 Brings 32B LLM Coaching to a Single H100—Whereas Bettering Exploration")
What would you construct in the event you may run Reinforcement Studying (RL) post-training on a 32B LLM in 4-bit NVFP4—on a single H100—with BF16-level accuracy and 1.2–1.5× step speedups? NVIDIA researchers (with collaborators from MIT, HKU, and Tsinghua) have open-sourced QeRL (Quantization-enhanced Reinforcement Studying), a coaching framework that pushes Reinforcement Studying (RL) post-training into 4-bit FP4 (NVFP4) whereas retaining gradient math in larger precision through LoRA. The analysis group reviews >1.5× speedups within the rollout section, ~1.8× end-to-end vs QLoRA in a single setting, and the first demonstration of RL coaching for a 32B coverage on a single H100-80GB GPU.
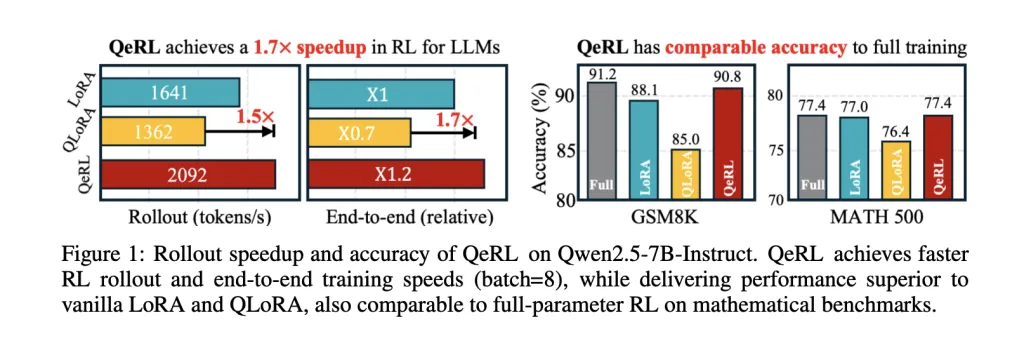
What QeRL modifications within the Reinforcement Studying (RL) loop?
Most RLHF/GRPO/DAPO pipelines spend the majority of wall-clock time in rollouts (token era). QeRL shifts the coverage’s weight path to NVFP4 (FP4) with dual-level scaling and retains logits/gradients in larger precision through LoRA, so backprop stays steady whereas the sampling path hits hardware-efficient FP4×BF16 kernels (Marlin). The result’s sooner prefill/decoding throughout rollouts with out sustaining a separate full-precision coverage.
