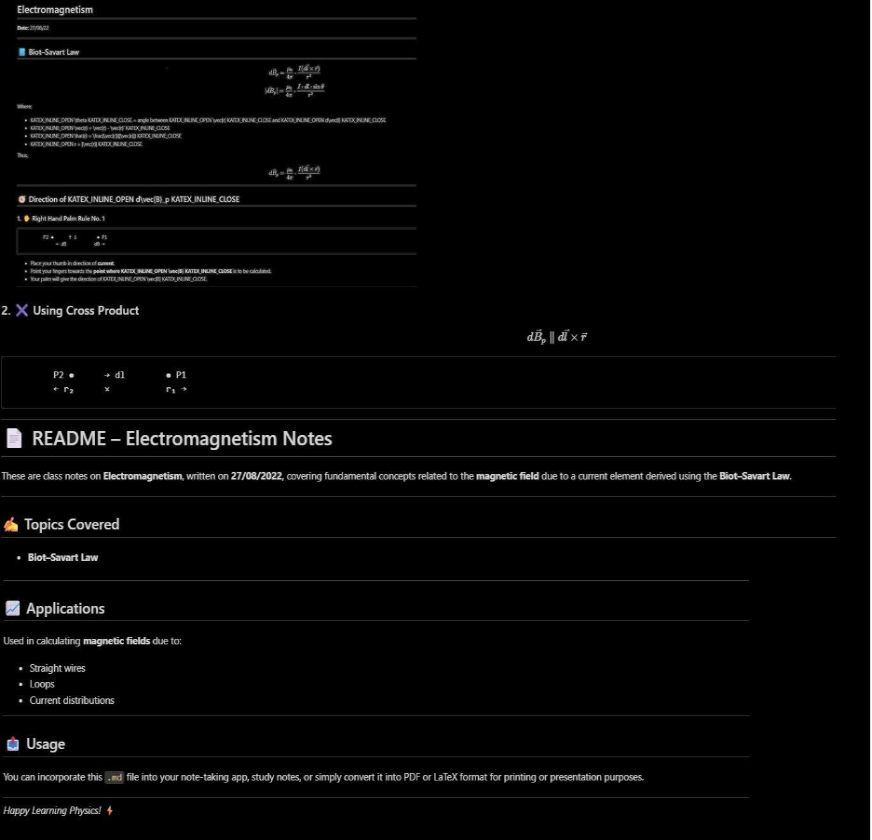
Complicated Doc Processing
This demonstrates processing a extra advanced JPG doc, sustaining formatting and format construction whereas changing to markdown, showcasing the mannequin’s means to deal with difficult visible textual content situations.
immediate = "nConvert the doc to markdown. "
image_file="/content material/img_2.jpg"
output_path="/content material/out_2"
res = mannequin.infer(tokenizer, immediate=immediate, image_file=image_file,
output_path=output_path, base_size=1024, image_size=640,
crop_mode=True, save_results=True, test_compress=True) Enter Picture:
Response from DeepSeek OCR:
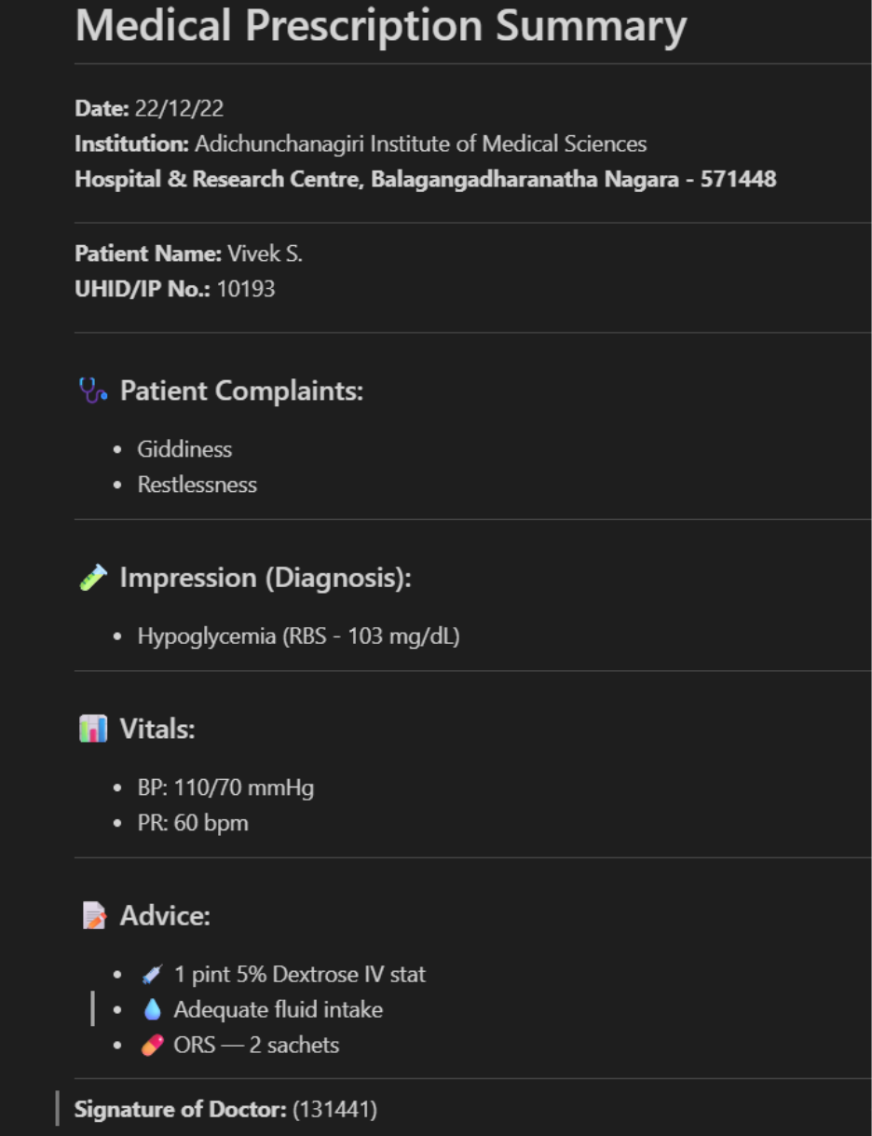
We will use small/medium/giant base_size/image_size to supply Tiny, Small, Base, or Massive modes for various efficiency outputs.
Refreshing the Cache
Now as soon as all of the libraries has been put in and you’ve got run the above code blocks and encountered any error then run the under command and restart the kernel if you’re utilizing a jupyter pocket book or collab. This command will delete all the information and the pre-existing variables within the cache.
!rm -rf ~/.cache/huggingface/modules/transformers_modules/deepseek-ai/DeepSeek-OCR/ Word: {Hardware} Setup Necessities: CUDA GPU with ~16–30GB VRAM (e.g. A100) for big pictures. For the whole code, go to right here.
Efficiency and Benchmarks
DeepSeek-OCR achieves excellent charges of compression and OCR accuracy, as illustrated within the determine under. The comparisons captured within the benchmarks replicate the extent to which the mannequin encodes visible tokens with out dropping accuracy.
Compression on Fox Benchmark
DeepSeek-OCR demonstrates good textual content retention, even at elevated ranges of compression. It achieves > 96% accuracy at 10× compression with solely 64–100 imaginative and prescient tokens per web page, and it sustains ~ 85–87% additional at 15–20× compression. This exhibits the mannequin’s means to encode a substantial amount of textual content effectivity, which presents giant language fashions alternatives to course of longer paperwork with restricted token utilization.