Mechanically, the analysis group integrates Marlin-based FP4 kernels in each rollout and prefill, whereas LoRA limits trainable parameters. This straight targets the stage that dominates RL price and latency for lengthy reasoning traces.
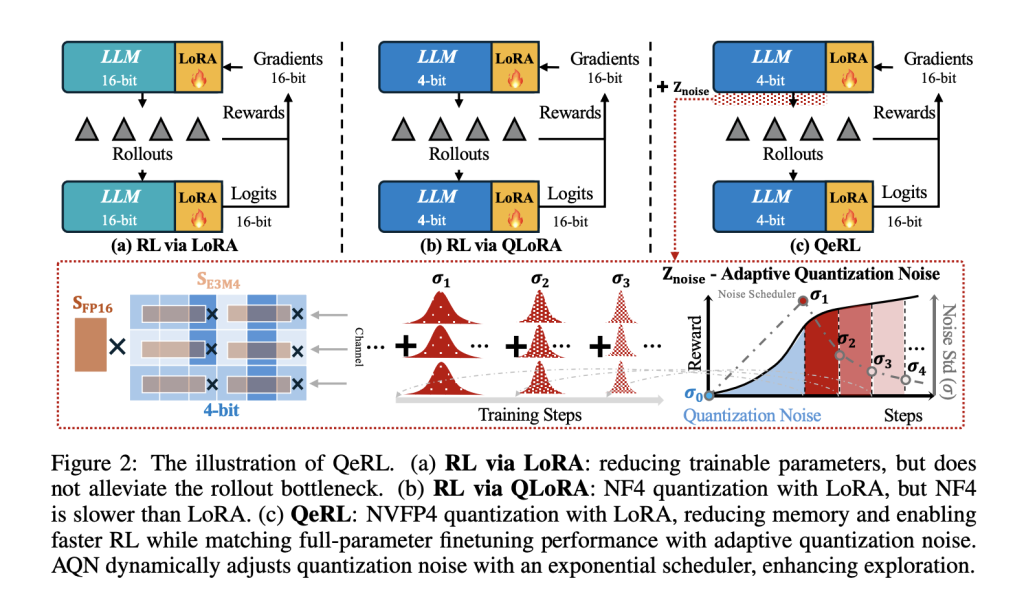
Quantization as exploration, made schedulable
A core empirical discovering: deterministic FP4 quantization raises coverage entropy, flattening token distributions early in coaching and enhancing exploration versus 16-bit LoRA and NF4-based QLoRA baselines. To manage that impact over time, QeRL introduces Adaptive Quantization Noise (AQN)—channel-wise Gaussian perturbations mapped into LayerNorm scale parameters and annealed with an exponential schedule. This retains kernel fusion intact (no additional weight tensors) whereas transitioning from exploration to exploitation.
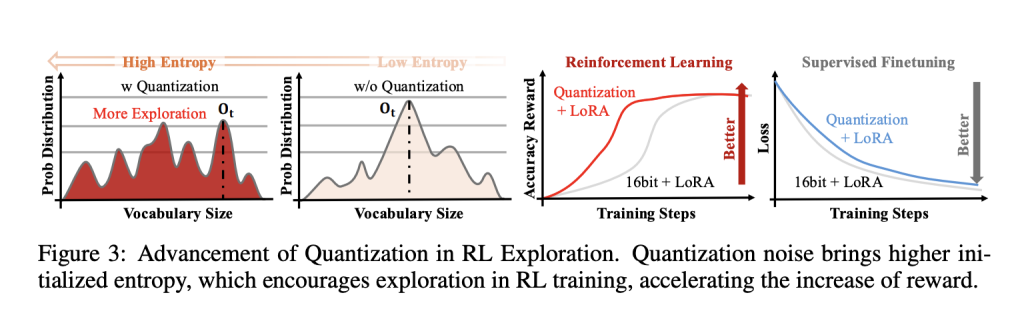
In ablations, QeRL exhibits sooner reward development and larger closing scores on math-reasoning duties underneath each GRPO and DAPO, aligning with the speculation that structured noise in parameter house is usually a helpful exploration driver in RL, though such noise is usually detrimental in supervised fine-tuning.