| Imaginative and prescient Tokens | Precision (%) | Compression (×) |
| 64 Tokens | 96.5% | 10× |
| 64 Tokens | 85.8% | 15× |
| 100 Tokens | 97.3% | 10× |
| 100 Tokens | 87.1% | 20× |
Efficiency on OmniDocBench
On the OmniDocBench, the efficiency of DeepSeek-OCR surpasses the main OCR fashions and imaginative and prescient language fashions, attaining Edit Distance (ED)
| Mannequin | Avg. Imaginative and prescient Tokens/Picture | Edit Distance (higher) | Accuracy Area | Comment |
| DeepSeek-OCR (Gundam-M 200dpi) | Excessive Accuracy | Greatest stability of precision & effectivity | ||
| DeepSeek-OCR (Base/Massive) | Excessive Accuracy | Constantly top-performing | ||
| GOT-OCR2.0 | >1500 | >0.35 | Reasonable | Requires extra tokens |
| Qwen2.5-VL / InternVL3 | >1500 | >0.30 | Reasonable | Much less environment friendly |
| SmolDocling | >0.45 | Low Accuracy | Compact however weak OCR high quality |
Additionally Learn: How one can Use Mistral OCR for Your Subsequent RAG Mannequin
Conclusion
Deepseek-OCR units a brand new and revolutionary strategy to studying textual content. It considerably reduces the token utilization of textual content (usually 7-20X decrease) through the use of imaginative and prescient as a compression layer whereas nonetheless retaining a lot of the data. The mannequin is open-source and obtainable for any builders to play with it.
This might be large for AI which is the flexibility to signify textual content in a compact, environment friendly method. As a lot of the OCR’s fail whereas coping with hand written textual content specifically on a medical receipt. However the DeepSeek-OCR excels at that as effectively. Its message goes past OCR and factors to new potentialities in AI reminiscence and context administration.
So comply with the above steps and provides it a strive!
Hiya! I am Vipin, a passionate information science and machine studying fanatic with a powerful basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My aim is to use data-driven insights to create sensible options that drive outcomes. I am desperate to contribute my abilities in a collaborative atmosphere whereas persevering with to be taught and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}