Reported outcomes
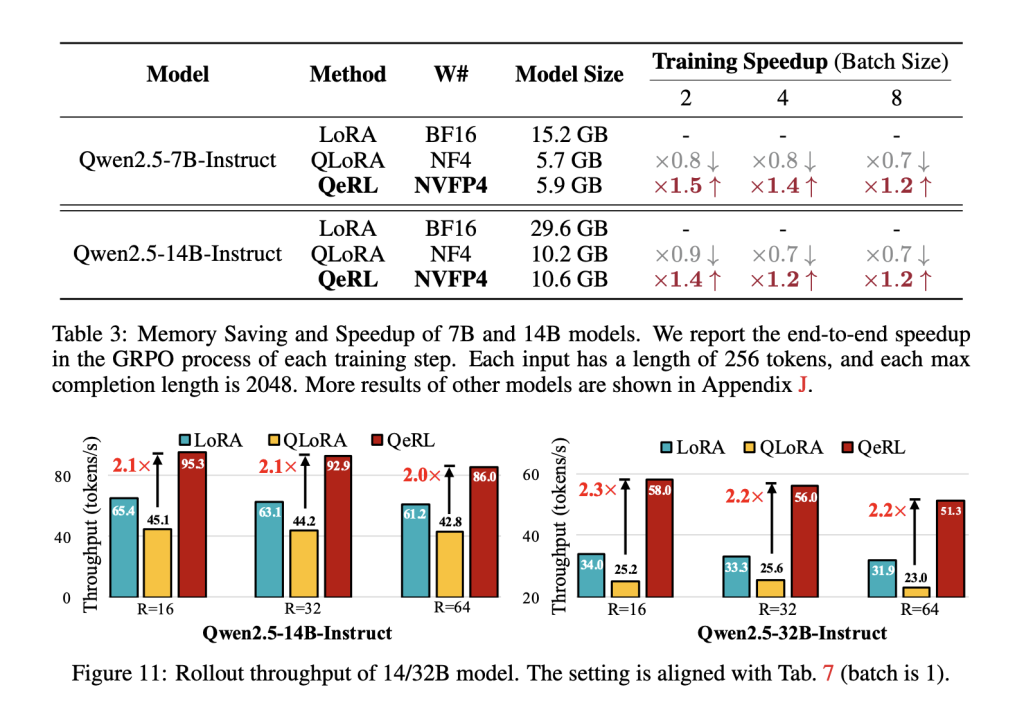
On Qwen2.5 spine mannequin, the analysis group present that NVFP4+LoRA outperforms vanilla LoRA and QLoRA in rollout throughput and total coaching time, with >2× rollout throughput on 14B/32B fashions in opposition to QLoRA and ~1.8× end-to-end vs QLoRA in a consultant setup. In addition they reveal coaching a 32B coverage with GRPO on a single H100-80GB, enabled by the decrease reminiscence footprint of weight-only FP4.
Accuracy is aggressive with higher-precision baselines. For a 7B mannequin, the analysis group reviews GSM8K = 90.8% and MATH500 = 77.4%, surpassing 16-bit LoRA and QLoRA underneath their setup and matching full-parameter fine-tuning. Throughout broader math benchmarks (e.g., BigMath), QeRL maintains parity or benefit, whereas converging sooner resulting from improved exploration.
What that is—and isn’t?
QeRL is weight-only FP4 with LoRA updates; it does not declare FP4 precision for logits/gradients. The advantages focus in rollout/prefill throughput and reminiscence footprint, with empirical proof that quantization-induced entropy aids RL exploration when AQN modulates it over coaching. Generalization to modalities past math-reasoning duties or to security/tool-use RL relies on reward design and sequence lengths.
Key Takeaways
- QeRL combines NVFP4 4-bit weight quantization with LoRA to speed up the rollout section and minimize reminiscence, enabling RL for a 32B LLM on a single H100-80GB.
- Quantization acts as exploration: FP4 will increase coverage entropy, whereas Adaptive Quantization Noise (AQN) schedules channel-wise noise through LayerNorm scales.
- Reported effectivity: >1.5× rollout speedups vs 16-bit LoRA and ~1.8× end-to-end vs QLoRA; >2× rollout throughput vs QLoRA on 14B/32B setups.
- Accuracy holds: Qwen2.5-7B reaches 90.8% on GSM8K and 77.4% on MATH500, matching full-parameter fine-tuning underneath the paper’s setup.
- NVFP4 is a hardware-optimized 4-bit floating format with two-level scaling (FP8 E4M3 block scalers + FP32 tensor scale), enabling environment friendly Marlin-based kernels.
QeRL hastens the RL rollout stage. It quantizes weights to NVFP4 and retains updates and logits in larger precision utilizing LoRA. It reviews >1.5× rollout speedups and might prepare a 32B coverage on a single H100-80GB GPU. It provides Adaptive Quantization Noise to make exploration a managed sign throughout coaching. Outcomes are proven primarily on math-reasoning duties utilizing GRPO and DAPO. The features depend on NVFP4 kernel assist corresponding to Marlin.
Take a look at the FULL CODES right here and Paper. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}